【深度学习】万字综述:用于深度神经网络加速的Shift操作
作者丨科技猛兽
编辑丨极市平台
导读
如何同时满足减少可学习参数的数量以及维持computation/memory access比值?你需要Shift操作。本文将详细介绍shift操作的具体方法、如何剪掉冗余的Shift操作、3种用于深度神经网络加速的Shift操作、如何利用bit-wise的Shift操作避免乘法运算以及如何将Shift的思想应用到加法网络中。
在之前的文章中,我们详细介绍了模型压缩中的Slimming操作以及高效模型设计的自动机器学习流水线,本文将非常全面的介绍模型压缩的另一种操作:Shift。
目录
我们为什么需要Shift操作?
论述shift操作的诞生背景。
如何进行Shift操作?
论述shift操作的具体方法。
稀疏的Shift操作
论述如何剪掉冗余的Shift操作。
给深度神经网络加速的Shift操作
详细讲解3种用于深度神经网络加速的Shift操作。
再进一步的bit-wise的Shift操作, 走向无乘法的神经网络
讲解如何利用bit-wise的Shift操作避免乘法运算。
"移位"Shift操作与加法网络结合,打造适用于边缘设备的ShiftAddNet
讲解如何将Shift的思想应用到加法网络中。
参考文献
1 我们为什么需要Shift操作?
端侧设备(手机,各种可穿戴设备,自动驾驶,智能机器人等)的功率较低,内存受限。而且,内存之间的通信和计算量也对CNN的功耗有很大的影响。除此之外,如果设备需要和云通信的话(模型更新等),模型的大小也会极大地影响成本。所以,对于端侧设备和物联网设备的推理过程(Inference)来讲,模型的优化,尺寸的缩减,速度的提升和功耗的节约是研究的重点。
CNN主要依赖卷积 (Spatial Convolution) 来聚合图像中的空间信息。在神经网络中,卷积核是卷积操作最核心的部分,它也叫滤波器,接收这一层的输入Input,计算出这一层的输出Output。卷积网络计算密集,且模型变大的原因是卷积核引入了高强度的计算量,且使模型参数量急剧上升。在这样的背景下,研究者们设法减少卷积核的大小,进而减少模型的计算量和参数量。其中比较著名的是Depthwise Seperable Convolution,即深度可分离卷积。如下图所示,图中对比了深度可分离卷积和常规卷积操作的不同:
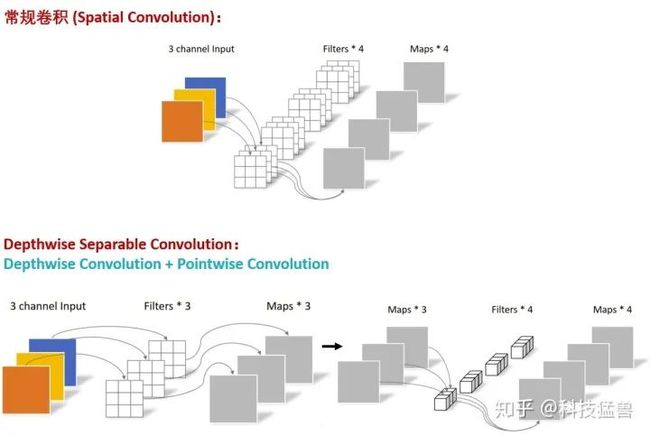
计算下常规卷积和深度可分离卷积的计算量和参数量:
假设输入张量 ,其中 代表特征的height和width, 代表特征的channel数。
假设卷积核 ,其中 代表卷积核的kernel size, 分别代表输入特征和输出特征的channel数。
假设输出张量 ,其中 代表特征的height和width(这里假设输入输出的大小一致), 代表特征的channel数。
1 普通卷积的表达式可以写作:
其中 为输入的第 个channel的第 个元素。
常规卷积的计算量:
常规卷积核的参数量:
输入特征和输出特征的参数量之和:
所以,常规卷积的computation/memory access:
这里需要着重强调的是computation/memory access,这个值反映了模型计算量与内存大小的比值,比值越大,代表我们把更多的资源倾向于计算,而不是内存访问上;比值越小,则代表我们把更多的资源倾向于内存的访问 (memory access),而这个过程相比计算要耗费更多的能量和更多的时间,使模型延迟 (Latency)上升严重。 这个缺点意味着I/O密集型设备 (I/O-bound device)将无法实现最大的计算效率。
注:关于I/O密集型设备 (I/O-bound device)和计算密集型设备 (CPU-bound device):意思是计算机在处理某个任务的时候,主要时间花在什么地方,就是被什么所“束缚”。比如主要时间消耗在CPU计算上,也就是说处理该任务大部分时间都在等待CPU的计算而不是等待读写(硬盘/内存)数据,那么就是CPU-bound,称之为CPU密集型。反过来如果主要时间消耗在等待读写数据而CPU利用率很低,那么该任务就是I/O-bound,I/O密集型。
CPU bound的程序一般而言CPU占用率相当高。这可能是因为任务本身不太需要访问I/O设备,也可能是因为程序是多线程实现因此屏蔽掉了等待I/O的时间。
I/O bound 指的是系统的CPU效能相对硬盘/内存的效能要好很多,此时,系统运作,大部分的状况是 CPU 在等 I/O (硬盘/内存) 的读/写,此时 CPU Loading 不高。
根据以上的注释,我们希望computation/memory access这个值尽量大,以更有效率地利用我们的硬件资源。
2 深度可分离卷积的表达式可以写作:
Depthwise Convolution:
式中, 代表Depthwise Convolution的卷积核。
Pointwise Convolution:
式中, 代表Pointwise Convolution的卷积核。
Depthwise Convolution的计算量:
Depthwise Convolution卷积核的参数量:
输入特征和输出特征的参数量之和:
所以,Depthwise Convolution的computation vs. memory access:
Depthwise Convolution的计算量/内存占用的比值相比于常规卷积小很多,这意味着Depthwise Convolution将更多的时间花费在内存访问上,这比浮点运算慢好几个数量级,并且更消耗能量。这个缺点意味着I/O密集型设备将无法实现最大的计算效率,使之不容易在硬件设备上实现。
问:为什么更轻量化的深度可分离卷积反而不利于实现最大的计算效率?
答:因为其内部的Depthwise Convolution的computation/memory access这个比值太低了,换句话说,同样的参数,没有带来同比的计算量。
所以,我们希望有一种操作,能够:
减少可学习参数 (learnable parameters)的数量。
维持computation/memory access这个比值不变小。
Shift操作因此诞生。它的最大特点是:requires zero FLOPs and zero parameters。这个特点能够同时满足上面的2个要求。这样,Shift操作维持了computation/memory access这个比值,从而能够很容易地在硬件设备上实现。
同时,Shift操作与其他的模型压缩方法是正交 (orthogonal)的,即Shift操作可以与其他的压缩方法联合使用。
A和B是正交 (orthogonal)的意思是:使用A方法,不妨碍B方法的使用,换句话说,A和B可以同时使用。
2 如何进行Shift操作?
