基于 Flink + Hive 构建流批一体准实时数仓
基于 Flink + Hive 构建流批一体准实时数仓
基于 Hive 的离线数仓往往是企业大数据生产系统中不可缺少的一环。Hive 数仓有很高的成熟度和稳定性,但由于它是离线的,延时很大。在一些对延时要求比较高的场景,需要另外搭建基于 Flink 的实时数仓,将链路延时降低到秒级。但是一套离线数仓加一套实时数仓的架构会带来超过两倍的资源消耗,甚至导致重复开发。
想要搭建流式链路就必须得抛弃现有的 Hive 数仓吗?并不是,借助 Flink 可以实现已有的 Hive 离线数仓准实时化。本文整理自 Apache Flink Committer、阿里巴巴技术专家李劲松的分享,文章将分析当前离线数仓实时化的难点,详解 Flink 如何解决 Hive 流批一体准实时数仓的难题,实现更高效、合理的资源配置。文章大纲如下:
-
离线数仓实时化的难点
-
Flink 在流批一体的探索
-
构建流批一体准实时数仓应用实践
离线数仓实时化的难点
离线数仓
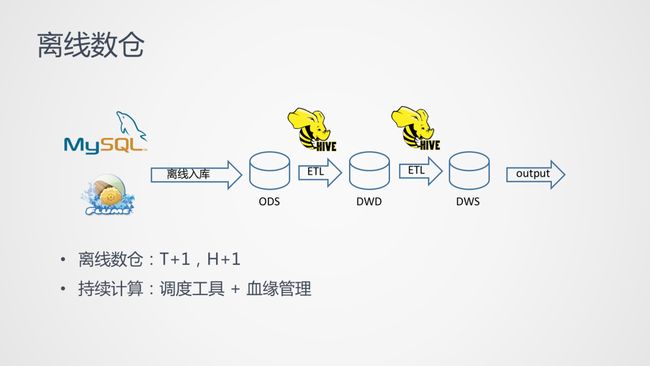
上图是一个典型的离线数仓,假设现在公司有一个需求,目前公司的数据量很大,需要每天出一个报表且输出到业务数据库中。首先是刚入库的业务数据,大致分为两种,一种是 MySQL 的 binlog,另外一种是业务系统中的业务打点,这个日志打点信息可以通过 Flume 等工具去采集,再离线入库到数仓中。然后随着业务越来越多,业务中的各个表可以做一些抽象,抽象的好处是更好的管理和更高效的数据复用和计算复用。所以数仓就分成了多层 (明细层、中间层、服务层等等),每一层存的是数据表,数据表之间通过 HiveSQL 的计算来实现 ETL 转换。
不止是 HiveSQL ,Hive 只是静态的批计算,而业务每天都要出报表,这意味着每天都要进行计算,这种情况下会依赖于调度工具和血缘管理:
-
调度工具:按照某个策略把批计算调度起来。
-
血缘管理:一个任务是由许多个作业组合而成,可能有非常复杂的表结构层次,整个计算是一个非常复杂的拓扑,作业间的依赖关系非常复杂 (减少冗余存储和计算,也可以有较好的容错),只有当一级结束后才能进行下一级的计算。
当任务十分庞大的时候,我们得出结果往往需要很长的一段时间,也就是我们常说的 T+1,H+1 ,这就是离线数仓的问题。
第三方工具

上面说过,离线数仓不仅仅是简单的 Hive 计算,它还依赖了其它的第三方工具,比如:
-
