一、Transformer
(一)更改连接方式
How Does Selective Mechanism Improve Self-Attention Networks?
哈工大刘挺组
选择机制如何改善自我注意网络?
- 背景:
这是一篇解释性的文章。 - 动机:
近年来,在自注意力网络引入选择机制使得模型关注其中重要的输入元素已经取得很好的效果。但是,对于选择机制取得这样结果的原因尚不清楚。本文提出一个通用的基于选择机制的自注意力网络。传统的自注意力网络在顺序编码以及结构信息建模能力存在一些不足,而本文针对其提出相应的假设,并在实验中验证假设的正确性。 - 模型:
选择性的自注意力网络:增加一个选择器,筛选出真正对当前词很重要的词,然后做Self-Attention。(这个思想和Reformer的出发点有点像-去关注真正值得关注的东西)

- 结果:
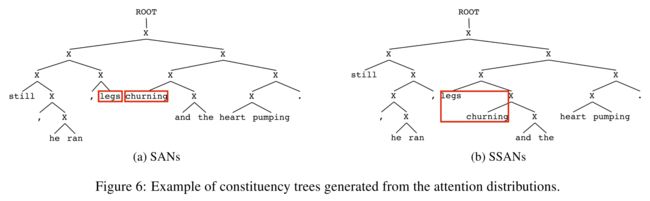
作者设计了几个实验,来探究SAN和SSAN的区别。
实验分析发现,将选择机制引入自注意力网络的好处在于:
(1) 其更多关注周围词的信息,从而对周围词序的变化比较敏感,使得其更好对顺序进行编码;
(2)其对于树结构重要成分关注度更高,从而其拥有更强的捕捉结构信息的能力。

Highway Transformer: Self-Gating Enhanced Self-Attentive Networks
中科院
- 动机:
Self-Attention更关注任意两个词之间的注意力分布,而忽略了单个词特征信息的基本重要性。想法类似于把LSTM中的控制门引入到Transformer结构中,以补充个体表示的多维潜在空间中的内部语义重要性。加入的SDU门允许通过跳过连接的调控潜在嵌入的信息流,让模型包含更多词本身的信息。并且作者分析了这样做可以让梯度下降算法具有更明显的收敛速度。 - 模型:
SDU(Self-Dependency Units):该组件中的门通常设为tanh函数,类似于LSTM中的调控门保留多少信息留下多少信息传递下去。
SDU-augmented Transformer:SDU可以被视作为一种具有动态适应能力的自依赖非线性激活函数。

- 结果:
和Transformer、R-Transformer、Transformer-XL做了比较,在一些任务上均有一定提升。
Improving Transformer Models by Reordering their Sublayers
Allen AI与Facebook团队
通过子层重新排序改进Transformer
- 动机:
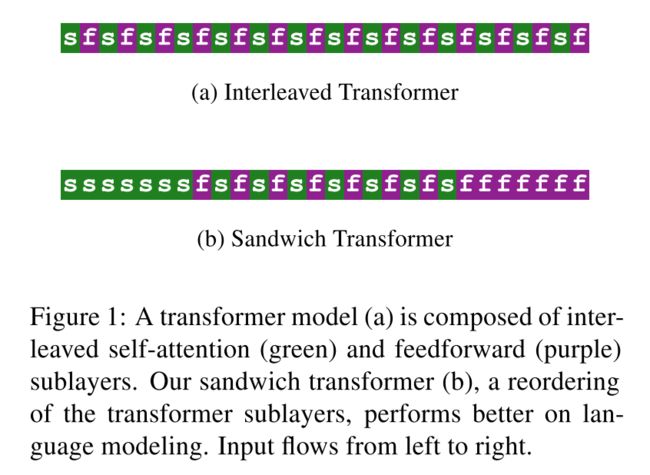
考虑的角度有些独特,Transformer中包含两个子层:Self-Attention层(s)和前馈网络层(f),本文考虑将这两个子层调换顺序后性能是否有提升。作者随机生成不同子层排列顺序的Transformer,然后发现底部有更多自注意力层和顶部有更多前馈网络层的模型具有更好的效果,于是设计了三明治结构的Transformer。
- 模型:
实验中作者探讨了两点:一个是s和f层的数量比例的问题,实验中发现二者数量均衡的效果要更好一些;另一个是s和f层排列先后的问题,实验中发现s越在底层f越在顶层效果越好。
虽然作者没法解释这一原因,但是针对这些现象设计了表现更好的三明治Transformer。底层和顶层部分是纯s和f,中间s和f交错排列成为三明治夹心,这种结构的效果最好。 - 结果:
作者根据不同任务进行了实验,每个任务表现最好的结构不固定,但是这种调整子层的思想可以在设计模型的时候不额外增加参数而获得一定提升。
(二)更改位置编码
FLAT: Chinese NER Using Flat-Lattice Transformer
复旦邱锡鹏组
平面格结构的Transformer
- 背景:汉字格(Lattice)结构被证明是一种有效的中文命名实体识别方法,格子结构被证明对利用词信息和避免分词的错误传播有很大的好处。我们可以将一个句子与一个词典进行匹配,得到其中的潜词,获得一个类似Lattice的结构:不仅考虑句子中的单个字,还考虑每个字可能组成的词组。Lattice是一个有向无环图,词汇的开始和结束字符决定了其位置。

