【预训练视觉-语言模型文献阅读文献阅读】最新BERT模型——UNITER: UNiversal Image-TExt Representation Learning
【预训练视觉-语言模型文献阅读文献阅读】最新BERT模型——UNITER: UNiversal Image-TExt Representation Learning
文章目录
- 【预训练视觉-语言模型文献阅读文献阅读】最新BERT模型——UNITER: UNiversal Image-TExt Representation Learning
-
- Abstract
- 1 Introduction介绍
- 2 Related Work相关工作
- 3 UNiversal Image-TExt Representation通用图像表示
-
- 3.1 Model Overview模型概述
- 3.2 预训练任务
-
- Masked Language Modeling (MLM)掩码语言建模
- Image-Text Matching (ITM) 图像文本匹配
- Word-Region Alignment 字区域对齐(WRA)
-
- Masked Region Modeling (MRM)
- 1)Masked Region Feature Regression掩码区域特征回归(MRFR)
- 2) Masked Region Classification掩码区域分类(MRC)
- 3) Masked Region Classification with KL-Divergence (MRC-kl)
- 3.3 Pre-training Datasets训练前数据集
- 4 实验
-
- 4.1 下游任务
- 4.2 Evaluation on Pre-training Tasks对预训练任务的评估
- 4.3 下游任务的结果
- 4.4 Visualization可视化
- 5 Conclusion结论
- A Appendix附录
-
- A.1Dataset Collection数据集收集
- A.2 Implementation Details实施细节
-
- Visual Question Answering视觉问答(VQA)
- Visual Commonsense Reasoning视觉常识推理(VCR)
- Natural Language for Visual Reasoning for Real (NLVR)基于事实的视觉推理的自然语言
- Image-Text Retrieval 图像文本检索
-
- Visual Entailment (SNLI-VE)
- Referring Expression Comprehension引用表达式理解
- A.3 条件屏蔽与联合随机屏蔽
-
- A.4 有关预训练设置的更多消融研究
- Significance of WRA
- A.5 有关VCR和NLVR2的更多结果
- A.6 与VLBERT和ViLBERT的直接比较
- A.7 最佳运输和IPOT算法的回顾
-
- Optimal Transport
- The IPOT algorithm
- A.8 Additional Visualization额外的可视化
Abstract
图像和文本的联合嵌入是大多数视觉和语言(V + L)任务的基础,在这些任务中,同时处理多模态输入以实现对视觉和文本的共同理解。 在本文中,我们介绍UNITER,这是一种通用的图像TExt表示形式,它是通过对四个图像文本数据集(COCO,Visual Genome,Conceptual Captions和SBU Captions)进行大规模预训练而学习的,可以为异构下游V +提供支持具有联合多模式嵌入的L个任务。 我们设计了四个预训练任务:掩码语言建模(MLM),掩码区域建模(MRM,具有三个变体),图像文本匹配(ITM)和字区域对齐(WRA) 。 与先前将联合随机掩码应用于这两种方法的工作不同,我们在预训练任务上使用条件掩码(即,掩码语言/区域建模取决于对图像/文本的完全观察)。 ==除了用于全局图像文本对齐的ITM之外,我们还建议通过使用最佳传输(OT)来建议WRA,以明确鼓励在预训练过程中单词和图像区域之间的细粒度对齐。==综合分析表明,条件掩码和基于OT的WRA都有助于更好地进行预训练。 我们还进行了彻底的消融研究,以找到训练前任务的最佳组合。广泛的实验表明,UNITER通过六个V + L任务(超过九个数据集)实现了最新的技术水平,包括视觉问答,图像文本检索,引用表达理解,视觉常识推理,视觉蕴涵和NLVR2.1
1 Introduction介绍
大多数视觉和语言(V + L)任务都依赖联合多模型嵌入来弥合图像和文本中视觉和文本线索之间的语义鸿沟,尽管此类表示通常是为特定任务而量身定制的。 例如,MCB [11],BAN [19]和DFAF [13]提出了用于视觉问题回答(VQA)的高级多模式融合方法[3]。扫描[23]和MAttNet [55]
为了研究图像文本检索[50]和参照表达理解[18],研究了单词和图像区域之间学习潜在的对齐方式。 尽管这些模型中的每一个都在各自的基准上推动了最新技术发展,但它们的体系结构却是多种多样的,并且学习到的表示形式是高度特定于任务的,从而阻止了它们将其推广到其他任务。这就提出了一个百万美元的问题:我们能否为所有V + L任务学习通用的图像文本表示形式?
本着这种精神,我们介绍了通用图像联合表示(UNITER),这是联合多模态嵌入的大规模预训练模型。我们采用Transformer [49]作为模型的核心,以利用其优雅的自我注意机制来学习上下文表示。受BERT [9]的启发,该BERT通过大规模语言建模已成功将Transformer应用于NLP任务,我们通过以下四个预训练任务对UNITER进行了预训练:
(i)以图像为条件的掩码语言建模(MLM);
(ii)以文本为条件的掩码区域建模(MRM);
(iii)图像文本匹配(ITM);
(iv)字区域对齐(WRA)。
为了进一步研究MRM的有效性,我们提出了三种MRM变体:
(i)掩码区分类(MRC);
(ii)掩码区域特征回归(MRFR);
(iii)具有KL散度的掩码区域分类(MRC-kl)。

