TSI文件结构概览
- 一个TSI文件的定义和操作在
tsdb/index/tsi1/index_file.go里实现的 - 一个TSI文件的结尾存储了这个文件相关的meta信息,主要是其他section在文件中的offset和size,这个meta信息被称为tsi文件的
IndexFileTrailer,我们看一下它的Size的定义:
IndexFileTrailerSize = IndexFileVersionSize +
8 + 8 + // measurement block offset + size
8 + 8 + // series id set offset + size
8 + 8 + // tombstone series id set offset + size
8 + 8 + // series sketch offset + size
8 + 8 + // tombstone series sketch offset + size
0
从上面的定义我们可以得到两点收获:
- 这个IndexFileTrailerSize在TSI文件结尾处有固定大小(82bytes),我们在解析TSI文件时,很容易读到并解析这个Trailer;
- 我们可以知道这个TSI文件都包含哪些Section, 下图是TSI文件结构
2.1 Trailer部分
2.2 series id set block
2.3 tombstone series id set block
2.4 series sketch block
2.5 tombstone series sketch block
- 下面我们就分别来看一下各组成部分
Measurement block
- 定义在
tsdb/index/tsi1/measurement_block.go - 它的结构也是由存储meta信息的
Trailer部分和其他各section组成 - 定义:....
type MeasurementBlock struct {
data []byte
hashData []byte
// Measurement sketch and tombstone sketch for cardinality estimation.
sketchData, tSketchData []byte
version int // block version
}
基础上是按照其在文件中的结构定义的,记录了measurement包括的tagset和series id信息;
- 我们来看一张完整的结构图
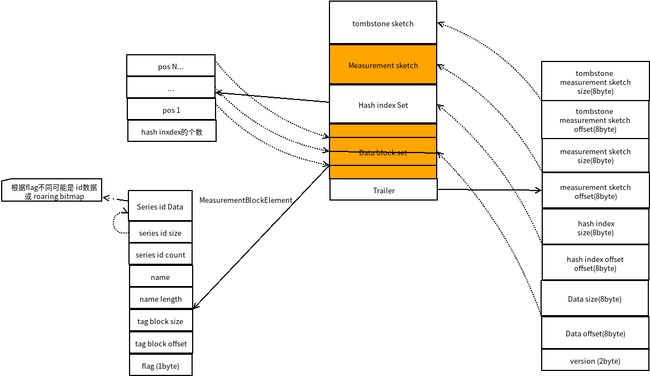
influxdb_measurement_block_in_tsi.png
- 一图抵千言
-
Trailer部分是整个MeasuermentBlock的索引,存储着其他部分的offset和size -
Data block set部分是所有MeasurementBlockElement的集合,
2.1 measurement 基本属性,比如name等;
2.2 对应的tag set在文件中的offset和size;
2.3 包括的所有series id信息, 这个series id有两种表示方式:roaring bitmap和 数组,flag指示了用哪种表示方法 -
hash index部分:以hash索引的方式存储了MeasurementBlockElement在文件中的offset, 可以在不用读取整体的tsi文件的前提下,快速定位对某个measurementblockElement的文件位置,然后读取并解析 -
tombstome sketch和mesurement sketch是使用HyperLogLog++算法来作基数统计用。
-
- 代码里还提供了很多的序列化和反序列化,遍历等方法,这里不再累述。
Tag Block
定义在
tsdb/index/tsil/tag_block.go中它由
trailer,hash index,tag key block,tag value block四个部分组成-
我们来看一张完整的结构图
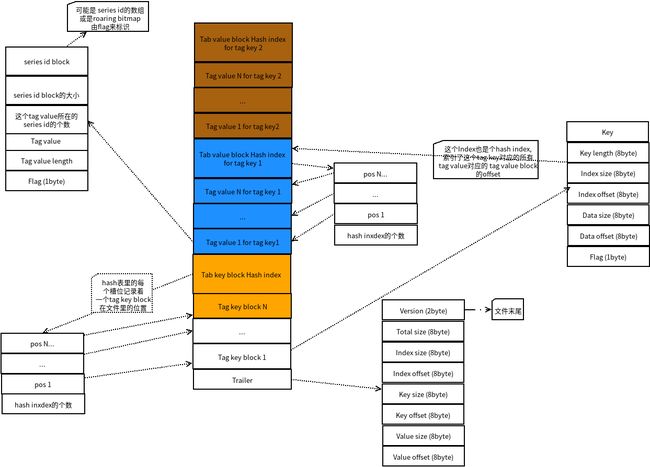 influxdb_tag_block_detail_in_tsi.png
influxdb_tag_block_detail_in_tsi.png -
一图抵千言
-
Trailer部分相当于这个tag block的meta 信息,主要保存其它各组成部分的offset和大小。 -
Hash index部分,可以通过 tag key快速定位到tag key block的offsset; - 在
tag key block部分的hash indxe部分,可以通过tag value快速定位到tag value block部分,Data offset, Data size部分指向了当前tag key对应的所有的tag value block文件区域; - 简言之,这就是个多级索引表,一级找一级;
-
代码里还提供了很多的序列化和反序列化,遍历等方法,这里不再累述;
我们来看一下tabblock的encode过程,我们用伪码来写一下:
//遍历每个tag key
for tagkey in tagkeys {