Lattice LSTM是中文NER的开山之作,融合了词汇信息到原生的LSTM中:

动机:
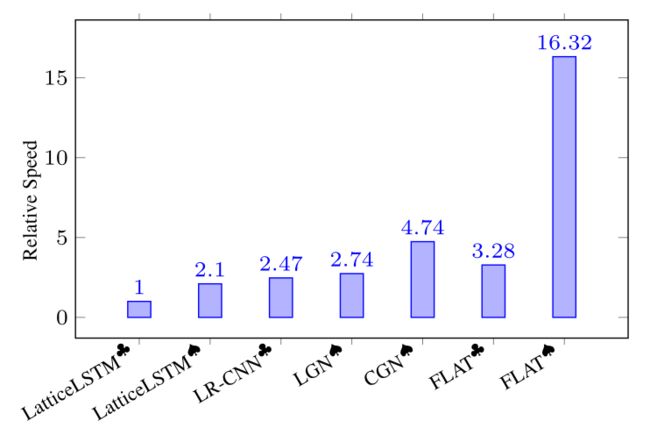
(1)Lattice-LSTM和LR-CNN采取的RNN和CNN结构无法捕捉长距离依赖,而动态的Lattice结构也不能充分进行GPU并行。
(2)而CGN和LGN采取的图网络虽然可以捕捉对于NER任务至关重要的顺序结构,但这两者之间的gap是不可忽略的。其次,这类图网络通常需要RNN作为底层编码器来捕捉顺序性,通常需要复杂的模型结构。模型:
FLAT设计了一种巧妙position encoding来融合Lattice 结构。对于每一个字符和词汇都构建两个head position encoding 和 tail position encoding,可以证明,这种方式可以重构原有的Lattice结构。也正是由于此,FLAT可以直接建模字符与所有匹配的词汇信息间的交互,例如,字符 [药] 可以匹配词汇 [人和药店] 和 [药店]。因此,我们可以将Lattice结构展平,将其从一个有向无环图展平为一个平面的Flat-Lattice Transformer结构,由多个span构成:每个字符的head和tail是相同的,每个词汇的head和tail是skipped的。

同时作者提到,绝对位置编码并不适用于NER任务,采用了XLNet中的相对位置编码计算attention score,论文提出四种相对距离表示xi和xj之间的关系,同时也考虑字符和词汇之间的关系:

- 结果:
该模型能够并行化在GPU上训练,训练效率大大高于原有模型。
Self-Attention with Cross-Lingual Position Representation
悉尼大学+腾讯
融入跨语言位置表示的Self-Attention

- 动机:由于原始的Self-Attention确实刻画序列先后次序的信息,因此位置编码(PE)对Self-Attention很重要。然而目前无论是绝对位置编码(APE,Transformer中提出的)还是相对位置编码(RPE),对源语言和目标语言都是独立建模的并且是固定的。由于不同语言中的词序差异,建立跨语言位置关系可能有助于SANs更好的学习到跨语言的信息。
- 模型:
(1)不同语言的词序如何对应起来?作者使用了基于BTG的重排序模型,根据对应目标句的词序生成一个重排序的源句,然后得到重排序后的单词索引PE_XL。
(2)融入重排后的单词索引PE_XL。作者提出了两种融入方法。一种在输出层融入-与绝对位置编码结合作为新的位置编码;一种在自注意力层中的Head中融入-不同的Head输入包含不同的位置编码。
(三)根据不同任务增加组件
Hooks in the Headline: Learning to Generate Headlines with Controlled Styles
MIT、Amazon等
生成指定风格的标题
- 动机:
目前的摘要系统只产生简单、真实的标题,但不能满足创建令人难忘的标题以增加曝光率的实际需要。我们提出了一个新的任务,文本标题生成(SHG),以丰富三种风格(幽默,浪漫和点击诱饵)的标题,以吸引更多的读者。

