一文弄懂交叉熵损失
引言
今天来好好地捋一捋交叉熵损失(Cross Entropy Loss)。
从信息熵入手,再到极大似然估计,然后引入KL散度,最后来看KL散度与交叉熵的关系。
虽然文章有点长,但相信看完本文,你一定会对交叉熵损失有更高一层的领悟。
信息熵
信息的价值在于消除事件的不确定性,那事件的不确定性要怎么度量呢?答案就是信息熵(information entropy)。
比如你告诉别人你中了500万彩票,别人会大吃一惊,因为他被消除了大量的不确定性。但如果你告诉别人你没中彩票,别人基本熵没有反应,因为他估计你这小子十有八九不会中彩票。相当于你几乎没有消除他对你没有中彩票这件事的不确定性。或者说你传达的信息量太少。我们知道概率只能在0到1之间,也就是说,最好在概率为1的时候,信息量为0,且概率越小,信息量越大。后来人们发现,对数函数很符合这样的规律,某个事件的信息量与概率的关系是 i = log ( 1 p ) i = \log(\frac{1}{p}) i=log(p1),这里的对数是以2为底的, p p p是事件发生的概率。
上面最后这个式子是怎么来的呢?以抛硬币游戏为例,如果有一枚理想的硬币,其出现正面和反面的概率相等,假设我们相隔很远,只能通过电位信号(0或1)进行交流,如何把这个硬币的结果告诉我呢。显然,此时只需要发送一个信号就可以,用1表示正面,用0表示反面。信息的价值在于消除事件的不确定性,传递一枚硬币结果的信息,帮我们消除了它是哪一个面的不确定性。
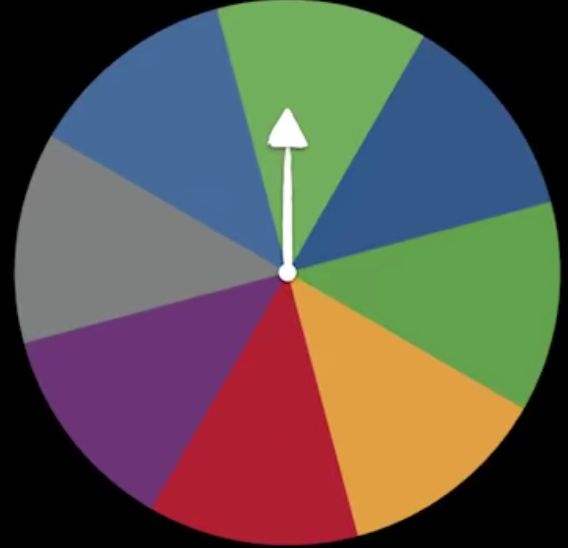
我们再来看一个转盘游戏,这个转盘被均等地分为8个区域,如果我们要把转盘的结果发送出去,那么需要多少个信号呢?答案是3个信号。
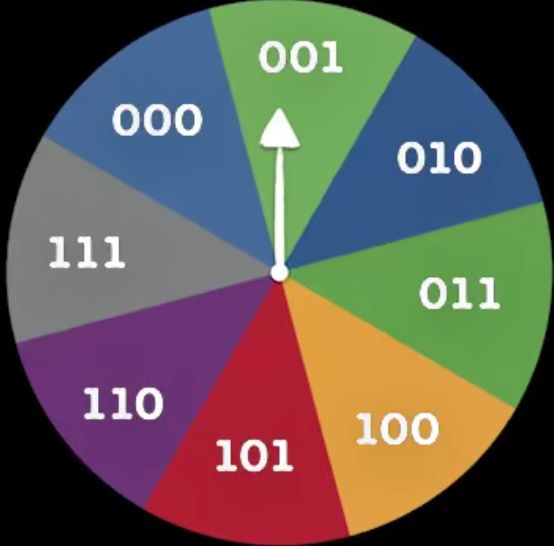
在这两个例子中,我们发现一件事情,把一个游戏系统中所有可能出现的等概率事件数量取以2为底的对数,就是我们要传递事件结果所需要的信号数量。比如在抛硬币游戏中是 log 2 ( 2 ) = 1 \log_2(2)=1 log2(2)=1,在转盘游戏中是 log 2 ( 8 ) = 3 \log_2(8)=3 log2(8)=3。这个数量就是信息量。
即 信息量 = log ( N ) \text{信息量}=\log(N) 信息量=log(N),这里的 N N N是等可能事件数量。
可以把这种度量不确定性的信息量称为信息熵,但严格来说这并不是香农所说的信息熵,这只是信息熵的一个特例,即所有的事件是等可能的。我们遇到的更多情况是事件发生的可能性不一样的系统。 比如现实生活中就无法制作出来正反面概率都是50%的硬币。
实际上,我们总是可以把一个事件的概率值转换为一个等可能事件系统中发生某个事件的概率。举例来说,我们总是可以把一个概率值转换为“在N个球中随机摸一个球”这个等可能事件系统中摸出某个球的概率。
假设中彩票大奖的概率很低,只有两千万分之一,我们可以把这个概率值转换为在两千万个球中摸出中奖球的概率。在这个摸球系统中,就有两千万个等可能事件。所以只需要用1除以概率值就可以想象出等可能事件系统中事件等数量,即 N = 1 p N=\frac{1}{p} N=p1。
假设我们有一个动了手脚的不均匀硬币,它正面朝上的概率是0.8,反面朝上的概率是0.2。

如上图,反面朝上0.2的概率可以想象有5个球的摸球系统中摸出某个球的概率。

而正面朝上0.8的概率可以想象成在有1.25个球的系统中摸出某个球的概率。我们通过想象把一个非等概率事件的系统拆成了两个等概率事件的系统。
而面对等概率事件系统,我们就可以很容易地计算它们的信息量。再把这两个想象出来的摸球系统的信息量加起来,就是这个不均匀硬币的信息量: log 5 + log 1.25 \log 5 + \log 1.25 log5+log1.25,由于这两个我们想象出来的等概率系统本身出现的概率也不一样,因此我们需要分别乘上它们出现的概率,得 0.2 ⋅ log 5 + 0.8 ⋅ log 1.25 0.2 \cdot \log 5 + 0.8 \cdot \log 1.25 0.2⋅log5+0.8⋅log1.25。
如果我们用符号去抽象这些具体的值,就是
p 1 ⋅ log 1 p 1 + p 2 ⋅ log 1 p 2 (1) p_1 \cdot \log \frac{1}{p_1} + p_2 \cdot \log \frac{1}{p_2} \tag{1} p1⋅logp11+p2⋅logp21(1)
对于有更多事件的一般情况,我们可以这么表示:
∑ i p i log 1 p i (2) \sum_i p_i \log \frac{1}{p_i} \tag{2} i∑pilogpi1(2)
我们整理下这个式子
∑ i p i log 1 p i = ∑ i ( p i ⋅ ( log 1 − log p i ) ) = ∑ i − p i log p i = − ∑ i p i log p i (3) \begin{aligned} \sum_i p_i \log \frac{1}{p_i} &= \sum_i (p_i \cdot (\log1 - \log p_i)) \\ &= \sum_i - p_i \log p_i \\ &= - \sum_i p_i \log p_i \end{aligned} \tag{3} i∑pilogpi1=i∑(pi⋅(log1−logpi))=i∑−pilogpi=−i∑pilogpi(3)
