Pytorch实战_图像降维及聚类
0. 文章说明
首先需要指出的是,代码是从李宏毅老师的课程中下载的,并不是我自己码的。这篇文章主要是进行了部分算法的原理说明,并在原代码中加了一些讲解和注释。
1. 任务简介
本次 Pytorch 实战的目标是做图像的降维及聚类。所谓降维,就是将图像向一个低维空间去投影,比如将一个 28 × 28 28 \times 28 28×28 大小的图像投影到一个 2 2 2 维度的空间。这样做的目的是去除一些多余的信息,同时也方便向我们的客户或者老板展示。在降维之后,我们可以对降维后的图像进行聚类,如: Kmeans算法,或者简单的计算各个图像之间的相似度(当两个图像的相似度大于一定阈值的时候就将二者归为一类)。
2. 方法简介
接下来我们简单介绍一下本次实战需要用到的方法:
- T-SNE
- Kernel-PCA
- Mini Batch KMeans
- Auto-Encoder
2.1 T-SNE
T-SNE 算法的全名是 T-distributed Stochastic Neighbor Embedding,是一种在图像处理里面经常使用到的降维工具。T-SNE 的思想是将数据投影后,尽量保持原有数据之间的相似度。下图是摘自李宏毅老师的 PPT ,可以看出,T-SNE 算法构造了一个关于相似度的概率分布,同时要求投影后数据关于相似度的概率分布函数和原有的尽可能接近,接近程度的衡量指标使用的是KL散度。

T-SNE 算法中相似度的具体构造如下图所示。相比于 SNE 算法,T-SNE 算法改变了投影后数据的相似度计算方式,使得原数据集中相距较远的数据点在投影后间隔更大。
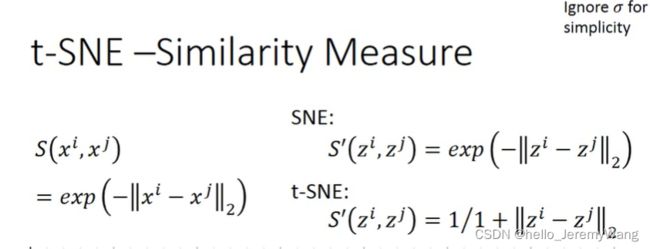
2.2 Kernel-PCA
Kernel-PCA 就是核PCA,其实该方法的原理和我们在 SVM 中见到的非线性 SVM算法里的核函数一致。一般来说,PCA 适用于数据的线性降维。而Kernel-PCA可实现数据的非线性降维,用于处理线性不可分的数据集。
Kernel-PCA的大致思路是:对于输入空间 (Input space) 中的矩阵 X X X ,我们先用一个非线性映射把 X X X 中的所有样本映射到一个高维甚至是无穷维的空间(称为特征空间,Feature space),(使其线性可分),然后在这个高维空间进行PCA降维。Kernel-PCA 的具体推导可以参看这篇博客 核主成分分析(Kernel-PCA)。
2.3 Mini Batch KMeans
Mini Batch KMeans 其实是为了减少计算量,每次只抽出一部分数据进行计算,并在计算的过程中不断加入新的数据。具体的算法步骤可以参考下面这个图片以及这篇博客 【聚类算法】MiniBatchKMeans算法。

2.4 Auto-Encoder
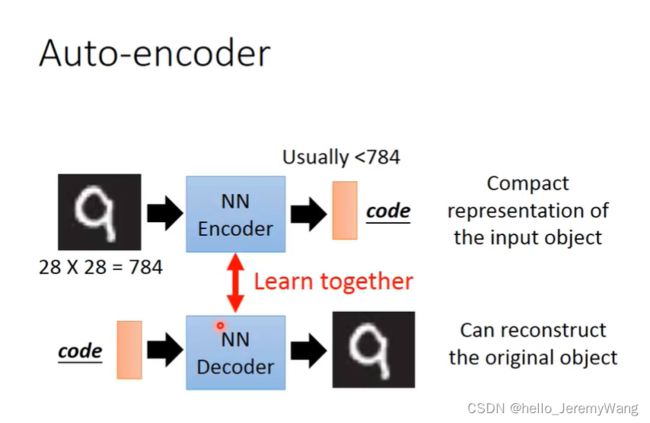
其实我们观察很多投影方法,其实都是在找到一个投影矩阵,然后将现有的数据投影到新的空间。那我们不免就会想:全连接的神经网络不就是产生一个投影矩阵,对原有的数据进行操作吗?我们能不能用神经网络去将数据进行投影呢?答案是能的。这就是 Auto-Encoder 的思想。
我们从下面这种 PPT 来看一下,我们的目的是将一个图片投影到一个更小的空间,但是神经网络需要一个输出的真值来计算损失,进而通过后向传播来不断更新参数。可是我们没有真值,这就造成网络没法训练了。那怎么办呢?我们就想到类似于 Seq2seq 模型中的结构,先编码,再解码,最终的目标是使得最后输出的图像和原有的图像尽可能相似。训练结束后,中间的橙色的部分,就是我们投影后的结果。
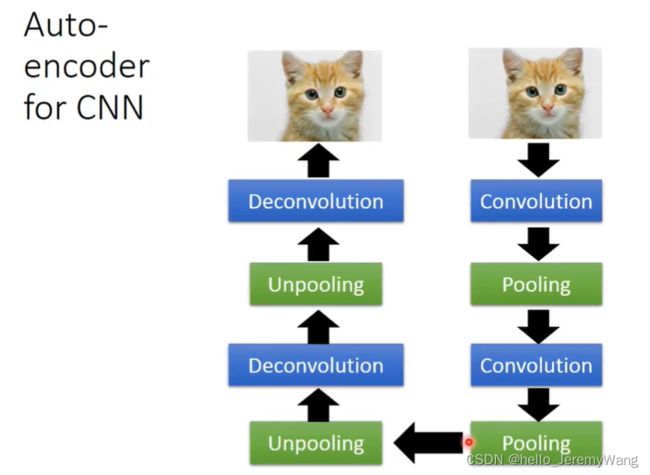
那图像该怎么办呢?中间的编码层和解码层该如何构造呢?这时我们通常是这么做的:编码层主要是卷积层和池化层的堆叠;解码层通常是 Upooling 层和 Deconvolution 层的堆叠。
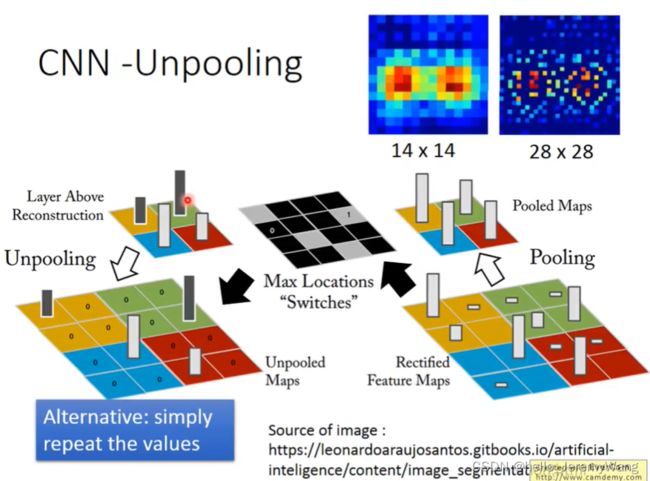
Unpooling 是做什么呢?Pooling 是将每四个像素值中的最大值保存下来,进而将一个 4 × 4 4 \times 4 4×4 的图像压缩到 2 × 2 2 \times 2 2×2 。而 Unpooling 的一种做法是先将最大值的位置记录下来,之后把 2 × 2 2 \times 2 2×2的图像扩展到 4 × 4 4 \times 4 4×4 ,再将最大值赋予到之前的位置,并将其余位置的值设为0。
