
背景介绍
当算法工程师在本地使用TensorFlow深度学习框架训练好模型后,会创建模型服务器供应用程序调用实现在线推理。由于部署本身存在一定的复杂性,他们需要考虑如何安装TensorFlow Serving相关的依赖,如何实现模型服务的高可用、请求负载均衡、A/B测试、自动伸缩机制等。Amazon SageMaker可以帮助用户快速创建多台模型服务器进行负载均衡,利用云上多可用区的方式实现高可用,并且在请求量变化时可以根据用户配置的策略进行自动扩展或收缩。本文会介绍如何将本地训练好的TensorFlow模型部署到Amazon SageMaker来快速、灵活地创建TensorFlow模型服务器。
1. TensorFlow Serving请求数据格式
在将模型部署到Amazon SageMaker之前,我们首先要了解TensorFlow Serving的SignatureDefs,它标识了保存模型时所需的接受请求函数的输入与输出,不同SignatureDefs下的请求数据格式不同。TensorFlow Serving支持gRPC API与RESTful API两种方式进行请求,本文以RESTful API的方式为例。
- SignatureDefs:
https://www.tensorflow.org/tf...
1.1 Classify与Regress API
Classify与Regress 的SignatureDefs分别支持分类与回归的TersorFlow Serving结构化调用方式。即当Serving的输入函数封装了tf.Example(一种灵活的消息类型,表示{“string”: value}的映射,常用来进行训练过程中的数据流式传输或解析feature_column中的特征列),需要调用该API进行推理。
参考以下代码,在保存模型时指定input_receiver_fn作为接受请求函数,其中定义了将feature_column解析为tf.Example消息类型的过程,然后输入给模型进行推理。
def input_receiver_fn(features):
example_spec = tf.feature_column.make_parse_example_spec(features)
return tf.estimator.export.build_parsing_serving_input_receiver_fn(
example_spec, default_batch_size=5)
model.export_savedmodel(export_dir, input_receiver_fn(features))左右滑动查看更多
在创建模型服务器后,若想对服务器进行请求得到推理结果,就需要将数据构造成Classify与Regress API所能接受的格式,如下所示:
{
// Optional: serving signature to use.
// If unspecifed default serving signature is used.
"signature_name": ,
// Optional: Common context shared by all examples.
// Features that appear here MUST NOT appear in examples (below).
"context": {
"": |
"": |
},
// List of Example objects
"examples": [
{
// Example 1
"": |,
"": |,
...
},
{
// Example 2
"": |,
"": |,
...
}
...
]
}
1.2 Predict API
Predict SignatureDefs支持将tensor作为输入和输出,可通用于分类与回归的推理问题类型。参考以下代码,在input_receiver_fn函数中,读取到数据后构造成tensor,作为模型的输入。
def input_receiver_fn ():
feature_map = {}
for i in range(len(iris_data.CSV_COLUMN_NAMES) -1):
feature_map[iris_data.CSV_COLUMN_NAMES[i]] = tf.placeholder(
tf.float32,shape=[3],name='{}'.format(iris_data.CSV_COLUMN_NAMES[i]))
return tf.estimator.export.build_raw_serving_input_receiver_fn(feature_map)
model.export_savedmodel(export_dir_base=export_dir,serving_input_receiver_fn=input_receiver_fn ())左右滑动查看更多
该情况下对模型服务器发起请求就需要使用Predict API,其所能接受的数据格式如下所示:
{
// (Optional) Serving signature to use.
// If unspecifed default serving signature is used.
"signature_name": ,
// Input Tensors in row ("instances") or columnar ("inputs") format.
// A request can have either of them but NOT both.
"instances": |<(nested)list>|
"inputs": |<(nested)list>| 左右滑动查看更多
1.3 在Amazon SageMaker中向Serving发送请求
在Amazon SageMaker的SDK(https://sagemaker.readthedocs...)中,将上述三种不同的API封装成了三种方法,即创建好Predictor之后,根据上述不同SignatureDefs所能接受的数据格式构造请求,就可以选择调用方法进行推理,Predict API、Classify与Regress API的调用方法如下所示:

2.将已训练好的TensorFlow模型部署到Amazon SageMaker
将模型压缩打包上传到Amazon S3之后,有两种方式可以实现模型的部署。
2.1方法一:不提供inference.py脚本
若不需要对请求中的数据进行前处理和后处理,就不需要提供inference.py脚本,实例化TensorFlowModel对象时只需要指定模型在Amazon S3中的位置,以及相关的role,如下所示:
from sagemaker.tensorflow import TensorFlowModel
model = TensorFlowModel(model_data='s3://mybucket/model.tar.gz', role='MySageMakerRole')
predictor = model.deploy(initial_instance_count=1, instance_type='ml.c5.xlarge')左右滑动查看更多
部署完成之后,在推理时需要根据Serving所使用的SignatureDefs,将数据构造成SignatureDefs可以接受的格式,再调用相关的API进行推理。比如,若使用Classify API进行推理,则需要先将数据构造成1.1节中提到的请求格式,然后调用Predictor的classify方法,将推理数据作为参数传入,即可得到推理结果。
2.2方法二:提供inference.py脚本
若需要对输入模型的数据进行前处理或对推理产生的结果进行后处理,则需要在实例化TensorFlowModel对象时提供inference.py脚本,通过entry_point参数指定,如下所示:
from sagemaker.tensorflow import TensorFlowModel
model = Model(entry_point='inference.py',
model_data='s3://mybucket/model.tar.gz',
role='MySageMakerRole')左右滑动查看更多
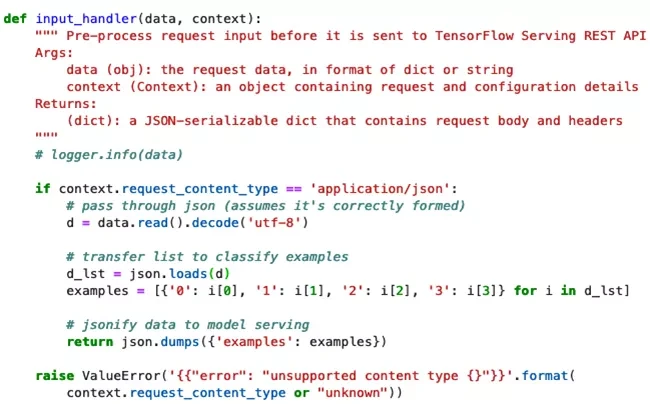
在inference.py的代码中需要定义两个函数,分别是input_handler与output_handler。其中input_handler首先需要对传递进来的序列化对象进行解析。比如TensorFlow Serving Predictor默认的serializer为JSONSerializer,那么在input_handler中就需要对json序列化对象解析,之后就可以对数据进行前处理操作。类似地,在推理前需要把处理好的数据转化为SignatureDefs所能接受的格式。注意,构造SignatureDefs数据格式这个过程是在input_handler中定义的,这么做的好处就是用户无需在请求Serving前完成请求数据格式的定义,让前端传入的数据更加简洁灵活。
- JSONSerializer:
https://sagemaker.readthedocs...
同样,在得到推理结果后,可以把数据后处理过程写在output_handler函数中,通过response_centent_type指定序列化对象,将结果返回给前端。
3. 实验
本实验使用已经训练好的iris模型,展示带有inference.py和不带inference.py在Amazon SageMaker上进行模型部署的过程,并调用Classify API进行推理。实验所需环境:
- 使用cn-northwest-1区域;
- 在Amazon SageMaker中创建一台Jupyter Notebook实例,创建过程可参考官方文档:https://docs.aws.amazon.com/s...
- 下载实验所需的材料:git clone https://github.com/micxyj/aws...,进入文件夹,将tf-byom.zip文件,上传至Notebook环境。
实验步骤如下:
- 打开Notebook命令行,执行以下命令解压zip包;
- cd SageMaker/unzip tf-byom.zip
- 双击打开tf_byom.ipynb笔记本文件,逐步执行notebook中的步骤;
- 可以看到若不提供inference.py,在进行推理前需要构造好Classify SignatureDefs所能接受的数据格式,如下图key为examples的字典:
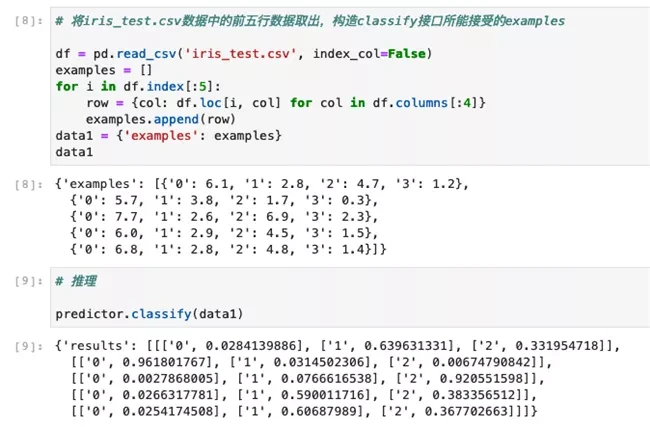
Amazon SageMaker SDK会把推理数据进行序列化传递给Serving,推理完成之后会将结果反序化回前端。
- 在提供了inference.py的场景中,由于在input_handler函数中定义了加载列表生成Classify SignatureDefs数据格式,在调用classify进行推理时只需要传入列表数据即可,如下所示:
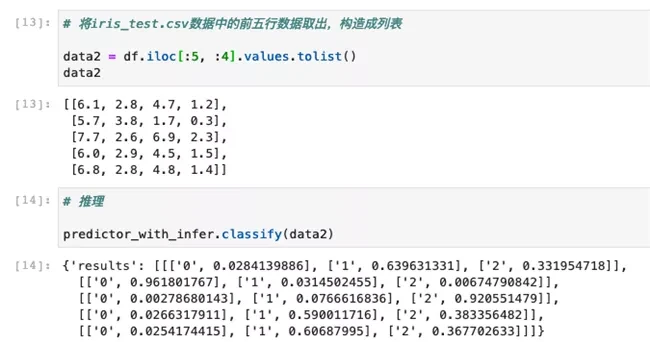
4. 总结
本文介绍了TensorFlow Serving三种不同SignatureDefs的区别以及调用方法,展示了如何将本地训练的模型在Amazon SageMaker上进行部署与推理。通过使用Amazon SageMaker,用户可以快速地将模型进行部署上线,无需进行复杂的配置便可实现高可用的、可扩展的模型服务器架构。
5. 参考资料
[1] https://www.tensorflow.org/tf...
[2] https://www.tensorflow.org/tf...
[3] https://sagemaker.readthedocs...
本篇作者

肖元君
亚马逊云科技解决方案架构师
负责基于亚马逊云科技云计算方案的架构咨询和设计实现,同时致力于数据分析与人工智能的研究与应用。

郭韧
亚马逊云科技人工智能和机器学习方向解决方案架构师
负责基于亚马逊云科技的机器学习方案架构咨询和设计,致力于游戏、电商、互联网媒体等多个行业的机器学习方案实施和推广。在加入亚马逊云科技之前,从事数据智能化相关技术的开源及标准化工作,具有丰富的设计与实践经验。