就得到了香农所提出的信息熵公式 − ∑ i p i log p i -\sum_i p_i \log p_i −∑ipilogpi
我们可以看出,信息熵实际熵就是我们给每个概率值想象出来的某球系统的信息量的平均值,或者说是信息量的期望。
如果我们要比较两个概率模型的距离,最简单的办法就是把它们的信息熵都算出来,直接比较两个结果就好了。但是问题是,在机器学习中,我们往往不知道训练样本的概率模型。此时呢,我们就需要用到相对熵,也称为KL散度(KL Divergence)。
但是在这之前,为了知识的完整性,我们需要了解极大似然估计的概念。
极大似然估计
极大似然估计里面有三个概念,极大、似然和估计。通俗来说,就是用已知的样本结果信息,去反推最有可能导致这些样本结果出现的模型参数值。
反推说的是一种推理、估计,我们无法保证完全能从已知样本去推出产生这些样本的概率分布,只能说是一种估计。似然值说的是,真实样本已经看到,假设有很多(概率)模型,每个模型产生这些真实样本的可能性就叫似然值。极大似然估计就是选择似然值最高的模型来估计真实(概率)模型。
还是以抛硬币为例,我们记硬币的正面为H(Head),反面为T(Tail)。
假设我们不知道这个硬币产生正反面的概率,但是我们可以做10次实验,假设产生这样一组结果:HHHHHHHTTT。即前7次是正面,后3次是反面。
假设有三个产生这组结果的模型(概率分布),
- 模型A产生正面的概率 p = 0.1 p=0.1 p=0.1,产生反面的概率就是 1 − p = 0.9 1-p=0.9 1−p=0.9
- 模型B产生正面的概率 p = 0.7 p=0.7 p=0.7,产生反面的概率是 1 − p = 0.3 1-p=0.3 1−p=0.3
- 模型 C C C产生正面的概率 p = 0.8 p=0.8 p=0.8,产生反面的概率是 1 − p = 0.2 1-p=0.2 1−p=0.2
计算某个概率模型产生这组结果的可能性是可以计算出来的,公式为:
P ( C 1 , C 2 , ⋯ , C 10 ∣ θ ) = ∏ i = 1 10 P ( C i ∣ θ ) (4) P(C_1,C_2,\cdots,C_{10}|\theta) = \prod_{i=1}^{10} P(C_i|\theta) \tag{4} P(C1,C2,⋯,C10∣θ)=i=1∏10P(Ci∣θ)(4)
其中 C i ∈ { 0 , 1 } C_i \in \{0,1\} Ci∈{ 0,1}是第 i i i次抛硬币的结果,整个式子说的是由参数 θ \theta θ确定的模型同时发生 C 1 , C 2 , ⋯ , C 10 C_1,C_2,\cdots,C_{10} C1,C2,⋯,C10的概率。
同时发生就是连乘。
这样的可能性就叫似然值。
因此我们只需要计算每个模型的似然值,然后选择似然值最大的模型来估计真实模型。
模型 A A A的似然值: 0. 1 7 0. 9 3 ≈ 7.29 e − 08 0.1^70.9^3 \approx 7.29e-08 0.170.93≈7.29e−08
模型 B B B的似然值: 0. 7 7 0. 3 3 ≈ 0.00222 0.7^70.3^3\approx 0.00222 0.770.33≈0.00222
模型 C C C的似然值: 0. 1 7 0. 9 3 ≈ 0.00168 0.1^70.9^3\approx 0.00168 0.170.93≈0.00168
挑出似然值最大的模型就叫最大似然估计法。
极大似然法
我们从极大似然估计的角度来看一下损失函数的选择。
以上图为例,把一些图片,输入到神经网络,神经网络会输出这张图片是猫的可能性。假设这些图片是训练数据,我们已经这些图片是否是猫。
在抛硬币中,我们通过 θ \theta θ来表示参数,在神经网络这里可以具体地用 W , b W,b W,b来表示。
即可以写成:
P ( x 1 , x 2 , x 3 , ⋯ , x n ∣ W , b ) (5) P(x_1,x_2,x_3,\cdots,x_n|W,b) \tag{5} P(x1,x2,x3,⋯,xn∣W,b)(5)
n n n这些图片的个数; x i ∈ { 0 , 1 } x_i \in \{0,1\} xi∈{ 0,1}代表输入的这张图片是否为猫, 1 1 1代表是猫。
这样我们也可以把上式改成连乘的形式:
P ( x 1 , x 2 , x 3 , ⋯ , x n ∣ W , b ) = ∏ i = 1 n P ( x i ∣ W , b ) (6) P(x_1,x_2,x_3,\cdots,x_n|W,b) =\prod_{i=1}^n P(x_i|W,b) \tag{6} P(x1,x2,x3,⋯,xn∣W,b)=i=1∏nP(xi∣W,b)(6)
我们就可以得到基于这些图片的模型的似然值,我们要找到使得这个似然值最大的 W , b W,b W,b。
