一、OLAP在唯品会演进迭代
1.1 Presto/Kylin在唯品会的使用
Presto作为当前唯品会OLAP主力军,经历了数次架构和使用方式演进。当前阶段,我们Presto共有物理机500多台,服务于20多个线上业务,日均查询高峰可达500万次,每天读取和处理接近3PB数据。

在业务应用上Presto从最初只有魔方、自助分析两个业务使用,发展到现在接入20个业务,基于业务使用实践,每个阶段我们对Presto都有相应改进。
1.1.1集群统一接入管控
定制化Presto管理工具Spider/Nebula(新版),做到多集群路由,集群HA,负载均衡,查询回溯,全链路监控等。
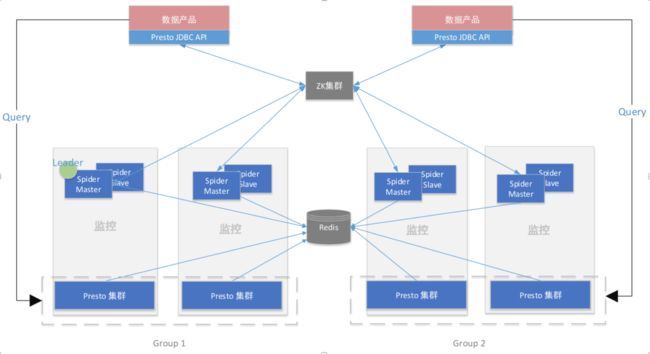
我们定制了Presto Server和Client。用自研管理工具Spider/Nebula从Presto暴露的API和系统表里获取到节点和查询信息,一方面将查询落入mysql,通过etl-job落入hive便于存储和分析;一方面根据集群查询数和节点信息来给该集群打分。用户可以事先在Spider里给Presto集群划分group,同一个group的集群coordinator信息被我们统一保存到zk中。这样用户查询presto时,在本地调用定制presto-client或者presto-jdbc来连接presto集群之际,就会通过zk获取当前业务所属group中打分最低的集群(负载最低)进行连接查询。当有集群处于维护状态或者连不通时,路由会自动感知摘除这个节点的coordinator信息,这样查询将不会打到这个集群上,同步保障了Presto的HA。
1.1.2 Presto容器化
Presto上云接入K8S,可以智能扩缩容Presto集群,做到资源合理调度、智能部署等功能。标准配置每个Presto的Worker 40vCPU/110G内存,每个集群100个Worker节点。

500多台物理机分批改造,让用户业务无感,随之带来的提升也很明显。
★后台presto-k8s集群是配置完全相同、算力相同的集群。用户的业务只需要在client里配置一个虚拟IP,我们就会使用路由功能为他分配一到N个集群。不同业务允许交叉和隔离。这种操作完全是动态的,不需要重启集群,算力也是均衡的。
★在查询比较集中,大促、流量比较大时,我们可以快速合并集群,动态删除部分集群,让其他集群快速扩容worker。用户在使用过程中是无感知的。
★部署Presto on k8s变得十分便捷。我们只需要在k8s管理平台上点击页面,填入集群名称,几分钟内就可以拉起一个标准化的Presto集群,域名跟集群名有规则对应。这样删除集群、新增集群代价非常小。
★由于网络、内存、反亲和性部署使得整个Presto-k8s集群处于相对均衡稳定状态,集群稳定性得到了大大的提升。我们观察了物理机的CPU、内存等指标,机器变得饱和且稳定。
★安装包和配置分离、k8s自动部署模式,使得所有集群的升级变得简单、快速、易操作。
自此,唯品会Presto走上了集群全面容器化的阶段。
1.2 Clickhouse的引入
随着业务对于OLAP要求越来越高,部分业务场景Presto和Kylin无法满足其需求。比如百亿JOIN百亿(Local Join)的低延迟实时数据场景和对中等qps的查询平均响应时间要求低于1秒的OLAP使用场景等,我们把目光转向”大家都说快“的Clickhouse。
| Presto | Kylin | Clickhouse | |
|---|---|---|---|
| 数据存储 | 本身不存储,依赖catalog的存储 | 中间文件存储在HDFS,结果文件存储在HBASE | Zookeeper保存元数据,数据存储在本地,且会压缩 |
| 查询 | 比较均衡,适配各种ADHOC场景 | 查询结果数据比Presto往往要快,得益于预计算 | 比Presto快的ADHOC能力,但是join多分布式表能力较弱 |
| 数据读写 | 借助connector来完成读写,不支持更新 | 读写Hbase。中间数据会读写Hdfs | 支持读写,不能更新,有伪更新 |
