《精通Hadoop》:第 1 章 Hadoop 2.X
第 1 章 Hadoop 2.X
“没有什么是不能通过搜索引擎或互联网找到的。”
——埃里克·施密特,谷歌执行主席
在大规模、高并行和分布式计算处理这个行业中,Hadoop实际上是大家所使用的一种开源框架标准。它为并行和分布式处理提供了一个计算层,与这个计算层紧密联系的是一个高度容错的存储层——Hadoop分布式文件系统(Hadoop Distributed File System,HDFS),而且它们都运行在低价、常见和相互兼容的普通硬件上。
本章我们将回顾Hadoop的发展历程,并着重介绍其准企业级特性。经过6年的发展和部署,Hadoop已经从一个只支持MapReduce模式的框架转变成更通用的集群计算框架。本章主要涵盖如下内容:
-
概括Hadoop代码的演进过程,以及主要的里程碑
-
介绍Hadoop从1.X版本发展到2.X版本所经历的变化,以及其如何演进为一个通用集群计算框架
-
介绍企业级Hadoop的可选项及其评估参数
-
概述一些流行的准企业级Hadoop发行版本
1.1 Hadoop的起源
互联网的诞生和发展孕育了万维网(WWW),它将大量使用标记语言(HTML)编写的文档用一个超链接连接在一起。它的客户端,也就是浏览器,成为了用户通往万维网的窗口。由于万维网上的文档易于创建、编辑和发布,于是海量的文档出现在了万维网中。
在20世纪90年代后半段,万维网中海量的数据导致了查找的问题。用户发现在有信息需求的时候,很难发现和定位正确的文档,于是众多互联网公司在万维网的搜索领域掀起了一股淘金浪潮,诸如Lycos、Altavista、Yahoo!和Ask Jeeves这样的搜索引擎或者目录服务变得司空见惯。
搜索引擎开始摄取和汇总网页信息,而遍历网络、摄取文档的程序则被称为爬虫。已经开发出来的优秀爬虫可以快速下载文档,能避免链接成环路,并且可以检测文档的更新。
在本世纪初期,谷歌的出现引领了搜索技术的发展。它的成功不仅是因为引入了强健的、反垃圾邮件的技术,还得益于它简洁的方法和快速的数据处理。对于前者,它创造了像PageRank这样新颖的概念,而对于后者,则在大规模并行、分布式的数据分析中,独具匠心地结合和应用了已有的技术,如MapReduce。
PageRank是一个以谷歌创始人Larry Page的名字命名的算法,它是为用户的网页搜索结果排序的算法之一。搜索引擎使用关键字匹配网站,以此来判断它与搜索查询间的相关度。受此启发,垃圾虫们就会在网站上加入许多相关或不相关的关键词,从而欺骗搜索引擎使它们出现在几乎所有的查询结果中。例如,一个汽车销售商却包含了关于购物和电影的关键字,这样他所对应的搜索查询范围就更广了。而用户则饱受这些无用信息的困扰。
PageRank通过分析指向某一特定页面的链接的质量和数量,阻碍了这种欺骗行为,它的出发点是重要的页面会有更多的入站链接。
大约在2004年,谷歌向世人公开了它的MapReduce技术实现,这项技术引入了与MapReduce引擎配合使用的GFS(Google File System,谷歌文件系统)。从此,其他许多公司在并行和分布式处理大数据时,都最喜欢使用MapReduce模式。Hadoop是MapReduce框架的一个开源实现,Hadoop和相关的HDFS,分别是受到了谷歌的MapReduce和GFS启发。
自从诞生以来,Hadoop和其他基于MapReduce的系统在各个领域执行着各种不同负载的任务,而网页搜索是其中一项。举个例子,http://www.last.fm/广泛使用Hadoop来产生图表和跟踪利用率的统计数据;Hadoop也被云服务提供商Rackspace用来做日志处理;雅虎(Yahoo!)是Hadoop最大的支持者之一,它不仅使用Hadoop集群创建网页索引,而且还用其执行复杂的广告植入和内容优化算法。
1.2 Hadoop的演进
大概在2003年,Doug Cutting和Mike Cafarella开始从事一个叫Nutch的项目,这是一个具有高可扩展性、特性丰富的开源爬虫和索引构建项目,目的是提供一个现成的爬虫框架去满足文档搜索的需求。Nutch能在多台机器组成的分布式集群上工作,并且遵守网页服务器上robots.txt文件中定义的协议。它之所以具有高扩展性是因为提供了一个插件框架,程序员能添加自定义的组件在上面运行,例如,一个可以从互联网读取不同类型媒体的第三方插件。
机器人排除标准(Robot Exclusion Standard),即robots.txt协议,是一个建议爬虫如何抓取网页的忠告性协议。它是一个放在网页服务器根目录下的文件,用来建议爬虫应该或者不应该抓取某个公共网页或者目录。作为一个有礼貌的爬虫,其中一个特征就是遵守放置在robots.txt文件内的建议。