图1:通过四个预训练任务学习的拟议UNITER模型的概述(最佳观看,彩色模型)由图像嵌入器,文本嵌入器和多层变压器组成
如图1所示,UNITER 首先使用Image Embedder和Text Embedder将图像区域(视觉特征和边框特征)和文本词(标记和位置)编码到一个公共的嵌入空间中。 然后,通过精心设计的预训练任务,使用一个Transformer模块来学习每个区域和每个单词的通用化上下文嵌入 与以前有关多模式预训练的工作相比[47,29,1,24,42,60,25]:
(i) 我们的掩码语言/区域建模是基于对图像/文本的完全观察,而不是对这两种方式都应用联合随机掩码;
(ii)通过使用“最佳运输”,我们引入了一种新颖的WRA预训练任务(OT)[37,7]明确鼓励单词和图像区域之间的细微对齐。直观地讲,基于OT的学习旨在通过最大程度地减少将一种分销转移到另一种分销的成本来优化分销匹配。 在我们的上下文中,我们旨在最大程度地减少将嵌入内容从图像区域传输到句子中的单词的成本(反之亦然),从而优化实现更好的跨模态对齐。我们证明,有条件的掩码和基于OT的WRA都可以成功缓解图像和文本之间的错位,从而为下游任务提供更好的联合嵌入。
为了展示UNITER的通用能力,我们评估了9个数据集中的6个V + L任务,包括:(i)VQA;
(ii)视觉常识推理(VCR)[58];
(iii)NLVR2 [44];
(iv)视觉约束[52];
(v)图像文本检索(包括零镜头设置)[23];
(vi)引用表达理解[56]。
我们的UNITER模型是在由四个子集组成的大规模V + L数据集上训练的:
(i)CoCo[26];
(ii)视觉基因组(VG)[21];
(iii)概念字幕(CC)[41];
(iv)SBU字幕[32]。
实验表明,UNITER在所有九个下游数据集上的性能都有了显着提高,从而达到了新的水平。 此外,与仅对COCO和VG进行训练相比,对其他CC和SBU数据(在下游任务中包含看不见的图像/文本)的训练进一步提高了模型性能。
我们的贡献总结如下:
(i)我们推出UNITER,这是一种功能强大的V + L任务通用图像表示法。
(ii)我们提出了用于掩码的语言/区域建模的条件掩码,并提出了一种新颖的基于最优运输的词域对齐任务以进行预训练。
(iii)我们在各种V + L基准上取得了最新的技术水平,大大超过了现有的多峰预训练方法。我们还提供了广泛的实验和分析,以提供有关多模式编码器训练的每个预训练任务/数据集有效性的有用见解。
2 Related Work相关工作
自我监督学习利用原始数据作为自己的监督源,该方法已应用于许多计算机视觉任务,例如图像整理[59],解决拼图[31,48],修复[35],旋转谓词等。 [15]和相对位置预测[10]。最近,预训练的语言模型,例如ELMo [36],BERT [9],GPT2 [39],XLNet [54],RoBERTa [27]Albert和ALBERT [22]在NLP任务方面取得了长足的进步。 它们成功的关键有两个:在大型语言语料库上进行有效的预培训任务,以及使用Transformer [49]学习上下文化的文本表示形式。
最近,人们开始对多模式任务进行自我监督学习,方法是对大型图像/视频和文本对进行预训练,然后对下游任务进行微调。例如,VideoBERT [46]和CBT [45]应用BERT来从视频文本对中学习视频帧特征和语言标记的联合分布。 ViLBERT [29]和LXMERT [47]引入了双流体系结构,其中两个Transformer分别应用于图像和文本,在稍后的阶段由第三个Transformer融合。
在另一方面,B2T2 [1],VisualBERT [25],Unicoder-VL [24]和VL-BERT [42]提出了单流体系结构,其中将单个Transformer应用于图像和文本。VLP [60]将预训练的模型应用于图像字幕和VQA。最近,多任务学习[30]和对抗训练[12]用于进一步提高性能。VALUE [6]开发了一组探测任务,以了解预训练的模型。
我们的贡献UNITER模型与其他方法之间的主要区别在两个方面的:
(i) UNITER在MLM和MRM上使用条件掩蔽,即仅掩盖一种模态,同时保持另一种模态不变;
(ii)通过使用最佳传输,实现了一种新颖的单词区域对齐预训练任务,而在以前的工作中,这种对齐仅由特定于任务的损失隐式地强制执行。此外,我们通过彻底的消融研究来检查预训练任务的最佳组合,并在多个V + L数据集上达到最新的发展水平,这些数据通常会大大胜过先前的工作。
3 UNiversal Image-TExt Representation通用图像表示
在本节中,我们首先介绍UNITER的模型架构(第3.1节),然后描述设计的预训练任务和用于预训练的V + L数据集(第3.2和3.3节)。
3.1 Model Overview模型概述
UNITER的模型架构如图1所示。 == 给定一对图像和句子,UNITER将图像的可视区域和句子的文本标记作为输入。我们设计了一个图像嵌入器和一个文本嵌入器来提取它们各自的嵌入。 然后将这些嵌入内容输入到多层Transformer中,以学习跨可视区域和文本标记的跨模态上下文化嵌入。请注意,Transformer中的自我关注机制是无序的,因此有必要将token的位置和区域的位置显式编码为附加输入。==