但是 W , b W,b W,b是一个确定的值,而我们知道神经网络可以看成是由 W , b W,b W,b这组参数确定的一个函数,该函数的输出结果 y i y_i yi表示输入图片 x i x_i xi是猫的可能性有多大,即 y i = N N W , b ( x i ) y_i = NN_{W,b}(x_i) yi=NNW,b(xi)。这里我们就可以用可能性 y i y_i yi来替代上面的参数 W , b W,b W,b:
P ( x 1 , x 2 , x 3 , ⋯ , x n ∣ W , b ) = ∏ i = 1 n P ( x i ∣ y i ) (7) P(x_1,x_2,x_3,\cdots,x_n|W,b) =\prod_{i=1}^n P(x_i|y_i) \tag{7} P(x1,x2,x3,⋯,xn∣W,b)=i=1∏nP(xi∣yi)(7)
这样输入不同猫的图片 x i x_i xi,我们可以得到不同的概率值 y i y_i yi。
这个式子我们要如何展开呢,我们这个连乘时的写法与 x i x_i xi的取值有关,当 x i = 1 x_i=1 xi=1时,输出的应该是判断为猫的概率,取 y i y_i yi;当 x i = 0 x_i=0 xi=0时,输出的应该是判断不是猫的概率,取 1 − y i 1-y_i 1−yi。
好在还是有解法的,这个式子可以通过伯努利分布展开的,因为 x i ∈ { 0 , 1 } x_i \in \{0,1\} xi∈{ 0,1}两种情况,同时 y i y_i yi又是一个概率。

和抛硬币的例子类似,当 x = 1 x=1 x=1时,我们用硬币是正面的概率 p p p去乘;当 x = 0 x=0 x=0是,我们用硬币是反面的概率 1 − p 1-p 1−p去乘。
我们就可以通过伯努利分布的这个式子来展开式 ( 7 ) (7) (7),得:
P ( x 1 , x 2 , x 3 , ⋯ , x n ∣ W , b ) = ∏ i = 1 n y i x i ( 1 − y i ) 1 − x i (8) P(x_1,x_2,x_3,\cdots,x_n|W,b) = \prod_{i=1}^n y_i^{x_i}(1-y_i)^{1-x_i} \tag{8} P(x1,x2,x3,⋯,xn∣W,b)=i=1∏nyixi(1−yi)1−xi(8)
我们通过在等式右边取对数,把连乘变成连加,因为取对数不改变单调性的。
log ( ∏ i = 1 n y i x i ( 1 − y i ) 1 − x i ) = ∑ i = 1 n log ( y i x i ( 1 − y i ) 1 − x i ) = ∑ i = 1 n ( x i ⋅ log y i + ( 1 − x i ) ⋅ log ( 1 − y i ) ) (9) \begin{aligned} \log \left( \prod_{i=1}^n y_i^{x_i}(1-y_i)^{1-x_i} \right )&= \sum_{i=1}^n \log \left(y_i^{x_i}(1-y_i)^{1-x_i} \right) \\ &= \sum_{i=1}^n \left(x_i \cdot \log y_i + (1-x_i)\cdot \log (1-y_i) \right) \\ \end{aligned} \tag{9} log(i=1∏nyixi(1−yi)1−xi)=i=1∑nlog(yixi(1−yi)1−xi)=i=1∑n(xi⋅logyi+(1−xi)⋅log(1−yi))(9)
我们要求极大似然值,是取的最大值,而损失函数是取最小值,我们把等式两边乘以一个负号,变成了求最小值。
min − ∑ i = 1 n ( x i ⋅ log y i + ( 1 − x i ) ⋅ log ( 1 − y i ) ) (10) \min - \sum_{i=1}^n \left(x_i \cdot \log y_i + (1-x_i)\cdot \log (1-y_i) \right) \tag{10} min−i=1∑n(xi⋅logyi+(1−xi)⋅log(1−yi))(10)
虽然这个式子看起来很像交叉熵,但实际上还是有很大不同的,主要的区别是它们的量纲不同。
这里面的对数是我们故意加上去的,并且负号也是为了凑成求最小值。
下面我们就来了解相对熵。
KL散度
KL散度,也被称为相对熵,是用来衡量两个分布的距离,设 P P P和 Q Q Q是两个概率分布,则 P P P对 Q Q Q的相对熵为:
D K L ( P ∣ ∣ Q ) = ∑ i P ( i ) log P ( i ) Q ( i ) (11) D_{KL}(P||Q) = \sum_i P(i) \log \frac{P(i)}{Q(i)} \tag{11} DKL(P∣∣Q)=i∑P(i)logQ(i)P(i)(11)
这里 i i i代表分布中的所有类别。
性质
- 不具备对称性,即 D ( P ∣ ∣ Q ) ≠ D ( Q ∣ ∣ P ) D(P||Q) \neq D(Q||P) D(P∣∣Q)=D(Q∣∣P)
- 非负性,即 D ( P ∣ ∣ Q ) ≥ 0 D(P||Q) \geq 0 D(P∣∣Q)≥0
举个例子,还是以抛硬币为例,假设我们有一个公平的硬币,即正反概率都是50%;我们还有一个有偏差的硬币,其正面概率为 p p p,反面概率为 q q q。
我们要如何判断这两个分布的相似性呢?