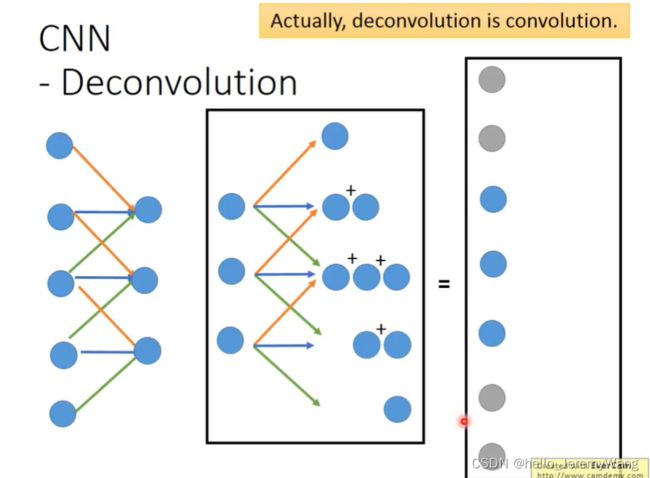
Deconvolution 是做什么呢?如下图所示,Convolution 是通过一个卷积核,每3个数据乘以对应的系数并相加,得到新的值。而 Deconvolution 是将每个数据乘以三个系数并保存到相应的位置,待所有的数据都乘完后,再将相应位置的数据相加得到最好的值。
3. 代码实战
首先下载数据
!gdown --id '1BZb2AqOHHaad7Mo82St1qTBaXo_xtcUc' --output trainX.npy
!gdown --id '152NKCpj8S_zuIx3bQy0NN5oqpvBjdPIq' --output valX.npy
!gdown --id '1_hRGsFtm5KEazUg2ZvPZcuNScGF-ANh4' --output valY.npy
!mkdir checkpoints
!ls
定义我们的 preprocess:将图片的像素值从介于 0~255 的 int 线性转化为 0~1 之间的 float。
import numpy as np
def preprocess(image_list):
""" Normalize Image and Permute (N,H,W,C) to (N,C,H,W)
Args:
image_list: List of images (9000, 32, 32, 3)
Returns:
image_list: List of images (9000, 3, 32, 32)
"""
image_list = np.array(image_list)
image_list = np.transpose(image_list, (0, 3, 1, 2))
image_list = (image_list / 255.0) * 2 - 1
image_list = image_list.astype(np.float32)
return image_list
定义 Dataset 类
from torch.utils.data import Dataset
class Image_Dataset(Dataset):
def __init__(self, image_list):
self.image_list = image_list
def __len__(self):
return len(self.image_list)
def __getitem__(self, idx):
images = self.image_list[idx]
return images
from torch.utils.data import DataLoader
trainX = np.load('trainX.npy')
trainX_preprocessed = preprocess(trainX)
img_dataset = Image_Dataset(trainX_preprocessed)
这边提供一些有用的 functions。 一个是计算 model 参数量的(report 会用到),另一个是固定训练用的随机数种子(以便 reproduce)。
import random
import torch
def count_parameters(model, only_trainable=False):
if only_trainable:
return sum(p.numel() for p in model.parameters() if p.requires_grad)
else:
return sum(p.numel() for p in model.parameters())
def same_seeds(seed):
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # if you are using multi-GPU.
np.random.seed(seed) # Numpy module.
random.seed(seed) # Python random module.
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
定义我们的 Auto-Encoder 模型
import torch.nn as nn
class AE(nn.Module):