原文链接:CVPR2018:Shift: A Zero FLOP, Zero Parameter Alternative to Spatial Convolutions
Shift操作可以看做是Depthwise Convolution的一种特殊情况,表达式为:
式中,shift operation的卷积核 的定义为:
这里,你会发现Shift操作与Depthwise Convolution的不同之处在于Shift操作的卷积核的每一个channel中的卷积核 中的 个值,只有一个是1,其他都是0。这里的 是个索引,告诉我们位于 处的这个值为1,其他 个值为0。
这一步做完以后,和Depthwise Convolution一样,我们在后面接上pointwise convolution来进一步融合channel之间的信息。下图1是Shift操作与常规卷积和深度可分离卷积的对比,图2是做完Shift操作以后,进一步在后面融合pointwise convolution。
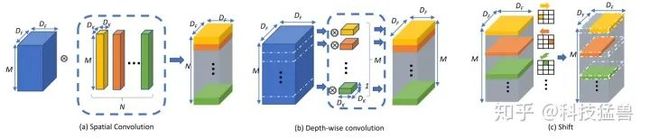
图1:Shift操作与常规卷积和深度可分离卷积的对比
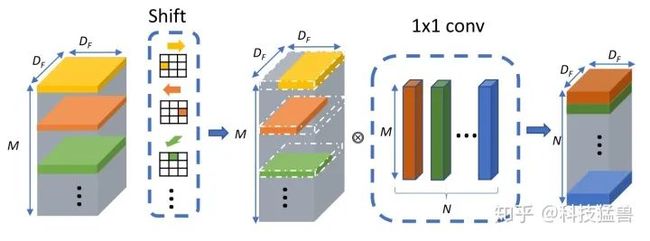
图2:Shift操作在空间上调整数据,1×1卷积在通道间混合信息。
我们发现,如下图3所示,shift卷积过程相当于将原输入的矩阵在某个方向进行平移,如图3所示。这也是为什么该操作称之为shift的原因。虽然简单的平移操作似乎没有提取到空间信息,但是考虑到我们之前说到的,通道域是空间域信息的层次化扩散。因此通过设置不同方向的shift卷积核,可以将输入张量不同通道进行平移,随后配合1x1卷积实现跨通道的信息融合,即可实现空间域和通道域的信息提取。
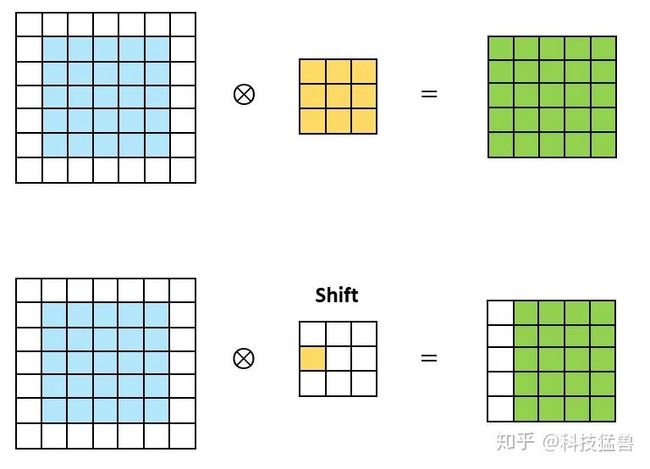
图3:shift卷积相当于将原输入矩阵在某个方向进行平移
如何构建Shift的卷积核?
一个卷积核在每一个channel上面有 种可能的shift directions,再假设有 个channel,所以共有 种可能的shift选择。显然,在这样的空间里暴力搜索出最适合的shift选择是不现实的。所以作者使用了近似的手段,即:把这 个channel分成 组,我们将每个组称之为平移组(shift group)。那么每组的 个channel使用相同的shift选择,采用相同的平移方向。当然,有可能存在除不尽的情况,这个时候将会有一些通道不能被划分到任意一个组内,这些剩下的通道都称之为“居中”组对输入按通道数进行分组, 每一组通道只往一个方向平移。
举个例子哈,比如现在卷积核是 的,然后一共有64个channel,按照上面的做法我们把这些channel分成9组,每组7个channel,剩下的一个channel不做shift操作。
那么下面的问题是:如何把每个channel正确地划分到对应的组里面?
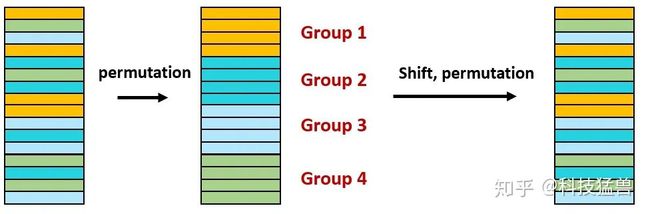
图4:如何把每个channel正确地划分到对应的组里面?
虽然通过这种手段大大缩小了搜索空间,但是仍然需要让模型学出如何将第 个通道映射到第 个平移组的最佳排列规则,这仍然是一个很大的搜索空间。为了解决这个问题,以下需要提出一种方法,其能够使得shift卷积层的输出和输入是关于通道排序无关的。
具体来讲,比如现在输入的通道如图4左侧图所示,相同颜色的通道应该归为一组 (此时是最优情况),但是现在我其实是事先告诉你哪些通道应该归为一组,即颜色应该相同。其实你事先是不知道的,即:我们不知道具体哪些通道的颜色是相同的,也就是说,我们不知道具体哪些通道应该归为一组。这时,为了解决这个问题,我们想先通过一个排序 (permutation),使得4个应该分到group 1的channel排到最上面,把4个应该分到group 2的channel排到5-8位置。这样,我们就可以直接把最上面的4个通道归为group 1,再下面的4个通道归为group 2,再下面的4个通道归为group 3,以此类推。shift进行完后,再通过一个排序恢复原来的channel的顺序。但是这样做排序 (permutation)是未知的,我们的目的就是关于通道排序无关的。
假设 表示是在以 为通道排序的shift卷积操作,则上式(2.1)可以表示为 ,如果我们在进行该卷积之前,先后进行两次通道排序,分别是 和 ,那么我们有:
其中 表示算子组合。
上式的意思是:输入特征 先经过一个排序 ,再经过Shift操作 ,再经过一个排序 。
那么,如上文所述,排序 都是未知的。怎么解决这个问题?
问:可不可以不用知道排序 是什么?
答:可以的。只需要在头和尾加上 卷积即可。为什么?