| 维护 | 我们自己开发了Presto运维工具,且额外依赖了redis和Zookeeper | 维护Kylin本身和一套Hbase | 额外维护Zookeeper |
| 应用场景 | 应对各种Adhoc和自助取数,ETL场景,应用最广 | 自助分析里,Presto解决不了的超大查询 | 百亿级数量级下 大宽表聚合、复杂查询等 |
1.3 ClickHouse在业务的部署架构和模式
我们在使用中发现 Clickhouse有如下优势:
★大宽表查询性能优异,其主要分析都是大宽表的sql聚合。ClickHouse整个聚合耗时都非常小,性能好,并且具有量级提升。
★单表性能分析以及分区对其的join计算都能取得很好的性能优势。比如百亿数量级join几十亿数量级的大表关联大表的场景,在24C 128G * 10 shard (2副本) 通过优化取得了10s左右的查询性能。
目前我们支持的业务主要是实验平台、agamotto监控、OLAP 查询日志。
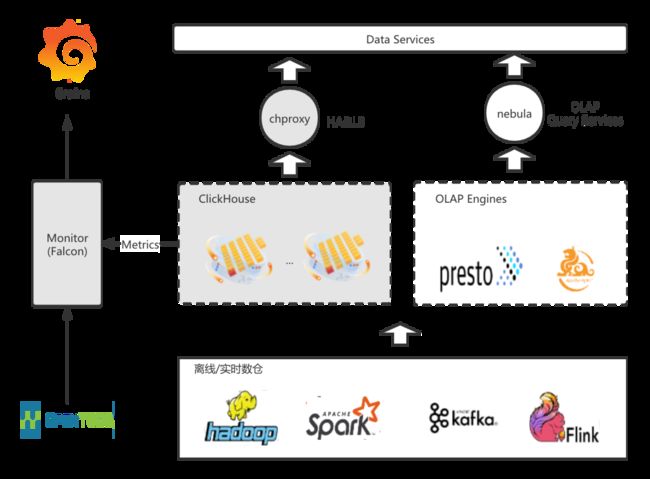
二、实时数据入ClickHouse
2.1 Flink写ClickHouse
2.1.1 Flink写入分布式表
最初我们使用分布式表写入是为了快速验证一些功能和性能,比如分布式表在建表时支持sharding_key和数据写入支持各种策略,分布式表的建表示例:
Distributed(logs, default, hits[, sharding_key[, policy_name]])
为了实现join时完全local join,我们在写入分布式表时,sharding_key就是join的column,policy_name设定为murmurHash3_64(sharding_key),实现起来相对比较简单。为了支持写入HA ,我们配置连接的URL有多个,如果某个host出现连接,会重连另外一个host。下面附上一些实践小经验:
★ck 适合小并发 大批次写入,否则会报错:典型的merge速度跟不上写入;
★本地表url填写的地址只需要一个(实际会根据这个地址查询集群分片信息,根据hash策略做哈希),分布式表可以一个或多个;
★如果是本地表写入推荐基于字段的一致性哈希,可以相对做到数据均衡,如果是分布式表写入推荐至少2个节点的分布式表写入 。
整体写入架构如下图所示:

2.1.2 Flink写入本地表
Flink写入分布式表能完成功能逻辑,但在性能和可靠性上还是略微有差异:
★由于数据是由ClickHouse节点做二次分发,会占用写入分布式表节点比较多的内存;
★集群节点异常后,导致分布式表无法准确把数据分发到新节点。
基于以上问题,我们在Flink的ClickHouse Connector端做了相应改造,支持写入本地表的相关功能。主要流程如下:
★根据库名和表名查system.tables获取表的engine信息(SELECT engine_full FROM system.tables WHERE database = ? AND name = ? )
★解析engine信息,获取集群名、本地表名;
★根据集群名,查system.clusters获取集群分片节点信息 (SELECT shard_num, host_address FROM system.clusters WHERE cluster = ?),得到TreeMap
★根据shard配置信息,初始化List
★当shard内,个别节点负载比较高或查询有热点时,会导致batch flush失败,这个时候需要做异常时重连操作。
究竟某条数据过来sink 到哪个shard,我们定义了RowData 到ClickHouseShardExecutor 的分区接口,并实现了3种分区策略round-robin轮训 、random随机分区、field-hash基于字段的一致性哈希等策略,通过 sink.partition-column 参数指定分区字段,保证相同分区字段哈希到同shard内。整体架构如下图所示:

Flink数据写入的时序图可以参考如下所示:

三、实验平台数据自助分析
3.1 实验平台简要介绍
唯品会实验平台是通过配置多维度分析和下钻分析,提供海量数据的A/B-test实验效果分析的一体化平台。一个实验是由一股流量(比如用户请求)和在这股流量上进行的相对对比实验的修改组成。实验平台对于海量数据查询有着低延迟、低响应、超大规模数据(百亿级)的需求。
3.2 Flink+ClickHouse整体架构
3.2.1 FLINK SQL + CK 在实验平台业务场景

我们实现了flink sql redis connector,支持redis的sink 、source维表关联等操作,可以很方便的读写redis,实现维表关联,维表关联内可配置cache ,极大提高应用的TPS。通过FLINK SQL 实现实时数据流的pipeline,最终将大宽表sink到CK 里,并按照某个字段粒度做murmurHash3_64 存储,保证相同用户的数据都存在同一shard 节点组内。
3.2.2 ClickHouse百亿级数据join的解决方案
在实际应用场景中,我们发现一些流量的特定场景。我们需要拿一天的用户流量点击情况,来join A/B TEST的日志,用以匹配实验和人群的关系。这就给我们带来了很大挑战,两张大分布式表join出来的性能也非常不理想。
分桶join字段
在这种情况下,我们用了类似于分桶概念。首先把左表和右表join的字段,建表时用hash来落到不同的机器节点,murmurHash3_64(mid)。
如果写入分布式表,在建表时指定murmurHash3_64字段,如果是写本地表,在flink写入段路由策略里加入murmurHash3_64策略即可。
在查询时,使用分布式表join本地表,来达到想要的效果。
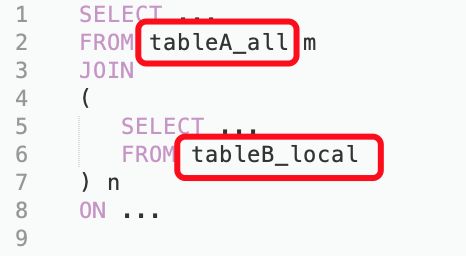
这样分桶后JOIN的结果,是等于分布式表JOIN分布式表,且处理的数据量,只有总数据量/(集群机器数/副本数)。
在写SQL的时候,我们还遇到一个坑,即在左表JOIN右表的过程中,如果左表是子查询,则分布式规则不生效,查询出的结果也远远小于预期值,等于本地表JOIN本地表。右表是子查询则没有关系,因为右表本来就是本地表,对分布式没有要求。
如图所示:


3.3. 增量数据更新场景
数据去重方案比较
订单类数据需要像写入kudu一样,做去重,由于流量数据都实时写入数据,为了订单数据和流量数据做join,就需要对订单数据做去重,由于订单数据是有生命周期的,从产生之后,会不停的update ,下面讨论基于CK各种MergeTree engine的去重方案优缺点。对于实验平台的场景,需要选用一种方案,既能够实时去重,又要保证查询历史数据的结果要固定下来,又不能影响归因准确率,不能忽大忽小,避免对用户产生困惑。
| 方案 | 优点 | 缺点 | 归因准确率 | 查询结果稳定性(是否存在忽大忽小的情况) | 查询性能 |
|---|---|---|---|---|---|
| ClickHouse ReplacingMergeTree | 写入快 | 数据一致性得不到保证,无法去重 | 低 | 不稳定 | 正常 |
| ClickHouse ReplicatedReplacingMergeTree | 可以去重,可以update,去重延迟低 | merge时效性低,mid变化的场景无法merge | 正常 | 稳定 | 正常 |
| ClickHouse remote表 | 数据一致性得到保证 | 存在单节点写入可靠性问题,查询复杂需要先到指定节点拉数据再计算,不能local join,查询仅限于右表 | 正常 | 稳定 | 正常 |
flink row_number 去重 + ReplicatedMergeTree |
规避去重问题,也规避mid hash变化的情况,数据一致性得到保证 | 数据不会update | 正常 | 稳定 | 正常 |
去重方案总结:a.ReplacingMergeTree 数据无法merge,忽大忽小,不能用。b.ReplicatedReplacingMergeTree 可以做去重,对hash字段不变化的情况下适合。c. remote表 查询复杂,对性能有影响,存在副本的可靠性问题。d.flink方案规避去重 和hash字段变化的问题。
