论文阅读笔记 | Transformer系列——Focal Transformer
如有错误,恳请指出。
文章目录
- 1. Introduction
- 2. Method
-
- 2.1 Model architecture
- 2.2 Focal self-attention
- 3. Result
paper:Focal Self-attention for Local-Global Interactions in Vision Transformers
code:未开源

摘要:
Vision Transformer及其变体在各种计算机视觉任务中显示出了巨大的前景,通过自注意力捕捉短期和长期视觉依赖的能力是成功的关键。但是其计算复杂度比较大,特别是对于高分辨率的任务。
目前许多研究试图通过应用粗粒度全局注意或细粒度局部注意来减少计算和内存开销并提高性能。然而,这两种方法都削弱了多层Transformer原有的自注意机制的建模能力,从而导致次最优解。为此,作者提出了Focal Self-attention,这是一种融合了细粒度局部和粗粒度全局交互的新机制。
Focal Self-attention让每个token以细粒度关注其最近的周围token,并以粗粒度关注远处的token,因此可以有效地捕获短期和长期的视觉依赖性。(这个是这篇paper的核心思想)
基于Focal Self-attention,作者提出了Focal Transformer架构,在一系列视觉任务中获得了比较好的效果:
- achieve 83.5% and 83.8% Top-1 accuracy(51.1M / 89.8M)
- 58.7/58.9box mAPs and 50.9/51.3mask mAPs on COCO mini-val/test-dev
- 55.4mIoU on ADE20K for semantic segmentation
1. Introduction
Transformer的除了cv、nlp领域外,它还被应用于各种时间理解任务,如动作识别,目标跟踪,场景流量估计。
在Transformer中,self-attention计算模块是其关键的组成部分,正如cnn中的卷积操作一样是架构的核心。在每个Transformer层,它支持不同图像区域之间的全局内容依赖交互,以便进行短期和长期依赖进行建模。

作者通过对self-attention进行可视化操作后,可以观察到self-attention确实学会了同时关注局部与全局的信息。但是,当图像的分辨率比较大且对于一些密集预测任务时,其平方次的计算复杂度是比较消耗资源的。目前的研究要么利用粗粒度全局自注意,要么利用细粒度局部自注意(Swin transformer)来减少计算负担。但是,作者说道这两种方式都对最初的self-attention的同时建模短期和长期视觉依赖的能力有一定的削弱。
