
作者:张伟辰(璟铭)
随着手机性能的不断提升,在手机端进行复杂的AI计算已经成为各大厂商的核心发展方向,在此之上产生了大量的端智能应用。这种端侧AI计算的模式,使得大量牵涉时效性、成本和隐私考虑的场景实现变成了可能。在这里,我们以广泛使用的文字识别技术(OCR)为例,介绍一下蚂蚁自研移动端OCR技术(xNN-OCR)。
背景介绍
文字识别技术是计算机视觉领域中历史悠久、应用广泛的一个研究方向,特别是随着深度学习技术的发展,其能力空间不断扩大。相比云端计算方式,移动端OCR算法可在离线情况下完成图片中文字提取,对于实时性、隐私保护和成本要求高的场景,有着很大的应用价值。另一方面,基于深度学习的OCR模型越来越复杂,通常具有几十M的参数量以及几百GFlops的计算量,如何在手机有限的计算资源下,完成OCR模型运行是一个极具挑战的任务。在支付宝中,我们结合自研的端侧推理引擎xNN和应用算法的深度优化,研发了又小、又快、又准的xNN-OCR技术产品,从2018年上线到银行卡号识别场景开始,陆续支撑了数十个核心业务的技术升级。本文我们将给大家完整的展开xNN-OCR的技术演进和能力开放情况。
xNN-OCR技术演进
一个端侧模型研发需要经历下面的几个流程:训练数据获取和标注、网络结构设计、训练调参、端侧移植和端侧部署,各个环节相互关联也相互影响。在基础算法方面,xNN-OCR经历了小字库、大字库到基于异构计算的三个模型研发阶段。我们将从核心的数据、网络设计和模型压缩层面分别介绍最新成果。
数据生成
数据像弹药一样,很大程度决定了模型的效果,特别是文字识别场景。中文的组合千变万化,很多场景很难获取到足够的实际数据。针对这个问题,我们探索了基于GAN技术的文字生成技术。在网络设计上,背景提取、文本提取和字体提取的三个编码器分别提取出对应的特征信息,通过字体迁移和背景融合,完成从源文本内容到目标字体与背景的融合。在训练过程中,除了常规的生成和对抗损失外,还加入了识别损失函数监督合成的内容是否正确。同时,我们为了将已有的真实数据使用起来,在训练链路加入Cycle-Path,提升整体数据生成效果。采用这种方式合成的卡证数据,只采用原本10%的数据量,就可以达到采用100%真实数据的识别精度。

xNN-OCR网络架构
有了数据之后,下一步就是模型设计,这里主要介绍xNN-OCR算法中主要的文字行检测、文字行识别和结构化三个部分。
文本检测算法
相比于通用物体检测任务,文本检测任务具有大宽高比和倾斜框的特点。针对这两个问题,传统的Anchor-based的检测方案需要配置非常大量的Anchor,带来计算量的上升。因此我们设计了一个轻量级的检测网络,其中骨干网络基于ShuffleNet的设计思想,采用多层Shuffle结构,网络头部采用Pixel-based的密集预测方式,每个输出图的像素点都会输出类别和框位置回归,经过融合后处理之后得到最终检测结果。为了适应端侧计算环境,通常图输入的分辨率不会过大,带来小目标易丢失和长目标边界不准的问题。我们在训练时采用Instance-balancing + OHEM的方式解决小目标丢失问题,在预测时采用加权融合NMS的方式解决边框预测不准的问题,取得了性能和精度的大幅度提升。
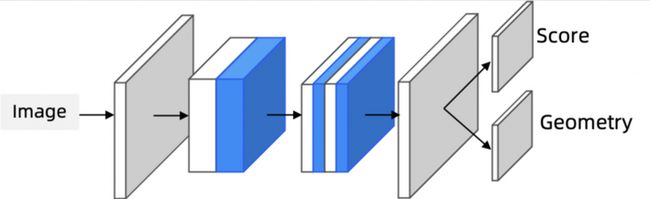
文本识别算法
文字行检测后,对于内容的识别通常采用CRNN的结构,在之前工作的基础上,我们针对骨干网络和网络head设计做了进一步的升级。为了得到一个高性能轻量骨干网络,我们通过NAS面向文本识别场景设计了相应的搜索策略,搜索出目标数据集上性价比最高的网络结构参数。对于CRNN的结构,我们发现模型head部分计算量非常大,占到整体计算量50%以上,这主要是由于Softmax分类的One-hot的稀疏编码方式导致。我们通过将稠密的Hamming编码方式与CRNN模型结合,Head部分耗时相比原本的Softmax分类方案下降约70%。

文字结构化
文字结构化指的是输出文字对应的结构信息,例如卡证场景中将OCR算法结果整理为Key-Value的输出格式。传统的结构化方法通常是基于文本位置和识别结果设计规则,调试较为复杂,并且工程上需要针对不同卡证分别开发处理逻辑,部署和维护成本高。我们从文本行检测入手,提出Instance检测算法进行卡证结构化。简单来讲,就是在检测网络头部增加文本框的类别信息进行学习,在结构化时直接将文本框的识别内容与类别对应起来。这种方法可以节省识别运算耗时,简化上线调试部署流程,同时因为模型学习了字段间的隐含关系,提升了整体的识别精度。
模型压缩
为了提升端侧模型研发性能和效果,xNN在之前基于已有结构进行轻量化的基础上,自研了xNAS算法工具,提供模型结构搜索能力。在主流NAS搜索框架基础上,xNAS扩展了端侧模型关心的计算量和硬件耗时等因素,结合超参搜索(HPO)、Multi-Trial NAS、One-Shot NAS等算法,搜索最优的移动端模型结构。在OCR的场景,我们重点针对识别网络使用了NAS的方案,通过对每个Channel和卷积层数进行搜索,使模型降低了70%的计算量并有2%的精度提升。
在模型压缩方面,剪枝、浮点量化、定点化功能对于推理性能提升至关重要,特别是定点化能力,可有效降低模型尺寸和运行耗时。为解决在OCR场景中定点参数难确定导致的精度问题,xNN结合NAS思想提出qNAS算法,有效提升了定点化精度。我们对文本检测和识别模型进行了qNAS量化训练,在精度下降不到1%的情况下,模型包大小下降至原本1/4左右,端侧CPU上运算时耗下降约50%。
xNN-OCR 性能精度
在基础模型研发的基础上,我们将能力逐步的覆盖到了大多数OCR应用场景,包括通用OCR识别以及各种卡证类识别,在保证较高精度的同时,可以在移动端计算平台上达到近似实时运算的性能,具体指标如下(耗时为高通855上CPU单线程运算耗时):

能力开放
xNN-OCR作为蚂蚁自研的移动端OCR技术,实现了OCR识别像扫码一样顺畅。目前在支付宝端内,已经广泛使用在安全风控、证件上传和数字金融等核心应用场景。为了让更多用户和外部业务能够使用到xNN-OCR,我们在支付宝端内通过小程序插件的方式提供给外部开发者使用。支付宝外的用户可以用过蚂蚁mPaaS产品和阿里云视觉开放平台以离线SDK形式接入。
支付宝小程序接入可参考:https://forum.alipay.com/mini-app/post/29301014
支付宝外使用可通过钉钉群(23124039)咨询mPaaS产品或者访问阿里云视觉开放平台接入离线SDK。
为了方便广大开发者体验,我们将已有的插件聚合在了“小程序体验中心“,可通过支付宝扫描下面的二维码进行体验。

关注【阿里巴巴移动技术】,每周 3 篇移动技术实践&干货给你思考!