Nutch搭配其他诸如Lucene和Solr这样的索引技术,为构建搜索引擎提供了必要的组件,但还不能满足互联网级别规模的需要。早期的Nutch曾演示过使用4台机器处理1亿个网页,不过调试和维护工作很繁琐。2004年,谷歌发布的颇具影响力的MapReduce和GFS概念解决了Nutch遇到的一些扩展性问题。Nutch的贡献者开始将分布式文件系统和MapReduce编程模型集成到这个项目中。到2006年,Nutch的扩展性虽然提升了,但是也没能达到互联网级别。它使用20台机器可以抓取和构建几亿的网页文档的索引。同时,编程、调试和维护搜索引擎的工作变得容易一些了。
2006年,雅虎将Doug Cutting招入麾下,Hadoop诞生了!Hadoop项目是受Apache软件基金会(Apache Software Foundation,ASF)支持的,不过它是从Nutch项目中分离出来的,并可以独立发展。2006到2008年间,Hadoop发行了大量的小版本,最终成长为一个稳定的、互联网级别的、基于MapReduce原理的数据处理框架。2008年,Hadoop在太字节(terabyte)级别数据的排序性能标杆竞赛中获胜,正式宣告它成为了一个基于MapReduce、适用于大规模的、可靠的集群计算框架。
Hadoop 家族
从2007年和2008年发布的早期版本算起,Hadoop项目的族谱可不短。由于它归属于Apache软件基金会,所以在本书中统称为Apache Hadoop。Apache Hadoop项目是后续发行的Hadoop版本的父项目,就像一条河流的分布一样,这个父项目相当于河流的干流,而它的分支或者说发布版本就像是支流。
参照Apache Hadoop的发展历程,下页图显示了Hadoop的血缘关系。在图中,黑色实线方框显示了Apache Hadoop的主发行版本,椭圆实线框则对应Hadoop的分支版本,而黑色虚线方框代表其他的Hadoop发行版本。
Apache Hadoop有三个关系非常密切的重要分支,它们是:
-
0.20.1分支
-
0.20.2分支
-
0.21分支
在0.20版本之前,Apache Hadoop一直是沿着一条主线发行版本的,并且每次总是一个单独的主版本,没有创建分支版本。在发行0.20版本的时候,这个项目分裂成了三个主要的分支,其中0.20.2分支被称为MapReduce 1.0版本、MRv1或者简称为Hadoop 1.0.0;0.21分支被称为MapReduce 2.0版本、MRv2或者简称为Hadoop 2.0;其他一些旧一点的发行版本派生于0.20.1版本。2011年,各个不同分支发行的版本数量创下了最高纪录。
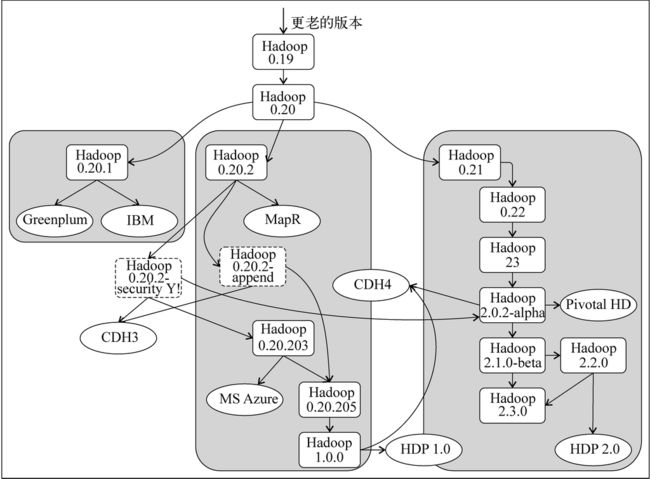
另外有两个发行版本虽然不属于主发行版本,但也非常重要,那就是:Hadoop-0.20-append和Hadoop-0.20-security。这两个发行版本分别引入了HDFS文件追加和安全相关的特性。随着这些增强特性的加入,Apache Hadoop渐渐被企业用户所接受。
1. Hadoop-0.20-append
文件追加(append)特性是Hadoop-0.20-append版本的主要特性,它让用户在执行HBase的时候不再担心数据丢失的风险。在HDFS上运行的HBase是一种被广泛使用的列存储应用,可以在面向批处理的Hadoop平台上提供在线存储功能。具体来说,文件追加特性使得HBase的日志能够持久存储,确保了数据的安全。传统的HDFS为MapReduce批处理作业提供文件的写入和输出功能。在完成这些作业时,一次只能打开一个文件,将很多数据写入其中,然后再关闭文件。被关闭的文件可以被读取很多次,但是不能再被修改。语义上提供的是一种一次写入多次读取( write-once-read-many-times)的模式,且当文件被写入时,没有人能读取文件的内容。
任何程序在写HDFS文件的过程中,当写操作失败或者程序崩溃时,都必须重写这个文件的全部内容。在MapReduce中,用户总是重新执行任务来产生新的文件,但是在像HBase这样的在线系统中却不是这样的。如果日志文件写失败,事务(transaction)操作就不能再被执行,从而导致数据的丢失。如果能够根据日志内容重新执行事务操作,那数据就不会丢失。文件追加功能使HBase和其他需要事务操作的应用能够在HDFS上执行,从而降低了这一风险。
2. Hadoop-0.20-security