具体来说,在“图像嵌入器”中,我们首先使用Faster R-CNN2提取每个区域的视觉特征(合并的ROI特征)。我们还通过7维向量对每个区域的位置特征进行编码。然后,视觉和位置特征都通过完全连接的(FC)层馈入,并投影到相同的嵌入空间中。每个区域的最终视觉嵌入是通过将两个FC输出求和然后通过层归一化(LN)层获得的。对于文本嵌入器,我们遵循BERT [9]并将输入句子标记为WordPieces [51]。每个子词的最终表示形式token是通过将其单词嵌入和位置嵌入相加后再加上另一个LN层而获得的。
我们介绍了四个主要任务来预训练我们的模型:基于图像区域(MLM)的掩码语言建模,基于输入文本(具有三个变体)(MRM),图像-文本匹配(ITM)和单词区域对齐(WRA)的掩码区域建模。如图1所示,我们的MRM和MLM与BERT类似,在BERT中,我们从输入中随机掩盖了某些单词或区域,并学习恢复这些单词或区域作为Transformer的输出。具体来说,通过用特殊令牌[MASK]替换token来实现单词屏蔽,通过用全零替换视觉特征向量来实现区域屏蔽。请注意,每次我们只掩盖一个模态而保持另一个模态不变,而不是像其他预训练方法那样随机掩盖两个模态。当被掩盖的单词描述了被掩盖的区域时,这可以防止潜在的未对准情况(详见第4.2节)。
我们还通过ITM学习了整个图像与句子之间的实例级对齐。在训练过程中,我们对正负图像句对进行采样,并学习它们的匹配分数。此外,为了在单词标记和图像区域之间提供更细粒度的对齐方式,我们通过使用“最佳传输”来建议WRA,它可以有效地计算将上下文化图像嵌入传输到单词嵌入的最低成本(反之亦然)。因此,推断出的运输计划可作为推进器,以实现更好的交叉运输方式对准。从经验上讲,我们表明条件屏蔽和WRA都有助于提高性能(在第4.2节中)。为了使用这些任务对UNITER进行预训练,我们为每个小批量随机抽取一个任务,并且每次SGD更新仅针对一个目标进行训练。
3.2 预训练任务
Masked Language Modeling (MLM)掩码语言建模
我们将图像区域表示为v ={v1,…,vK},输入单词w = {w1,…,wT},掩码索引为m ∈ N M N^M NM在MLM中,我们以15%的概率随机掩码输入单词,并替换为带有特殊标记[MASK]的遮罩 w m w_m wm。
目标通过最小化负对数似然性,基于对周围单词w \ m和所有图像区域v的观察来预测这些掩码单词:
![]()
其中θ是可训练参数。每对(w,v)是从整个训练集D中采样的。
Image-Text Matching (ITM) 图像文本匹配
在ITM中,附加的特殊token[CLS]被输入到我们的模型中,该令牌指示两种模式的融合表示。ITM的输入是一个句子和一组图像区域,输出是二进制标签y ∈{0,1},指示采样对是否匹配。我们提取[CLS]令牌的表示作为输入图像-文本对的联合表示,然后将其输入FC层和S形函数以预测0到1之间的分数。我们将输出分数表示为 s θ ( w , v ) s_θ(w,v) sθ(w,v)。ITM监督是通过[CLS]token进行的。在训练期间,我们在每一步中都从数据集D中对正对或负对(w,v)进行采样。否定对是通过将配对样本中的图像或文本替换为其他样本中随机选择的一个来创建的。我们应用二进制交叉熵损失进行优化:
![]()
Word-Region Alignment 字区域对齐(WRA)
我们对WRA使用最佳传输(OT),其中学习了传输计划T RT×K来优化w和v之间的对齐。WRA的选择:
(i)自归一化:T的所有元素之和为1 [37]。
(ii)稀疏性:当精确求解时,OT产生的稀疏解T最多包含(2r-1)个非零元素,其中r = max(K,T),导致更易解释和更可靠的对齐[37]。
(iii)效率:与传统的线性规划求解器相比,我们的解决方案可以使用仅需要矩阵向量乘积的迭代程序轻松获得[53],因此易于应用于大规模模型预训练。
具体来说,(w,v)可视为两个离散分布 μ , ν \mu,\nu μ,ν,公式如下 μ = ∑ T i = 1 a i δ ω i \mu =\sum{\begin{array}{c} T\\ i=1\\ \end{array}}a_i\delta _{\omega _i} μ=∑Ti=1aiδωi和 ν = ∑ K j = 1 b j δ v i \nu =\sum{\begin{array}{c} K\\ j=1\\ \end{array}}b_j\delta _{v _i} ν=∑Kj=1bjδvi
δwias是以wi为中心的狄拉克函数。权向量
a = { a i } T i = 1 ∈ △ T a=\left\{ a_i \right\} \begin{array}{c} T\\ i=1\\ \end{array}\in \bigtriangleup _T a={ ai}Ti=1∈△T和 b = { b i } K j = 1 ∈ △ K b=\left\{ b_i \right\} \begin{array}{c} K\\ j=1\\ \end{array}\in \bigtriangleup _K b={ bi}Kj=1∈△K分别属于T维和K维单纯形(即 ∑ T i = 1 a i = ∑ K j = 1 b j = 1 \sum{\begin{array}{c} T\\ i=1\\ \end{array}}a_i= \sum{\begin{array}{c} K\\ j=1\\ \end{array}}b_j=1 ∑Ti=1ai=∑Kj=1bj=1),因为 μ , ν \mu,\nu μ,ν都是概率分布。和ν之间的OT距离(因此也是(w,v)对的对准损耗)定义为:

其中
![]()
1 n 1_n 1n表示n维全一向量,c(wi,vj)是计算 w i w_i wi和 v j v_j vj之间距离的代价函数。在实验中,使用余弦距离
![]()
矩阵T表示为运输计划,解释了两种模式之间的对齐。不幸的是,T上的精确最小化是计算上的难题,并且我们考虑用IPOT算法[53]来近似OT距离(细节在补充文件中提供)。求解T后,OT距离作为WRA损失,可用于更新参数θ。
Masked Region Modeling (MRM)
与MLM类似,我们还对图像区域进行采样并以15%的概率掩码其视觉特征。 训练模型以在给定其余区域的情况下重建掩码区域 v m v_m vm,v\m和所有单词w。被Masked区域的视觉特征被零代替。与以离散标签表示的文本标记不同,视觉标记特征是高维且连续的,因此无法通过类可能性进行监督。相反,我们为MRM提出了三种变体,它们具有相同的目标基础:

1)Masked Region Feature Regression掩码区域特征回归(MRFR)
MRFR学习将每个遮罩区域 v m ( i ) v^{(i)}_m vm(i)的Transformer输出回归到其视觉特征。具体来说,我们应用FC层将其Transformer输出转换为矢量与输入ROI合并特征 r ( v m ( i ) ) r(v^{(i)}_m) r(vm(i))尺寸相同的 h θ ( v m ( i ) ) h_θ(v^{(i)}_m) hθ(vm(i))。然后我们在两者之间应用L2回归::
![]()
2) Masked Region Classification掩码区域分类(MRC)
MRC学会预测每个屏蔽区域的对象语义类。 我们首先将蒙版区域 v m ( i ) v^{(i)}_m vm(i)的Transformer输出馈入FC层以预测K的分数对象类,该对象类进一步通过softmax函数转换为归一化分布 g θ ( v m ( i ) ) ∈ R K g_θ(v^{(i)}_m)∈R^K gθ(vm(i))∈RK。请注意,没有理由-真标签,因为未提供对象类别。因此,我们使用对象检测来自Faster R-CNN的输出,并将检测到的物体类别(具有最高的置信度得分)作为被遮盖区域的标签,被转换为单热向量 c θ ( v m ( i ) ) ∈ R K c_θ(v^{(i)}_m)∈R^K cθ(vm(i))∈RK。最终目标最小化交叉熵(CE)损失:
![]()
3) Masked Region Classification with KL-Divergence (MRC-kl)
MRC将来自对象检测模型的最可能的对象类别作为硬标签(w.p.0或1),假设检测到的物体类别是该区域的地面真实标签。 但是,这可能不是正确的,因为没有可用的真实标签。因此,在MRC-kl中,我们通过使用软标签作为监督信号来避免这种假设,监督信号是检测器的原始输出(即
对象类 c ~ ( v m ( i ) ) \tilde{c}(v^{(i)}_m) c~(vm(i))的贡献。MRC-kl旨在通过最小化两个分布之间的KL差异,将此类知识提炼为UNITER [16]中的知识:
![]()
3.3 Pre-training Datasets训练前数据集
我们基于四个现有的V + L数据集构建训练前数据集:COCO [26],视觉基因组(VG)[21],概念字幕(CC)[41]和SBU字幕[32]。仅将图像和句子对用于预训练,即使模型框架更具可扩展性,因为易于收获其他图像句对以进行进一步的预训练。

为了研究不同数据集对预训练的影响,我们将四个数据集分为两类。 第一个由来自COCO的图像字幕数据和来自VG的密集字幕数据组成。 我们将其称为“域内”数据,因为大多数V + L任务都建立在这两个数据集之上。为了获得“公平”的数据划分,我们将COCO的原始训练和验证划分合并,并排除了出现在下游任务中的所有验证和测试图像。我们还通过URL匹配排除了所有同时出现的Flickr30K [38]图像,因为COCO和Flickr30K图像都是从Flickr抓取的,并且可能有重叠。9同样的规则也适用于Visual Genome。这样,我们获得了用于训练的560万个图像-文本对和用于内部验证的131K个图像-文本对,这是LXMERT [47]中使用的数据集大小的一半,这归因于对重叠图像的过滤和使用。仅图像-文本对。我们还使用来自概念字幕[41]和SBU字幕[32]的其他域外数据进行模型训练。表1提供了清理后的拆分的统计信息。
4 实验
通过将预训练模型转移到每个目标任务并通过端到端训练进行微调,我们对六个V + L任务11进行UNITER评估。我们报告两种模型尺寸的实验结果:基于UNITER的12层和基于UNITER的24层.12
4.1 下游任务
在VQA,VCR和NLVR2任务中,给定输入图像(或一对图像)和自然语言问题(或描述),模型可预测答案(或判断描述的正确性)基于图像中的视觉内容。对于Visual Entailment,我们在SNLI-VE数据集上进行评估。 目的是预测给定图像在语义上是否需要输入句子。使用三个类别(“需求”,“中性”和“冲突”)的分类准确性来衡量模型的性能。 对于图像文本检索,我们考虑两个数据集(COCO和Flickr30K),并在两个设置中评估模型:图像检索(IR)和文本检索(TR)。 引用表达式(RE)理解要求模型在给定查询描述的情况下从一组图像区域建议中选择目标。在地面实物和检测到的建议上都对模型进行了评估13(MAttNet [55])。
对于VQA,VCR,NLVR2,Visual Entailment和图像文本检索,我们从[CLS]令牌表示中通过多层感知器(MLP)提取输入图像文本对的联合嵌入。对于RE理解,我们使用MLP来计算区域性比对得分。这些MLP层是在微调阶段学习的。具体来说,我们将VQA,VCR,NLVR2,Visual Entailment和RE理解公式化为分类问题,并最大程度地减小了真实答案/响应的交叉熵。 对于图像文本检索,我们将其公式化为排名问题。 在微调期间,我们通过随机替换其句子/图像来对三对图像和文本进行采样,从数据集中对一个正对进行采样,对两个负对进行采样。我们计算正负对的相似度得分(基于联合嵌入),并通过三重态损失最大化它们之间的余量。
4.2 Evaluation on Pre-training Tasks对预训练任务的评估