使用 Flume 来入库,但存在一定的问题,首先,它的容错可能无法保证 Exactly-Once 效果,需要下游再次进行去重操作。其次,自定义逻辑需要通过一些手段,比如脚本来控制。第三,离线数仓并不具备良好的扩展能力,当数据剧增时,增加原本的并发数就比较困难了。
-
基于调度工具的作业调度会带来级联的计算延迟,比如凌晨 1 点开始计算昨天的数据,可能需要到早上 6、7 点才能做完,并且无法保证在设置的调度时间内数据可以完全 ready 。此外,级联的计算还会带来复杂的血缘管理问题,大任务的 Batch 计算可能会突然打满集群的资源,所以也要求我们对于负载管理进行考量,这些都会给业务增加负担。
无论是离线数仓还是第三方工具,其实主要的问题还是“慢”,如何解决慢的问题,此时就该实时数仓出场了。
实时数仓

实时数仓其实是从 Hive+HDFS 的组合换成了 Kafka,ETL 的功能通过 Flink 的流式处理解决。此时就不存在调度和血缘管理的问题了,通过实时不断的增量更新,最终输出到业务的 DB 中。
虽然延时降低了,但此时我们会面临另外一些问题:
-
历史数据丢失,因为 Kafka 只是临时的存储介质,数据会有一个超时的时间 (比如只保存 7 天的数据),这会导致我们的历史数据丢失。
-
成本相对较高,实时计算的成本要大于离线计算。
Lambda 架构
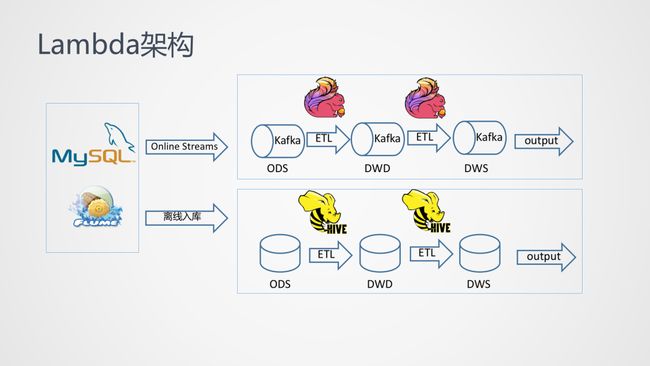
所以此时很多人就会选择一套实时一套离线的做法,互不干扰,根据任务是否需要走实时的需求来对需求进行分离。
这套架构看似解决了所有问题,但实际带来的问题也是非常多。首先,Lambda 架构造成了离线和实时的割裂问题,它们解决的业务问题都是一样的,但是两套方案让同样的数据源产生了不同的计算结果。不同层级的表结构可能不一致,并且当数据产生不一致的问题时,还需要去进行比对排查。
随着这套 Lambda 架构越走越远,开发团队、表结构表依赖、计算模型等都可能会被割裂开,越到后面越会发现,成本越来越高,而统一的代价越来越大。
那么问题来了,实时数仓会耗费如此大的资源,且还不能保留历史数据,Lambda 架构存在如此多的问题,有什么方案可以解决呢?
数据湖

数据湖拥有不少的优点,原子性可以让我们做到准实时的批流一体,并且支持已有数据的修改操作。但是毕竟数据湖是新一代数仓存储架构,各方面都还不是很完美,目前已有的数据湖都强依赖于 Spark(当然 Flink 也正在拥抱数据湖),将数据迁移到数据湖需要团队对迁移成本和人员学习成本进行考量。
如果没有这么大的决心迁移数据湖,那有没有一个稍微缓和一些的方案加速已有的离线数仓呢?
