Deep Residual Learning for Image Recognition--ResNet论文阅读笔记
Deep Residual Learning for Image Recognition--ResNet
原文 点击打开链接
“ease the training of networks that are substantially deeper than those used previously”
核心思想:提高更深层网络的训练效率
网络加深后遇到的问题:
1. vanishing/exploding gradients
normalized initialization and intermediate normalization layers
梯度消失或爆炸,导致最终无法逼近局部最小值。用归一化处理可以基本解决这一问题。
2. degradation
退化问题:更深层的网络训练效果却更差,残差网络主要解决这一问题。
I. Basic Ideas
1. residual mapping
denoting the desired underlying mapping as H(x), we let the stacked nonlinear layers fit another mapping of F(x) := H(x)−x. The original mapping is recast into F(x)+x
x是输入层,现在通过网络不直接获得输出层的值H(x),而是获得残差值F(x),输出层的值=F(x)+x(也可以把x换成其它x的函数,但是用identity的好处是没有增加新的学习参数)
2. shortcut connections
The formulation of F(x)+x can be realized by feed forward neural networks with “shortcut connections” (Fig. 2). Shortcut connections are those skipping one or more layers.
残差网络实现方法:在输入与输出之间加一个向前的shortcut,这样原网络输出就成了残差

II. Notice
1. The dimensions of x and F mustbe equal. If this is not the case (e.g., when changing the input/output channels), we can perform a linear projection Ws by the shortcut connections tomatch the dimensions
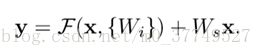
如果输入输出层维度不同(比如channel数不同),shortcut就要加一个转换维度的映射。
2. a function F that has two or three layers. if F has only a single layer we have not observed advantages.
用来学习残差的网络层数应当大于1(否则没有明显效果),更多的层也是可行的。
III. Network Architectures

1. plain network 基于VGG设计,residual network 在plain network的基础上加了shortcut connections.
2. When the dimensions increase (dotted line shortcutsin Fig. 3), we consider two options:
(A) The shortcut still performs identity mapping, with extra zero entries padded for increasing dimensions. This option introduces no extra parameter;
(B) The projection shortcut is used to match dimensions (done by 1×1 convolutions).
虚线是维度不匹配时的shortcut,有两种方案:直接把增加的维度设为0或乘投影矩阵
IV. Implementation
multi-scale, standard color augmentation, BN, SGD with a mini-batch size of 256
learning rate starts from0.1 and is divided by 10 when the error plateaus and the models are trained forup to 60×104 iterations.
weight decay : 0.0001 momentum : 0.9. no dropout
V. Experiments
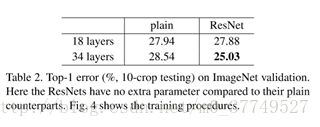
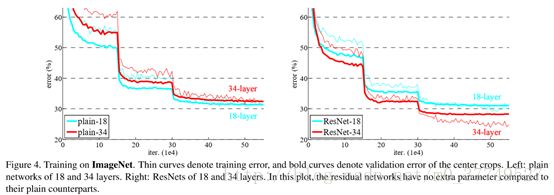
plain network从18-layer到34-layer出现了退化现象,而ResNet-34效果要优于ResNet-18
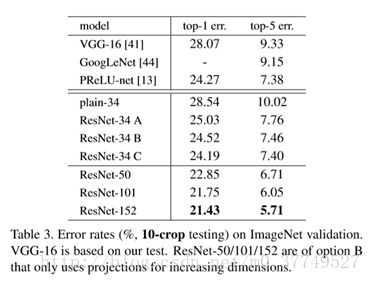
(A)zero-padding shortcuts areused for increasing dimensions, and all shortcuts are parameter free
(B) projection shortcuts areused for increasing dimensions, and other shortcuts are identity;
(C) all shortcuts areprojections
ResNet-34 ABC都优于plain-34,B优于A,C略优于B,说明projection shortcuts在效果上更好
VI. Deeper Bottleneck Architectures

The three layers are 1×1, 3×3, and 1×1 convolutions, where the 1×1 layers are responsible for reducing and then increasing (restoring) dimensions, leaving the 3×3 layer a bottleneck with smaller input/output dimensions.
两头的conv1先降维再升维
identity shortcuts lead to more efficient models for the bottleneck designs
对于bottleneck,identity shortcut要优于projection shortcut