表2:使用VQA,图像文本重新评估评估预训练任务和数据集
我们通过对VQA,NLVR2,Flickr30K和RefCOCO +作为代表性V + L基准进行消融研究,分析了不同的预训练设置的有效性。除了每个基准的标准指标14,我们还将Meta-Sum(所有基准中所有分数的总和)用作全局指标。
首先,我们建立两个基准:表2中的第1行(L1)表示不涉及预训练,而L2显示的是用[9]中的预训练权重初始化的MLM结果。尽管只接受文本训练的传销在预训练过程中没有吸收任何图像信息,但我们发现,与L1相比,Meta-Sum的增益约为+30。因此,我们使用L2中的预训练权重进行初始化我们的模型用于以下实验。
其次,我们通过彻底的消融研究验证了每个预训练任务的有效性。比较L2和L3,仅在NLVR2上,MRFR(L3)会比MLM(L2)取得更好的结果。 另一方面,仅在ITM(L4)或MLM(L5)上进行预训练时,我们观察到所有任务在L1和L2基准上均得到了显着改善。当组合不同的预训练任务时,MLM + ITM(L6)优于单个ITM(L4)或MLM(L5)。当对MLM,ITM和MRM进行联合培训(L7-L10)时,我们在所有基准测试中观察到一致的性能增益。在MRM的三个变体(L7-L9)中,我们观察到MRC-kl(L9)与MLM + ITM结合使用时可达到最佳性能(397.09),而MRC(L7)最差(393.97)。当将MRC-kl和MRFR与MLM和ITM(L10)结合使用时,我们发现它们是互为补充的,这导致Meta-Sum得分第二高。通过MLM + ITM + MRC-kl + MRFR + WRA(L11)获得最高的元总和得分。我们发现通过添加WRA可以显着改善性能,尤其是在VQA和RefCOCO +上。它表明在预训练期间通过WRA学习的单词和区域之间的细粒度对齐有利于涉及区域级别识别或推理的下游任务。我们将这种最佳的预训练设置用于进一步的实验。
此外,我们通过比较研究验证了条件掩蔽的贡献。当我们在预训练期间同时对两种模态进行随机屏蔽时,即不使用条件屏蔽(L12)时,与条件屏蔽(399.97)相比,我们发现Meta-Sum得分有所下降(396.51)。这表明条件屏蔽策略使模型得以实现有效地学习更好的联合图文表示。
最后,我们研究了预训练数据集的影响。 到目前为止,我们的实验都集中在域内数据上。 在这项研究中,我们在域外数据(概念字幕+ SBU字幕)上对我们的模型进行了预训练。 与在域内数据(COCO +视觉基因组)上训练的模型(L11中的400.93)相比,性能下降(在L13中为396.91)表明,尽管域外数据包含更多图像,该模型仍然受益于在预训练期间暴露于相似的下游图像。我们进一步在域内和域外数据上对模型进行预训练。随着数据大小增加一倍,该模型将继续改进(L14中的405.24)。
4.3 下游任务的结果
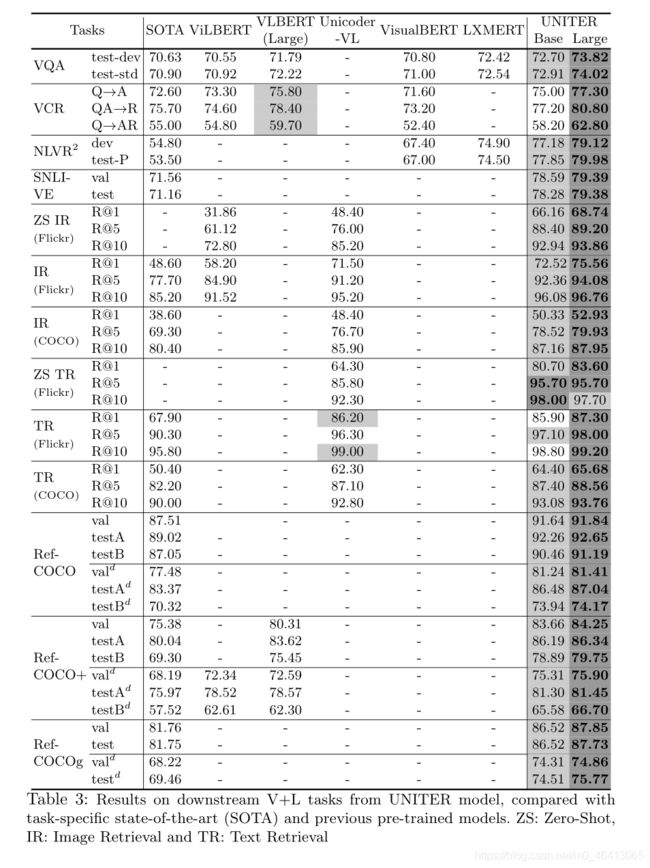
表3:来自UNITER模型的下游V + L任务的结果,与特定于任务的最新技术(SOTA)和先前的预训练模型。 ZS: 零射,IR:图像检索和TR:文字检索
表3列出了UNITER在所有下游任务上的结果。我们的基本模型和大型模型都在域内+域外数据集上进行了预训练,并具有最佳的预训练设置:MLM + ITM + MRC-kl + MRFR + WRA。补充文件中提供了每个任务的实现详细信息。 我们将针对每个下游任务的任务特定模型和其他预训练模型进行比较。SOTA特定于任务的模型包括:用于VQA的MCAN [57],用于NLVR2的MaxEnt [44],用于VCR的B2T2 [1],用于图像-文本检索的SCAN [23],用于SNLI-VE的EVE-Image [52],以及用于RE理解的MAttNet( RefCOCO,RefCOCO +和RefCOCOg)。15其他预先训练的模型包括:ViLBERT [29],LXMERT [47],Unicoder-VL [24],VisualBERT [25]和VL-BERT [42]。
结果表明,我们的UNITER大型模型在所有基准测试中均达到了最新水平。 基于UNITER的模型在除VQA之外的所有任务上也大大优于其他模型。具体来说,我们基于UNITER的模型在Q AR上的VCR胜过SOTA约+ 2.8%,对于NLVR2胜过+ 2.5%,对于SNLI-VE胜过+ 7%,对于图像文本检索,R @ 1胜过+ 4%(+ 15% (用于零拍设置),+ 2%用于RE理解。
请注意,LXMERT使用下游VQA(+ VG + GQA)数据进行预训练,这可能有助于使模型适应VQA任务。 但是,当对NLVR2等看不见的任务进行评估时,UNITER-base的性能比LXMERT高3%。此外,在仅针对图文对进行预训练的所有模型中,基于UNITER的模型在VQA方面比其他模型高出1.5%以上。
还值得一提的是,VilBERT和LXMERT都观察到两流模型优于单流模型,而我们的结果从经验上证明,通过我们的预训练设置,单流模型可以实现新的最新技术参数少得多的结果(基于UNITER的位置:LXMERT 86M:183M,VilBERT:221M)
对于VCR,我们提出了两阶段的预训练方法:
(i)在标准预训练数据集上进行预训练;
(ii)在下游VCR数据集上进行预训练。有趣的是,虽然VLBERT和B2T2观察到预训练对VCR并不是很有帮助,但我们发现第二阶段的预训练可以显着提高模型性能,而第一阶段的预训练仍然有帮助但效果有限(结果如表4所示。这表明,在我们的预训练模型中,针对未在预训练数据集中看到的新数据,建议的两阶段方法非常有效。使用与其他功能相同的功能来更新