Flink 在批流一体上的探索
统一元数据
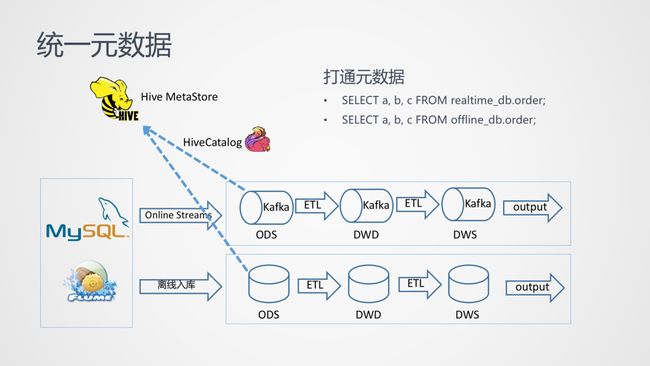
Flink 一直持续致力于离线和实时的统一,首先是统一元数据。简单来说就是把 Kafka 表的元数据信息存储到 HiveMetaStore 中,做到离线和实时的表 Meta 的统一。(目前开源的实时计算并没有一个较为完善的持久化 MetaStore,Hive MetaStore 不仅能保存离线表,也可以承担实时计算的 MetaStore 能力)。
统一计算引擎
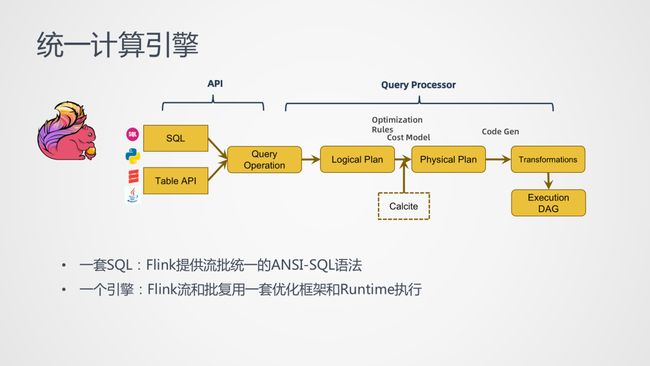
同样的元数据之后,实时和离线的表结构和层次可以设计成一样,接下来就是可以共用:
-
同一套 SQL,Flink 自身提供批流一体的 ANSI-SQL 语法,可以大大减小用户 SQL 开发者和运维者的负担,让用户专注于业务逻辑。
-
同一个引擎,Flink 的流和批复用一套优化和 Runtime 框架,现阶段的大数据引擎还远远达不到完全稳定的情况,所以仍然有很多时候需要我们去深入的分析和优化,一套引擎可以让开发者专注单个技术栈,避免需要接触多个技术栈,而只有技术广度,没有技术深度。
统一数据
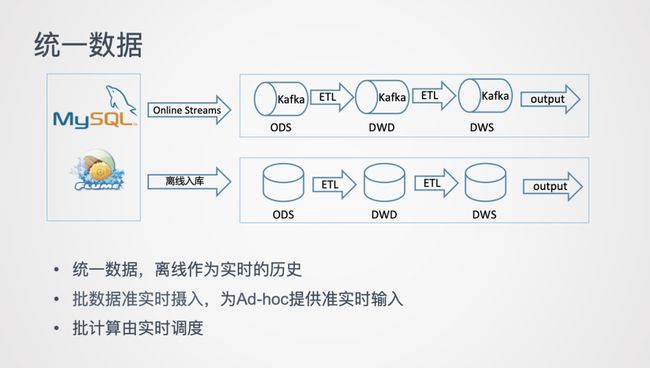
分析了元数据和计算引擎的统一,更进一步,是否能统一实时和离线的数据,避免数据的不一致,避免数据的重复存储和重复计算。ETL 计算是否能统一呢?既然实时表设计上可以和离线表一模一样,是否可以干脆只有实时表的 ETL 计算,离线表从实时表里获取数据?
并且,通过实时链路可以加速离线链路的数据准备,批计算可以把调度换成流输入。
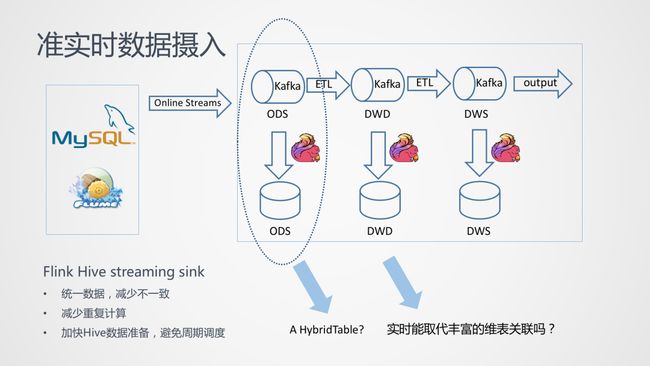
Flink Hive/File Streaming Sink 即为解决这个问题,实时 Kafka 表可以实时的同步到对于的离线表中:
-
离线表作为实时的历史数据,填补了实时数仓不存在历史数据的空缺。
-
数据批量准实时摄入为 Ad-hoc 查询离线表提供了准实时输入。
此时离线的批计算也可以交由实时调度,在实时任务处理中某个契机 (Partition Commit 见后续) 自行调度离线那块的任务进行数据同步操作。
此时实时和离线的表已经基本统一,那么问题来了,Kafka 中的表和 Hive 中的表能否就共用一张表呢?我的想法是之后可能会出现以下情况,在数仓中定义一张表,分别对应着 Kafka 和 Hive+HDFS 两种物理存储:
-
