杂项维度概述
- 杂项维度就是一种包含的数据具有很少可能值的维度。
- 事务型商业过程通常产生一系列混杂的、低基数的标志位或状态信息。与其为每个标志或属性定义不同的维度,不如建立单独的将不同维度合并到一起的杂项维度。这些维度,通常在一个模式中标记为事务型概要维度,一般不需要所有属性可能值得笛卡尔积,但应该至少包含实际发生在源数据中得组合值。
- 例如,在销售订单中,可能存在很多离散数据(yes-no这种开关类型得值),如:
(1)verification_ind(如果订单已经被审核,值为yes)
(2)credit_check_flag (表示此订单的客户信用状态是否已经检查)
(3)new_customer_ind(如果这是新客户的首个订单,值为yes)
(4)web_order_flag(表示一个订单是在线上订单还是线下订单) - 这类数据通常用于增强销售分析,其特点是属性可能值很少。在建模复杂的操作源系统时,经常会遭遇大量五花八门的标志或者状态信息,他们包含小范围的离散值。处理这些较低基数的标志或者状态位可以采用以下几种方法。
1-忽略这些标志和指标
- 暂且将这种回避问题的处理方式也算做方法之一。在开发ETL系统时,如果他们是微不足道的,ETL开发小组可以向业务用户询问有关忽略这些标志的必要问题;但是这样的方案通常立即就被否决了,因为有人偶尔还需要他们。如果来自业务系统的标志或者状态时难以理解且不一致的,也许真的应该考虑去掉他们。
2-保持事实表行中的标志位不变
- 以销售订单为例,和源数据库一样,我们可以在事实表中也建立这四个标志位字段。在装载事实表时,除了订单号以外,同时装载这四个字段的数据,这些字段没有对应的维度表,而是作为订单的属性保留在事实表中。
- 这种处理方法简单直接,装载程序不需要做大量的修改,也不需要建立相关的维度表。但是一般我们不希望在事实表中存储难以识别的标志位,尤其时当每个标志位还配有一个文字描述字段时。不要在事实表行中存储包含大量字符的描述符,因为每一行都会有文字描述,他们可能会使表快速膨胀。在行中保留一些文本标志时令人反感的,比较好的做法时分离出单独的维度表保存这些标志位字段的数据,他们的数据量很小,并且极少改变。事实表通过维度表的代理键引用这些标志。
3-将每个标志位放入其自己的维度中
- 例如,为销售订单的四个标志位分别建立四个对应的维度表。在装载事实表数据前先处理这四个维度表,必要时生成新的代理键,然后再事实表中引用这些代理键。这种方法是将杂项维度当作普通维度来处理,多数情况下这也是不合适的。
- 首先,当类似的标志或状态位字段比较多时,需要建立很多的维度表,其次事实表的外键也会大量增加。处理这些新增的维度表和外键需要大量修改数据装载脚本,还会增加出错的机会,同时给ETL的开发、维护、测试过程带来很大的工作量。最后,杂项维度的数据有自己明显的特点,即属性多但每个属性的值少,并且极少修改,这种特点决定了他应该与普通维度的处理区分开。
- 作为一个经验值,如果外键的数量处于合理的范围中,即不超过20个,则在事实表中增加不同的外键时可以接受的。但是,若外键列表已经很长,则应该避免将更多的外键加入到事实表中。
4-将标志位字段存储到订单维度中
- 可以将标志位字段添加到订单维度表中。在数仓--DW--Hadoop数仓实践Case-08-退化维度中我们将订单维度表作为退化维度删除了,因为它除了订单号,没有其他任何属性。与其将订单号当成是退化维度,不如视其为将低基数标志或状态作为属性的普通维度。事实表通过引用订单维度表的代理键,关联到所有的标志位信息。
- 尽管该方法精确地表示了数据关系,但依然存在前面讨论的问题。在订单维度表中,每条业务订单都会存在对应的一条销售订单记录,该维度表的记录数会膨胀到跟事实表一样多,而在如此多的数据中,每个标志位字段都会存在大量的冗余,需要占用很大的存储空间。通常维度表应该比事实表小很多。
5-使用杂项维度
- 处理这些标志位的适当替换方法是仔细研究它们,并将它们包装为一个或多个杂项维度。杂项维度中放置各种离散的标志或状态数据,尽管为每个标志位创建专门的维度表会非常容易定位这些标志信息,但这会增加系统实现的复杂度。此外,正因为杂项维度的值很少,也不会频繁使用他们,所以不建议为保证单一目的的分配存储空间。杂项维度能够合理地存放离散属性值,还能够维持其他主要维度的存储空间。在维度建模领域,杂项维度术语主要用在DW/BI专业人员中。在与业务用户讨论时,通常将杂项维度成为事务指示器或事务概要维度。
- 杂项维度时低基数标志和指标的分组。通过建立杂项维度,可以将标志和指标从事实表中移除,并将它们放入到有用的多维框架中。
- 对杂项维度数据量的估算也会影响其建模策略。如果某个简单的杂项维度包含10个二值标识,例如:现金或信用卡支付类型、是否审核、在线或离线、本国或海外等,则最多将包含1024(2^10)行。假设由于每个标志都与其他标志一起作用,这种情况下浏览单一维度内的标识可能没什么意义。但是,杂项维度可提供所有标识的存储,并用于基于这些标识的约束和报表。事实表与杂项维度之间存在一个单一的、小型的代理键。
- 另一方面,如果具有高度非关联的属性,包含更多的数量值,则将它们合并为单一的杂项维度时不合适的。遗憾的是,是否使用统一杂项维度的决定并不完全是公式化的,要依据具体的数据范围而定。如果存在5个标识,每个仅包含3个值,则单一杂项维度是这些属性的最佳选择,因为维度最多仅有243 (3^5) 行。但是如果5个没有关联的标识,每个具有100个可能值,建议建立不同的维度,因为单一杂项维度表最大可能最在1亿(100^5)行。