与其他任务不同,NLVR2将两个图像作为输入。因此,直接对预先经过图像句对训练的UNITER进行微调可能不会导致最佳性能,因为在预训练阶段未学习配对图像之间的交互。因此,我们在NLVR2上试验了三种修改的设置:
(i)三元组:图像对和查询标题的联合嵌入;
(ii)配对:每个图像和每个查询标题的单独嵌入;
(iii)Pair-biattn:在Pair模型中增加了双向注意,以学习配对图像之间的交互作用。
比较结果列于表5。即使图像对之间没有交叉注意,“对”设置也比“三重态”设置具有更好的性能。我们假设这是由于我们的UNITER接受了图文对的预训练。因此,难以在三重态输入上微调基于对的预训练模型。但是,在“双向-双向”设置中的双向注意力机制可以补偿图像之间缺乏交叉注意力的情况,从而以较大的余量产生最佳性能。 这表明,只需在UNITER顶层进行最少的手术,我们的预训练模型就可以适应与预训练任务截然不同的新任务。

4.4 Visualization可视化
类似于[20],我们在UNITER模型的注意力图中观察到了几种模式,如图2所示。注意,与[20]不同,我们的注意力机制以模态内和模态方式运作。为了完整起见,我们在这里简要讨论每种模式:
– 纵向:关注特殊Token[CLS]或[SEP];
– 对角线:关注令牌/区域本身或之前/之后的令牌/区域;
– 垂直+对角线:垂直和对角线的混合;
– 阻止:模态内注意,即文本自我注意和视觉自我注意;
– 异类:无法归类且高度依赖于实际输入的各种关注;
– 反向块:模式间注意,即文本到图像和图像到文本的注意。


图3:文字到图片的注意力可视化示例
注意,Reversed Block(图2f)显示了标记和区域之间的交叉模态对齐。在图3中,我们可视化了文本到图像注意的几个示例,以演示区域和标记之间的局部交叉模式对齐方式。
5 Conclusion结论
在本文中,我们介绍UNITER,这是一种大规模的预训练模型,可为视觉和语言任务提供通用的图像TExt表示。提出了四个主要的培训前任务,并通过广泛的消融研究对其进行了评估。在域内和域外数据集的训练下,UNITER在多个V + L任务上以相当大的优势执行了最新模型。未来的工作包括研究原始图像像素和句子标记之间的早期交互,以及开发更有效的预训练任务。
A Appendix附录
该补充材料分为八个部分。第A.1节介绍了我们的数据集集合的详细信息。A.2节描述了我们对每个下游任务的实施细节。A.3节提供了条件掩蔽和联合随机掩蔽之间的详细定量比较。 A.5节提供了有关VCR和NLVR2的更多结果。 第A.6节提供了与VLBERT和ViLBERT的直接比较。 第A.7节提供了有关最佳传输(OT)和用于计算OT距离的IPOT算法的一些背景知识。A.8节提供了其他可视化示例。
A.1Dataset Collection数据集收集
如前所述,我们的完整数据集由四个现有的V + L数据集组成:COCO,视觉基因组,概念字幕和SBU字幕。数据集的收集不仅仅是将它们组合在一起,因为我们需要确保在预训练期间看不到任何下游评估图像。 其中,COCO是最棘手的清理对象,因为在此基础上构建了多个下游任务。图4列出了全部来自COCO图像的VQA,图像文本检索,COCO字幕,RefCOCO / RefCOCO + / RefCOCOg和自下而上的自顶向下(BUTD)检测[2]的拆分。
如观察到的,不同任务的验证和测试拆分分散在原始COCO拆分中。因此,我们排除了出现在下游任务中的所有那些评估图像。此外,我们还通过URL匹配排除了所有同时出现的Flickr30K图像,以确保Flickr上的零镜头图像-文本检索评估是公平的。 其余图像成为我们完整数据集中的COCO子集,如图4底部所示。我们对视觉基因组,概念字幕和SBU字幕应用相同的规则。

