论文简读《视听觉深度伪造检测技术研究综述》
《视听觉深度伪造检测技术研究综述》
概述:
深度学习被广泛的应用于各个领域,自然语言处理、计算机视觉、无人驾驶等,推动了人工智能的发展。但在带来好处的同时,也对信息安全方面也有一定的威胁,深度学习可以能够生成逼真的虚假图像及音视频内容。本文介绍了深度伪造的背景和内容生成原理,概述和分析了针对不同类型伪造内容(包括音视图像)的检测方法和数据集。展望了未来的深度伪造检测和防御的研究方向和挑战。
文章结构:
第 1 章 引言
第 2 章 扼要介绍了深度伪造生成技术的基本原理及发展现状
第 3 章 对已存在的深度伪造内容检测技术进行了归纳和分析
第 4 章 对已有的深度伪造数据集进行了介绍
第 5 章 则对影响深度伪造检测的相关技术进行了介绍和分析
第 6 章 展望了深度伪造检测技术的未来研究方向和所面临的挑战
1.引言
deepfake源自美国的一个的社交用户网名,他发布了一个把一个女演员的面孔映射到色情表演者身上的伪造视频。
深度伪造技术自身并不存在善恶, 所以本文更加倾向于赋予“深度伪造”一个中立化定义: 基于深度学习等智能化方法创建或合成视听觉内容(如图像、音视频、文本等)。
深度伪造技术可以推动娱乐与文化交流产业的新兴发展, 如可应用于在电影制作中创建虚拟角色、视频渲染、声音模拟; “复活”历史人物或已逝的亲朋好友, 实现“面对面”沟通, 创造了一种新型的交流方式。
深度伪造技术也可用于误导舆论、扰乱社会秩序, 甚至可能会威胁人脸识别系统、干预政府选举和颠覆国家政权等, 已成为当前最先进的新型网络攻击形式。基于深度伪造技术构建的图像/视频换脸、语音诈骗等事件数见不鲜, 相继出现了FakeApp、Faceswap等多个“一键式”内容合成(图像、视频、语音)应用程序, 2019 年 6 月甚至出现了“一键式”智能脱衣软件 Deepnude, 虽然该软件在发布之后即迫于舆论压力被开发者下架, 但仍在全球范围内引起了巨大恐慌。深度伪造内容的危害和影响已经蔓延至世界各地, 针对深度伪造内容的检测和防御现已成为世界各国政府、企业乃至个人所关注的热点问题之一。
2.深度伪造内容生成技术
在深度伪造中广泛使用的深度学习技术主要有:
生成对抗网络(Generative adversarial networks, GAN)
卷积神经网络(Convolutional neural network, CNN)
循环神经网络(Recurrent neural network, RNN)
变分自编码器(Variational auto-encoder, VAE)
2.1视觉深度伪造生成技术
视觉深度伪造生成技术的实现总体可以分为数据收集、模型训练和伪造内容生成三个核心步骤, 以伪造人脸图像生成为例对深度视觉伪造生成技术的共性原理进行简单介绍, 假设我们的目标是将 Alice 的脸换至 Bob 的身体上。
- 数据收集
数据收集顾名思义是通过各种渠道对 Alice 和Bob 的已有图像进行大量收集, 以便为模型训练提供数据支撑。
- 模型训练
目前, 深度伪造模型的构造主要基于GAN实现, 由编码器(encoder)和解码器(decoder)构成: 编码器用于提取人脸图像的潜在特征, 解码器则用于重构人脸图像, 基于该原理的典型工具如 DeepFake_tf和Dfaker。为了实现换脸操作, 模型需要两个编码器/解码器对(编码器 A/解码器 A, 编码器 B/解码器 B), 分别基于已收集的 Alice 和 Bob 的图像集进行训练, 其中编码器 A 和编码器 B 具有相同的编码网络(即参数共享), 编码器的统一性能够保证模型学习到两组图像面部结构之间的相似性(如五官特征)。伪造模型具体的训练过程如下图所示。