- 关于杂项维度的一个微妙的问题是,在杂项维度中所有行的组合确定并已知的前提下,是应该实现为所有组合的完全笛卡尔积建立行,还是建立杂项维度行,只用于保存哪些在源系统中出现的组合情况的数据。答案要看大概有多少可能的组合,最大行数是多少。一般来说,理论上组合的数量较小,比如只有几百行时,可以预装载所有组合的数据;而如果组合的数据量大,那么在数据获取时,当遇到新标志或指标时,再建立杂项维度行。当然,如果源数据中用到了全体组合时,那别无选择只能预先装载好全部杂项维度数据。
- 如果杂项维度的取值事先并不知道,只有再获取数据时才能确定,那么就需要在处理业务系统事务表时,建立新观察到的杂项维度行。这一过程需要聚集杂项维度属性并将它们与已经存在的杂项维度行比较,已确定改行是否已经存在。如果不存在,将组建新的维度行,建立代理键。在处理事务表过程中适时地将该行加载到杂项维度中。
杂项维度应用
-
解释了杂项维度之后,将它们与处理标志位作为订单维度属性的方法进行比较。如希望分析订单事实的审核情况,其订单属性包含"是否审核"标志位;如果使用杂项维度,维度表中只会有很少的记录。而这些属性如果被存储到订单维度中,针对事实表的约束将会是一个巨大的列表,因为每一条订单记录都包含"是否审核"标志。在与事实表关联查询时,这两种处理方式将产生巨大的性能差异。
下图描述了杂项维度的具体实现,如下所示:
 杂项维度.PNG
杂项维度.PNG
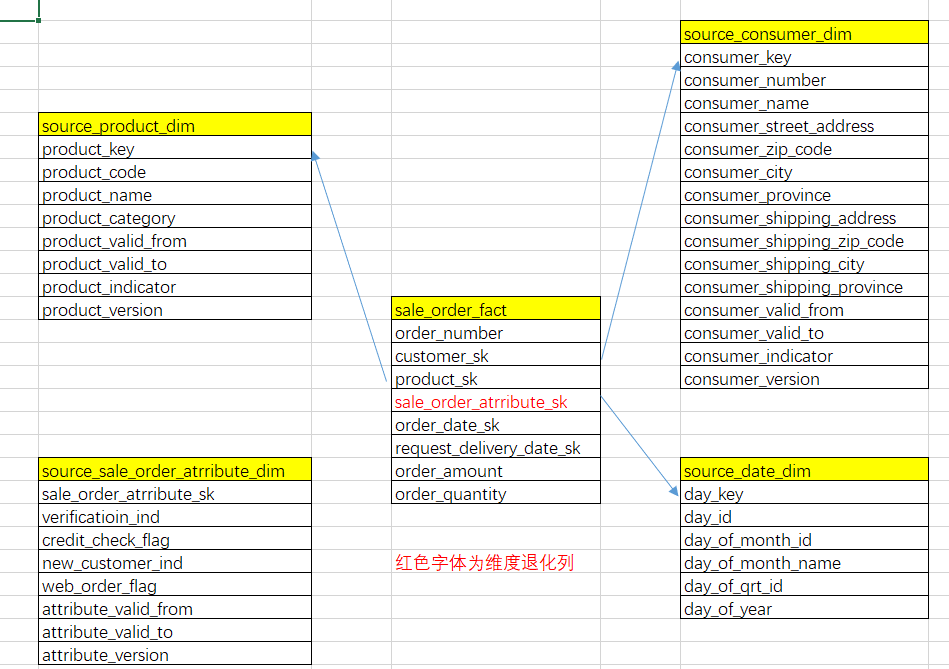
新增销售订单杂项维度
- 给现有的数据仓库新增一个销售订单属性杂项维度。需要新增一个名为source_sale_order_atribute_dim的杂项维度表,该表包括四个yes-no列:verfication_ind、credit_check_flag、new_customer_ind和web_order_flag,每个列只有两个可能值一个,Y或N,因为杂项维度表最多16行。我们假设这16行已经包含了所有可能的组合,因此可以预装这个维度,并且只需要装载一次。
- 注意,如果指导某种组合式不可能出现的,就不需要装载这种组合。
修改定期装载脚本
- 修改hive脚本
-- 创建杂项维度表
create table
source.source_sale_order_attribute_dim
(
sales_order_attribute_sk int comment 'sales order attribute SK',
verification_ind char(1) comment'verification index, y or n',
credit_check_flag char(1) comment'credit check flag, y or n',
new_customer_ind char(1) comment'new customer index, y or n',
web_order_flag char(1) comment'web order flag, y or n',
attribute_valid_from date comment'effective date',
atrribute_valid_to date comment'expiry date',
attribute_indicator varchar(50) comment 'attribute_indicator',
attribute_version int comment 'attribute_version'
)
clustered by (sales_order_attribute_sk) into 8 buckets
stored as
orc tblproperties ('transactional'='true');
-- 生成杂项维度数据
insert into
source.source_sale_order_attribute_dim
values
(1, 'y', 'n', 'n', 'n','1900-00-00', '9999-12-31','Current',1);
..... 共16条数据
-- 修改dw.sale_order_fact表,添加杂项维度外键
alter table dw.sale_order_fact rename to dw.sale_order_fact_old;
-- 创建新表
create table
dw.sale_order_fact
(
order_number int comment 'order_number',
customer_sk int comment 'customer surrogate key',
product_sk int comment 'product surrogate key',
sale_order_atrribute_sk int comment 'sale_order_atrribute_sk',
order_date_sk string comment 'date surrogate key',