3.4 . Flink写入端遇到的问题及优化
问题 1:Too many parts (328). Merges are processing significantly slower than inserts.
原因:刚开始使用clickhouse的时候都有遇到过该异常,出现异常的原因是因为MergeTree的merge的速度跟不上目录生成的速度, 数据目录越来越多就会抛出这个异常, 所以一般情况下遇到这个异常,降低一下插入频次就可以。
解决:
1. 服务端参数调整,将parts_to_throw_insert参数调大值10000,默认值300 对我们大流量的应用场景来说较小。
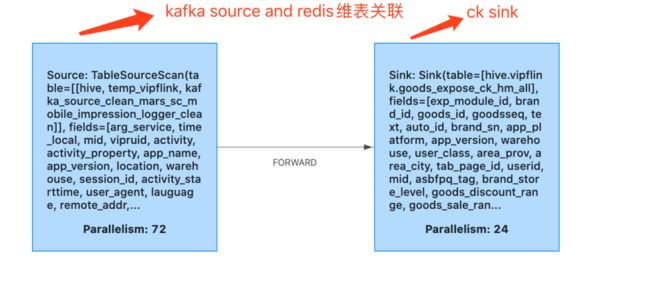
2. 客户端参数调整,调小ck sink 并行度 小并发 大批次写入。小并发,我们通过修改执行计划调整flink 算子并行度,如下图kafka source的并行度=72 ck sink并行度=24 大批次,例如调整connector参数 'sink.buffer-flush.max-rows' = '200000','sink.buffer-flush.interval' = '60s' 20W条记录或60s产生一个batch批量写入CK
3.分区时间字段event_time选择单调递增的时间,流量数据选择nginx日志时间 time_local,曝光数据不适合选择忽大忽小的activity_starttime ,订单数据选择add_time创建时间。
问题2:Unexpected NULL value of not Nullable type Int64
原因:ck建表时如果去掉nullable限制,插入时,就必须给一个确定的值,否则会flush时执行失败,影响flink sql job稳定性。
解决:
1. ck建表时每个字段加上默认值,或建表时加上Nullable 约束(不建议,但是主要这种约束不要太多,主要会占用过多的存储空间,也会降低了查询效率)。
2.flink sql在处理数据时,加上coalesce 空值处理函数。
四、ClickHouse查询优化
4.1.schema 定义优化
CREATE TABLE goods_click_app_h5_ck_hm on cluster ck_cluster (`goods_id` Int64 default -9999,`app_version` String default '-9999',....`dt` Date,`exp_page_id` Int32 default -9999)ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/goods_click_app_h5_ck_hm', '{replica}')PARTITION BY (dt, exp_page_id)ORDER BY (activity_type)TTL dt + INTERVAL 32 DAYSETTINGS index_granularity = 8192
① 选择有副本的merge引擎
② 按dt作为分区,分区内的part 文件进行异步合并
③ 按照字段order by 排序,提升查询性能
④ 设置TTL过期时间
⑤ index_granularity 设置索引粒度为8192行一个查找单元
4.2.常用参数调整
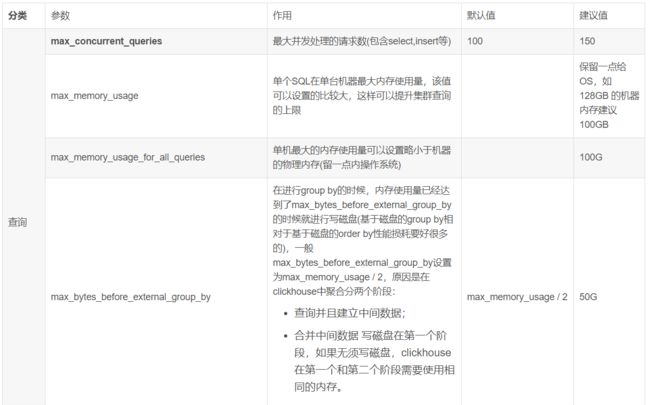
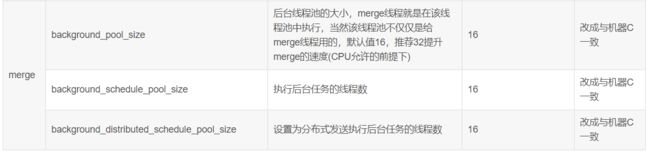
此外,我们在存储策略里设置了冷热数据多盘分离,极大提高热数据的读写速度。
五、物化视图
5.1.物化视图对常用维度组合进行加速
使用ReplicatedSummingMergeTree引擎,相同的数据长度集合,物化视图和明细表查询效率对比(相差将近10-100倍)。
物化视图的创建