每个tag key对应多个tag value,遍历
每个tag key都生成一个tag key entry对象,记录下tag key entry的offset,然后将这个tag key entry放入数组TagKeyEntrys备用
for tagValue in tagValuesBytagKey {
buildTagValueBlock
写这个tagValueBlock的offset和tag value入hash表
}
写入这个tag value到tagValueBlockOffset的hash表
}
for tagkeyEntry in TagKeyEntrys {
构建tagKeyBlock
写这个tagKeyBlock的offset和tag key入hash表
}
写入这个tag key到tagKeyBlock Offset的hash表
简单讲就是:
- 构建一系列tag value block, 同时准备好TagKeyEntry组数;
- 根据 1 中的TabKeyEntry构建一系列tab key block, 同时准备好[tag key] -> [tag key block offset]的map;
- 根据 2 中的 map 建hash index。
IndexFile
- 定义在
tsdb/index/tsil/index_file.go中
type IndexFile struct {
wg sync.WaitGroup // ref count
data []byte
// Components
sfile *tsdb.SeriesFile // 对应的Seriesile文件
tblks map[string]*TagBlock //包含的所有TagBlock
mblk MeasurementBlock //MeasurementBlock
// Raw series set data.
seriesIDSetData []byte
tombstoneSeriesIDSetData []byte
// Series sketch data.
sketchData, tSketchData []byte
// Sortable identifier & filepath to the log file.
level int
id int
mu sync.RWMutex
// Compaction tracking.
compacting bool
// Path to data file.
path string
}
- 我们看一下结构图:
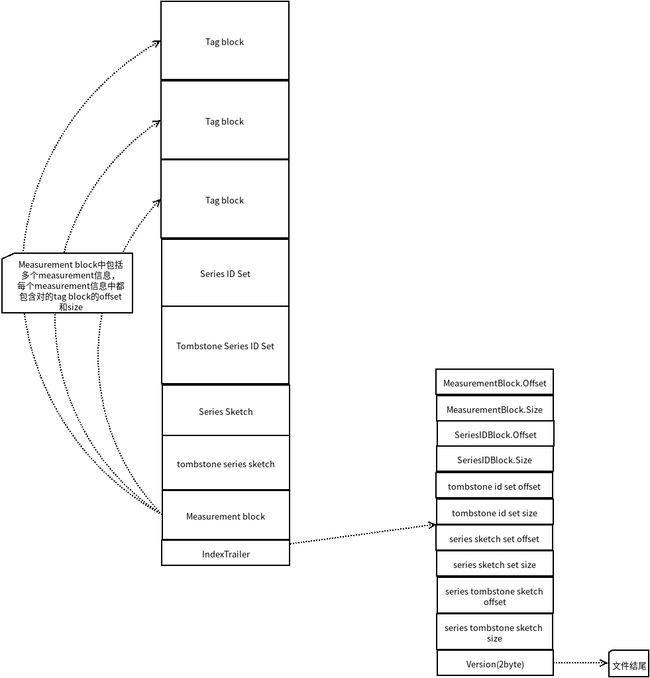
influxd_series_index.png
-
Trailer部分是其meta信息,里面是其他block的offset和size; - 按
Trailer部分的信息可以定位到Measurement block部分; - 在
Measurement block部分有hash index,根据measurement name可以快速定位到其tab block部分 - 在
tag block中可以根据tag key定位到tab key block部分; - 在
tag key block部分又按hash indexd快速定位到 tag value;
IndexFiles
- 代表了一个layer上所有的index file,定义如下:
type IndexFiles []*IndexFile
- 提供了一系列的iterator操作,按measurement name来汇集了所有index文件中的measurement, tagkey, tagvalue, series id set等,且作了排序
func (p IndexFiles) MeasurementIterator() MeasurementIterator
func (p *IndexFiles) TagKeyIterator(name []byte) (TagKeyIterator, error)
func (p IndexFiles) MeasurementSeriesIDIterator(name []byte) tsdb.SeriesIDIterator
func (p IndexFiles) TagValueSeriesIDSet(name, key, value []byte) (*tsdb.SeriesIDSet, error)
- 最主要的是提供了CompactTo方法,将其包含的所有index文件合并成一个
利用上面的一系列iterator方法,依次写入tag block, measurement block等,这里不累述。
FileSet
- 是File类型的集合,这个 File类型可能是LogFile,也可能是 IndexFile,功能是上面的
IndexFiles类似,定义如下:
type FileSet struct {
levels []CompactionLevel
sfile *tsdb.SeriesFile
files []File // 按最后更改时间从小到大排列
manifestSize int64 // Size of the manifest file in bytes.