request_delivery_date_sk int comment 'request_delivery_date_sk',
order_amount decimal (10 , 2 ) comment'order amount',
order_quantity int comment 'order_quantity'
)
clustered by (order_number)
into 8 buckets
stored as orc tblproperties('transactional'='true');
-- 将老表中的数据插入到新表中
insert into
dw.sale_order_fact
select
order_number,
customer_sk,
product_sk,
null,
order_date_sk,
request_delivery_date_sk,
order_amount,
order_quantity
from
dw.sale_order_fact_old;
-- 删除掉旧表
drop table dw.sale_order_fact_old;
-- 修改ods.ods_sale_order表
alter table
ods.ods_sale_order
add columns(
verification_ind char(1) comment 'verification index, y or n',
credit_check_flag char(1) comment 'credit check flag, y or n',
new_customer_ind char(1) comment 'new customer index, y or n',
web_order_flag char(1) comment 'web order flag, y or n'
);
- 语句说明,还是老策略"腾笼换鸟";
- 修改msyql中sale_order表结构
-- 修改 mysql中表结构
alter table
sale_order
add verification_ind char(1) after product_code,
add credit_check_flag char(1) after verification_ind,
add new_customer_ind char(1) after credit_check_flag,
add web_order_flag char(1) after new_customer_ind ;
- 因为sqoop抽取的时候没有指定字段,所以sqoop增量抽取脚本不需要修改,但是需要注意,增量导入的最大id不能变动。
- 修改定期装载脚本,ods.ods_sale_order表
-- 修改装载脚本
insert into
sales_order_fact
select
a.order_number,
customer_sk,
product_sk,
g.sales_order_attribute_sk,
e.order_date_sk,
f.request_delivery_date_sk,
order_amount,
order_quantity
from
ods.sale_order a,
source.source_consumer_dim c,
source.source_product_dim d,
source.source_order_date_dim e,
source.source_request_delivery_date_dim f,
source.source_sale_order_attribute_dim g,
ods.ods_cdc_time h
where
a.customer_number = c.consumer_number
and
a.order_date >= c.consumer_valid_from
and
a.order_date < c.consumer_valid_to
and
a.product_code = d.product_code
and
a.order_date >= d.product_valid_from
and
a.order_date < d.product_valid_to
and
to_date(a.order_date) = e.order_date
and
to_date(a.request_delivery_date) = f.request_delivery_date
and
a.verification_ind = g.verification_ind
and
a.credit_check_flag = g.credit_check_flag
and
a.new_customer_ind = g.new_customer_ind
and
a.web_order_flag = g.web_order_flag
and
a.entry_date >= h.last_load
and
a.entry_date < h.current_load ;
- 脚本说明,从各种表中进行关联join,组建事实表。写脚本之前需要理清之间的关系。
- 注意:此案例中杂项维度式采用预装载的方式,如果有数据变动需要采用SCD2进行处理。