令 和 分别表示1x1卷积操作,我们有式子(2.4):

这一点不难理解,即便对1x1卷积的输入进行通道排序重组,在学习过程中,通过算法去调整 卷积的参数的顺序,就可以通过构造的方式,实现 和 之间的双射(bijective)。如式子(2.5)所示,就结论而言,不需要考虑通道的排序,比如只需要依次按着顺序赋值某个平移组,使得其不重复即可。通过用 卷积“三明治”夹着shift卷积的操作,从理论上可以等价于其他任何形式的通道排序后的结果。
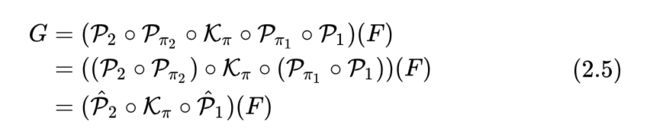
这样我们就有效地避开了排序 的求解。那么接下来,根据shift算子构建出来的卷积模块如下图所示:
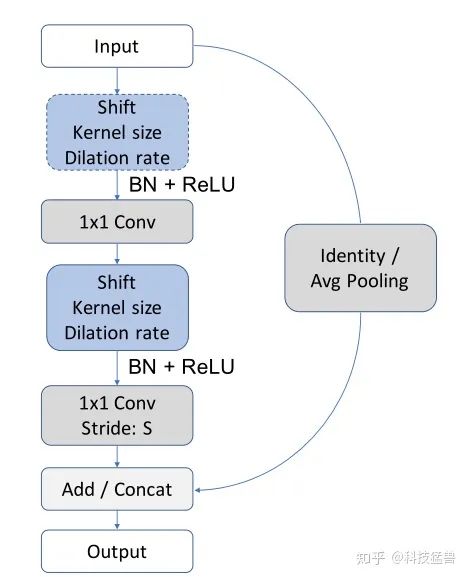
图5:基于shift卷积算子构建的ResNet网络基本模块。
如上图5所示为一个基于Shift操作的模块,先忽略虚线部分,首先输入经过一个pointwise convolution,融合channel维度的信息。然后,是带有Shift操作的卷积核重新分配spatial维度的信息,最后再经过一个pointwise convolution,融合channel维度的信息。这样就形成了1x1 conv -> shift kernel -> 1x1 conv的结构。所有的pointwise convolution前面都会加上BN和ReLU激活函数。与此同时,为了形成残差结构,模块还添加了Identity块,如果输入输出的shape是一样的,就直接使用残差即可;如果输入输出的shape是不一样的,就结合downsampling。
蓝色虚线块的Shift块是实验补充的一个设计,存在虚线部分的shift块的设计称之为 结构,只存在实线部分的设计则称之为 结构,它可以在下采样之前就结合spatial information。
同时,也使用了expansion rate来控制中间层的channel数,因为 卷积计算密集,使得中间层的channel数不能过大。但是使用了Shift操作之后,因为卷积核得到了调整,就可以使中间层的channel数更大。
实验结果:
ShiftResNet的构建是通过把ResNet里面所有的basic module (2个3×3卷积) 替换为图5的 结构。下图6为若我们把ResNet56网络使用Shift操作,并通过调节expansion rate使参数量降低约3倍时的结果,我们发现模型的Accuracy基本没有变化。
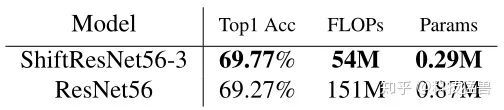
图6:Shift操作使得参数量降低约3倍
下图7展示了3个模型 (ResNet20,ResNet56,ResNet110)的不同参数量 (expansion rate=1,3,6,9)时在2个数据集 (CIFAR-10,CIFAR-100)上的实验结果。Shift算子的确在计算量和参数量上有着比较大的优势。比如说当我们控制参数量或计算量下降8倍左右时,即每组的第一行,那么常规ResNet的性能会大幅地下降,而ShiftResNet的性能下降幅度较小。
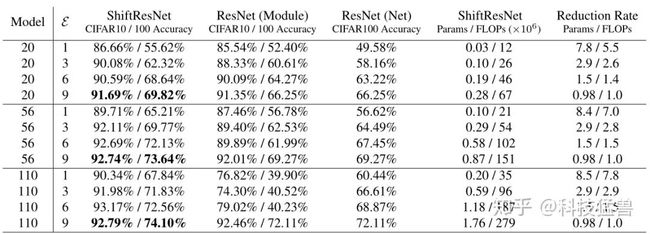
图7:不同模型使用Shift操作,在不同参数量级上的结果
如下图8所示为ShiftNet-A的结构,因为参数量并不会随着Shift kernel size的增长而变大,所以在一开始的module里面使用了比较大的卷积5×5。通过调节expansion rate 来改变每个CSC module的参数量。下图所示的结构为ShiftNet-A。若把每个CSC模块的channel数变为原来的0.5倍,即得到ShiftNet-B的结构。若在group 1,2,3,4中分别使用{1,4,4,3}个CSC module,channel数分别为{32,64,128,256},expansion rate ,kernel size为3,则得到ShiftNet-C的结构。
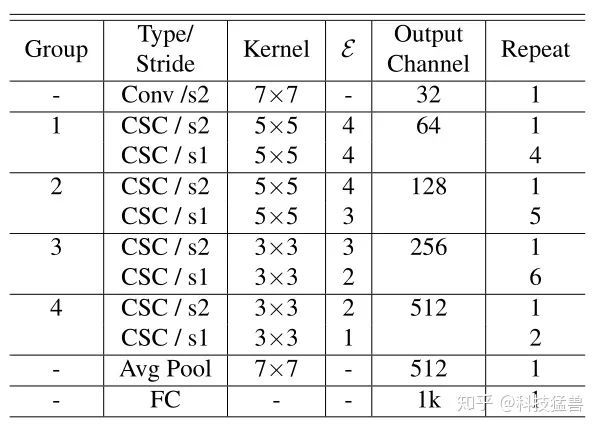
图8:ShiftNet-A的结构
下图9所示为ShiftNet的3种结构:ShiftNet-A,ShiftNet-B,ShiftNet-C与其他方法的对比,ShiftNet-A,ShiftNet-B,ShiftNet-C对比的对象为具有相似的精度 (Accuracy)的模型。结果发现,在精度相当的条件下,ShiftNet的参数量大幅减少。
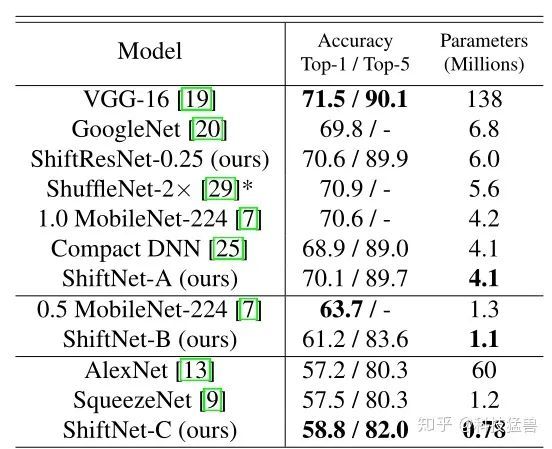
图9:ShiftNet的3种结构与其他方法的对比
下图10所示为不同的网络改造成ShiftNet之后的结果对比,结果表明,ShiftNet模型在精度和参数量/计算量之间提供了很好的trade-off。
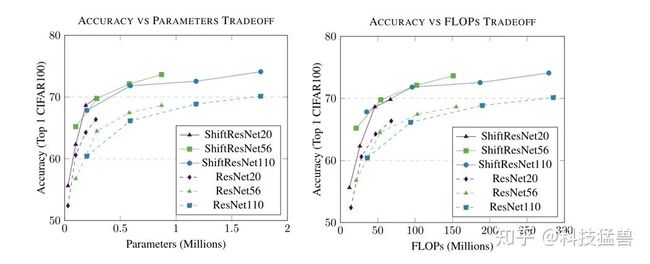
图10:ShiftNet模型在精度和参数量/计算量之间提供了很好的trade-off
3 稀疏的Shift操作
原文链接:CVPR 2019:All you need is a few shifts: Designing efficient convolutional neural networks for image classification