为此,作者提出Focal Transformer来结合以上的两种思想,同时捕获局部和全局交互。考虑到邻近区域之间的视觉依赖关系通常比远处区域更强,为此只在局部区域执行细粒度自注意,而在全局区域执行粗粒度自注意。如图1所示,特征图中的query token以最细的粒度关注其最近的环境。然而,当它进入更远的区域时,它会关注概括的标记以捕获粗粒度的视觉依赖。
区域距离查询位置越远,粒度越粗,可以有效覆盖整个高分辨率特征图,同时在自注意计算中引入的token数量要比全自注意机制少得多。因此,它能够有效地捕捉短期和长期的视觉依赖。
2. Method
2.1 Model architecture
Focal Transformer的结构与Swim Transformer,CSWin Transformer的结构类似,如下图所示:
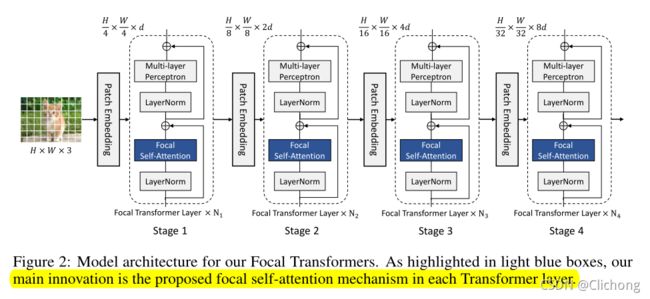
大致结构是一样的,不同的只是将self-attention变成了Focal self-attention。
首先将图片分成4x4的patch(所以patch的线性信息为4x4x3=48),然后进入Patch Embedding层,Patch Embedding层为卷积核和步长都为4的卷积,然后将其投影到具有维数d的隐藏特征中。得到了这个特征图之后,就将其传递给一系列的focal Transformer blocks。在每个stage之后,使用另一个patch embedding层将feature map的空间大小减少两倍,feature的维数增加2倍。
那么,应该采用什么样的办法来减少计算量呢?原始的SA将query token和其他所有token都进行了相似度的计算,因为无差别的计算了所有token的相似度,导致这一步是非常耗时、耗显存的。但其实,对于图片的某一个点,与这个点的信息最相关的事这个点周围的信息,距离越远,这个关系应该就越小。所以作者就提出了,对于这个点周围的信息进行细粒度的关注,距离这个点越远,关注也就越粗粒度。
2.2 Focal self-attention
对局部区域采用细粒度自注意力而对全局区域采用粗粒度自注意力可以实现与原始的self-attention关注一样多的区域,但是成本更低。下图展示了self-attention与Focal self-attention的感受野变化。

可以看见,使用Focal self-attention同时结合局部与全局的注意力操作所获得的感受野要比普通的self-attention要大的。而查询每个query位置附近的token的复杂度也是比较大,解决的方法是将输入特征映射划分为窗口,在窗口层面进行focal self-attention。