A.2 Implementation Details实施细节
我们的模型是基于PyTorch17 [34]实现的。 为了加快训练速度,我们使用Nvidia Apex18进行混合精确训练。所有预培训实验均在Nvidia V100 GPU(16GB VRAM; PCIe连接)上运行。微调实验是在相同的硬件或Titan RTX GPU(24GB VRAM)上实施的。为了进一步加快训练速度,我们实现了动态序列长度,以减少输入单位(文本标记+图像区域)数量的填充和批处理示例。对于大型的预培训实验,我们使用Horovod19 + NCCL20进行多节点通信(通过以太网的TCP连接),最多4个Vx Server 4个节点。梯度累加[33]也可用于减少多GPU通信的开销。
Visual Question Answering视觉问答(VQA)
我们遵循[57]的方法,将3129个最常见的答案作为候选答案,并根据每个候选者与10个人回答的相关性为每个候选者分配软目标分数。 为了在VQA数据集上进行微调,我们使用二进制交叉熵损失来训练多标签分类器,该方法使用的批处理大小为10240个输入单元,最大5K步。我们使用AdamW优化器[28],其学习速率为3e 4,权重衰减为0.01。在推断时,将最大可能答案选择为预测答案。 对于test-dev和test-std分割的结果,训练和验证集都用于训练,而Visual Genome的其他问题-答案对则用于数据扩充,如[57]中所述。
Visual Commonsense Reasoning视觉常识推理(VCR)
VCR可以分解为两个多项选择子任务:问答任务(Q A)和回答理由任务(QA R)。 在整体设置(Q AR)中,模型需要首先从答案选择中选择一个答案,然后在选择的答案正确的情况下从理由选择中选择一个支持的理由。 我们同时在两个设置中训练我们的模型。 在整体环境中进行测试时,我们首先将模型应用于预测答案,然后基于给定的问题和预测的答案从同一模型中获得基本原理。对于VCR数据集的微调,我们将问题(问题答案和基本事实答案)与来自四个可能答案(理智)的每个答案(理智)的选择串联起来。扩展了“模式嵌入”以帮助区分问题,答案和理由。交叉熵损失用于为每个问题-答案对(问题-答案-理性三元组)训练超过两类(“正确”或“错误”)的分类器,批量最大为4096个输入单元5K步。我们使用AdamW优化器,其学习速率为1e-4,权重衰减为0.01。
由于VCR数据集中的图像和文本与我们的预训练数据集有很大不同,因此我们将MLM,MRFR和MRC-kl作为预训练任务,进一步在VCR上对我们的模型进行预训练。由于VCR中的文本未明确描述该图像,因此ITM被丢弃。表4(在主要论文中)报告了两种关于VCR的预培训的结果,并在正文中进行了讨论。总之,对于包含新数据的下游任务,这些新数据与预训练数据集有很大不同,第二阶段的预训练有助于进一步提高性能。
在我们的实施方案中,第二阶段的预训练以4096个输入单位的批处理量,3e-4的学习率和3的权重衰减进行。
最多60K步超过0.01。经过第二阶段的预交易后,我们以最大8K步长的6e-5的学习率对模型进行微调。
Natural Language for Visual Reasoning for Real (NLVR)基于事实的视觉推理的自然语言
NLVR2是视觉推理的一项新挑战。目的是确定自然语言陈述对于给定的图像对是否正确。 在这里,我们详细讨论NLVR2微调的三种体系结构变体。 由于UNITER在预训练时仅处理一张图像和一张文本输入,因此扩展了“模态嵌入”以帮助区分NLVR2任务中显示的其他图像。对于Triplet设置,我们将图像区域连接起来,然后输入UNITER模型。MLP变换应用于[CLS]输出以进行二进制分类。对于“配对”设置,我们通过重复文本将一个输入示例视为两个文本-图像对。"]],null,"en 然后,将UNITER的两个[CLS]输出进行深度连接,作为该示例的联合嵌入。 另一个MLP进一步将此嵌入转换为最终分类。对于“配对”设置,输入格式与“配对”设置相同。对于联合表示,我们不仅仅依赖两个[CLS]输出,而是在一个联合图像-文本嵌入序列上应用一个多头注意层[49]来处理另一个嵌入序列,反之亦然。在进行这种“双向”注意力交互之后,对每个输出序列应用简单的注意力集中,然后最后的concat + MLP层将交叉参与的联合表示转换为真/假分类。
我们对NLVR2的UNITER进行了8K步的微调,批量大小为10K输入单元。AdamW优化器的学习速率为1e 4,权重衰减为0.01。
Image-Text Retrieval 图像文本检索
为此任务考虑了两个数据集:COCO和Flickr30K。COCO由123K图像组成,每个图像都带有五个人工书写的字幕。我们按照[17]将数据分为82K / 5K / 5K培训/验证/测试图像。 还包括来自MSCOCO验证集的其他30K图像,以改善训练效果,如[23]中所述。Flickr30K数据集包含从Flickr网站收集的31K图像,每个图像有五个文本描述。我们按照[17]将数据划分为30K / 1K / 1K训练/验证/测试划分。在微调期间,我们分别从图像和文本侧面对每个正样本采样两个负的图像-文本对。 对于COCO,我们使用60个示例的批次大小,2e 5的学习率,并以20K步微调我们的模型。对于Flickr30K,我们以120个示例的批次大小和一个
在最大16K步中,学习率为5e-5。
为了获得表3中的最终结果,我们进一步对样本进行抽样
底片以利于微调。对于每N个步骤,我们从每个文本输入中随机采样128个负图像,并获得整个训练集的稀疏得分矩阵。 对于每个图像,我们选择排名前20位的否定句子作为硬否定样本。同样,我们根据每个句子的分数获得20个硬否定图像。硬底片作为附加底片样本发送到模型。最后,我们有两个随机采样的负样本和每个正样本两个硬负样本。对于COCO,N设置为4000;对于Flickr30K,N设置为2500。
Visual Entailment (SNLI-VE)
视觉蕴涵是一项从Flickr30K图像和斯坦福自然语言推理(SNLI)数据集派生的任务,其目的是确定自然语言陈述与图像之间的逻辑关系。 与自然语言推断(NLI)的BERT相似,我们将SNLI-VE视为三向分类问题,并在[CLS]输出上应用了MLP变换。使用交叉熵损失对UNITER模型进行微调。批量大小设置为10K输入单位,我们使用AdamW
学习率为8e-5的3K步训练。
Referring Expression Comprehension引用表达式理解
我们使用三个引用表达式数据集:进行评估的RefCOCO,RefCOCO +和RefCOCOg均收集在COCO图像上。为了对UNITER进行微调,我们在Transformer的区域输出之上添加了一个MLP层,以计算查询短语/句子与每个区域之间的对齐分数。 由于只有一个对象与查询短语/句子配对,因此我们对标准对齐分数应用交叉熵损失。 微调非常有效-我们仅用5个时间段就以64个示例的批次大小和5e 5的学习率训练了模型,并实现了最先进的性能。
请注意,包括我们在内的所有作品都使用在COCO(和Visual Genome)上经过训练的现成对象检测器来提取视觉特征。 尽管这不会影响其他下游任务,但是却引起了对RE理解的问题,因为RefCOCO,RefCOCO +和RefCOCOg的值/测试图像是COCO训练分组的子集。严格来说,我们的目标检测器不允许使用这些val / test图像进行训练。"]],null,"en但是,仅是为了与并发作品进行“公平”比较,我们忽略了此问题,并使用了与其他作品相同的功能[2]。 我们还使用此“受污染”功能更新了MAttNet的结果,该功能的准确性比原始功能高1.5%。如前所述,句子和图像之间的交互可以从标记和像素开始,而不是从标记和像素开始提取的特征。我们将这项研究和对RE的理解留给以后的工作以严格正确的特征为准。
A.3 条件屏蔽与联合随机屏蔽