雅虎的Hadoop团队在Hadoop-0.20-security版本中主动承担了添加安全特性的工作。企业内的团队各种各样,并且他们处理的数据类型也各不相同。为了遵守法规、保护客户隐私和保障数据安全,进行数据隔离、数据认证以及Hadoop作业和数据的授权是非常重要的。这个安全相关的版本的发布包含了丰富的特性以支持上述三方面的企业安全需求。
这个版本将Kerberos认证系统完整集成到Hadoop中。访问控制列表(Access Control Lists,ACL)的引入确保了作业的运行和数据的访问得到恰当的授权。认证与授权为系统中属于不同用户的作业和数据提供了必要的隔离性。
3. Hadoop年鉴
下图展示了Apache Hadoop的主要发行版本和里程碑。虽然该项目已经持续了8年,但是直到最后的4年,Hadoop才在大数据处理领域发挥了巨大影响力。2010年1月,谷歌获得了MapReduce技术的专利,但是4个月后这项技术专利就授权给了Apache软件基金会,这为Hadoop打了一针强心剂。摆脱了法律纠纷的烦扰,各家企业,不论规模大小,都张开双臂准备迎接Hadoop。至此,Hadoop也经历了一些重大改进,并发布了相关版本。这也为Hadoop的分销、支持、培训以及相关业务带来了商机。
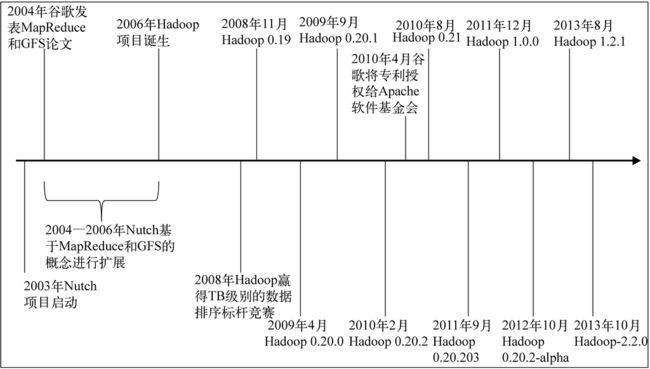
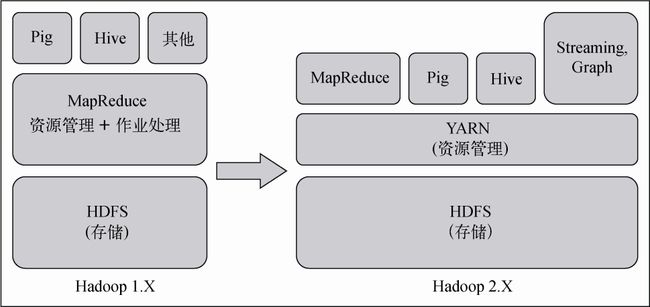
Hadoop 1.0系列版本在本书中统称为1.X版本,它经历了Hadoop作为一个纯粹的MapReduce作业处理框架从诞生到演进的全过程,它广泛采用了大数据处理工具,发挥的作用远远超出了人们的预期。这个时期,Hadoop 1.X发行版的稳定版本是1.2.1,它包括了文件追加和安全等特性。Hadoop 1.X试图通过不断的改变来保持其灵活性,例如HDFS文件追加功能,以支持HBase这样的在线系统。然而,尽管Hadoop 1.X的灵活性得到了扩展,但是原有的MapReduce计算模型却不能支持所有大数据应用涉及的领域,除非在它的架构上做出改变。
Hadoop 2.0系列版本在本书中统称为2.X版本。自2013年问世以来,这一系列的版本也经历了重大改进,拓展了Hadoop可以处理的应用范围。这个系列还针对企业内现有的Hadoop集群提升了效率,并扩大了优势。显然,Hadoop正在快速赶超MapReduce,由于它还具有向后兼容的优势,因此在大数据领域保持着遥遥领先的地位。它正在从一个仅针对MapReduce的框架成长为一种通用的集群计算和存储平台。
1.3 Hadoop 2.X
Hadoop 1.X在一些组织机构内大受欢迎,也让人们认识到了它的局限性。
-
Hadoop对集群计算资源赋予了史无前例的准入方式,组织机构内的每一个人都有权访问。并且由于MapReduce编程模型比较简单,且支持“一次开发,任意部署”(develop once deploy at any scale)的模式,因此,用户将一些不怎么适合MapReduce实现的数据处理作业也部署到了Hadoop上,例如,网页服务端应用被部署到一个长时间运行的map作业中。众所周知,MapReduce难以承担迭代类型的算法运算,但是一些黑客通过改造使Hadoop能执行迭代算法,这使得集群的资源利用和容量规划面临众多挑战。
-
Hadoop 1.X采用集中式作业流控制,然而集中式系统由于其负载的单点问题,很难实现扩展。一旦JobTracker(作业跟踪器)出现故障,系统中所有的作业都必须重新启动,这对整个集中式组件造成了极大压力。按照这种模式,Hadoop很难与其他类型的集群进行集成。
-
早期发行的Hadoop 1.X版本将所有HDFS目录和文件的元数据存储到一个NameNode单点。整个集群的数据状态取决于这个单点的成败。随后的版本添加了一个作为冷备的从NameNode(secondary NameNode)节点。从NameNode节点周期性地将写日志(edit log)和NameNode的映象文件(image file)合并,这样做有两个优点:首先,由于主NameNode节点在启动的时候不需要完全合并写日志和映象文件,因此主NameNode节点的启动时间缩短了;其次,从NameNode节点复制NameNode的所有信息,这样当NameNode节点出现不可恢复的故障时,数据丢失会降到最低。但是,从NameNode(它并不是NameNode的一个实时备份)并不是一个热备份节点,这意味着故障切换时间和恢复时间较长,且集群可用性会受到影响。
-
Hadoop 1.X主要是一个基于Unix系统的大数据处理框架,想要直接在微软的Windows Server操作系统上执行是不可能的。随着微软大举进入云计算和大数据分析领域,再加上业界已经在Windows Server上有了大量投入,Hadoop也应该支持微软Windows系统的功能,这一点非常重要。