这里我不再分其他小节,直接一步到位的介绍Focal self-attention的实现思想,其主要操作过程如图所示:

首先介绍3个关键参数:
- Focal levels:可以表示FSA中对特征关注的细粒度程度(这里采用了3个等级)
- Focal window size:将token划分成了多个sub-window,focal window size指的是每个sub-window的大小
- Focal region size:横向和纵向的sub-window数量
假设,某一个stage之前的输入特征图为20x20xd,表示有20x20个token,然后每个tokne的信息维度是d,首先作者将其划分为5x5的窗口,每个窗口包含4x4个token,接着就进行Focal Self-attention操作。
这里,作者将Self-attention分为了3个层级,分别对应着细粒度自注意,粗粒度自注意,还有更粗粒度的自注意力,分别为level1,level2,level3。
- 对于level1,由于是细粒度操作,每个窗口的大小设置为1( s w = 1 s_{w}=1 sw=1),取附近的8个窗口( s r = 8 s_{r}=8 sr=8)。token的范围就是1x8=8个。
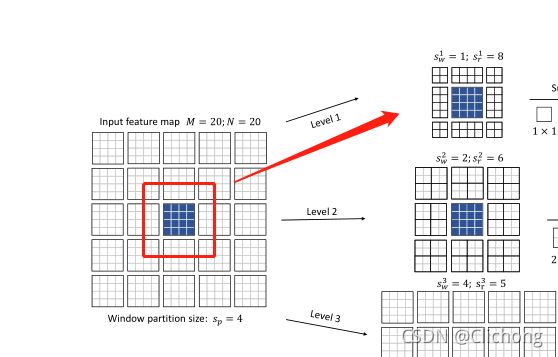
- 对于level2,由于是粗粒度操作,每个窗口的大小设置为2( s w = 2 s_{w}=2 sw=2,也就是包含2x2个token),取附近的6个窗口( s r = 6 s_{r}=6 sr=6)。token的范围就是2x6=12个。
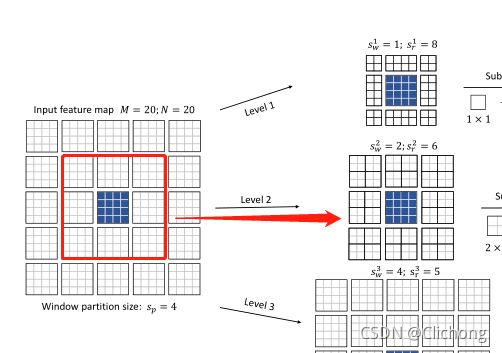
- 对于level3,由于是粗粒度操作,每个窗口的大小设置为4( s w = 4 s_{w}=4 sw=4,也就是包含4x4个token),取附近的5个窗口( s r = 5 s_{r}=5 sr=5)。token的范围就是4x5=20个。
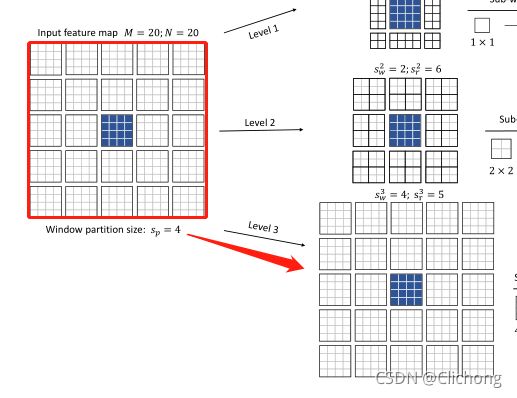
那么,现在对于每个层级都获得了其所对应范围的token数量,对于level1的token,进行一个池化处理将每个窗口压缩成1x1的信息(其实也可以不作处理,因为本来就是1x1的token),而调用对于level2,level3的每个窗口,都进行压缩处理,所以每层得到的特征图是不一样的,其与所构成的窗口的大小有关。对于level1,窗口数量是8x8,所以池化后得到的特征图也是8x8,对于level2,窗口数量是6x6,所以池化后得到的特征图也是6x6,level3类似的,得到的是5x5的特征图。然后将其展平为1维的vector,方面一会作self-attention处理,如图所示:
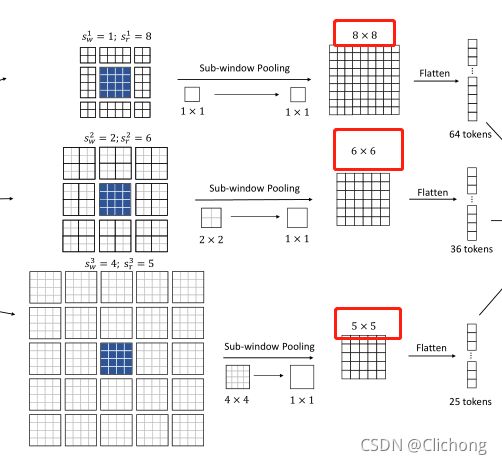
将以上进行细粒度与粗粒度提取到的token拼接在一起,这个就是中心蓝色块区域对于局部与全局的信息。将长度为125的token列表再进行线性分别投影作为value与key,再与蓝色部分的需要查询的token(需要同样进行一个线性投影)做一个普通的Multi-head Self-Attention(这里线性投影的想法是让value,key,query的维度长度相同)。
以上流程就是Focal Self-Attention的处理流程,可以直观的感觉到,从做法上确实同时结合了局部与全局的信息进行自注意力处理。
3. Result
-
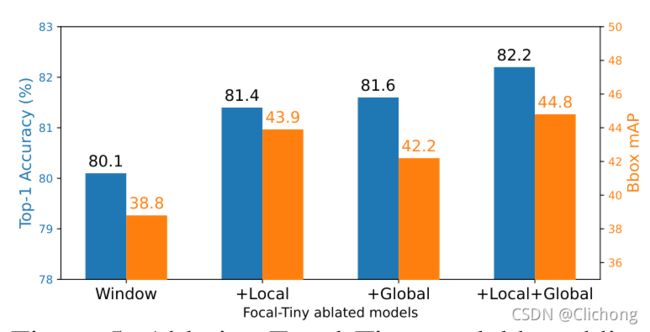
消融实验:
-
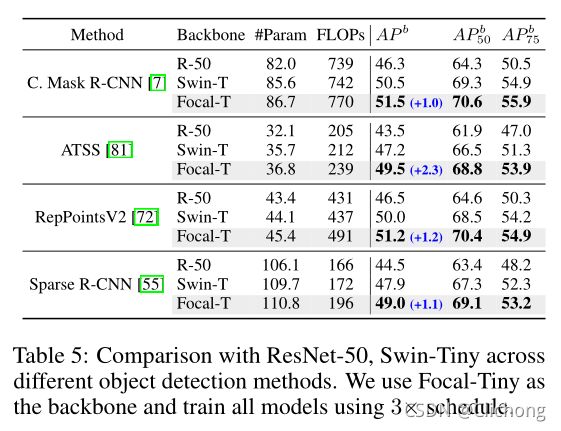
作为backbone的效果:
-
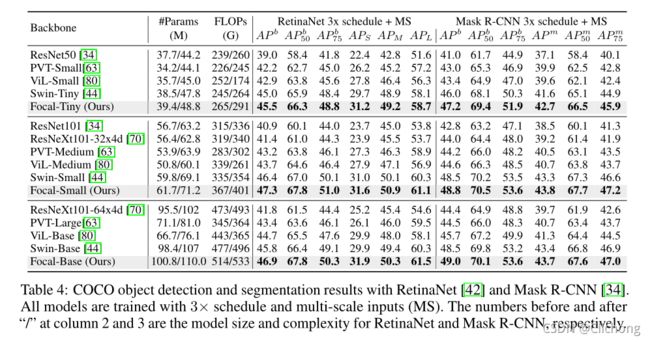
分类任务与检测任务的性能对比:
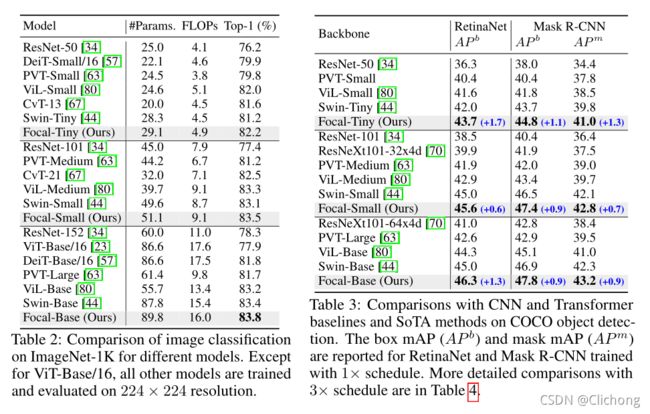
这里可以看见,在分类任务中,Focal Transformer的参数量要比Swin Transformer的参数量要大的,但是性能提升了0.4个点,所以有观点认为这两者均是SOTA,暂时还不能说明Focal Transformer超越了Swin Transformer。 -
语义分割效果对比:
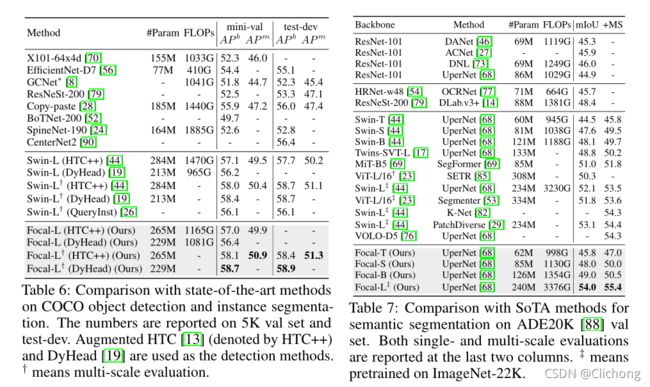
-
降低层数与Swin的对比:
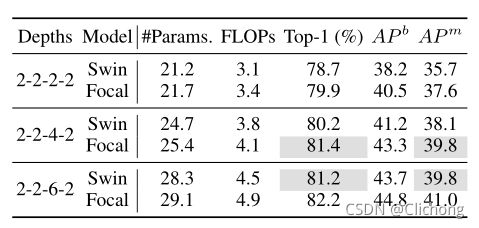
ps:这里可以看见参数量为25.4(2-2-4-2)的Focal Transformer要比28.3(2-2-6-2)的Swin Transformer的效果还要好,说明Focal Transformer确实有其优势。
总结:
作者提出了同时结合细粒度自注意力与粗粒度自注意力的结合来做self-attention的计算,从而实现有效的local-global信息交互,且在同等层数下其获得的感受野范围要更高。不过,从结果也可以看出,其参数量比Swin是要大的,只是一定程度上减少了计算复杂度的问题。
ps:感觉绝大多数的博文都没有细节的讲解核心部分,然后有时直接看论文还是有点懵,这篇paper推荐油管的一个讲解视频:https://www.youtube.com/watch?v=YH319yyeoVw