- 模型:
数据集S(包含新闻文本A和对应标题H),T(带有风格的文本T,不一定是标题,因为带有风格的标题数据集很昂贵)
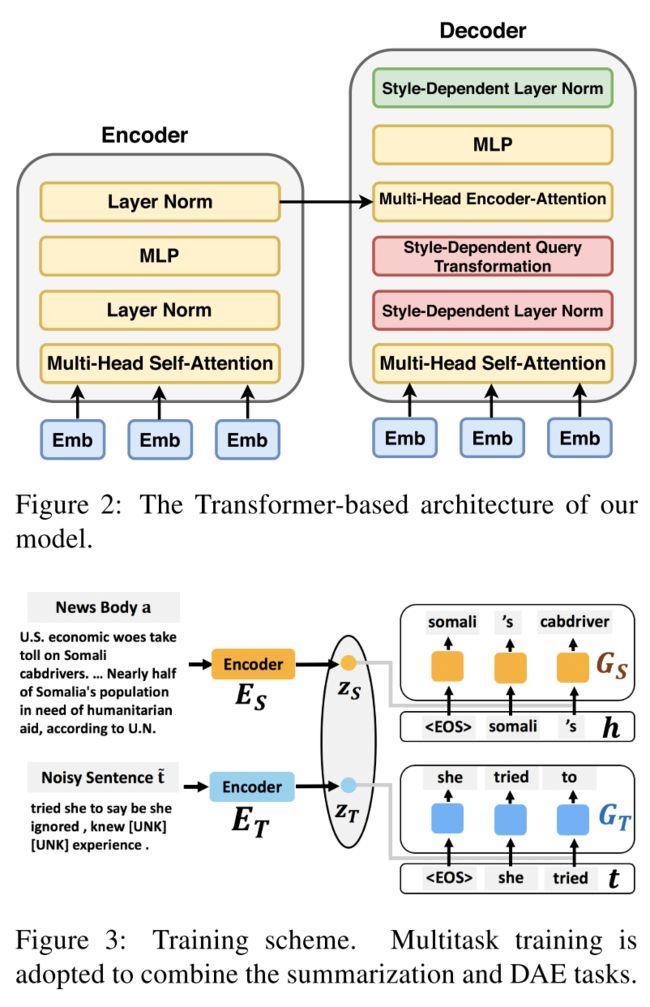
模型整体为一个Transformer结构,分为encoder和decoder。采用了多任务学习的框架,同时进行:文本总结(在S上,根据新闻文本A生成对应标题,有监督学习);带有风格的文本重构(在T上,输入为乱序和mask的句子,目标是还原生成原句t)
由于两部分数据集和任务都是独立的,为了将二者融合,达到在总结文本的时候带有风格的目标,作者设计了参数共享的策略:模型黄色的部分全部参数贡献,红色和绿色的部分不参数贡献。共享部分很好理解,就是在总结文本信息时将风格融入;不共享的地方,旨在得到不同风格的层归一化后的输入和查询
- 结果:
模型生成标题的吸引力得分超过了最新的摘要模型的9.68%,甚至超过了人工编写的reference。

二、BERT
(一)应用
增加隐变量
PLATO: Pre-trained Dialogue Generation Model with Discrete Latent Variable
百度
包含离散隐变量的预训练对话生成模型
视频讲解:https://mp.weixin.qq.com/s/w1oMnYDql09EVBbmIV6cSg
- 背景:
隐变量较为普遍地在VAE、CVAE等技术中使用,但在论文中,作者们首次提出将离散的隐变量结合Transformer结构,应用到通用的对话领域。通过引入离散隐变量,可以对上文与回复之间的“一对多”关系进行有效建模。 - 动机:
本文研究开放领域的对话机器人。目前存在两个比较大的挑战:一是大规模开放域多轮对话数据匮乏; 二是对话中涉及常识、领域知识和上下文,因此在对话回复时,存在“一对多”问题。例如,当人说“外面正在下雪”,回答“去堆雪人怎么样?”或者“太冷了,好想念夏天。”在不同场景下都是合理的。也就是说:一个对话的上文(Context),往往可以对应多个不同回复(Response)的方向。这些不同的回复随着不同的人,不同的背景和环境可能有所不同,但都是合理的回复。经典的深度学习模型目前都能比较好解决一对一的问题,例如Seq2Seq。
为了解决这2个问题,本文通过大规模数据进行预训练,然后首次在Transformer结构中引入离散隐变量,对上文与回复之间的“一对多”关系进行有效建模。