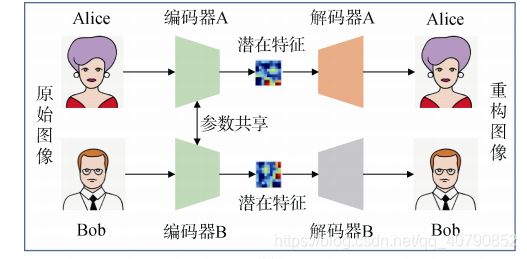
- 伪造图像生成
待模型训练完成之后, 通过将模型训练中 Alice和 Bob 的解码器互换, 进而构建新的编码器/解码器对(编码器 A/解码器 B, 编码器 B/解码器 A), 然后选取 Alice 的一张图像作为目标图像, 在编码器 A 编码完成之后, 基于解码器 B 进行解码, 从而生成载有Alice 面部、Bob 身体的深度伪造(换脸)图像, 如下图所示。
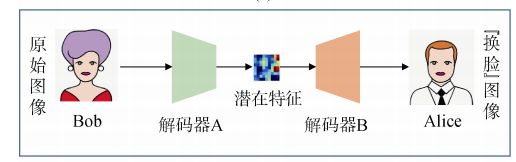
2.2 听觉深度伪造生成技术
音频生成技术最初的研究主要专注于文本到语音的转换(Text-to-speech, TTS), 主要可分为两种方
法: 拼接式语音合成方法和基于参数估计的语音合成方法。 在拼接式语音合成方法中, 音频的生成主要通过对语音索引词典中预先录制的小部分语音进行排序。基于参数估计的语音合成方法则通过将文本映射到语音的显著参数, 进而基于声码器来合成语音。其中典型语音参数估计方法为隐马尔可夫模型(Hidden markov model, HMM)。随着人工智能技术的兴起, 研究人员借鉴图像、 视频的新型智能化合成技术, 开始探索智能化辅助的语音合成方法, 陆续提出了基于声码器、GAN、自编码器(Denoising autoencoder, DAE)、 自 回 归 模 型(Autoregressive model, AR)等一系列新兴的语
音合成技术, 推动了语音合成产业的快速发展。
3.深度伪造内容检测技术
现有的深度伪造内容检测方法多依赖于深度学习模型, 基于深度伪造内容数据集的训练, 实现特征提取并构建分类器。特征提取可分为自动提取和手动提取两种类型: 自动提取指在数据集上直接训练模型, 即让模型自主学习和提取能够区分真伪内容的特征; 手动提取特征则需要对数据集进行预处理, 人工提取出部分特征, 进而基于已提取特征完成分类器的训练。
3.1视觉深度伪造检测技术
深度伪造内容颠覆了人们对“眼见为实”观念的认知, 近两年出现的视觉深度伪造主要有换脸、表情迁移和动作迁移等方式, 造成了全球范围内的“信任”危机。现有(已调研)的视觉深度伪造内容检测方法可分为深度伪造图像检测技术和深度伪造视频检测技术两大类。
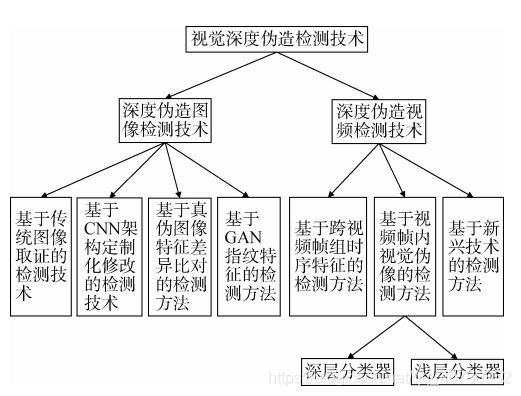
3.1.1 深度伪造图像检测技术
- 基于传统图像取证的检测技术
Nataraj 等人通过提取像素域中 RGB 通道上的共现矩阵(co-occurrence matrices), 基于 CNN 构建了一种像素级的图像检测模型来实现对GAN生成伪造图像的检测。等人提出一种在商业软件Adobe Photoshop 上编写脚本来检测合成图像内容的方法。然而, 这类借鉴传统图像取证技术的深度伪造图像检测模型可通过在伪造图像中加噪声的方式绕过。
- 基于 CNN 架构定制化修改的检测技术
Mo 等人通过修改 CNN 架构(如输入图像的高通滤波器、层组数和激活函数), 进而以监督学习的方式实现了对深度伪造图像的检测。但是这种通过定制化修改 CNN 架构和损失函数等方式构建的深度伪造图像检测模型容易受到对抗样本的攻击。
- 基于真伪图像特征差异比对的检测方法