我们将进一步讨论我们提出的条件掩蔽相对于[47,29]中使用的联合随机掩蔽的优势。直观地讲,我们的条件掩蔽学习了两种模式下实体(区域和单词)的更好的对齐方式。图5示出了带有“男人和他的狗和猫坐在沙发上的人”的示例图像。通过条件掩蔽,当对狗的区域进行掩蔽时,我们的模型应该能够基于周围区域和整个句子的上下文来推断该区域为狗(图5(a)),反之亦然。 但是,对于联合掩蔽实现,当同时遮盖住dog和字dog的区域时,可能会发生这种情况(图5(b))。在这种情况下,模型必须盲目地进行预测,这可能会导致失准。
为了验证这种直觉,我们在图6中显示了MLM和MRC-kl的预训练过程中的验证曲线。每个子图显示在UNITER的预训练期间应用条件掩膜和联合随机掩膜之间的比较。MLM准确性衡量UNITER可以很好地重构屏蔽词,而MRC-kl准确性21衡量UNITER可以对屏蔽区域进行分类的程度。在这两种情况下,如图6所示,我们的条件掩蔽比联合随机掩蔽收敛更快,并且最终精度更高。此外,主文件中的表2(第10和11行) 显示我们的条件屏蔽在微调的下游任务上也表现更好。

图6:使用联合遮罩和我们提出的条件遮罩对MLM和MRC-kl验证准确性进行比较
A.4 有关预训练设置的更多消融研究
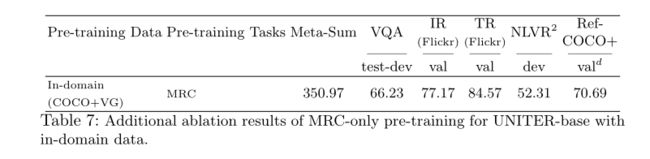
仅MRC的预训练除了主表中的表2所示的消融外,当仅对域内数据进行MRC的预训练时,我们还包括UNITER-base的结果。表7显示,仅MRC的预训练会导致与仅MRFR的预训练类似的下游性能,与所有其他具有域内数据的预训练设置相比,这是一个较弱的基线(表2中的第4-12行) )。
Significance of WRA
在论文的表2中,我们表明添加WRA可以显着提高VQA和RefCOCO +上的模型性能,同时在Flickr和NLVR2上可以达到可比的结果。通过设计,WRA鼓励在每个图像区域和一个句子中的每个单词之间进行局部对齐。因此,WRA大多依赖于区域级的识别和推理(例如VQA)而使下游任务受益,而Flickr和NLVR2则更侧重于全局而不是局部对齐。当使用表8中的域内和域外数据进行预训练时,我们为UNITERlarge的WRA添加了其他消融结果。 我们在零镜头设置中获得了可观的图像/文本检索性能,并在所有其他任务中获得了一致的增益。

A.5 有关VCR和NLVR2的更多结果

按照主文件表4中的VCR设置,我们进一步使用10 UNITER-large构建一个集成模型。表9显示了VCR上VLBERT,ViLBERT和UNITER之间的比较。 我们的集成模型的Q AR准确性优于ViLBERT [29]集成,为7.0%。请注意,即使是单个UNITER-large也已经比ViLBERT集成和VLBERT-large的性能高出3.0%。

此外,在表10中,我们还将NLVR2的其他测试部分与UNITER-large,LXMERT [47]和VisualBERT [25]进行了比较。我们的结果在所有指标上始终比以前的SOTA高出约4.0%。在[43]中引入了平衡评估和不平衡评估。
A.6 与VLBERT和ViLBERT的直接比较
为了进一步证明我们的想法,我们直接与接受概念字幕[41]训练的ViLBERT [29]和VLBERT [42]进行比较。 我们仅使用拟议的条件掩蔽和最佳的预训练任务对UNITER进行概念字幕的预训练。表11显示UNITER在VQA和RefCOCO +上的可见余量仍然始终优于其他模型。

表11: ViLBERT [29],VLBERT [42]和我们的UNITER之间的直接比较,所有这些仅接受了概念字幕[41]的培训
A.7 最佳运输和IPOT算法的回顾
Optimal Transport
我们首先简要回顾一下最优运输,它定义了域X(在我们的设置中为序列空间)上的概率测度之间的距离。两种概率测度的最佳运输距离
µ和ν定义为[37]:

其中Π(μ,ν)表示所有具有边际的联合分布γ(x,y)的集合
µ(x)和ν(y); c(x,y):X X R是将x移至y的成本函数,例如,欧几里得距离或余弦距离。直观地,最佳运输距离是
γ引起的从µ到ν迁移的最小成本。当c(x,y)是X的度量时,c(µ,ν)会在X所支持的概率分布空间(通常称为Wasserstein距离)上诱发一个适当的度量。最受欢迎的选择之一是2-Wasserstein距离W2(µ,ν),其中平方欧几里德距离c(x,y)=“ x-y” 2被用作成本。
The IPOT algorithm

不幸的是,在T上的精确最小化通常在计算上是棘手的[4,14,40]。为了克服这种难处理性,我们考虑了一种有效的迭代方法来近似OT距离。 我们建议使用最近引入的Inexact近邻点方法进行最优传输(IPOT)算法可计算OT矩阵T *,从而计算OT距离[53]。具体来说,IPOT迭代地解决了以下优化问题
使用近端点法的问题[5]:

接近度项 B ( T , T ( t ) ) B(T,T^{(t)}) B(T,T(t))惩罚了太过复杂的解决方案
远离最新的近似值,并且1被理解为广义的步长。这为精确的OT解决方案提供了一种易于处理的迭代方案。
在这项工作中,我们采用广义的KL Bregman散度B(T,T(t))=
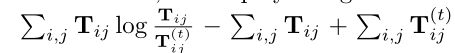
作为接近度指标。算法1描述IPOT的实现细节。
注意,Sinkhorn算法[8]也可用于计算OT矩阵。具体来说,Sinkhorn算法尝试解决熵正则优化问题:![]()
其中![]()
是熵正则项,而s> 0是正则化强度。但是,在我们的实验中,我们凭经验发现
Sinkhorn算法的数值稳定性和性能对超参数s的选择非常敏感,因此在模型训练中仅考虑IPOT。
A.8 Additional Visualization额外的可视化

图7:附加的文本到图像注意力可视化示例