CREATE MATERIALIZED VIEW vip_sirius.multi_data_1000445_491_local ON cluster ck_cluster( date Date , `timestamp` UInt32 , `network_fail_total` Nullable(Int64) , `isp` String default '-null' , `pv_total` Nullable(Int64), `service_success_total` Nullable(Int64), `response_t_total` Nullable(Float64), `response_t_count_total` Nullable(Int64), `business_success_total` Nullable(Int64), `time_cnt_100` Nullable(Int64), `time_cnt_200` Nullable(Int64), `time_cnt_500` Nullable(Int64), `time_cnt_5000` Nullable(Int64), `time_cnt_more_5000` Nullable(Int64))ENGINE =ReplicatedSummingMergeTree('/clickhouse/tables/{layer}-{shard}/multi_data_1000445_491_local', '{replica}')PARTITION BY dateORDER BY (timestamp,isp)TTL date + toIntervalDay(14)SETTINGS index_granularity = 8192,storage_policy = 'hotdata'AS select CAST(timestamp AS Date) AS date,timestamp , sum(network_fail_total) AS network_fail_total, `isp` , sum(pv_total) AS pv_total, sum(service_success_total) AS service_success_total, sum(response_t_total) AS response_t_total, sum(response_t_count_total) AS response_t_count_total, sum(business_success_total) AS business_success_total, sum(time_cnt_100) AS time_cnt_100, sum(time_cnt_200) AS time_cnt_200, sum(time_cnt_500) AS time_cnt_500, sum(time_cnt_5000) AS time_cnt_5000, sum(time_cnt_more_5000) AS time_cnt_more_5000FROM vip_sirius.multi_data_1000445_localGROUP BY timestamp ,isp Distributed table:CREATE TABLE vip_sirius.multi_data_1000445_491ON cluster ck_cluster AS vip_sirius.multi_data_1000445_491_localENGINE = Distributed('ck_cluster','vip_sirius','multi_data_1000445_491_local',rand())
查询明细表
语句:
select sum(pv_total),toDateTime(timestamp) from multi_data_1000445 where date>='2021-02-10' and date<='2021-03-03' group by timestamp order by timestamp desc;
查询物化视图
语句:
select sum(pv_total),toDateTime(timestamp) from multi_data_1000445_491 where date>='2021-02-10' and date<='2021-03-03' group by timestamp order by timestamp desc ;
5.2 物化视图的问题
我们在使用物化视图的过程中,也遇到一些问题。比如:
1、物化视图维度比较多的时候,生成的结果表也会指数级增加。我们这些表最多的一个库,有着1500多张计算各种维度的物化视图,且无法进行表级合并。这样在管理、监控表的时候,带来一些麻烦。
2、物化视图维度增多的时候,写入数据将会带来不小的消耗,在CPU,内存等层面都会有更多的消耗,这样在分配集群和角色资源的时候,会扰乱原有的分配计划。
总而言之,物化视图是一把双刃剑。在带来速度加速效果明显的同时,也会带来资源、管理上的一些弊端,用户使用的时候要把握好这些优缺点。
六、展望
6.1 ClickHouse和Spark/Presto融合
HyperLogLog是大数据分析常用的去重计算分析方法,在我们之前的应用中已经打通了Spark,Presto的HyperLogLog对象,即在一种引擎里生产的HyperLogLog对象,在其他引擎均可以解析、计算与分析。
未来我们会打通Clickhouse的HyperLogLog的数据对象,将C++和JAVA做统一序列化和反序列化。
最终达到在hadoop中通过Spark和Presto等引擎ETL出的HyperLogLog,导入Clickhouse也可以直接用Clickhouse的语法查出。DWS/ADS层可以共享数据,使得ClickHouse在ADS层数据可以加速。
6.2 业务使用
后续我们有push效果分析,广告投入效果等应用场景,陆陆续续接入的Clickhouse。
我们也在探索使用RoaringBitmap来进行字段长度不一的 user_id,push_id等各种ID的精确去重、留存分析等。
RoaringBitmap:http://roaringbitmap.org/
6.3 ClickHouse底层架构迭代演进
随着业务的推进和发展,我们之后会通过以下几个方向,继续优化Clickhouse在唯品会的推进和使用。
6.3.1 存算分离
我们都知道Clickhouse是自带本地化存储的OLAP引擎,本地化存储在海量数据请求的情况下,会有I/O速度受限,扩容复杂(需修改clickhouse的存储策略),不能按需自动扩缩容,Clickhouse不好上AI云平台等诸多限制。
所以我们有计划将这部分存储打到云上,实现存算分离,可以做到用网络的传输的高速率打破本地I/O的读写瓶颈,按照需求自动扩缩容云端存储,将Clickhouse上到我们自己的AI云平台便于管理。
我们将会从修改存储策略接口代码,多种云存储或者分布式存储来对数据进行分类,不同热度、容量的数据对应不同的存储策略。
6.3.2 写入优化
目前我们写入主要是写入分布式表,将来会考虑测试优化写入分布式表的性能和hash功能,来支持更高的写入tps。
6.3.3 接入管控
目前我们属于Clickhouse业务推广阶段,对Clickhouse使用方管控较少,也没做过多的存储、计算、查询角色等方面的管控。数据安全乃大数据重中之重,我们将在接下来的工作中逐步完善这一块。
6.3.4 SQL管控
在Clickhouse的新版中,已经加入了RBAC的访问控制管理,官方也推荐使用这种方式。
参考:https://clickhouse.tech/docs/en/operations/access-rights(点击阅读原文)

我们将会:
1、用default创建一个root账户,作为管理者账户。
2、所有授权的操作通过root账户GRANT完成。
3、禁用default用户的管理功能。
6.3.5 资源管控
在资源层面,我们会结合存算分离,给不同的业务分配不同的用户,不同的用户在云平台上申请的存储资源有限。且会对每个用户的存储进行价值计算。