-
Hadoop的成功主要得益于企业的参与,而它被采用则是由于有现成的、企业需要的特性。尽管Hadoop 1.X尝试支持其中的一些企业特性(例如安全),但是还是有其他的企业需求亟待解决。
1.3.1 Yet Another Resource Negotiator(YARN)
在Hadoop 1.X中,资源的分配和任务的执行是由JobTracker完成的。由于计算模型是和集群的资源紧密联系的,所以只能支持MapReduce一种计算模型。这种紧密的耦合导致开发者强行适配其他的计算模型,从而出现了与MapReduce设计意图相悖的使用方式。
YARN的主要设计目标是将大家比较关注的资源管理(resource management)和应用执行(application execution)之间的耦合隔离,然后其他的应用模式就可以在Hadoop集群上执行了。增强不同计算模型和各种应用之间的交互,使得集群的资源得到高效的利用,同时也能更好地与企业中已经存在的计算结构集成在一起。
然而,为了达到资源管理和作业管理的低耦合性,也不能牺牲了向后兼容性。在过去的6年里,Hadoop已经引领了大数据并行与分布式处理领域的潮流,这意味着大量的开发、测试和部署已经投入到位了。
YARN能够保持与Hadoop 1.X(Hadoop-0.20.205+)版本API的向后兼容性。一份老版本的MapReduce程序不做任何代码修改就能继续在YARN上执行。当然,重新编译是必需的。
架构概述
下页图展示了YARN的架构。YARN将资源管理的功能抽象成一个叫资源管理器(Resource- Manager,RM)的组件。每个集群都有一个RM,它主要用来跟踪资源的使用情况,同时也负责资源的分配和解决集群中的资源竞争问题。RM使用通用的资源模型,而且不感知资源的具体情况以及应用使用资源做什么。例如,RM不需要知道资源对应一个Map还是一个Reduce。
Application Master(AM)负责一个作业的调度和执行工作,而且每个应用有一个单独的AM实例(例如,每个MapReduce作业都有一个AM)。AM向RM请求资源,然后使用资源执行作业,并处理作业执行中可能出现的错误。
一般情况下在集群中指定一台机器以守护进程(daemon)的方式运行RM,RM维护着整个集群的全局状态和资源分配情况。由于拥有全局的信息,RM可以根据集群的资源使用率做出公平的资源配置。当收到资源请求时,RM动态地分配一个容器(container)给请求方。容器是一个与节点绑定的资源抽象概念,例如,一个节点上的2个CPU和4 GB内存可以作为一个容器。
节点管理器(NodeManager,NM)是集群中每个节点上执行的一个后台进程,它协助RM做节点的本地资源管理工作。NM承担容器的管理功能,例如启动和释放容器,跟踪本地资源的使用,以及错误通知工作。NM发送心跳信息给RM,而RM通过汇总所有的NM的心跳信息从而了解整个系统的状态。
作业(job)是直接向RM提交的,RM基于集群的资源可用情况调度作业执行。作业的基本信息保存在可靠的存储系统中,这样当RM崩溃后很容易恢复作业重新执行。在一个作业被调度执行后,RM在集群的某个节点上分配一个容器给该作业,作为这个作业的AM。
然后,AM就接管了这个作业的后续处理,包括请求资源、管理任务执行、优化和处理任务的异常。AM可以用任何语言编写,并且不同版本的AM可以独立地运行在同一个集群里面。
AM请求的资源明确了本地化信息和期望的资源类型,RM会基于资源分配策略和当前可用资源的情况尽力满足AM的要求。当AM获取到一个容器时,它能在容器内执行自己的应用程序,并且可以自由地和这个容器通信,而RM并不知道这些通信的存在。
1.3.2 存储层的增强
Hadoop 2.X发行版中做了大量的存储层的增强,它们的主要目的就是为Hadoop在企业中的使用铺平道路。
1. 高可用
NameNode其实是Hadoop的一个目录服务,它包含着整个集群存储的文件的元数据。Hadoop 1.X有一个从NameNode作为冷备节点,它滞后主NameNode节点几分钟。而Hadoop 2.X则具备NameNode的热备节点。当主NameNode节点故障了,从NameNode就能够在几分钟内转变成主NameNode。如果有热备份节点,就能够提供无数据丢失且不间断的NameNode服务,并且自动故障切换也比较容易实现。
热备份的关键在于维护它的数据尽可能与主NameNode节点保持一致,可以通过读取主NameNode的写日志文件并在备份节点上执行来实现,并且延时也是非常低的。写日志文件的共享可以使用以下两种方法来实现。
-