用户在进行 insert 操作时,就自然插入到了 Kafka 的实时 table 当中,同时生成另外一条链路,自动同步到 Hive Table 当中。这样这一张表就非常的完整,不仅满足实时的需求,而且拥有历史的数据。
-
一个 SQL 读取这样的一个 Hybrid Source ,根据你的查询语句后面的 where 条件,自动路由到 Hive 的历史数据,或者是 Kafka 的实时数据。根据一定的规则先读 Hive 历史数据,再读 Kafka 实时数据,当然这里有一个问题,它们之间通过什么标识来切换呢?一个想法是数据中或者 Kafka 的 Timestamp。
Hive Streaming Sink 的实现
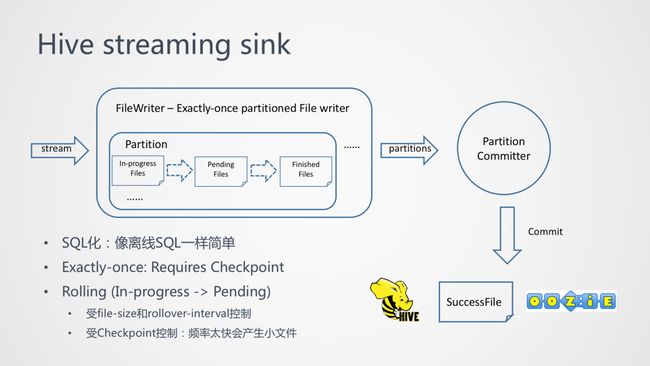
Flink 1.11 前已经有了 StreamingFileSink,在 1.11 中不但把它集成到 SQL 中,让这个 Hive Streaming Sink 可以像离线的 Hive SQL 那样,所有的业务逻辑都由 SQL 去处理,而且带来了进一步的增量。
接下来介绍下 Hive/File Streaming Sink,分为两个组件,FileWriter 和 PartitionCommitter:
-
FileWriter 组件可以做到分区感知,通过 checkpoint 机制可以保证 Exactly-Once(分布式场景是不可靠的,需要通过两阶段提交 + 文件 Rename 的幂等性),FileWriter 也提供了 Rolling 相关的参数,这个 Rolling 指的是我们的流式处理过程,它可以通过两个参数来控制执行频率,file-size 就是每个数据流的大小,rollover-interval 就是时长间隔。但是需要注意,checkpoint 不宜设置太频繁,以免产生过多的小文件。
-
Partition Committer,通过一系列的业务逻辑处理后得到的 Finished Flies 就直接可用了吗?因为我们典型的 Hive 表都是分区表,当一个分区就绪后,还需要通知下游,Partition 已经处理完成,可以同步到 Hive metastore 中了。我们需要在合适的时机来有效的 trigger 特定的 Partition commit。Partition committer 总的来说,就是完成了 Hive 分区表的数据及元数据的写入,甚至可以完成通知调度系统开始执行之后的 Batch 作业。

因为流式作业是不间断的在运行的,如何设置分区提交的时间,某个分区什么时候提交它呢?