可能不好回答,但是我们知道,如果 p = 0.55 p=0.55 p=0.55,它肯定比 p = 0.95 p=0.95 p=0.95要更相似。
我们可以从抛硬币的结果来看,
假设公平硬币的抛掷结果为:HHTHHTTHTHTH
假设 p = 0.55 p=0.55 p=0.55硬币的抛掷结果为:HHTHHTTHHHTH
假设 p = 0.95 p=0.95 p=0.95硬币的抛掷结果为:HHHHHHTHHHHH
我们可以简单的计算不相等的结果个数,但是更严谨的做法是计算产生某个结果的似然值。
如果似然值很接近,那么说明这两个概率分布很接近。
基于(公平硬币抛出的)观察结果,我们就可以计算公平硬币的似然值和其他硬币的似然值的比值:
P ( 观察结果 ∣ 公平硬币 ) P ( 观察结果 ∣ 偏差硬币 ) \frac{P(\text{观察结果}|\text{公平硬币})}{P(\text{观察结果}|\text{偏差硬币})} P(观察结果∣偏差硬币)P(观察结果∣公平硬币)
我们再举一个例子,假设有一枚硬币,其正面概率为 p 1 p_1 p1,反面概率为 p 2 p_2 p2;
假设我们抛掷这枚硬币12次,产生的结果为:HHTHHTHHHTHT
我们可以很容易计算出这枚硬币产生这个结果的概率: p 1 ⋅ p 1 ⋅ p 2 ⋅ p 1 ⋅ p 1 ⋅ p 2 ⋅ p 1 ⋅ p 1 ⋅ p 1 ⋅ p 2 ⋅ p 1 ⋅ p 2 p_1\cdot p_1 \cdot \color{red}p_2 \cdot \color{black}p_1 \cdot p_1 \cdot \color{red}p_2 \cdot \color{black}p_1 \cdot p_1 \cdot p_1 \cdot \color{red}p_2 \cdot \color{black}p_1 \cdot \color{red}p_2 p1⋅p1⋅p2⋅p1⋅p1⋅p2⋅p1⋅p1⋅p1⋅p2⋅p1⋅p2
我们再拿一枚硬币,它产生正面的概率为 q 1 q_1 q1,反面概率为 q 2 \color{red}q_2 q2
那么这枚新的硬币产生这个结果的概率为: q 1 ⋅ q 1 ⋅ q 2 ⋅ q 1 ⋅ q 1 ⋅ q 2 ⋅ q 1 ⋅ q 1 ⋅ q 1 ⋅ q 2 ⋅ q 1 ⋅ q 2 q_1\cdot q_1 \cdot \color{red}q_2 \cdot \color{black}q_1 \cdot q_1 \cdot \color{red}q_2 \cdot \color{black}q_1 \cdot q_1 \cdot q_1 \cdot \color{red}q_2 \cdot \color{black}q_1 \cdot \color{red}q_2 q1⋅q1⋅q2⋅q1⋅q1⋅q2⋅q1⋅q1⋅q1⋅q2⋅q1⋅q2
即基于观察结果,有
P ( 观察结果 ∣ 硬币1 ) = p 1 N H p 2 N T P(\text{观察结果}|\text{硬币1}) = p_1^{N_H}\color{red}p_2^{N_T} P(观察结果∣硬币1)=p1NHp2NT
P ( 观察结果 ∣ 硬币2 ) = q 1 N H q 2 N T P(\text{观察结果}|\text{硬币2}) = q_1^{N_H}\color{red}q_2^{N_T} P(观察结果∣硬币2)=q1NHq2NT
其中 N H N_H NH表示观察结果中为正面的次数, N T N_T NT为反面的次数。我们计算它们的比值:
P ( 观察结果 ∣ 真实硬币 ) P ( 观察结果 ∣ 硬币2 ) = p 1 N H p 2 N T q 1 N H q 2 N T (12) \frac{P(\text{观察结果}|\text{真实硬币})}{P(\text{观察结果}|\text{硬币2})} = \frac{p_1^{N_H}\color{red}p_2^{N_T}}{q_1^{N_H}\color{red}q_2^{N_T}} \tag{12} P(观察结果∣硬币2)P(观察结果∣真实硬币)=q1NHq2NTp1NHp2NT(12)
这样就能计算出来这两个硬币的相似性。
其实KL散度衡量的是类似的东西。怎么说?