def __init__(self):
super(AE, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(3, 64, 3, stride=1, padding=1),
nn.ReLU(True),
nn.MaxPool2d(2),
nn.Conv2d(64, 128, 3, stride=1, padding=1),
nn.ReLU(True),
nn.MaxPool2d(2),
nn.Conv2d(128, 256, 3, stride=1, padding=1),
nn.ReLU(True),
nn.MaxPool2d(2)
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(256, 128, 5, stride=1),
nn.ReLU(True),
nn.ConvTranspose2d(128, 64, 9, stride=1),
nn.ReLU(True),
nn.ConvTranspose2d(64, 3, 17, stride=1),
nn.Tanh()
)
def forward(self, x):
x1 = self.encoder(x)
x = self.decoder(x1)
return x1, x
这个部分就是主要的训练阶段。我们先将准备好的 dataset 当做参数喂给dataloader。 将 dataloader、model、loss criterion、optimizer 都准备好之后,就可以开始训练。 训练完成后,我们会将 model 存下來。
import torch
from torch import optim
model = AE().cuda()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-5, weight_decay=1e-5)
model.train()
n_epoch = 100
same_seeds(0)
# 準備 dataloader, model, loss criterion 和 optimizer
img_dataloader = DataLoader(img_dataset, batch_size=64, shuffle=True)
# 主要的訓練過程
for epoch in range(n_epoch):
for data in img_dataloader:
img = data
img = img.cuda()
output1, output = model(img)
loss = criterion(output, img)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
torch.save(model.state_dict(), './checkpoints/checkpoint_{}.pth'.format(epoch+1))
print('epoch [{}/{}], loss:{:.5f}'.format(epoch+1, n_epoch, loss.data))
# 訓練完成後儲存 model
torch.save(model.state_dict(), './checkpoints/last_checkpoint.pth')
计算准确率和画图的函数,以便于之后使用。
import numpy as np
def cal_acc(gt, pred):
""" Computes categorization accuracy of our task.
Args:
gt: Ground truth labels (9000, )
pred: Predicted labels (9000, )
Returns:
acc: Accuracy (0~1 scalar)
"""
# Calculate Correct predictions
correct = np.sum(gt == pred)
acc = correct / gt.shape[0]
# 因為是 binary unsupervised clustering,因此取 max(acc, 1-acc)
return max(acc, 1-acc)
import matplotlib.pyplot as plt
def plot_scatter(feat, label, savefig=None):
""" Plot Scatter Image.
