参考:http://www.cnblogs.com/heavenwang/p/3988033.html
1. 基本概念
Hadoop 是Apache基金会下一个开源的分布式计算平台,它以分布式文件系统HDFS和MapReduce算法为核心,为用户提供了系统底层细节透明的分布式基础架构。
如下图Hadoop集群中有很多并行的机器来存储和分析数据,客户端把任务提交到集群,集群计算返回结果。

Hadoop强调把代码向数据迁移,即Hadoop集群中既包含数据又包含运算环境,并且尽可能让一段数据的计算发生在同一台机器上,代码比数据更加容易移动,Hadoop的设计理念即是把要执行的计算代码移动到数据所在的机器上去。
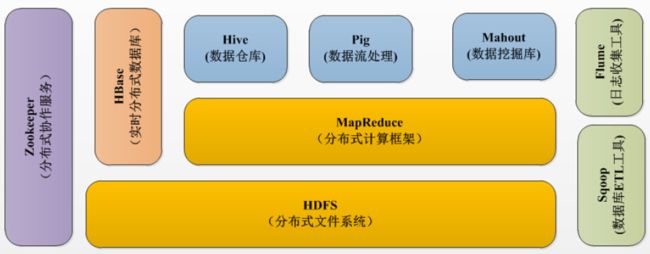
- HDFS是一种分布式文件系统,数据被保存在计算机集群上,HDFS为HBase等工具提供了基础。
- MapReduce,它是一个分布式、并行处理的编程模型,MapReduce把任务分为map(映射)阶段和reduce(化简)。实现并行。
- Hive类似于SQL高级语言,用于运行存储在Hadoop上的查询语句。
2. Hadoop与SQL数据库
从总体上看,现在大多数数据应用处理的主力是关系型数据库,即SQL面向的是结构化的数据,而Hadoop则针对的是非结构化的数据,从这一角度看,Hadoop提供了对数据处理的一种更为通用的方式。
用scale-out代替scale-up
拓展商用服务器的代价是非常昂贵的。要运行一个更大的数据库,就要一个更大的服务器,事实上,各服务器厂商往往会把其昂贵的高端机标称为“数据库级服务器”,不过有时候有可能需要处理更大的数据集,但却找不到更大的机器,而更为重要的是,高端机对于许多应用并不经济。用键值对代替关系表
关系型数据库需要将数据按照某种模式存放到具有关系型数据结构表中,但是许多当前的数据模型并不能很好的适应这些模型,如文本、图片、xml等,此外,大型数据集往往是非结构化或半结构化的。而Hadoop以键值对作为最基本的数据单元,能够灵活的处理较少结构化的数据类用函数式编程(MapReduce)代替声明式查询(SQL)
SQL从根本上说是一个高级声明式语言,它的手段是声明你想要的结果,并让数据库引擎判断如何获取数据。而在MapReduce程序中,实际的数据处理步骤是由你指定的。SQL使用查询语句,而MapReduce使用程序和脚本。MapReduce还可以建立复杂的数据统计模型,或者改变图像数据的处理格式。用离线批量处理代替在线处理
Hadoop并不适合处理那种对几条记录读写的在线事务处理模式,而适合一次写入多次读取的数据需求。
3. HDFS Hadoop Distributed File System
特点:高访问量,高容错性,线性拓展
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件的访问操作;集群中的DataNode管理存储的数据。NameNode执行文件系统的命名操作,比如打开、关闭、重命名文件或目录等,它也负责数据块到具体DataNode的映射。DataNode负责处理文件系统客户端的文件读写请求,并在NameNode的同意调度下进行数据块的创建、删除和复制工作

结构:
- NameNode:master节点,管理HDFS的名称空间和数据块映射信息、配置副本策略和处理客户端请求
- Secondary NameNode: 辅助master节点,备份namespace
- DataNod: slave节点,实际存储数据、执行数据块的读写并汇报存储信息给NameNode
操作:
- hadoop fs: 实际存储数据、执行数据块的读写并汇报存储信息给NameNode;
hadoop fs -ls /
hadoop fs -lsr
hadoop fs -mkdir /user/hadoop
hadoop fs -put a.txt /user/hadoop/
hadoop fs -get /user/hadoop/a.txt /
hadoop fs -cp src dst
hadoop fs -mv src dst
hadoop fs -cat /user/hadoop/a.txt
hadoop fs -rm /user/hadoop/a.txt
hadoop fs -rmr /user/hadoop/a.txt
hadoop fs -text /user/hadoop/a.txt
hadoop fs -copyFromLocal localsrc dst 与hadoop fs -put功能类似。
hadoop fs -moveFromLocal localsrc dst
hadoop fsadmin
dfsadmin是一个多任务的工具,我们可以使用它来获取HDFS的状态信息,以及在HDFS上执行的一系列管理操作。
-report:查看文件系统的基本信息和统计信息。
-safeadmin enter | leave | get | wait:安全模式命令。安全模式是NameNode的一种状态,在这种状态下,NameNode不接受对名字空间的更改(只读);不复制或删除块。NameNode在启动时自动进入安全模式,当配置块的最小百分数满足最小副本数的条件时,会自动离开安全模式。enter是进入,leave是离开。
-refreshNodes:重新读取hosts和exclude文件,使新的节点或需要退出集群的节点能够被NameNode重新识别。这个命令在新增节点或注销节点时用到。hadoop fsck
HDFS支持fsck命令用以检查各种不一致。fsck用以报告各种文件问题,如block丢失或缺少block等。
4. MapReduce
是一个分布式计算框架,用来并行计算海量数据。
MapReduce 框架的核心步骤主要分两部分:Map 和Reduce。
Hadoop的MapReduce模型是通过输入key/value对进行运算得到输出key/value对。其分为Map过程和Reduce过程。
- Map主要的工作是接收一个key/value对,产生一个中间key/value对,之后MapReduce把集合中所有相同key值的value放在一起并传递给Reduce函数。
- Reduce函数接收key和相关的value集合并合并这些value值,得到一个较小的value集合。
下图是MapReduce的数据流图,体现了MapReduce处理大数据集的过程。这个过程就是将大数据分解为成百上千个小数据集,每个(或若干个)数据集分别由集群中的一个节点进行处理并生成的中间结果,然后这些中间结果又由大量的节点合并,形成最终结果。

例子1:Hadoop Word Count
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount ");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setInputFormatClass(TextInputFormat.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
例子2:下载气象数据,求每年的最低温度
Min Temperature
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MinTemperature {
public static void main(String[] args) throws Exception {
if(args.length != 2) {
System.err.println("Usage: MinTemperature MinTemperatureMapper
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MinTemperatureMapper extends Mapper{
private static final int MISSING = 9999;
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String year = line.substring(15, 19);
int airTemperature;
if(line.charAt(87) == '+') {
airTemperature = Integer.parseInt(line.substring(88, 92));
} else {
airTemperature = Integer.parseInt(line.substring(87, 92));
}
String quality = line.substring(92, 93);
if(airTemperature != MISSING && quality.matches("[01459]")) {
context.write(new Text(year), new IntWritable(airTemperature));
}
}
}
MinTemperatureReducer
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MinTemperatureReducer extends Reducer {
@Override
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int minValue = Integer.MAX_VALUE;
for(IntWritable value : values) {
minValue = Math.min(minValue, value.get());
}
context.write(key, new IntWritable(minValue));
}
}