Zhang 等人使用稳定特征加速算法(Sped up robust features, SURF)和词袋模型(Bag of words, BoW)来提取图像特征, 并将其分别在支持向量机(Support vector machine, SVM), 随机森林(Random forest, RF)和多层感知器(Multilayer perceptron, 简称 MLP)等分类器上进行了测试, 准确率均可达到92%以上。但该模型所使用的数据集相对较小, 仅包含 10000 张图像(伪造图像占 50%), 且其数据集中的伪造图像质量也未与其他深度伪造数据集进行比较。
- 基于 GAN 指纹特征的检测方法
Zhang 等人通过探索 GAN 指纹特征提出了一种基于频谱输入的分类器模型AutoGAN, 该模型能够实现对基于 CycleGAN等流行 GAN 模型所生成的伪造图像的准确检测。Zheng 等人则提出了一种基于频域分析的深度伪造图像分类模型 SegNet, 该模型在高像素图像集Faces-HQ、中像素图像集 CelebA和低像素图像集 FaceForensics++上均具有较高的准确率。Wang 等人提出了一种基于神经元覆盖的深度伪造图像检测方法, 其性能优于基于传统图像取证和CNN 架构定制化修改的深度伪造图像检测模型。然而, 深度伪造图像生成模型可通过选用无指纹特征的 GAN 来绕过这类检测模型, 且 GAN 技术进展迅速, 所以上述检测方法所提取的 GAN 指纹特征并不具有持久性和通用性。
3.1.2 深度伪造视频检测技术
由于视频在被压缩后, 帧数据会产生严重的退化现象, 且视频帧组之间的时序特征存在一定的变化, 故多数基于静态特征的深度伪造图像检测方法无法直接用于深度伪造视频的检测。 当前, 深度伪造视频检测方法可分为三大类: 第一类是基于跨视频帧组时序特征的检测方法, 第二类是基于视频帧内视觉伪像的检测方法, 第三类则是基于新兴技术的检测方法。
-
基于跨视频帧组时序特征的检测方法
由于深度伪造内容检测模型经常使用在线收集的(静态)面部图像集进行训练, 无法实现对眨眼、呼吸和心跳等生理信息的准确伪造, 故可以基于生理信息的合理性来构建深度伪造视频检测方法。 -
基于视频帧内视觉伪像的检测方法
基于视频帧内视觉伪像的检测技术主要通过探索视频帧内视觉伪像提取判别特征, 并将这些特征分配至深层或浅层分类器中进行训练, 其中深层分类器基于神经网络模型实现, 而浅层分类器则采用
简单的机器学习模型实现, 最终完成对深度伪造视频的准确检测。 -
基于新兴技术的检测方法
Hasan 等人基于区块链和智能合约构建了一种深度伪造视频检测方法, 该方法的前提假设是视
频只有来源可追溯才是真实的。每个视频都与一个智能合约相关联, 该智能合约链接到其父视频, 并
且每个父视频在其层次结构中都有一个指向其子视频的链接。通过该链, 即使视频已被多次复制, 用户也可以可靠地追溯到其与原始视频关联的初始智能合约。智能合约的一个重要属性是星际文件系统(Inter planetary file system, IPFS)具有独特的哈希值, 该哈希值可用于以分散和内容可寻址的方式存储视频。Hasan 等人进而对智能合约的关键特性和功能进行了测试, 以应对中间人(Man in the middle, MITM)、重放和分布式拒绝服务(Distributed denial of service, DDoS)等常见安全攻击。 实验证明, 这种方法可以扩展到图像、音频和文本等其他数字内容的伪造检测之中。
3.2 听觉深度伪造检测技术
随着听觉深度伪造的流行和技术能力不断的提升, 针对恶意使用(如语音诈骗)的听觉深度伪造的检测变得越来越重要。现有的听觉深度伪造检测技术主要通过语速、声纹和频谱分布等生物信息的差异化特征实现。
4 深度伪造内容数据集
目前, 深度伪造检测模型的训练和评估多依赖于大规模的深度伪造内容数据集, 数据集的质量直
接影响着检测模型的准确率, 因此对高质量深度伪造视频数据集的需求不断增长。当前具有代表性的深度伪造内容数据集如表 2 所示。
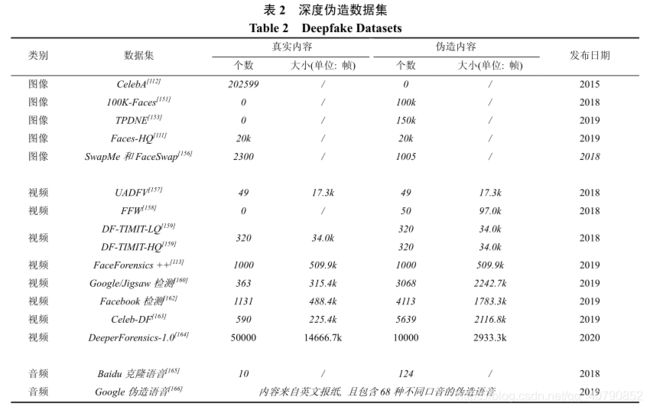
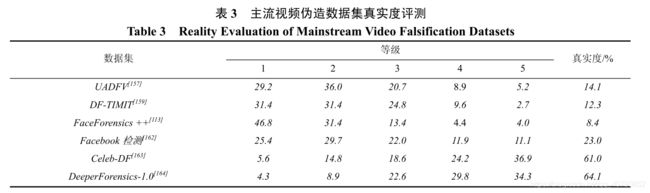
主流视频伪造数据集真实度评测如表3所示。专家意见总共分为 5 个等级: 等级 1-强烈不认可, 等级 2-稍微不认可, 等级 3-中立, 等级 4-稍微认可, 等级 5-强烈认可。进一步, Jiang 等人将等级 4、等级 5 的得分总和定义为该数据集整体的“真实度”。
5.相关技术
深度伪造检测技术多基于深度学习模型构建, 所以针对深度学习模型本身或围绕深度学习模型的相关研究进展(成果)在一定程度上会影响深度伪造检测和防御技术的研究方向,
5.1 人工智能对抗技术
人工智能对抗技术的主要研究目标是通过构建对抗样本实现对特定人工智能模型的攻击。对抗样本是一种通过指定算法处理的内容, 通过在原始样本加入部分扰动, 进而使目标模型出错。 针对分类模型, 对抗样本的目标是改变其对于原有样本的分类; 针对检测模型, 对抗样本的目标则是使其无法发现特定目标或对特定目标识别错误, 如针对智能语音系统或物理目标检测系统的对抗攻击。
5.2 数字水印技术
数字水印(Digital watermark)是一种将特定标识信息嵌入图像、 音视频等数字载体中, 但不影响其使用价值且不易被人的直觉系统直接察觉的方法。数字水印可以用于验证信息的真实性和完整性, 目前主要应用于防伪溯源、欺诈和篡改检测、版权保护等领域。
5.3 模型可解释技术
目前, 针对深度学习模型的可解释性研究工作仍然处于初级阶段。深度学习模型, 作为一个具有
强大功能的“黑盒子”, 由于其参数规模庞大、神经元结构复杂及内部状态的不透明性, 使得对其内在
机理的理解和研究工作面临巨大的挑战。目前, 业界对可解释性还没有公认的统一性定义, 研究者基
于其各自的角度赋予了“可解释性”不同的定义, 如Miller 等人将可解释性定义为“人们可以理解决策原因的程度”, 而 Kim 等人将其定义为“人类可以一致地预测模型结果的程度”。直观来讲, 可解释性是回答针对一个特定的输入, “黑盒子”内部是如何“运作”得到相应的输出的问题。现有的深度学习模型推动了无人驾驶、语音交互等生活服务类产业的快速发展, 但由于其在可解释性研究工作上的困难, 使人们对基于深度学习模型的应用产生了信任危机。所以, 模型具有可解释性是人们对智能化系统产生信任的基石。
6.总结与展望
当前, 主流的深度伪造内容检测技术主要依赖两点: 基于伪造内容数据集完成对模型检测器的训
练, 以及基于生物信息不一致性实现对伪造内容的判别。针对第一点, 当伪造图像、音视频等内容来源于新型伪造内容生成技术时, 或训练数据集不包含某一种内容伪造技术生成的样本时, 则检测器对该类伪造内容无法实现良好的检测效果; 针对第二点, 受限于当前的伪造内容生成技术水平, 伪造图像、 音视频等内容存在生物信息以及习惯等不一致性, 如眨眼频率、 手部动作等, 基于这些差异化特征可实现伪造内容的检测, 然而随着生成技术水平的不断提升, 深度伪造内容将趋近逼真, 基于生物不一致性的检测也将变得越来越困难。
针对以上深度伪造内容检测技术面临的挑战以及难点问题, 我们可以从多角度出发, 探索针对深度伪造内容的检测。
1) 构建数字内容可信体系
2) 研究高效、准确的深度伪造内容检测技术
3) 制定深度伪造相关的法律法规
原文链接:http://jcs.iie.ac.cn/xxaqxb/ch/reader/view_abstract.aspx?file_no=20200202&flag=1