我们把上式右边取对数,并除以实验总数 N = N H + N T N=N_H+\color{red}N_T N=NH+NT:
1 N log ( p 1 N H p 2 N T q 1 N H q 2 N T ) = 1 N log p 1 N H + 1 N log p 2 N T − 1 N log q 1 N H − 1 N log q 2 N T = p 1 log p 1 + p 2 log p 2 − p 1 log q 1 − p 2 log q 2 = p 1 log p 1 q 1 + p 2 log p 2 q 2 \begin{aligned} \frac{1}{N}\log \left( \frac{p_1^{N_H}\color{red}p_2^{N_T}}{q_1^{N_H}\color{red}q_2^{N_T}} \right) &= \frac{1}{N}\log p_1^{N_H} + \frac{1}{N}\log \color{red}p_2^{N_T} \color{black} - \frac{1}{N}\log q_1^{N_H} -\frac{1}{N}\log \color{red} q_2^{N_T} \\ &= p_1\log p_1 + p_2 \log \color{red}p_2 \color{black} - p_1 \log q_1 - \color{red}p_2 \color{black}\log \color{red}q_2 \\ &= p_1 \log \frac{p_1}{q_1} + \color{red}p_2 \color{black}\log \frac{\color{red}p_2}{\color{red}q_2} \end{aligned} N1log(q1NHq2NTp1NHp2NT)=N1logp1NH+N1logp2NT−N1logq1NH−N1logq2NT=p1logp1+p2logp2−p1logq1−p2logq2=p1logq1p1+p2logq2p2
其中 N H N = p 1 N T N = p 2 \frac{N_H}{N}=p_1 \,\,\,\, \frac{\color{red}N_T}{N}=\color{red}p_2 NNH=p1NNT=p2。这里 p p p是一个概率分布, q q q是另一个概率分布,该式子和KL散度的式子一模一样。
即我们通过计算真实分布的似然值除以第二个分布的似然值,再取归一化的对数,就得到了KL散度的表达式。
我们可以看到,KL散度是一种衡量两个概率分布距离的方式,通过观察第二个概率分布产生第一个概率分布样本的可能性。
KL散度非常适用于深度学习的场景,因为深度学习模型基本上是关于为已知样本的真实分布建模。
实际上,交叉熵损失(cross entroy loss)就等于KL损失,最小化交叉熵就是最小化两个分布的距离。
我们先来看下交叉熵的定义。
交叉熵
交叉熵(Cross Entropy)主要衡量两个概率分布之间的差异性。交叉熵可在神经网络中作为损失函数,有:
H ( P ∗ ∣ P ) = − ∑ i P ∗ ( i ) log P ( i ) (13) H(P^*|P)=- \sum_i P^*(i) \log P(i) \tag{13} H(P∗∣P)=−i∑P∗(i)logP(i)(13)
其中 P ∗ P^* P∗表示真实分布; P P P表示预测分布; i i i表示分布中的所有类别。
KL散度和交叉熵
我们已经了解了KL散度和交叉熵,我们本小节来看它们之间的关系。
我们知道,交叉熵可以用来衡量预测分布和真实分布的差异(距离)。我们观察到的样本都是由真实分布产生的,所以我们可以这样描述KL散度:
D K L ( P ∗ ∣ ∣ P ) = D K L ( P ∗ ( y ∣ x i ) ∣ ∣ P ( y ∣ x i ; θ ) (14) D_{KL}(P^*||P) =D_{KL}\left ( P^* (y|x_i) || P(y|x_i;\theta\right) \tag{14} DKL(P∗∣∣P)=DKL(P∗(y∣xi)∣∣P(y∣xi;θ)(14)
其中 P ∗ P^* P∗是真实分布, P P P是我们的预测分布; x i x_i xi是第 i i i个样本, y y y是其对应的标签; θ \theta θ是模型的参数。
D K L ( P ∗ ∣ ∣ P ) = ∑ y P ∗ ( y ∣ x i ) log P ∗ ( y ∣ x i ) P ( y ∣ x i ; θ ) = ∑ y P ∗ ( y ∣ x i ) [ log P ∗ ( y ∣ x i ) − log P ( y ∣ x i ; θ ) ] = ∑ y P ∗ ( y ∣ x i ) log P ∗ ( y ∣ x i ) − ∑ y P ∗ ( y ∣ x i ) log P ( y ∣ x i ; θ ) (15) \begin{aligned} D_{KL}(P^*||P) &= \sum_y P^* (y|x_i) \log \frac{P^*(y|x_i)}{P(y|x_i;\theta)} \\ &=\sum_y P^* (y|x_i) \left [\log P^*(y|x_i) - \log P(y|x_i;\theta) \right] \\ &= \sum_y P^* (y|x_i)\log P^*(y|x_i) - \sum_y P^* (y|x_i) \log P(y|x_i;\theta) \\ \end{aligned} \tag{15} DKL(P∗∣∣P)=y∑P∗(y∣xi)logP(y∣xi;θ)P∗(y∣xi)=y∑P∗(y∣xi)[logP∗(y∣xi)−logP(y∣xi;θ)]=y∑P∗(y∣xi)logP∗(y∣xi)−y∑P∗(y∣xi)logP(y∣xi;θ)(15)