-
第一种是默认策略 Process time ,也就是我们所说的事件被处理时的当前系统时间,但是缺点也比较明显,可能出现各种各样的数据不完整。
-
推荐策略就是 partition-time,这种策略可以做到提交时的语义明确且数据完整,partition 字段就是由 event time ,也就是事件产生的时间所得到的。
如果当前时间 Current time > 分区产生的时间 + commitDelay 延时,即是可以开始进行分区提交的时间。一个简单的例子是小时分区,比如当前已经 12 点过 1 分了,已经过了 11 点的分区 + 一个小时,所以我们可以说不会再有 11 点分区的数据过来了,就可以提交 11 点的分区。(要是有 LateEvent 怎么办?所以也要求分区的提交是幂等的。)

接下来介绍分区的提交具体作用,最直接的就是写 SuccessFile 和 Add partition 到 Hive metastore。
Flink 内置支持了 Hive-MetaStore 和 SuccessFile,只要配置"sink.partition-commit.policy.kind" 为 "metastore,success-file",即可做到在 commit 分区的时候自动 add 分区到 Hive 中,而且写 SuccessFile,当 add 操作完成的时候,这个 partition 才真正的对 Hive 可见。
Custom 机制允许自定义一个 Partition Commit Policy 的类,实现这个类可以做到在这个分区的任务处理完成后:比如触发下游的调度、Statistic Analysis、又或者触发 Hive 的小文件合并。(当然触发 Hive 的小文件合并不但需要启动另一个作业,而且做不到一致性保证,后续 Flink 也会有进一步的探索,在 Flink 作业中,主动完成小文件的合并)。
实时消费
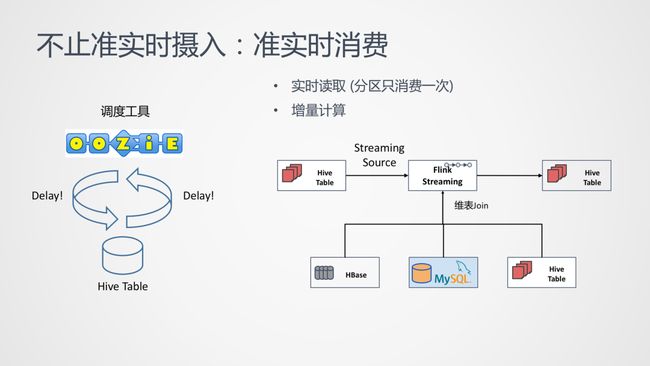
不止是准实时的数据摄入,Flink 也带来了维表关联 Hive 表和流实时消费 Hive 表。
我们知道 Flink 是支持维表关联查询 MySQL 和 HBase 的,在计算中维护一个 LRU 的缓存,未命中查询 MySQL 或 HBase。但是没有 Lookup 的能力怎么办呢?数据一般是放在离线数仓中的,所以业务上我们一般采用 Hive Table 定期同步到 HBase 或者 MySQL。Flink 也可以允许直接维表关联 Hive 表,目前的实现很简单,需要在每个并发中全量 Load Hive 表的所有数据,只能针对小表的关联。
传统的 Hive Table 只支持按照批的方式进行读取计算,但是我们现在可以使用流的方式来监控 Hive 里面的分区 / 文件生成,也就是每一条数据过来,都可以实时的进行消费计算,它也是完全复用 Flink Streaming SQL 的方式,可以和 HBase、MySQL、Hive Table 进行 Join 操作,最后再通过 FileWriter 实时写入到 Hive Table 中。
构建流批一体准实时数仓应用实践

案例如下:通过 Flume 采集日志打点 Logs,计算各年龄层的 PV,此时我们存在两条链路:
-
一条是实时链路,通过输入访问日志,关联 Hive 的 User 表来计算出所需要的结果到业务 DB 中。
-
而另一条则是离线链路,我们需要 Hive 提供小时分区表,来实现对历史数据的 Ad-hoc 查询。
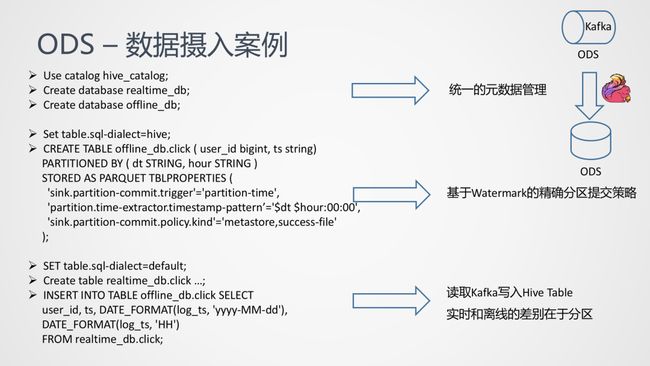
这里就是我们刚刚提到的,虽然是对应两个 database:realtime_db 和 offline_db,但是它们共用一份元数据。