我们把CPU称为compute-bound computation platforms,对于这类设备来说,算力是它们的瓶颈。而GPU称为memory-bound computation platforms,对于这类设备来说,内存数据的移动等是它们的瓶颈。然后分别测试以下Shift操作和Depth-wise convolution在这两类设备上的运行时间(Runtime)的占比:结果如下图11所示。
图(a)和(b)展示了在ShiftNet(上一小节讲的模型)中,Shift操作分别在在这两类设备上的运行时间(Runtime)的占比,我们发现,Shift操作在CPU上占3.6%的运行时间,但在GPU上占28.1%,这表明由于memory movement,Shift操作在memory-bound computation platforms上仍然占据相当大的运行时间。
图(c), (d)展示了在ShiftNet中,我们仅用深度可分卷积Depthwise separable convolution代替Shift操作来测试其推理时间,得到此时的Depthwise convolution在GPU上的运行时间(Runtime)的占比。其中,图(c)为使用5×5卷积核的占比,Depthwise separable convolution占了运行时间的79.2%;图(d)为使用3×3卷积核的占比,Depthwise separable convolution占了运行时间的62.1%。
通过以上的对比即可体现出Shift操作的优越性,即:
对于memory-bound的设备来说,某种操作占用越小份额的运行时间,代表memory movement所需要的时间越短,即这种操作更有利于在memory-bound的设备中实现。

图11:Shift操作和Depth-wise convolution在这两类设备上的运行时间(Runtime)的占比
尽管Shift操作在实际运行时间上优于Depthwise separable convolution,但它的实现仍然存在瓶颈,即上文所述memory movement。这里自然就来了一个问题:
每个Shift操作真的有必要吗?
如果消除无意义的Shift操作,那些memory movement可以减少。这也就是本文的motivation。
为了抑制冗余移位操作,作者在优化过程中增加了惩罚。结果发现,一定数目的Shift操作实际上足以提供空间信息通信。作者将这种类型的移位层称为稀疏移位层(Sparse Shift Layer , SSR),如图11(e)所示,它可以显著减少Shift操作的占用时间。
具体是怎么做的呢?我们先统一下Shift操作的表达:
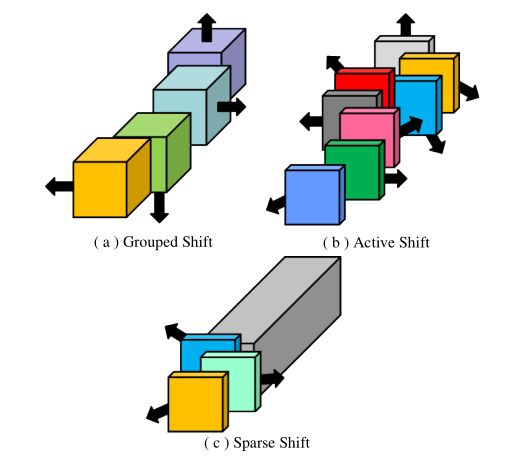
图12:不同类型的Shift操作的比较
标准的Shift操作可以表达为:
其中, 角标 表示 channel, 和 分别表示这个channel的横向和纵向的移位数。 和 的参数数量分别相当于输入特征图的通道数,与卷积层的参数相比几乎可以忽略不计。
上节提到的分组Shift操作可以表达为(图12(a)):
式中, 代表第 个channel, 代表分组数, 代表kernel size。
这样做的局限性是移位数 和 是不可学习的。
主动Shift操作:
为了使得移位数 和 可学习, 也有研究者将位移从整数放宽到实数值,并将移位操作放宽到双线性插值,以使其可微,前向传播的表达式如下所示(图12(b)):
即对于输出的每一个channel上的每个点 都会有一个neighbor set ,它包含的是 周围的4个点,之后利用这4个点的值做双线性插值。
但是,这种做法不能带来与Shift操作相同的inference speed的加速,因为插值仍然需要乘法,而标准的移位操作在推理过程中只需要存储器移动。
所以,本文方法是从减小Shift操作的数目开始, 冗余的Shift操作会带来冗余的memory movement,进一步影响神经网络的推理时间。从这一点出发,作者希望以更少的移位操作构建高效的网络。
为了避免无意义的记忆移动,我们在损失函数中加入位移惩罚来消除无用的Shift操作。具体是 使用 正则化, 以惩罚冗余的Shift操作,表达式如下:
但是,因为现在的 和 依然是实数值,所以现在依然需要解决主动Shift操作共性的问题,即利用这4个点的值做双线性插值,插值仍然需要乘法,而标准的移位操作在推理过程中只需要memory movement,所以插值会影响神经网络的推理时间。
所以,作者避开了双线性插值,而是直接把实数值的 和 作近似,如下式所示:
前向传播的表达式如下:

反向传播:
当前向传播使用Active Shift(式3.3)时,即移位数 和 是可学习的参数时,损失对移位参数的偏导数为:
式中 和 是feature map的spatial size。损失对输入特征的偏导数为: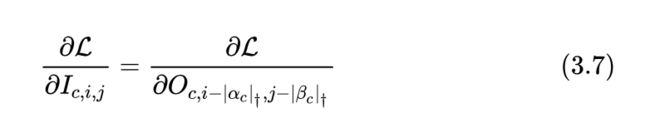
为了充分地利用每个特征,作者在每次只使用feature map的一个子集用于计算,其他的feature map直接传播到下一层,以确保信息流动,可以表示为下式:
式中, 和 分别代表输入和输出的特征, 表示channel的分离, 表示channel的concatenation。上式的意思是:先把这些输入的feature map的通道进行分离,再将一部分进行运算,另一部分直接传播;最后将得到的结果结合在一起。如下图13所示,以上操作叫做Fully-Exploited computational Block (FE-Block)。随着层数的增加,我们将更多的feature map混合到计算中。这样,每一个输入的特征最终都会被优化,得到多尺度的特征用于预测。