观察上面最终的式子,其中 P ∗ ( y ∣ x i ) log P ∗ ( y ∣ x i ) P^* (y|x_i)\log P^*(y|x_i) P∗(y∣xi)logP∗(y∣xi)与参数 θ \theta θ无关,实际上是真实分布的信息熵,是一个常数;而 − P ∗ ( y ∣ x i ) log P ( y ∣ x i ; θ ) -P^* (y|x_i)\log P(y|x_i;\theta) −P∗(y∣xi)logP(y∣xi;θ)就是我们熟悉的交叉熵的式子。
如果看不明白的话,或者我们换一种写法: D K L ( P ∗ ∣ ∣ P ) = − S ( P ∗ ) + H ( P ∗ , P ) D_{KL}(P^*||P)= -S(P^*) + H(P^*,P) DKL(P∗∣∣P)=−S(P∗)+H(P∗,P), S ( P ∗ ) S(P^*) S(P∗)是 P ∗ P^* P∗的信息熵; H ( P ∗ , P ) H(P^*,P) H(P∗,P)是交叉熵,KL散度 = 交叉熵 - 熵
因此,我们最小化关于参数 θ \theta θ的KL散度,就相当于最小化式 ( 15 ) (15) (15)中的第二项,即:
arg min θ D K L ( P ∗ ∣ ∣ P ) ≡ arg min θ − ∑ i P ∗ ( y ∣ x i ) log P ( y ∣ x i ; θ ) (16) \arg\,\min_{\theta}D_{KL}(P^*||P) \equiv \arg\,\min_{\theta} - \sum_i P^* (y|x_i) \log P(y|x_i;\theta) \tag{16} argθminDKL(P∗∣∣P)≡argθmin−i∑P∗(y∣xi)logP(y∣xi;θ)(16)
即
arg min θ D K L ( P ∗ ∣ ∣ P ) ≡ arg min θ H ( P ∗ , P ) (17) \arg\,\min_{\theta}D_{KL}(P^*||P) \equiv \arg\,\min_{\theta} H(P^*,P) \tag{17} argθminDKL(P∗∣∣P)≡argθminH(P∗,P)(17)
因此,在机器学习中,我们要评估预测模型和真实模型之间的差距,可以使用KL散度,而KL散度中的信息熵那一部分不变,所以只需要关注交叉熵就可以了。
基于KL散度恒不小于零的特性,博主找到了一个很好的图示:
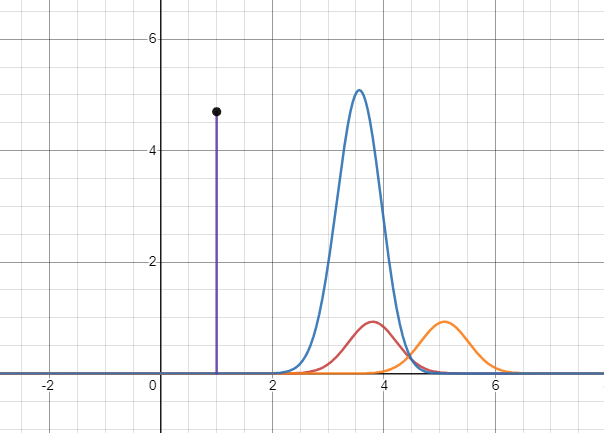
红色曲线代表真实概率分布;橙色曲线代表预测概率分布;紫线代表蓝色曲线下的面积,代表这两个分布的交叉熵。
交叉熵的大小与预测分布和真实分布的偏离程度相关。
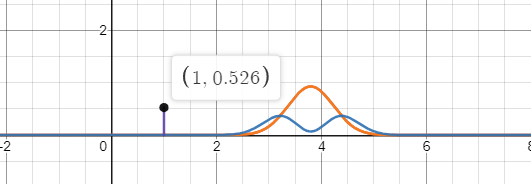
当两个分布重叠时,此时交叉熵最小,为真实分布的信息熵。
交叉熵损失
在机器学习中,我们需要评估标签值 y y y和预测值 y ^ \hat y y^之间的差距,我们知道只需要关注交叉熵。一般在机器学习中直接用交叉熵做损失函数来评估模型。
l o s s = − ∑ j = 1 n y j log y ^ j (18) loss=-\sum_{j=1}^n y_j \log \hat y_j \tag{18} loss=−j=1∑nyjlogy^j(18)
这里 y j y_j yj是真实样本的标签; y ^ j \hat y_j y^j是预测值,通常是一个概率; n n n是分类的个数;因此这是针对单个样本的情况,如果对于批量样本,那么交叉熵计算公式为:
L = − ∑ i = 1 m ∑ j = 1 n y i j log y ^ i j (19) \mathcal L = -\sum_{i=1}^m \sum_{j=1}^n y_{ij} \log \hat y_{ij} \tag{19} L=−i=1∑mj=1∑nyijlogy^ij(19)
其中 m m m是样本数; n n n是分类数。
二分类
有一种特殊问题,即分类数为 2 2 2,就是二分类问题。对于这种问题,由于 n = 2 n=2 n=2, y 1 = 1 − y 2 y_1=1-y_2 y1=1−y2, y ^ 1 = 1 − y ^ 2 \hat y_1 = 1- \hat y_2 y^1=1−y^2,所以交叉熵可以简化为:
l o s s = − [ y 1 log y ^ 1 + ( 1 − y 1 ) log ( 1 − y ^ 1 ) ] (20) loss = - \left[ y_1 \log \hat y_1 + (1-y_1)\log (1-\hat y_1) \right] \tag{20} loss=−[y1logy^1+(1−y1)log(1−y^1)](20)
对于批量样本的交叉熵为:
L = − ∑ i = 1 m [ y i log y ^ i + ( 1 − y i ) log ( 1 − y ^ i ) ] (21) \mathcal L = - \sum_{i=1}^m \left [ y_i \log \hat y_i + (1-y_i)\log(1-\hat y_i) \right] \tag{21} L=−i=1∑m[yilogy^i+(1−yi)log(1−y^i)](21)
通常对于二分类问题,记正例为 1 1 1,负例为 0 0 0。因此上式的两个相加项只会有一个存在。
多分类
常见的是多分类问题,即分类数 n ≥ 3 n \geq 3 n≥3。多分类问题对于批量样本的交叉熵损失即为式 ( 19 ) (19) (19):
L = − ∑ i = 1 m ∑ j = 1 n y i j log y ^ i j \mathcal L = -\sum_{i=1}^m \sum_{j=1}^n y_{ij} \log \hat y_{ij} L=−i=1∑mj=1∑nyijlogy^ij
这里有必要指出的是,对于多分类问题,标签值一般采用独热编码,预测值在输出之前会经过Softmax转换为概率分布。这样交叉熵损失只会关注预测正确的类别的概率。
这种特性使得代码编写也比计较直观。
均方误差和交叉熵
我们知道,线性回归的损失函数是均方误差,而逻辑回归的损失函数为交叉熵损失。为什么呢?