在主NameNode和从NameNode节点间使用共享的网络文件系统(Network File System,NFS)存储目录:主NameNode往共享目录中写入日志,而从NameNode监听这个共享目录的变更消息,然后拉取这些变更。
-
使用一组JournalNode(quorum of Journal Nodes):主NameNode将写日志发送到部分JournalNode以记录信息,而从NameNode持续监听这些JournalNode,从而更新和同步主NameNode的状态。
下图展示了一种使用基于有效配额的存储系统的高可用实现框架。DateNode需要同时发送数据块报告信息(block report)到主从两个NameNode。
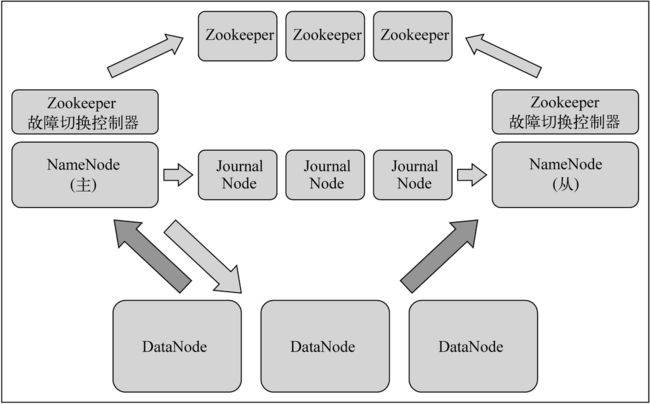
ZooKeeper等高可用的监听服务可以用来跟踪NameNode的故障,并且可以触发故障切换的流程,使从NameNode节点提升为主节点。
2. HDFS联合
类似于YARN对计算层的改进措施,在Hadoop 2.X中也实现了一个更为通用的存储模型。一个通用的块存储(block storage)层已经从文件系统层隔离出来。这种隔离使得其他存储服务有机会被集成到Hadoop集群中。在此之前,HDFS和块管理层紧紧地耦合在一起,难以集成其他的存储服务。
这种通用存储模型使得HDFS联合(HDFS Federation)功能得以实现。这个功能允许多个HDFS命名空间使用相同的底层存储设备,且联合的NameNode节点提供了文件系统层面的隔离功能。在第10章中,我们会详细介绍这个特性。
3. HDFS快照
快照(snapshot)是文件系统的整体或部分目录在某个时间点的只读镜像(image),通常是为了以下三个原因:
-
防止用户的错误操作导致的数据损坏或丢失
-
备份
-
容灾
快照仅在NameNode上实现,它不会涉及数据从一个数据节点复制到另一个数据节点,而仅仅是复制了块列表以及文件的大小。生成一个快照的操作几乎是瞬间完成的,它不会影响NameNode节点的性能。
4. 其他增强功能
在Hadoop 2.X中,还有大量其他的增强功能,如下所示。
-
以前,Hadoop的RPC通信协议是使用Java的Writables序列化实现的,但在Hadoop 2.X是基于Protocol Buffers1实现的。这个改进不仅很容易保持向后兼容,而且帮助集群中的不同组件实现了滚动升级(rolling the upgrades)。另外,RPC也允许在客户端实现重试功能。
-
Hadoop 1.X是不感知存储设备的类型的,这意味着机械硬盘和SSD(固态硬盘)被无区别对待。用户无法对数据的布局做任何干预。2014年发布的Hadoop 2.X版本能够识别存储设备的类型,并且应用程序可以获取到这些信息。这样,应用程序就可以通过这些信息来优化它们的数据存取和布局策略。
-
Hadoop 2.X发行版支持HDFS的文件追加功能。
-
Hadoop 1.X发行版是通过HDFS客户端访问文件系统的。Hadoop 2.X开始支持NFSv3,促进了NFS网关组件的诞生。现在,HDFS可以挂载(mount)到用户本地兼容的文件系统上,他们可以直接往HDFS下载或上传文件。往已有的文件追加内容是可以的,但是随机写(random write)是不支持的。
-
对Hadoop的I/O进行了大量的改进。例如,在Hadoop 1.X中,当客户端运行在某个数据节点上时,它需要通过TCP来读取本地数据。但是,有了本地快捷读取(short-circuit local reads),客户端就可以直接读取本地的数据;通过特定的接口还可以实现零复制(zero-copy)数据读取;读或写数据的CRC校验码计算方法也使用英特尔的SSE 4.2 CRC 32指令进行了优化。
1这是谷歌开发的高效序列化组件。——译者注
1.3.3 支持增强
Hadoop通过支持其他平台和框架增广了它支持的应用的范围。上面我们展示了通过YARN支持其他的计算模型,还有通过块存储层支持其他存储系统。此外还有如下其他方面的支持增强。
-
Hadoop 2.X天然支持微软的Windows系统。这个转变使得微软的Windows服务器有极好的机会进入大数据处理领域。当然,部分原因得归功于Hadoop开发使用的Java编程语言有很好的可移植性,但更重要的原因在于Hadoop对计算和存储的通用性的增强,使其能支持包括Windows在内的系统。
-
云服务商将Hadoop作为一种按需分配的服务,作为其平台即服务(Platform-as-a-Service)产品的一部分。Hadoop 2.X支持OpenStack,促进了在云端的弹性和虚拟化部署。