- 模型:
在PLATO中,离散隐变量可以有K个取值,它的每个取值,是与一个回复中的意图相对应的,或者可以理解为多样化的对话的动作(Action)。
在PLATO的训练中,有2个任务同步进行-回复生成(Response Generation)和隐变量识别(Latent Act Recognition)。回复生成任务中(灰色箭头):给定上文和离散隐变量的取值(即确定了回复中的意图,向量中绿色的点),尽可能生成绿色那句的话。识别任务(蓝色箭头)尽量估计给定上文和目标回复对应的隐变量取值。显然,隐变量的准确识别,可以进一步提升回复生成的质量。
模型网络架构由Transformer Blocks组成,整个模型对两个任务是共享参数的。在回复生成任务中,PLATO借鉴UniLM使用了灵活的注意力机制:对上文进行了双向编码,充分利用和理解上文信息;对回复进行了单向解码,适应回复生成的Autoregressive特性。在隐变量识别任务中,PLATO使用特殊符号[M]作为隐变量的输入,对上文和回复进行双向编码,尽可能收集更多的信息,更准确估计回复意图(即离散隐变量的取值)。
针对多轮对话的输入的表示方法,PLATO也进行了独特的设计,每个token的Input Embedding是由对应的token、role、turn和position embedding相加得到。
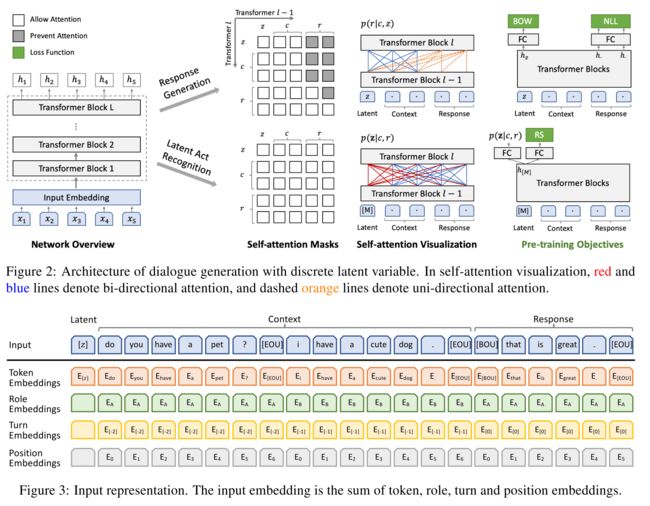
- 结果:
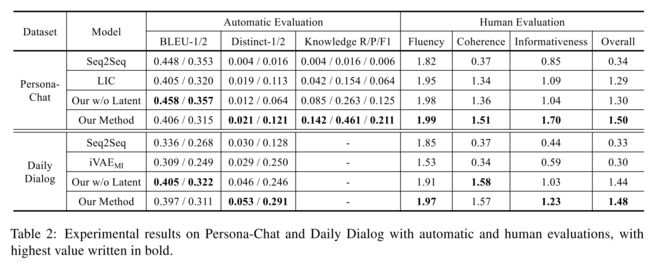
在三个公开对话数据集上的评测,PLATO 都取得了新的最优效果。
A Novel Cascade Binary Tagging Framework for Relational Triple Extraction
吉林大学
一种用于关系三元组抽取的级联二进制标记框架
参考:https://www.zhihu.com/question/385259014/answer/1141621197
- 背景:
关系三元组抽取(Relational Triple Extraction, RTE),也叫实体-关系联合抽取,是信息抽取领域中的一个经典任务,旨在从文本中抽取出结构化的关系三元组(Subject, Relation, Object)用以构建知识图谱。 - 动机:
随着NLP领域的不断发展,在简单语境下(例如,一个句子仅包含一个关系三元组)进行关系三元组抽取已经能够达到不错的效果。但在复杂语境下(一个句子中包含多个关系三元组,有时甚至多达五个以上),尤其当多个三元组有重叠的情况时(如下图所示),现有SOTA模型的表现就显得有些捉襟见肘了。
以往的方法大多将关系建模为实体対上的一个离散的标签,这也是一种非常符合直觉的做法:首先通过命名实体识别(Named Entity Recognition, NER)确定出句子中所有的实体,然后学习一个关系分类器在所有的实体对上做RC,最终得到我们所需的关系三元组。然而这种Formulation在多个关系三元组有重叠的情况下会使得关系分类成为一个极其困难的不平衡多分类问题,导致最终抽取出的关系三元组不够全面和准确。

-
模型:
CasRel框架最核心思想是,把关系(Relation)建模为将头实体(Subject)映射到尾实体(Object)的函数,而不是将其视为实体对上的标签。具体来说,我们不学习关系分类器
在本文中我们提出了一个新的Formulation,以一种新的视角来重新审视经典的关系三元组抽取问题,并在此基础上实现了一个不受重叠三元组问题困扰的CasRel标注框架(Cascade Binary Tagging Framework)来解决RTE任务。
,而是学习关系特定的尾实体标注器 ,每个标注器都将在给定关系和头实体的条件下识别出所有可能的尾实体。在这种框架下,关系三元组抽取问题就被分解为如下的两步过程:
,每个标注器都将在给定关系和头实体的条件下识别出所有可能的尾实体。在这种框架下,关系三元组抽取问题就被分解为如下的两步过程: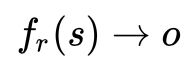
(1)确定出句子中所有可能的头实体;
(2)针对每个头实体,使用关系特定的标注器来同时识别出所有可能的关系和对应的尾实体。

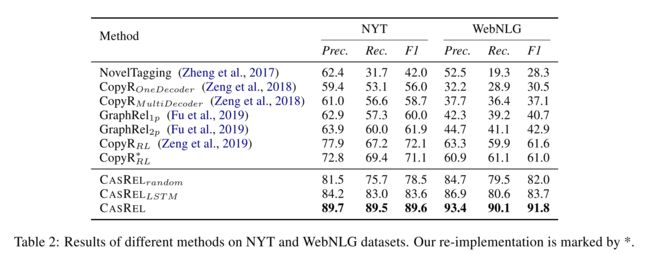
- 结果:
(二)不同的预训练任务
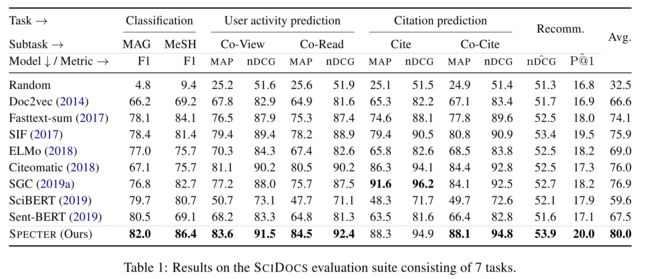
SPECTER: Document-level Representation Learning using Citation-informed Transformers
Allen AI
使用引文信息的Transformer进行文档级表示学习
背景:
这篇文章是将论文引用信息融入到预训练模型中去学习论文的表示。输入为论文的title、abstract和citation information。动机:
现有语言模型多用来学习词、句子级别的表示,这种通过文档内部的信号去建模整个文档表示具有局限性,在很多下游任务如论文分类或论文推荐方面表现并不好。引用关系作为一种自然发生的、跨文档的事件监督信号,指示哪些文档最相关,因此本文考虑融入这种文档间的信息来学习更好的文档表示。模型:
用SciBERT模型去预训练文档(论文的标题和摘要),然后用特殊标记CLS的表示作为最终的文档输出表示。
关键之处在于Loss的设计。这里用了对比学习的思想,设计了一种三元Loss:选取查询论文引用的论文为正例,未引用的论文为负例。选取负例时也有一些技巧,作者并不是直接在未引用的论文中随机选出负例,而是把这样的论文作为负例:P1引用了P2,P2引用了P3,但是P1没有引用P3,这时把P3作为hard negatives的候选。
本文的另一个贡献是提出了论文表示预训练的框架和七个预训练任务,还公布了一个新的包含论文标题、摘要和引用关系的数据集。

- 结果:
SPECTER在七个任务上优于其他基线。
(三)模型压缩与加速
FastBERT: a Self-distilling BERT with Adaptive Inference Time
北大与腾讯
具有自适应推理时间的自蒸馏BERT
- 背景:
- 动机:
虽然BERT类的预训练模型被证明非常有效,但它也存在模型大参数多等问题。本文提出一种蒸馏后的BERT模型,期望在减小模型本身的同时保持推理的精度。 - 模型:
模型的核心想法很简单,就是在每层Transformer后都增加一个分类器,去预测样本标签,如果某样本预测结果的置信度很高,就不用继续计算了。(这个想法有点像ICLR 2019的Universal Transformer)
论文把这个逻辑称为样本自适应机制(Sample-wise adaptive mechanism),就是自适应调整每个样本的计算量,容易的样本通过一两层就可以预测出来,较难的样本则需要走完全程。

- 结果:
论文比较了增加分类器后的模型计算成本要远小于增加Transformer层。

模型在6个数据集上的表现还是不错的,已经十分接近BERT的效果了。

(四)可解释性
Finding Universal Grammatical Relations in Multilingual BERT
斯坦福Manning组
很有意思,但还没完全看明白,后续更~