先看逻辑回归为什么用交叉熵损失而不是均方误差。
逻辑回归其实是分类问题,输出的是一个概率,交叉熵就是用于衡量概率距离的函数,所以选用交叉熵损失。如果把概率值看成是一个数值的话,也可以用均方误差啊。那到底为什么呢?
我们可以从均方误差和交叉熵的函数图形入手。
以二分类问题为例,先看交叉熵的函数图形。
import numpy as np
import matplotlib.pyplot as plt
def cross_entropy(y_hat, y):
return -np.log(y_hat) if y == 1 else -np.log(1 - y_hat)
y_hat = np.arange(0.01,1,0.01)
plt.plot(y_hat, cross_entropy(y_hat, 1), label='y=1')
plt.plot(y_hat, cross_entropy(y_hat, 0), label='y=0')
plt.legend()
plt.show()

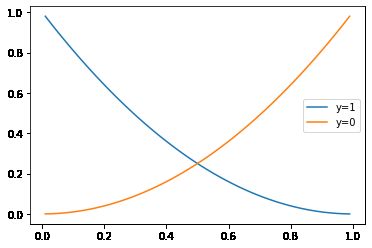
其中蓝线代表真实标签 y = 1 y=1 y=1时的交叉熵损失函数图形,橙线代表真实标签 y = 0 y=0 y=0时的图形。横坐标代表预测值,纵坐标代表损失值。
可以看到,当 y = 1 y=1 y=1时(蓝线),如果预测的越正确(预测值与1越近),则损失(惩罚)越小,在越接近0的位置,损失越大。
反过来,当 y = 0 y=0 y=0时(橙线),如果预测的越正确(预测值与0越近),则损失越小,在越接近1的位置,损失越大。
我们来看下,当 y = 1 y=1 y=1时,预测结果为 y ^ = 0.1 \hat y=0.1 y^=0.1时的损失:
> cross_entropy(0.1, 1)
2.3025850929940455
大约是 2.3 2.3 2.3。
我们再来看均方误差的图形:
def mse(y_hat, y):
return (y - y_hat)**2
plt.plot(y_hat,mse(y_hat, 1) , label='y=1')
plt.plot(y_hat, mse(y_hat, 0), label='y=0')
plt.legend()
其中蓝线代表真实标签 y = 1 y=1 y=1时的均方误差损失函数图形,橙线代表真实标签 y = 0 y=0 y=0时的图形。横坐标代表预测值,纵坐标代表损失值。
上面纵轴最大值也只是 1.0 1.0 1.0,整个函数图像看起来也没有特别大的梯度。
我们也来看下,当 y = 1 y=1 y=1时,预测结果为 y ^ = 0.1 \hat y=0.1 y^=0.1时的损失:
> mse(0.1, 1)
0.81
其损失值也不大,如果选用均方误差作为逻辑回归的损失函数,很可能训练不起来。
这样我们就明白了为什么逻辑回归要选择交叉熵。
我们再来看线性回归为什么不选择交叉熵。直接说结论,假设概率分布为高斯分布的情况下,采用交叉熵损失等同于采用均方误差损失。相关证明可以网上查找。
交叉熵损失的梯度
这里以多分类问题为例,拷贝了博主之前的另一篇文章Softmax与Cross-entropy的求导。
softmax函数为:
y ^ i = e z i ∑ k = 1 K e z k \hat y_i = \frac{e^{z_i}}{\sum_{k=1}^K e^{z_k}} y^i=∑k=1Kezkezi
这里 K K K是类别的总数,接下来求 y ^ i \hat y_i y^i对某个输出 z j z_j zj的导数,
∂ y ^ i ∂ z j = ∂ e z i ∑ k = 1 K e z k ∂ z j \frac{\partial \hat y_i}{\partial z_j} = \frac{\partial \frac{e^{z_i}}{\sum_{k=1}^K e^{z_k}}}{\partial z_j} ∂zj∂y^i=∂zj∂∑k=1Kezkezi
这里要分两种情况,分别是 i = j i=j i=j与 i ≠ j i \neq j i=j。当 i = j i=j i=j时, e z i e^{z_i} ezi对 z j z_j zj的导数为 e z i e^{z_i} ezi,否则当 i ≠ j i \neq j i=j时,导数为 0 0 0。
当 i = j i = j i=j,
∂ y ^ i ∂ z j = e z i ⋅ ∑ k = 1 K e z k − e z i ⋅ e z j ( ∑ k = 1 m e z k ) 2 = e z i ∑ k = 1 m e z k − e z i ∑ k = 1 m e z k ⋅ e z j ∑ k = 1 m e z k = y ^ i − y ^ i 2 = y ^ i ( 1 − y ^ i ) \begin{aligned} \frac{\partial \hat y_i}{\partial z_j} &= \frac{e^{z_i}\cdot \sum_{k=1}^K e^{z_k} - e^{z_i} \cdot e^{z_j} }{(\sum_{k=1}^m e^{z_k})^2} \\ &= \frac{e^{z_i}}{\sum_{k=1}^m e^{z_k}} - \frac{e^{z_i}}{\sum_{k=1}^m e^{z_k}} \cdot \frac{e^{z_j}}{\sum_{k=1}^m e^{z_k}} \\ &= \hat y_i - \hat y_i^2 = \hat y_i(1 - \hat y_i) \end{aligned} ∂zj∂y^i=(∑k=1mezk)2ezi⋅∑k=1Kezk−ezi⋅ezj=∑k=1mezkezi−∑k=1mezkezi⋅∑k=1mezkezj=y^i−y^i2=y^i(1−y^i)