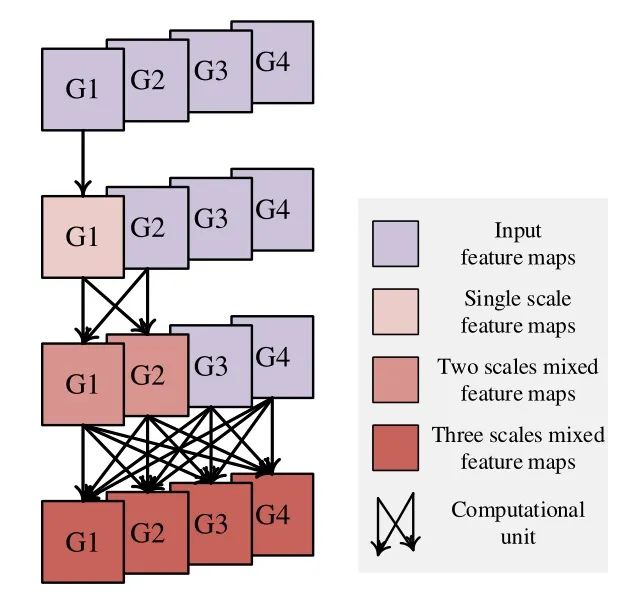
图13:Fully-Exploited computational Block (FE-Block)
其中,黑色的箭头代表基本的运算单元,如下图14所示,其中(a)和(b)分别为不带残差和带残差的运算单元,(c)为下采样的运算单元。expansion rate默认为6,即:1×1卷积先将channel数扩展为6倍。作者主要采用图14(b)作为基本计算单元。对于每个计算块(FE-Block)的最后一个计算单元,我们使用图14(a)来改变下一个计算块的信道号,或者使用图14(c)来进行空间下采样。
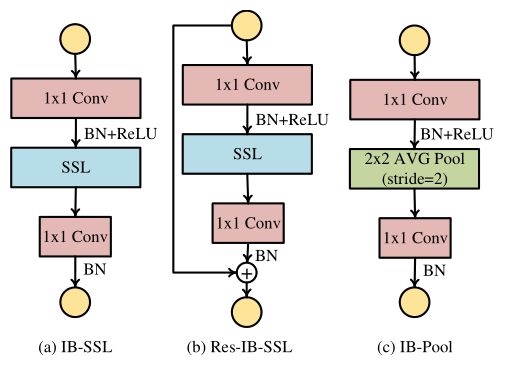
图14:FE-Block基本运算单元
实验:
数据集:CIFAR-10/100
模型:ResNet-20/56,ShiftResNet(GroupedShift)-20/56(上一小节的模型),ShiftResNet(SSL)-20/56。
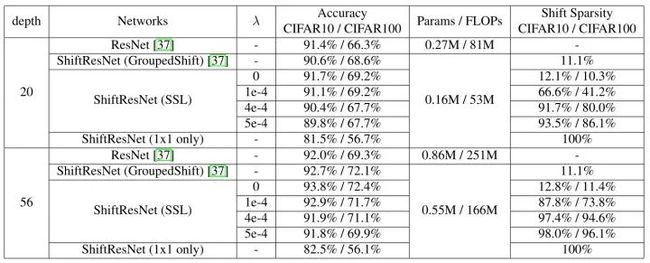
图15:The analysis of SSL on CIFAR10 and CIFAR100
其实是从3个维度上进行了比较,如图15所示:
Grouped Shift vs. Sparse Shift:
通过Shift操作,网络可以根据不同的任务和不同的数据集自适应地调整移位操作的位移和方向。通过偏移惩罚,它可以消除大部分偏移操作,同时保持网络的精度与原始网络相当。即使偏移操作的稀疏度超过90%,该网络仍能保持相当好的性能,这表明只有少量的偏移操作在传递图像分类的空间信息方面起着至关重要的作用。当稀疏度达到100%时,即不再使用Shift操作而只有1×1 convolution时,性能会有明显下降,这也证明了Shift操作的重要性。
Deep Networks vs. Shallow Networks:
当网络由20层变为56层时,Shift操作的冗余度增加了,说明增加深度会给移位层带来更多冗余。
的设置:
当 从0增大到5e-4时, 发现大部分Shift操作被逐步消除,而网络的精度略有下降。这里的( )实际上相当于量化感知的主动移位Active Shift。当我们显著地增加 ,使得稀疏度达到100%时,这意味着这些基本模块都由1×1 convolution组成,并且网络中只有3个pooling layer提供空间信息通信。在这种情况下,精度下降了很多,这从另一个方面反映了这样的几个偏移对空间信息交流真的很重要。
为了进一步分析部分Shift操作的冗余性,作者继续使用ShiftResNet-20在CIFAR-10/100上进行实验, ,结果如图16所示。作者详细展示了每一层的Shift操作的稀疏性。
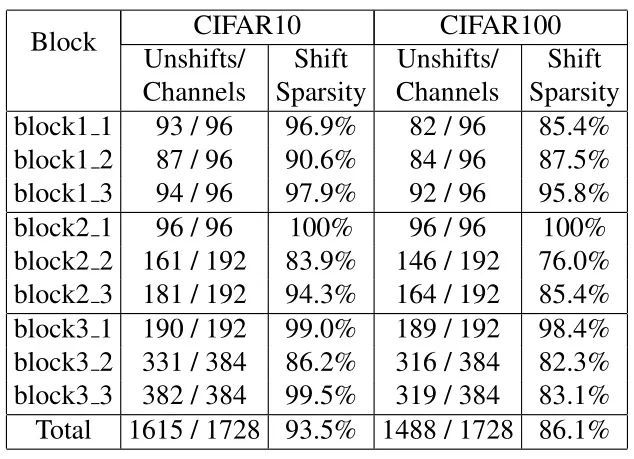
图16:CIFAR10和CIFAR100上的ShiftResNet-20 (λ = 0.0005)中各层的shift稀疏度。
解释一下表格数据的含义:Unshifts/Channels(比如93/96)这个指标是指在某个block的某层中的96个channel里面,没有进行移位操作的channel占了93个,说明这93个channel是冗余的,并不重要,那么它的稀疏度就是93/96 = 96.9%。
我们也发现,确实在所有的层中都存在着大量的冗余Shift操作,可以直接剪掉。我们将block2_2进行可视化,结果如图17所示:
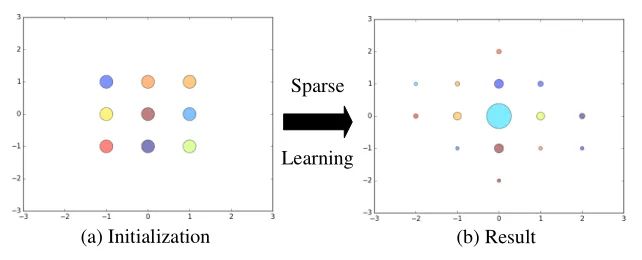
图17:在CIFAR100上从ShiftResNet-20的block2_2的偏移层中偏移值的可视化。
可以看到在所有的channel中不移位的channel是最多的,所以点也是最大的。但即使许多的channel选择不移位,剩下的移位的channel仍可以学习有意义的转换模式,并提供多个感受野。实际上,与pointwise convolution配合的移位层优于传统卷积层。
接下来作者直接粗暴地剪掉稀疏度大的layer,结果如下图18所示:
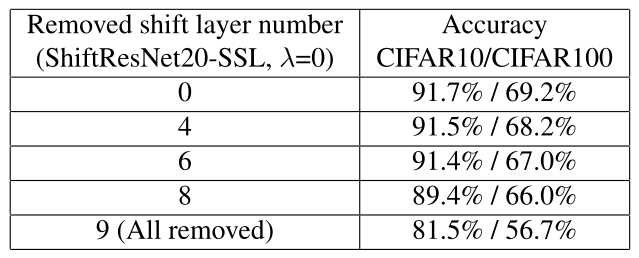
图18:在移除最不重要的偏移层后,ShiftNet-20在CIFAR10和CIFAR100上的性能。
图18为在移除最不重要的偏移层后,ShiftNet-20在CIFAR10和CIFAR100上的性能。可以看出,一共9个layer,我们一次砍掉4个,6个,甚至是只保留稀疏度最低的block 2_2,依然有89.4%/66.0%的精度。但是全部砍掉以后,精度就大幅下降。说明少量重要的Shift操作必须保留,大量冗余的Shift操作可以剪掉。
最后作者把SE 模块 (Squeeze-and-Excitation)操作融合进图14的FE-Block基本运算单元中,产生了2种新的FE-Block基本运算单元,如图19所示。
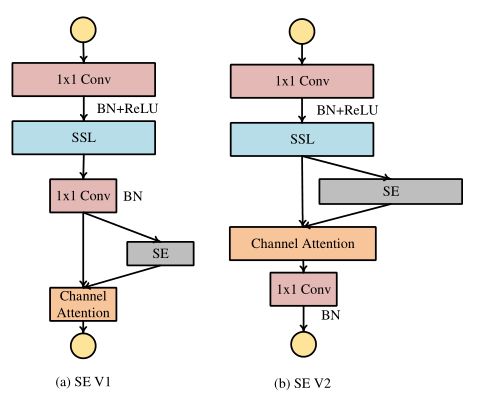
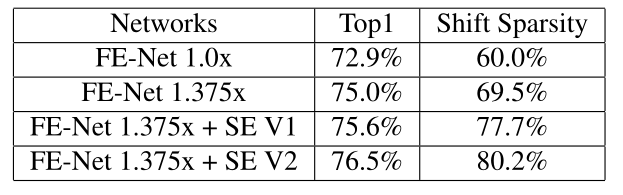
图19:SE模块的两种不同放置方式。
结果发现,将SE模块放置在 inverted bottleneck部分更为合理。表中的结果从经验上验证了这个想法。此外,我们注意到,在装备SE模块后,Shift操作的稀疏度增加了很多,这可以从另一个角度反映SE模块带来的 channel attention 的作用。