Args:
feat: the (x, y) coordinate of clustering result, shape: (9000, 2)
label: ground truth label of image (0/1), shape: (9000,)
Returns:
None
"""
X = feat[:, 0]
Y = feat[:, 1]
plt.scatter(X, Y, c = label)
plt.legend(loc='best')
if savefig is not None:
plt.savefig(savefig)
plt.show()
return
- 接着我们使用训练好的 model,来预测 testing data 的类别。
- 由于 testing data 跟 training data 一样,因此我们使用同样的 dataset 来操作 dataloader。与 training 不同的地方在于 shuffle 这个参数在这边是 False。
- 当准备好 model 和 dataloader,我们就可以进行预测了。
- 我们只需要 encoder 的结果(latents),利用 latents 进行 clustering 之后,就可以分类了。
import torch
from sklearn.decomposition import KernelPCA
from sklearn.manifold import TSNE
from sklearn.cluster import MiniBatchKMeans
def inference(X, model, batch_size=256):
X = preprocess(X)
dataset = Image_Dataset(X)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=False)
latents = []
for i, x in enumerate(dataloader):
x = torch.FloatTensor(x)
vec, img = model(x.cuda())
if i == 0:
latents = vec.view(img.size()[0], -1).cpu().detach().numpy()
else:
latents = np.concatenate((latents, vec.view(img.size()[0], -1).cpu().detach().numpy()), axis = 0)
print('Latents Shape:', latents.shape)
return latents
def predict(latents):
# First Dimension Reduction
transformer = KernelPCA(n_components=200, kernel='rbf', n_jobs=-1)
kpca = transformer.fit_transform(latents)
print('First Reduction Shape:', kpca.shape)
# # Second Dimesnion Reduction
X_embedded = TSNE(n_components=2).fit_transform(kpca)
print('Second Reduction Shape:', X_embedded.shape)
# Clustering
pred = MiniBatchKMeans(n_clusters=2, random_state=0).fit(X_embedded)
pred = [int(i) for i in pred.labels_]
pred = np.array(pred)
return pred, X_embedded
def invert(pred):
return np.abs(1-pred)
def save_prediction(pred, out_csv='prediction.csv'):
with open(out_csv, 'w') as f:
f.write('id, label\n')
for i, p in enumerate(pred):
f.write(f'{i},{p}\n')
print(f'Save prediction to {out_csv}.')
# load model
model = AE().cuda()
model.load_state_dict(torch.load('./checkpoints/last_checkpoint.pth'))
model.eval()
# 準備 data
trainX = np.load('trainX.npy')
# 預測答案
latents = inference(X=trainX, model=model)
pred, X_embedded = predict(latents)
# 將預測結果存檔,上傳 kaggle
save_prediction(pred, 'prediction.csv')
# 由於是 unsupervised 的二分類問題,我們只在乎有沒有成功將圖片分成兩群
# 如果上面的檔案上傳 kaggle 後正確率不足 0.5,只要將 label 反過來就行了
save_prediction(invert(pred), 'prediction_invert.csv')
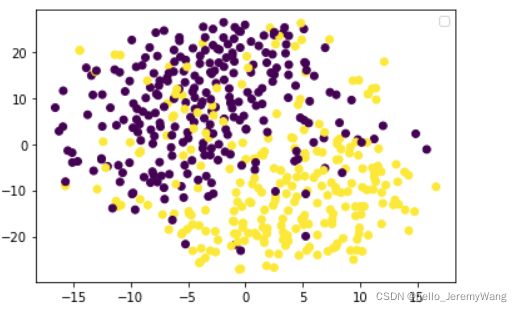
將 val data 的降维结果 (embedding) 与他们对应的 label 可视化一下。
valX = np.load('valX.npy')
valY = np.load('valY.npy')
# ==============================================
# 我們示範 basline model 的作圖,
# report 請同學另外還要再畫一張 improved model 的圖。
# ==============================================
model.load_state_dict(torch.load('./checkpoints/last_checkpoint.pth'))
model.eval()
latents = inference(valX, model)
pred_from_latent, emb_from_latent = predict(latents)
acc_latent = cal_acc(valY, pred_from_latent)
print('The clustering accuracy is:', acc_latent)
print('The clustering result:')
plot_scatter(emb_from_latent, valY, savefig='p1_baseline.png')
可以看出,降维效果蛮不错的。
使用 test accuracy 最高的 autoencoder,从 trainX 中,取出 index 1, 2, 3, 6, 7, 9 这 6 张图片,画出他们的原图以及 reconstruct 之后的图片(即从解码器输出的图片)。
import matplotlib.pyplot as plt
import numpy as np
# 畫出原圖
plt.figure(figsize=(10,4))
indexes = [1,2,3,6,7,9]
imgs = trainX[indexes,]
for i, img in enumerate(imgs):
plt.subplot(2, 6, i+1, xticks=[], yticks=[])
plt.imshow(img)
# 畫出 reconstruct 的圖
inp = torch.Tensor(trainX_preprocessed[indexes,]).cuda()
latents, recs = model(inp)
recs = ((recs+1)/2 ).cpu().detach().numpy()
recs = recs.transpose(0, 2, 3, 1)
for i, img in enumerate(recs):
plt.subplot(2, 6, 6+i+1, xticks=[], yticks=[])
plt.imshow(img)
plt.tight_layout()
可以看出,还原度还可以,说明模型效果是不错的。