当 i ≠ j i \neq j i=j,
∂ y ^ i ∂ z j = 0 ⋅ ∑ k = 1 K e z k − e z i ⋅ e z j ( ∑ k = 1 m e z k ) 2 = − e z i ∑ k = 1 m e z k ⋅ e z j ∑ k = 1 m e z k = − y ^ i y ^ j \begin{aligned} \frac{\partial \hat y_i}{\partial z_j} &= \frac{0 \cdot \sum_{k=1}^K e^{z_k} - e^{z_i} \cdot e^{z_j}}{(\sum_{k=1}^m e^{z_k})^2} \\ &= - \frac{e^{z_i}}{\sum_{k=1}^m e^{z_k}} \cdot \frac{e^{z_j}}{\sum_{k=1}^m e^{z_k}} \\ &= - \hat y_i \hat y_j \end{aligned} ∂zj∂y^i=(∑k=1mezk)20⋅∑k=1Kezk−ezi⋅ezj=−∑k=1mezkezi⋅∑k=1mezkezj=−y^iy^j
损失函数 L L L为:
L = − ∑ k y k log y ^ k L = -\sum_k y_k \log \hat y_k L=−k∑yklogy^k
其中 y k y_k yk是真实类别,相当于一个常数,接下来求 L L L对 z j z_j zj的导数
∂ L ∂ z j = ∂ − ( ∑ k y k log y ^ k ) z j = ∂ − ( ∑ k y k log y ^ k ) ∂ y ^ k ∂ y ^ k ∂ z j = − ∑ k y k 1 y ^ k ∂ y ^ k z j = ( − y k ⋅ y ^ k ( 1 − y ^ k ) 1 y ^ k ) k = j − ∑ k ≠ j y k 1 y ^ k ( − y ^ k y ^ j ) = − y j ( 1 − y ^ j ) − ∑ k ≠ j y k ( − y ^ j ) = − y j + y j y ^ j + ∑ k ≠ j y k ( y ^ j ) = − y j + ∑ k y k ( y ^ j ) = − y j + y ^ j = y ^ j − y j \begin{aligned} \frac{\partial L}{\partial z_j} &= \frac{\partial -(\sum_k y_k \log \hat y_k)}{z_j}\\ &= \frac{\partial -(\sum_k y_k \log \hat y_k)}{\partial \hat y_k} \frac{\partial \hat y_k}{\partial z_j} \\ &= -\sum_k y_k \frac{1}{\hat y_k} \frac{\partial \hat y_k}{z_j} \\ &= \left(-y_k \cdot \hat y_k(1 - \hat y_k) \frac{1}{\hat y_k} \right)_{k=j} - \sum_{k \neq j} y_k \frac{1}{\hat y_k} (-\hat y_k \hat y_j) \\ &= - y_j (1 -\hat y_j) - \sum_{k \neq j} y_k (-\hat y_j) \\ &= - y_j + y_j \hat y_j + \sum_{k \neq j} y_k (\hat y_j) \\ &= - y_j + \sum_{k} y_k (\hat y_j) \\ &= - y_j +\hat y_j \\ &= \hat y_j -y_j \end{aligned} ∂zj∂L=zj∂−(∑kyklogy^k)=∂y^k∂−(∑kyklogy^k)∂zj∂y^k=−k∑yky^k1zj∂y^k=(−yk⋅y^k(1−y^k)y^k1)k=j−k=j∑yky^k1(−y^ky^j)=−yj(1−y^j)−k=j∑yk(−y^j)=−yj+yjy^j+k=j∑yk(y^j)=−yj+k∑yk(y^j)=−yj+y^j=y^j−yj
这里用到了 ∑ k y k = 1 \sum_{k} y_k = 1 ∑kyk=1
Reference
-
如何理解信息熵
-
损失函数是如何设计出来的
-
Softmax与Cross-entropy的求导