1.4 Hadoop的发行版
如今,Hadoop和其生态圈中的各个组件都成为了一项项复杂的工程。如上所述,Hadoop在不同的发行版本上有很多的代码分支,同时也有好几种不同的发行方式。其中,最活跃也是社区参与度最高的,是通过Apache软件基金会的方式。这是一种免费发行的方式,并且背后有强大的社区支持。同时,Apache Hadoop发行中的社区贡献影响着Hadoop发展的大方向。Apache Hadoop通过在线论坛的方式提供支持,问题是提交给社区,并由论坛的成员来解答的。
在企业内部部署和管理Apache Hadoop发行版本是很枯燥和繁琐的。Apache Hadoop使用Java来开发并且针对Linux的文件系统进行了优化。这可能与企业已有的应用程序和基础架构不匹配。另外,当与Hadoop生态系统的其他组件集成时,Apache Hadoop版本有不少的bug,并且也不够直观。
为了解决这样的问题,出现了几个为Hadoop提供新的发行模式的公司,主要有三种不同风格的发行方式。
-
第一种风格是为Apache Hadoop发行版提供付费的商业支持和培训。
-
第二种风格是一些公司通过提供一系列的工具来部署和管理Apache Hadoop。这些公司也为Hadoop生态圈内不同的组件提供健壮的集成层。
-
第三种模式是有些公司通过自己私有的特性和代码来增强Apache Hadoop,这些特性属于付费的增强功能,而它们中的大部分是为了解决具体的用户案例。
所有这些发行版本都以Apache软件基金会的Hadoop作为共同的源头。这些版本的用户,尤其是那些使用第三种模式发行版本的用户,很可能会集成一些私有代码到Apache Hadoop中。但是这些发行版本总是和Apache Hadoop保持紧密的联系并紧跟它的趋势,而且通常是经过了完善的测试,并能提供深入、及时的支持,为企业减少了大量管理成本。如果使用的并非是Apache Hadoop发行版,那就会因为被束缚于某个服务商而陷入不利的形势。一个服务商所提供的工具和私有特性往往与其他服务商发布的版本或者其他第三方所提供的工具不兼容,从而产生代码迁移的费用,而且这个费用不仅仅是指技术上的,还包括机构的培训、能力规划和架构调整等。
1.4.1 选哪个Hadoop发行版
自2008年以来,多家公司都提供了Hadoop发行版本,并且各有千秋。对于某家企业或者机构,到底该如何选择合适的发行版,这需要具体问题具体分析。发行版本的评估标准也各不相同,下面将就重点的几项进行分析。
1. 性能
让Hadoop能够在集群上快速处理数据当然是众望所归的一项能力。通常,这一直都是所有性能基准参考标准的重要基础。这项特殊的性能标准被称为“吞吐量”(throughput)。Hadoop能够处理各类分析工作,同时,这些分析工作所支持的使用案例也多种多样,因此,“延时”(latency)也成为了一项重要的性能标准。为了实现低延时的分析,Hadoop就一定要能够快速读取输入数据并且给出输出数据,这种输入到输出的成本形成了数据处理流程的主要组成部分。
延时是为了得到结果而需要等待的时间,它的度量单位是时间单位,例如毫秒、秒、分钟或者小时。
吞吐量是在单位时间内能执行操作的数量,它表明在单位时间内能完成的工作量。
无论哪种Hadoop发行版,要想达到低延时的目的,都可以采用扩充硬件规模的方法。然而这种方法的成本很高,而且很快就没有了提升的空间。从架构上说,低的I/O延时可以采用不同的方法实现。一种方法是减少数据发送器(data source)或数据接收器(data sink)与Hadoop集群之间中间数据驻留层的数量。有些发行版本提供了流(streaming)的方式写入Hadoop集群,从而减少中间驻留层数。在数据流到存储系统之前,可以在流层面插入一些用于过滤、压缩以及轻量级别数据处理的运算符,对数据进行预处理。
Apache Hadoop发行版是使用运行在虚拟机上的Java语言编写的,尽管它增加了应用程序的可移植性,但是系统负载也随之升高,比如它在执行的时候由于转换字节码解析(byte-code interpretation)以及后台垃圾回收(garbage collection)而产生额外的间接层。这样一来,执行速度比直接在目标设备上编译应用要慢。一些厂商针对特殊的硬件做了优化,提升了每个节点上作业执行的性能。例如,压缩和解压特性就可以在某些硬件类型上进行优化。
2. 可扩展性
总有一天,数据的大小会超出一家机构所能提供的计算或存储资源的物理容量,这就要求我们能够对计算资源和存储资源做扩展。自然扩展可以通过垂直扩展或者水平扩展两种方式实现。垂直扩展(或者称产品升级)成本较高,而且会受硬件技术发展的限制,此外,缺乏灵活性也是它的一个劣势。水平扩展(或者称向外扩展)是对计算和存储进行扩展的首选方式。