4 给深度神经网络加速的Shift操作
原文链接:WACV 2019:AddressNet: Shift-based Primitives for Efficient Convolutional Neural Networks
本文作者提出了3种基于Shift的操作:channel shift, address shift, shortcut shift来减少GPU上的推理时间,这些操作避免了内存复制(memory copy),所以很快。比如,channel shift的速度要比channel shuffle的速度快12.7倍,但能得到相同的精度。
本文所基于的出发点是:
一个神经网络,拥有较小的参数量 (params.)或计算量 (FLOPs)并不总是导致直接的神经网络推理时间 (inference time)的减少,因为这些最先进的紧凑架构 (compact architecture)引入的许多核心操作不能有效地在基于GPU的机器上实现。
我们举个例子,如下图20所示:
在MobileNet网络中,深度可分离卷积(depthwise separable convolutions)只占了总计算量的3%和总参数量的1%,但是占了总的推理时间的20%。
在ShuffleNet网络中,Channel shuffle 与 shortcut connections操作不占任何参数量和计算量,但是,推理时间却占了总的推理时间的30%。
在上文所讲到的ShiftNet网络中,特征图的 shift操作依旧是parameter-free 和 FLOP-free,但是,推理时间却占了总的推理时间的25%。
虽然MobileNet和ShuffleNet的FLOPs大致相同,但后者需要多两倍的推理时间。

图20:不同操作和模型中计算量、参数数量和推理时间的比较
所以根据上面的现象作者得到结论:无论是减少参数量或者是计算量都不能确保减少推理时间。
这也就是本文Motivation的来源,即:有哪些操作能够既减少参数和计算量,使模型达到压缩的效果,又减少推理时间,使模型达到加速的效果呢?
答:作者为GPU-based machine设计了3种Shift primitive的操作,如下图21所示:
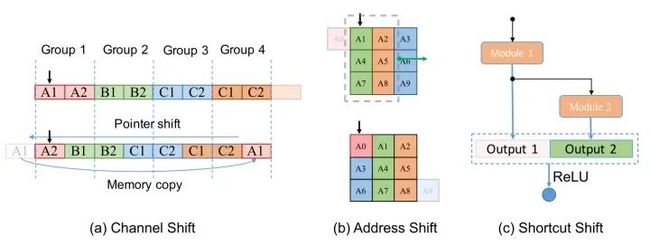
图21:用于高效神经网络架构设计的三种高效Shift primitive
(a)表示Channel Shift:用来替代Channel Shuffle的操作。
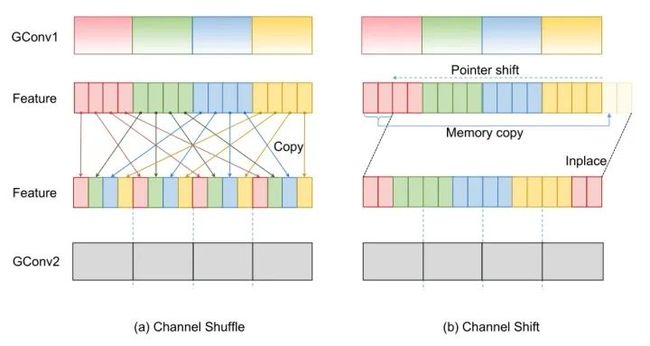
图22:具有2层卷积的Channel Shuffle和Channel Shift操作
Channel Shuffle非常耗时,因为它需要将特征映射移动到另一个存储空间。请注意,与浮点运算相比,移动数据在延迟和能耗方面要昂贵得多。相比之下,移动指针或加载数据的物理地址是free的。因此,作者提出Channel Shift Primitive来利用指针移位和最小化实际数据移动来减少时间和能量。Channel Shift 层,通道沿预定义的方向循环移位,该过程最多花费两个单位的时间来复制数据,因此memory movement比Channel Shuffle少8倍。
(b)表示Address Shift:有效收集空间信息而不消耗实际的推理时间。
Address Shift是把卷积核沿着4种不同的方向移位,以右移为例:黑色箭头指向feature map的初始地址,右移操作是指把这个地址移动一位,使它指向前面的A, 然后从地址开始在内存空间中连续取张量,相当于将整个张量右移一格。类似地,我们可以定义其他三种不同的移位操作(left,up和down)。
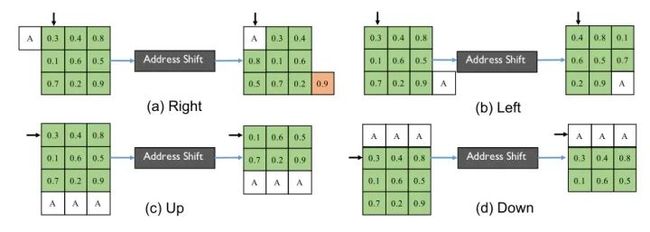
图23:实现4个方向的地址移位,其中A代表相邻要素图的值,黑色箭头表示指向feature map 的 pointer
以上过程可以抽象为下述公式:
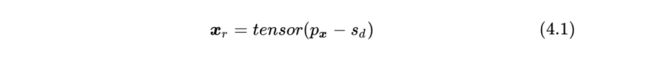
式中, 是指根据指针 读取对应的地址位置的值, 代表移位的方向。具体而言, 。

图24:Depth-wise Convolution中的右移操作
Address Shift中的右移操作(图23)与上文讲到的Shift操作中的右移操作(图24)十分相似,区别是:Shift操作中的右移操作相当于是padding的值都取为0,而Address Shift中的右移操作的boundary值非0。但是作者通过实验发现, 这种细微差别对网络的准确性没有任何明显的影响。
可能的移位方向的数量相对于kernel size成二次增长(3×3 的kernel:9个可能的方向;5x5的kernel:25个可能的方向)。但是,左上移位方向也可以分解为左移位+上移位的形式。随着信道数量的增加,配备地址移位操作的CNNs可以融合来自各个方向的所有信息。因此,我们可以只使用四个基本的移动方向来表示其他方向,以简化网络架构。
(c)表示Shortcut Shift:通过预先分配连续的存储空间来提供快速的channel concatenation以实现残差,但是不消耗推理时间。
作者通过预先分配一个固定大小的空间,将当前层的输出放在上一层的输出之后。换句话说,可以使两层的输出位于预先分配的连续存储空间中,这样就不会在channel concatenation上花费复制或计算时间。