对于 Hive 表我们可以通过 Flink SQL 提供的 Hive dialect 语法,然后通过 Hive 的 DDL 语法来在 Flink 中创建 Hive 表,这里设置 PARTITION BY 天和小时,是与实时链路的不同之处,因为实时链路是没有分区概念的。
如何在表结构里避免分区引起的 Schema 差异?一个可以解决的方案是考虑引入 Hidden Partition 的定义,Partition 的字段可以是某个字段的 Computed Column,这也可以与实际常见的情况做对比,如天或小时是由时间字段计算出的,之后是下面的三个参数:
-
sink.partition-commit.trigger,指定什么时候进行 partition 的 commit,这里设置了 partition-time,用于保证 exactly-once;
-
partition.time-extractor.timestamp-pattern,怎样从 partition 中提取时间,相当于设置了一个提取格式;
-
sink.partition-commit.policy.kind,既 partition commit 所要进行的操作,也就是刚刚提到的 metastore,success-file。
之后设置回默认的 Flink dialect,创建 Kafka 的实时表,通过 insert into 将 Kafka 中的数据同步到 Hive 之中。
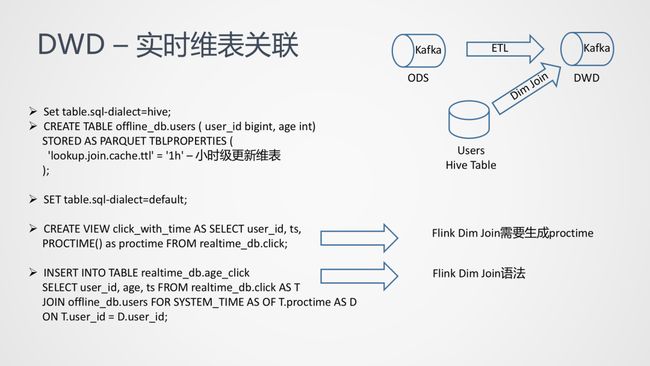
这部分是关于 Kafka 中的表如何通过 Dim join 的方式,拿到 User 表的年龄字段。图中需要关心的是 lookup.join.cache.ttl 这个参数,我们会将 user 这张表用类似于 broadcast 的方式,广播到每一个 task 中,但是这个过程中可能出现 Hive 中的 table 存在更新操作,这里的 1h 就说明,数据有效期仅为 1 小时。创建 view 的目的是将 Dim join 所需要的 process time 加上(Dim Join 需要定义 Process time 是个不太自然的过程,后续也在考虑如何在不破坏 SQL 语义的同时,简化 DimJoin 的语法。)
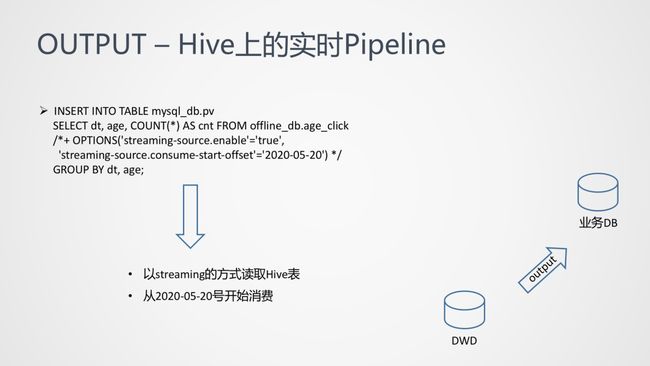
通过实时 Pipeline 的手段消费 Hive Table,而不是通过调度或者以往手动触发的 batch 作业,第一个参数 streaming-source.enable,打开流处理机制,然后使用 start-offset 参数指定从哪个分区 / 文件开始消费。此时,整个流批一体准实时数仓应用基本算是完成啦。
未来规划
Hive 作为分区级别管理的 Table Format 在一些方便有比较大的限制,如果是新型的 Table Format 比如 Iceberg 会有更好的支持,未来 Flink 会在下面几个方面加强:
-
Flink Hive/File Streaming Sink 的 Auto Compaction(Merging) 能力,小文件是实时的最大阻碍之一。
-
Flink 拥抱 Iceberg,目前在社区中已经开发完毕 Iceberg Sink,Iceberg Source 正在推进中,可以看见在不远的将来,可以直接将 Iceberg 当做一个消息队列,且,它保存了所有的历史数据,达到真正的流批统一。
-
增强 Flink Batch 的 Shuffle,目前完全的 Hash Shuffle 带来了很多问题,比如小文件、随机 IO、Buffer 管理带来的 OOM,后续开源 Flink (1.12) 会加强力量引入 SortedShuffle 以及 ShuffleService。
-
Flink Batch BoundedStream 支持,旧的 Dataset API 已经不能满足流批统一的架构,社区 (1.12) 会在 DataStream 上提供 Batch 计算的能力。