理想情况下,水平扩展仅仅是集群网络中添加节点和磁盘,因此配置变更最小。然而,对于Hadoop集群的扩容,不同的发行版本其难易程度也不尽相同,主要体现在工作量和成本上。水平扩展可能会大幅增加管理和部署的成本,说不定还需要重写许多应用程序的代码。扩展的成本还取决于现有的架构,以及如何让其与正在评估的Hadoop发行版本兼容。
垂直扩展(或者称产品升级)是指在系统中的一个单一节点处添加更多的资源,例如,添加更多的CPU、内存或者存储设备到一台计算机上。垂直扩展可以增加容量,但是不会减少系统的负载。
水平扩展(或者称向外扩展)是在系统中添加额外的节点。例如,通过网络连接添加一台计算机到一个分布式系统中。由于新机器也承担了一部分的负载,所以水平扩展能减轻系统负载。然而,集群中单个节点的容量并没有增加。
3. 可靠性
任何分布式系统都饱受部分故障的困扰。故障可能来自硬件、软件、网络问题,而且若在普通硬件上运行,发生故障的间隔时间还会更短。要想成为高可用、高度一致的系统,首要目标都是在处理好这些故障的同时不得中断服务或破坏数据的完整性。
重视可靠性的发行版都会令其提供的组件具有高可用性。减少单点故障(Single Point of Failures,SPOF)可以确保组件的可用性,而这也意味着需要增加组件的冗余度。在过去很长一段时间内,Apache Hadoop只有唯一一个NameNode,NameNone的硬件故障就意味着整个集群不可用了。现在,由于增加了从NameNode和热备份的概念,在NameNode故障的时候可以使用它们来恢复NameNode功能。
能够减少集群管理员手动操作的发行版会更可靠一些。手动的干预往往会导致更高的错误率,比如对故障切换的处理。故障切换是系统的危急时刻,因为此时的冗余度较低。这时,任何一个操作错误对于应用而言都是致命的。而运用自动故障切换处理,系统就能在较短的时间内恢复运行,故障恢复时间越短,系统的可用性就越好。
无论是正常操作还是处理故障,都必须保证数据的完整性。数据校验可以检测到数据中的错误并尽可能修复,这就可以确保数据安全,此外还有数据复制、数据镜像和快照等方式。数据复制会按照一定的冗余度要求来确保数据的可用性。需要密切注意感知机架信息的智能数据布局,以及对复制不足或复制过多的处理方式。镜像是通过互联网将数据异步地复制到其他站点,在主站故障的时候可以恢复数据。快照是任何发行版本都期望具有的性能,它不仅有助于灾难恢复,而且还能帮助数据的离线访问。数据分析会涉及大量数据的试验和评估,而快照就能帮助数据科学家在完成这项工作的同时不破坏分析成果。
4. 可管理性
部署和管理Apache Hadoop开源的发行版需要对代码和配置有深入的了解,这项技能在IT管理员团队中可能并不是普遍拥有的。同时,IT管理员需要管理企业大量的系统,Hadoop只是其中的一个。
面对各种不同的Hadoop版本,可能需要对这些版本及其所支持的生态圈内其他组件之间的适用性进行评估。新版本的Hadoop支持集群中执行MapReduce以外的其他应用模式,所以新版本可以根据企业的规划,更有效地利用企业内的硬件资源。
对于企业而言,要想选择一个合适的Hadoop发行版,它的管理工具的能力是很关键的鉴别标准。管理工具需要提供集中式的集群管理、资源管理、配置管理以及用户管理。此外,作业调度、自动升级、用户配额管理和集中的调试功能也是大家希望看到的性能。
集群的健康检测是管理性功能中另一项重要特性。发行版中最好包含可视化集群健康面板(Dashboard),并且最好有集成其他工具的能力。另外,更便捷的数据访问也是需要评估的因素,例如,Hadoop上支持POSIX文件系统接口会使工程师和程序员更容易浏览和访问数据,但这也有不利的一面,它使得修改数据成为了可能,事实证明这在某些情况下是存在风险的。
数据安全选项评估同样至关重要,它包括Hadoop用户认证、数据授权和数据加密。每家机构和企业可能已经有了自己的授权系统,例如Kerberos或者LDAP。如果Hadoop发行版能够集成已有的认证系统,它就在节约成本、提高兼容性方面获得了巨大优势。细化的授权有助于控制不同层面对数据和作业的访问权限。当数据迁入或迁出企业集群时,保护数据不被窃取的重要方法是使用加密的传输通道。
不同发行版本都会提供与开发和调试工具的集成。如果它所提供的工具能和机构工程师或科学家正在使用的工具有很多重合之处,那也是一个优势,这不仅体现在购买软件授权的成本上,而且也体现在更少的培训和指导上。同时,由于工作人员已经习惯使用这些工具,这也能提高机构的生产力。
1.4.2 可用的发行版
当前有好几种可用的Hadoop发行版,具体列表可参见网站:http://wiki.apache.org/hadoop/Distributions%20and%20Commercial%20Support。我们将选择其中4个进行详细探讨:
-
Cloudera Distribution of Hadoop(CDH)
-
Hortonworks Data Platform(HDP)
-
MapR
-
Pivotal HD
1. Cloudera Distribution of Hadoop
Cloudera公司创建于2009年3月,它的主营业务是提供Hadoop软件、支持、服务和企业级Hadoop及其生态圈组件部署培训。这套软件被称为Cloudera Distribution of Hadoop。作为Apache软件基金会的赞助商之一,该公司在提供Hadoop支持和服务的同时,将大部分对Hadoop的增强功能合并到了Apache Hadoop的主线中。
CDH现在已升级到第五个主版本(CDH5.X),并且被认为是一个成熟的Hadoop发行版。它的付费版本包含一个独家的管理软件——Cloudera Manager。
2. Hortonworks Data Platform
2011年1月,雅虎公司的Hadoop团队出走创建了Hortonworks公司,它的主营业务类似于Cloudera。他们的发行版称为Hortonworks Data Platform。HDP提供的Hadoop和其他软件是完全免费的,只对技术支持和培训收费。Hortonworks也将增强功能合入到Apache Hadoop主线中。
HDP当前已升级到第二个主版本,被认为是Hadoop发行版中一颗冉冉升起的新星。它拥有一款免费并开源的管理软件——Ambari。
3. MapR
MapR创建于2009年,它的使命是提供企业级的Hadoop。它的Hadoop发行版相较于Apache Hadoop提供了大量的私有代码,其中一些组件他们承诺会与现有的Apache Hadoop项目保持兼容。MapR发行版的关键私有代码是使用了POSIX兼容的网络文件系统(POSIX-compatible NFS)来替换HDFS,另一个关键特性是支持快照功能。
MapR拥有自己的管理控制台(management console)。不同级别的版本分别命名为M3、M5和M7。其中,M5是他们的标准商业版本;M3是免费版本,但可用性不高;M7是付费版,具有重写的HBase API。
4. Pivotal HD
Greenplum是EMC公司一个主要的并行数据存储产品,EMC将Greenplum集成到Hadoop中,形成了一个较高级的Hadoop发行版本——Pivotal HD。这种整合减少了Greenplum与HDFS之间的数据导入和导出操作,从而减少了成本和延时。
Pivotal HD提供的HAWQ技术能够高效、低延时地对HDFS中的数据进行查询,在某些MapReduce工作上相对于Apache Hadoop有100倍的性能提升。HAWQ支持在Hadoop上使用SQL处理数据,使得熟悉SQL的用户能加入到Hadoop的大家庭中。
1.5 小结
本章,我们展示了Hadoop的演进、里程碑和发行版本,深入了解了Hadoop 2.X以及它给Hadoop带来的变化。从本章中学到的主要内容如下。
-
MapReduce是由于互联网规模的数据收集、处理和索引需求而诞生的,Apache Hadoop是MapReduce计算模型的一个开源发行版本。
-
在Hadoop 6年的发展历程中,它变成了大数据并行和分布式计算领域的首选框架。社区已经为Hadoop在企业中运用做好了准备。Hadoop 1.X版本实现了HDFS的文件追加功能和安全特性,这是对企业用户非常有利的关键特性。
-
MapReduce支持的使用实例有限,通过融入其他的应用模式,Hadoop扩展了它在数据分析领域的领地,并增加了集群资源的利用率。在Hadoop 2.X中,JobTracker被分解,而YARN可以处理集群资源管理和作业调度。MapReduce属于能够运行在YARN上的一种应用模式。
-
Hadoop 2.X将块管理器从文件系统层隔离出来,从而增强了它的存储层。这样它能支持多命名空间并集成其他类型的文件系统。Hadoop 2.X还对存储可用性和快照方面进行了改进。
-
Hadoop的各种发行版都提供了企业级的管理软件、工具、技术支持、培训和其他服务。它们中的大部分在功能上都胜于Apache Hadoop。
MapReduce依然是Hadoop核心中不可分割的部分。在下一章,我们将探讨MapReduce的优化和最佳实践。
from: http://www.ituring.com.cn/tupubarticle/8410