这些操作只需要在内存空间中移动指针来实现, 以最小化实际内存移动(memory copy),完全避免浮点运算,从而能够实现推理加速。
Address-based模块:
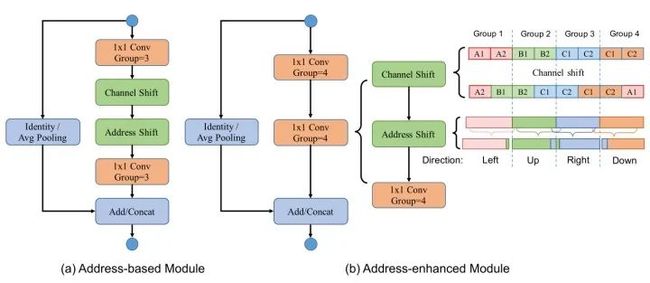
图25:Address-based模块 and Address-enhanced模块
如图25(a)所示为Address-based模块,首先通过pointwise group convolution layer,然后通过Channel Shift层融合channel之间的信息。再然后是address shift层融合spatial information,并将channel分为3组,对每一组的数据使用4种基本移位操作里的一种。最后再通过pointwise group convolution layer来匹配channel数以及融合信息。如果特征的大小是不变的,就再使用 additive residual connection,否则就使用average pooling + concatenation。
如图25(b)所示为Address-enhanced模块,它进一步把Address Shift和Channel Shift融入第2个pointwise group convolution layer,并把channel分为4组,每一组分别使用一种方向的Address Shift操作,分别是Left,Up,Right,Down。
实验:
Channel shift vs. Channel shuffle:
以上二者都可以融合网络不同的通道之间的信息,二者的性能的对比如图26所示。

图26:Channel shift vs. Channel shuffle
上图为2者在相同的参数量(Params.)和计算量(FLOPs)下的性能对比,Total Time指的是模型的平均运行时间,Operation Time指的是这个操作的平均运行时间。两种模型达到了相同的精度,但是Channel shuffle在两个指标上的提速分别达到了1.4倍和12.7倍,显示出这种操作的优越性。
Address Shift vs. Feature map Shift:
基于上面的分析,4种基本的移位操作(Left,Up,Right,Down)可以替代原本的 个操作。所以,作者将第2节中的ShiftResNet中的feature map Shift操作替换为Address Shift操作,得到的网络结构称为AddressResNet,以及只使用4种基本的移位操作替代9个操作( ),比较的结果如下图27所示。
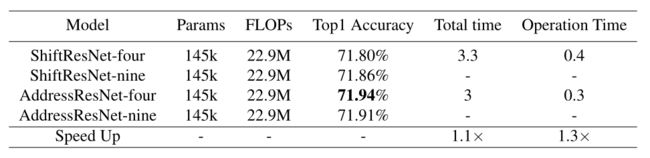
图27:Address Shift vs. Feature map Shift
第1个结果是:无论是使用4种基本的移位操作还是使用全部的9种操作,模型的性能相似。这表明基于四个基本方向的移动操作足以较好地融合空间上的信息。
第2个结果是:当将feature map Shift操作替换为Address Shift操作以后,模型实现了一定程度的加速。
下图28是AddressNet与ShiftResNet在参数量,计算量和推理时间这3个维度的对比。

图28:AddressNet与ShiftResNet在3个维度的对比
与ShiftResNet的最佳精度相比,AddressNet-44可以用少3倍的计算量和少6倍的参数量获得更好的性能。此外,图28(a)和图28(b)中的曲线表明,在不同的参数量和计算量下,AddressNet始终比移位寄存器网络获得更好的精度。在图28(c)中,AddressNet可以显著减少推理时间。
5 再进一步的"移位"Shift操作, 走向无乘法的神经网络
原文链接:Arxiv:Deepshift: Towards multiplication-less neural networks
在上面的工作里面我们是在二维空间上进行Shift的操作,目的是CNN卷积核减少参数量,进而减少整个网络的参数量和计算量。我们让卷积核的每个channel点乘一个one-hot矩阵(只有一个位置为1,其余位置为0),假设有M个channel,shift kernel的可能情况为 种,为了降低搜索空间,对M个channel分组,每个组内采用一个one-shot矩阵。相同的组使用相同的Shift操作,得到了满意的结果。
下面要讲的这篇工作将Shift操作拓展到了bit-wise,即按位进行。简而言之就是:维持Shift操作的思想,只是把它按位进行。
这个工作的思想其实是来自数字电路中乘法器的实现原理:比如说有一个整数10,我们把它用8位二进制表示为:00001010。对它做乘法时,比如乘以4,其实可以不直接相乘,而是把它按位左移2位:即:00001010→00101000。这样一来,移位实现的乘除法比直接乘除的效率高很多。
用移位实现乘除法运算:
a=a×16;
b=b÷16;
可以改为:
a=a<<4;
b=b>>4;
说明:
除2 = 右移1位 乘2 = 左移1位
除4 = 右移2位 乘4 = 左移2位
除8 = 右移3位 乘8 = 左移3位 通常如果需要乘以或除以2的n次方,都可以用移位的方法代替。大部分的C编译器,用移位的方法得到代码比调用乘除法子程序生成的代码效率高。实际上,只要是乘以或除以一个整数,均可以用移位的方法得到结果,如:
分析 可以拆成 ,因此为:
再如:
分析 可以拆成 ,因此为:
。
问:上面我们其实是做了一件什么事情?