}
- 提供了一系列的iterator操作,按measurement name来汇集了所有index文件中的measurement, tagkey, tagvalue, series id set等,且作了排序
- 文件替换操作, 参数中
oldFiles是fs.files的一部分,即当前正在被compat的文件列表,这个方法的目的是将这oldFiles列表从fs.files中删除,然后在oldFiles原来开始的位置插入这个newFile, 这个newFile就是compact之后新生成的文件。
func (fs *FileSet) MustReplace(oldFiles []File, newFile File) *FileSet {
assert(len(oldFiles) > 0, "cannot replace empty files")
// Find index of first old file.
var i int
for ; i < len(fs.files); i++ {
if fs.files[i] == oldFiles[0] {
break
} else if i == len(fs.files)-1 {
panic("first replacement file not found")
}
}
// Ensure all old files are contiguous.
for j := range oldFiles {
if fs.files[i+j] != oldFiles[j] {
panic(fmt.Sprintf("cannot replace non-contiguous files: subset=%+v, fileset=%+v", Files(oldFiles).IDs(), Files(fs.files).IDs()))
}
}
// Copy to new fileset.
other := make([]File, len(fs.files)-len(oldFiles)+1)
copy(other[:i], fs.files[:i])
other[i] = newFile
copy(other[i+1:], fs.files[i+len(oldFiles):])
// Build new fileset and rebuild changed filters.
return &FileSet{
levels: fs.levels,
files: other,
}
}
Partition
- 它包含层级结构的index files和一个LogFile,其中这个层级结构的index files就是L1-l7的tsi,这个LogFile就是tsl(它算作是L0),在磁盘上的目录结构上,它位于每个shard目录下。一个partiton下包含有一个tsl文件,若干tsi文件和一个MANIFEST文件。
- tsl:就是WAL,前面已经介绍过,新写入的index信息除了在内存里缓存外,还会以LogEntry的形式写入这个tsl,作故障恢复时用。
- L0层LogFile会定期compact到L1, L1-L6会定期向高层作compact, compact的过程其实就是将相同measurement的tagbock作在一起,相同measurement的相同tagkey对应的所有tagvalue放在一起, 相同measurement的相同tagkey又相同tagvalue的不同series id作合并后放在一起。
- 我们重点看一下compact方法:
func (p *Partition) compact() {
if p.isClosing() {
return
} else if !p.compactionsEnabled() {
return
}
interrupt := p.compactionInterrupt
fs := p.retainFileSet()
defer fs.Release()
//influxdb的每个partition中tsi的层次是固定的L0-L7,其中L0是wal,这个方法不涉及它的compact
//L7为最高层,它也不会再被compact了
//所以这个compact方法需要处理的是L1-L6层
minLevel, maxLevel := 1, len(p.levels)-2
for level := minLevel; level <= maxLevel; level++ {
//如果正在被compact则跳过
if p.levelCompacting[level] {
continue
}
// 获取当前level中的相邻的index文件列表,按文件更改时间由新到旧排,每次最多compact两个文件,少于两个的不作compact
files := fs.LastContiguousIndexFilesByLevel(level)
if len(files) < 2 {
continue
} else if len(files) > MaxIndexMergeCount {
files = files[len(files)-MaxIndexMergeCount:]
}
// Retain files during compaction.
IndexFiles(files).Retain()
// Mark the level as compacting.
p.levelCompacting[level] = true
// 开goroutine作compact
func(files []*IndexFile, level int) {
// Start compacting in a separate goroutine.
p.wg.Add(1)
go func() {
// compact到高一级.
p.compactToLevel(files, level+1, interrupt)
// Ensure compaction lock for the level is released.
p.mu.Lock()
p.levelCompacting[level] = false
p.mu.Unlock()
p.wg.Done()
// Check for new compactions
p.Compact()
}()
}(files, level)
}
TagValueSeriesIDCache
- series id set 在内存中的缓存,实际上就是一个LRU缓存,一般用双向链表+map实现;
- 使用map来记录缓存内容:
cache map[string]map[string]map[string]*list.Element,这是个嵌套map结构
seasurement name -> tag key -> tag value -> list.Element,最后的这个list.Element里包括seriesIDSet
type seriesIDCacheElement struct {
name []byte
key []byte
value []byte
SeriesIDSet *tsdb.SeriesIDSet
}
利用这个map来加速cache的查找过程;
- 使用
golang list.List来记录所有的list.Eement对象,实现缓存的LRU淘汰机制。新加入的和刚刚Get过的element被移动到链表的头部,如果缓存大小到达上限,则直接删除链表尾部的元素,同时也要清理map中相应的元素。
完整结构图
-
最后我们来放一张完整的tsi结构图,每个Shard都对应有这样的一个tsi结构
 influxdb_index_arch.png
influxdb_index_arch.png