MAML原理讲解和代码实现
Model-Agnostic Meta-Learning - MAML
一、相关概念:
1、meta-leaning
meta-leaning指的是元学习,元学习是深度学习的一个分支,一个好的元模型(meta-learner)应该具备对新的、少量的数据做出快速而准确的学习。通俗的来讲, 对于人来说,给几张橘猫的图片让看一下,再给你几张没见过的英短猫图片,你一定能很快识别出来都是猫。但是对于神经网络来说,并非如此。如果让一个小汽车分类网络去识别不同的大货车,那效果肯定很差。而传统的CNN网络都是输入大量的数据,然后进行分类的学习。但是这样做的问题就是,神经网络的通用性太差了,根本达不到“智能”的标准。而人类的认知系统,可以通过少量的数据就可以从中学习到规律,人类之所以可以做到这么智能,是因为人脑存在“先验知识”。
2、few-shot learning
few-shot learning译为小样本学习,是指从极少的样本中学习出一个模型。
N-way K-shot
这是小样本学习中常用的数据,用以描述一个任务:它包含N个分类,每个分类只有K张图片。
Support set and Query set
Support set指的是参考集,Query set指的是测试集。用人识别动物种类大比分,有5种不同的动物,每种动物2张图片,这样10张图片给人做参考。另外给出5张动物图片,让人去判断各自属于那一种类。那么10张作为参考的图片就称为Support set,5张测试图片就称为Query set。

二、什么是MAML?
论文地址
1、要解决的问题
- 小样本问题
- 模型收敛太慢
普通的分类、检测任务中,因为分类、检测物体的类别是已知的,可以收集大量数据来训练。例如 VOC、COCO 等检测数据集,都有着上万张图片用于训练。而如果我们仅仅只有几张图片用于训练,这给模型预测带来很大障碍。
在深度学习中,解决训练数据不足常用的一个技巧是“预训练-微调”(Pretraining-finetune),即大数据集上面预训练模型,然后在小数据集上去微调权重。但是,在训练数据极其稀少的时候(仅有个位数的训练图片),这个技巧是无法奏效的。并且这样的方式有时候反而会让模型陷入局部最优。
2、MAML的关键点
本文的设想是训练一组初始化参数,模型通过初始化参数,仅用少量数据就能实现快速收敛的效果。为了达到这一目的,模型需要大量的先验知识来不停修正初始化参数,使其能够适应不同种类的数据。
3、MAML与Pretraining的区别
- Pretraining
假设有一个模型从task1的数据中训练出来了一组权重,我们记为 θ 1 \theta1 θ1,这个 θ 1 \theta1 θ1是图中深绿色的点,可以看到,在task1下,他已经达到了全局最优。而如果我们的模型如果用 θ 1 \theta1 θ1作为task2的初始值,我们最终将会到达浅绿色的点,而这个点只是task2的局部最优点。产生这样的问题也很简单,就是因为模型在训练task1的数据时并不用考虑task2的数据。

- MAML
MAML则需要同时考虑两个数据集的分布,假设MAML经过训练以后得到了一组权重我们记为 θ 2 \theta2 θ2,虽然从图中来看,这个权重对于两个任务来说,都没有达到全局最优。但是很明显,经过训练以后,他们都能收敛到全局最优。
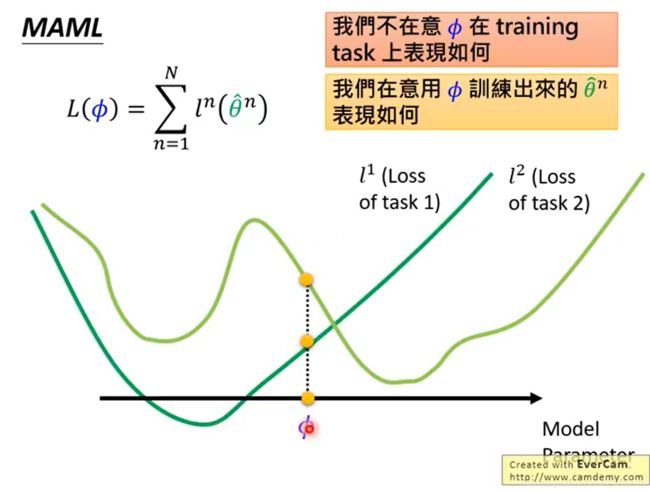
所以,Pretraining每次强调的都是当下这个模型能不能达到最优,而MAML强调的则是经过训练以后能不能达到最优。
三、MAML的核心算法
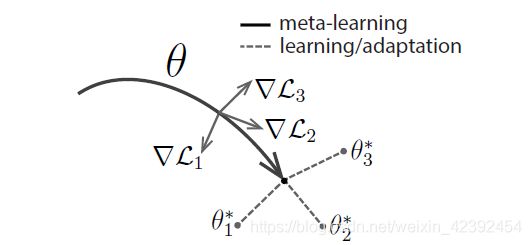
刚刚说了MAML关注的是,模型使用一份“适应性很强的”权重,它经过几次梯度下降就可以很好的适用于新的任务。那么我们训练的目标就变成了“如何找到这个权重”。而MAML作为其中一种实现方式,它先对一个batch中的每个任务都训练一遍,然后回到这个原始的位置,对这些任务的loss进行一个综合的判断,再选择一个适合所有任务的方向。
其中有监督学习的分类问题算法流程如下:

先决条件:
- 以任务为单位的数据集
- 两个学习率 α 、 β \alpha 、\beta α、β
流程解析:
Step 1: 随机初始化一个权重
Step 2: 一个while循环,对应的是训练中的epochs(Step 3-10)
Step 3: 采样一个batch的task(假设为4个任务)
Step 4: for循环,用于遍历所有task(Step 5-8)
Step 5: 从support set中取出一批task图片和标签
Step 6-7: 对这一张图片进行前向传播,计算梯度后用 l r α lr_\alpha lrα反向传播,更新 θ ′ \theta' θ′这个权重
Step 8: 从query set中取出所有task进行前向传播,但不更新模型
Step 10: 将所有用 θ ′ \theta' θ′计算出来的损失求和,计算梯度后用 l r β lr_\beta lrβ进行梯度下降,更新 θ \theta θ的权重
相关代码如下:
def train_on_batch(self, train_data, inner_optimizer, inner_step, outer_optimizer=None):
"""
MAML一个batch的训练过程
:param train_data: 训练数据,以task为一个单位
:param inner_optimizer: support set对应的优化器
:param inner_step: 内部更新几个step
:param outer_optimizer: query set对应的优化器,如果对象不存在则不更新梯度
:return: batch query loss
"""
batch_acc = []
batch_loss = []
task_weights = []
# 用meta_weights保存一开始的权重,并将其设置为inner step模型的权重
meta_weights = self.meta_model.get_weights()
meta_support_image, meta_support_label, meta_query_image, meta_query_label = next(train_data)
for support_image, support_label in zip(meta_support_image, meta_support_label):
# 每个task都需要载入最原始的weights进行更新
self.meta_model.set_weights(meta_weights)
for _ in range(inner_step):
with tf.GradientTape() as tape:
logits = self.meta_model(support_image, training=True)
loss = losses.sparse_categorical_crossentropy(support_label, logits)
loss = tf.reduce_mean(loss)
acc = tf.cast(tf.argmax(logits, axis=-1, output_type=tf.int32) == support_label, tf.float32)
acc = tf.reduce_mean(acc)
grads = tape.gradient(loss, self.meta_model.trainable_variables)
inner_optimizer.apply_gradients(zip(grads, self.meta_model.trainable_variables))
# 每次经过inner loop更新过后的weights都需要保存一次,保证这个weights后面outer loop训练的是同一个task
task_weights.append(self.meta_model.get_weights())
with tf.GradientTape() as tape:
for i, (query_image, query_label) in enumerate(zip(meta_query_image, meta_query_label)):
# 载入每个task weights进行前向传播
self.meta_model.set_weights(task_weights[i])
logits = self.meta_model(query_image, training=True)
loss = losses.sparse_categorical_crossentropy(query_label, logits)
loss = tf.reduce_mean(loss)
batch_loss.append(loss)
acc = tf.cast(tf.argmax(logits, axis=-1) == query_label, tf.float32)
acc = tf.reduce_mean(acc)
batch_acc.append(acc)
mean_acc = tf.reduce_mean(batch_acc)
mean_loss = tf.reduce_mean(batch_loss)
# 无论是否更新,都需要载入最开始的权重进行更新,防止val阶段改变了原本的权重
self.meta_model.set_weights(meta_weights)
if outer_optimizer:
grads = tape.gradient(mean_loss, self.meta_model.trainable_variables)
outer_optimizer.apply_gradients(zip(grads, self.meta_model.trainable_variables))
return mean_loss, mean_acc
四、论文作者源码
- 原作者TF1实现版本
- Keras实现版本
五、MAML存在的问题
MAML本身存在一些问题被发表在How to train your MAML中。