答:我们总结了这样一个结论,即:原数任意乘以一个数其实可以通过原数的移位操作和加法操作来实现,而不需要直接相乘。且用移位的方法比调用乘除法子程序的计算量低很多。
上面这句话就是这个工作的核心思想,现在我们把它推广到神经网络里面,看看能为我们优化网络,减少运算带来哪些有益的启发。
上面介绍的移位操作使用公式可以表达为:
我们定义一个移位矩阵Shift matrix ,代表每个元素的 值,为整数(integer)。式中 是整数(integer)或定点数(fixed-point)格式。
这里简单讲解下什么是定点数(fixed-point):
定点数(fixed-point number)就是小数点位置固定的数,也就是说,小数点后面的位数是固定的,比如要记录一笔账目,这些账目的数字都不会超过100,就可以使用2位小数位定点数来记录,比如99.99,2.30,75.28;如果要更精确,可以使用3位小数位的定点数来记录,比如7.668,38.235。存储方式:
第1种方式是对每一个十进制数进行BCD编码(BCD码(Binary-Coded Decimal),用4位二进制数来表示1位十进制数中的0~9这10个数码,是一种二进制的数字编码形式,用二进制编码的十进制代码),然后加上一个额外的符号位,0表示正数,1表示负数。由于需要使用整数个字节数来存储定点数,所以依据不同情形,符号位可能使用4bit编码,也可能使用8bit编码。如果用4bit编码符号位,加上数值位的bit数刚好是整数字节,那么就用4bit编码编码符号位,否则就用8bit编码符号位。比如,对-9.99编码,由于使用BCD编码9.99需要1.5字节,那么使用4bit编码符号位刚好就可以凑成2字节,编码结果如下:0001 1001 1001 1001;如果对-99.99编码,由于使用BCD编码99.99刚好是2字节,那么对符号位就使用8bit编码,编码结果如下:0000 0001 1001 1001 1001 1001(蓝色部分表示符号位编码,红色部分表示数值位编码)。第2种方式是有一个定点小数的规范。假设机器字长8 bits,我们规定从左至右,第一位为符号位,接着后5位表示定点小数的整数部分,后两位表示定点小数的小数部分。那么26.5的实际存储形式为01101010。这种情况是可以进行移位的操作的。
注意对定点数的编码,不需要对小数点位置进行编码,因为小数点位置是固定的(对同一定点数表示方式来说)。
优缺点:
定点数的优点就是可以精确表示想要表示的数值,不会像浮点数一样计算机内部无法精确的表示一些数值,比如要表示[0,100)之间的任何两位小数,定点数都能精确表示;
定点数的缺点就是不适用于表示特别大或者特别小的数值,比如要表示[0.00000000026,490000000000)之间的任何11位小数,那么就需要使用的字节高达12个(算上符号位)。
在神经网络中,要成的权重也可能为负值,所以再定义取负操作 (sign flip):
我们定义一个符号矩阵Shift matrix ,代表每个元素的符号变化,即是否进行取负操作 。
这样,不论是神经网络的卷积层: 亦或是全连接层: ,我们都可以把乘法运算的过程用下式来表示:
那么,我们通过上述简单的变换就把神经网络的乘法操作转换为了移位操作和加法操作。把训练神经网络的权重的问题转化为了训练移位矩阵Shift matrix和符号矩阵Shift matrix的问题。如下图29所示:
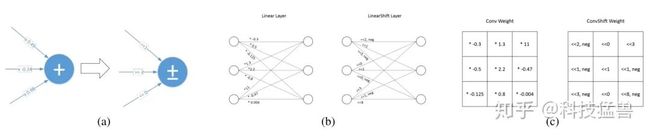
图29:神经网络的乘法操作转换为了移位操作和加法操作
问:如何训练移位矩阵Shift matrix和符号矩阵Shift matrix呢?
答:DeepShift-Q 和DeepShift-PS方法。
DeepShift-Q方法:
假设现在有权重 ,我们先把它进行量化得到 ,具体的量化方法是:把它近似为离它最近的2的N次幂。
这里举个例子,比如 ,则经过上面的计算有: 。
这样,我们再定义LinearShift operator:
和ConvShift operator:
LinearShift的反向传播过程可以计算为:
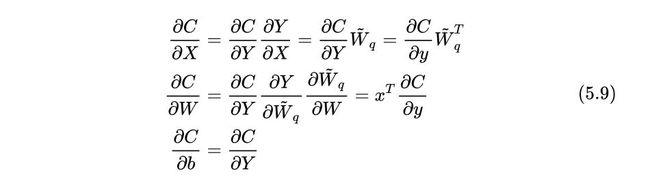
式中, 为损失函数对输出的偏导数; 是损失函数对权重的偏导数。
因为 是 的近似值,所以我们取:
所以, 可化简为:
ConvShift的反向传播过程可以计算为:
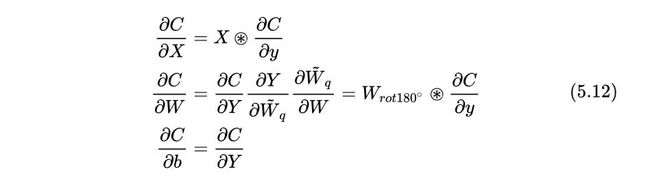
这样,有了前向传播的方法(5.7-5.8)和反向传播的方法(5.9-5.12),我们就可以正常完成网络的训练过程,如下图30所示:
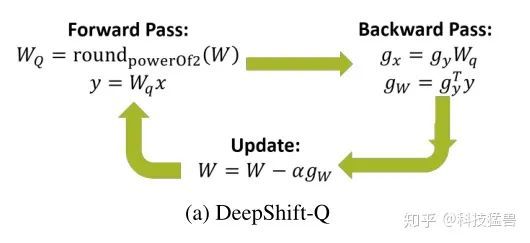
图30:DeepShift-Q方法网络的训练过程
DeepShift-PS方法:
DeepShift-PS方法直接把移位矩阵Shift matrix 和符号矩阵Shift matrix 作为可训练的参数,按照上面的公式,前向传播的过程和权重的定义是相同的:
矩阵 中的每个元素: