
前言
Spring 5发布有两年了,随Spring 5一起发布了一个和Spring WebMvc同级的Spring WebFlux。这是一个支持反应式编程模型的新框架体系。反应式模型区别于传统的MVC最大的不同是异步的、事件驱动的、非阻塞的,这使得应用程序的并发性能会大大提高,单位时间能够处理更多的请求。这里不讲WebFlux是怎么用的,有什么用,这类文章网上有太多了,而且都写的非常不错。下面主要看下WebFlux是怎么从无到有,框架怎么设计的,已期能够更灵活的使用WebFlux。
接口抽象
Spring最牛逼的地方就是,无论啥东西,都可以无缝的集成到Spring。这得益于Spring体系优良的抽象封装能力。WebFlux框架也一样,底层实现其实不是Spring的,它依赖reactor和netty等。Spring做的就是通过抽象和封装,把reactor的能力通过你最熟悉不过的Controller来使用。而且不局限于此,除了支持和Spring Mvc一样的控制器编码模式,还支持路由器模式(RouterFunctions),还支持端点模式(EndPoint)等。WebFlux所有功能其实内部只由几个抽象类构建而成:
org.springframework.boot.web.reactive.server.ReactiveWebServerFactory
org.springframework.boot.web.server.WebServer
org.springframework.http.server.reactive.HttpHandler
org.springframework.web.reactive.HandlerMapping
org.springframework.web.server.WebHandler
WebServer
我们从最底层往上层剖析,WebServer见名之意,就是Reacive服务器的抽象类,它定义了服务的基本方法行为,包含启动,停止等接口。结构如下:
public interface WebServer {
void start() throws WebServerException;
void stop() throws WebServerException;
int getPort();
}
Spring默认有五个WebServer的实现,默认的不特别指定情况下,在spring-boot-starter-webflux自带的是Netty的实现,其实现类如下:
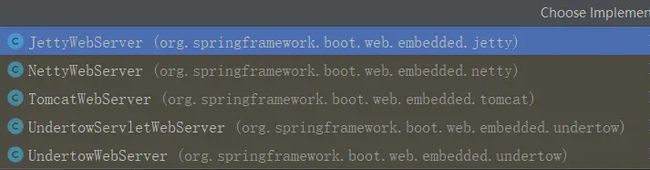
ReactiveWebServerFactory
对应WebServer,每个实现都会有一个工厂类对应,主要准备创建WebServer实例的资源,如NettyReactiveWebServerFactory生产WebServer方法:
public WebServer getWebServer(HttpHandler httpHandler) {
HttpServer httpServer = createHttpServer();
ReactorHttpHandlerAdapter handlerAdapter = new ReactorHttpHandlerAdapter(
httpHandler);
return new NettyWebServer(httpServer, handlerAdapter, this.lifecycleTimeout);
}
可以看到,在创建WebServer实例时,传入了一个入参,HttpHandler。而且进而传入了一个HttpHandlerAdapter实例里,这是因为每个WebServer的接收处理接口的适配器是不一样的,在每个不同的WebServer工厂里通过不过的适配器去适配不同的实现。最后转化成统一设计的HttpHandler里,见下面。
HttpHandler
接下来看下HttpHandler,上面在创建WebServer的时候,传了一个入参,类型就是Httphandler。为了适配不同的WebServer请求响应体,Spring设计了HttpHandler用来转化底层的Http请求响应语义,用来接收处理底层容器的Http请求。其结构如下:
public interface HttpHandler {
Monohandle(ServerHttpRequest request, ServerHttpResponse response);
}
如在Netty的实现中,Netty接收请求处理的适配器ReactorHttpHandlerAdapter的apply中转化的伪代码如下:
public Monoapply(HttpServerRequest reactorRequest, HttpServerResponse reactorResponse) {
NettyDataBufferFactory bufferFactory = new NettyDataBufferFactory(reactorResponse.alloc());
try {
ReactorServerHttpRequest request = new ReactorServerHttpRequest(reactorRequest, bufferFactory);
ServerHttpResponse response = new ReactorServerHttpResponse(reactorResponse, bufferFactory);
if (request.getMethod() == HttpMethod.HEAD) {
response = new HttpHeadResponseDecorator(response);
}
return this.httpHandler.handle(request, response)
.doOnError(ex -> logger.trace(request.getLogPrefix() + "Failed to complete: " + ex.getMessage()))
.doOnSuccess(aVoid -> logger.trace(request.getLogPrefix() + "Handling completed"));
}
}
WebHandler其实一般来讲设计到HttpHandler这一层级基本就差不多了,有一致的请求体和响应体了。但是Spring说还不够,对Web开发来讲不够简洁,就又造了一个WebHandler,WebHandler架构更简单,如下:
public interface WebHandler {
Monohandle(ServerWebExchange exchange);
}
这回够简洁了,只有一个入参,那请求提和响应体去哪里了呢?被包装到ServerWebExchange中了。我么看下当HttpHandler接收到请求后,是怎么处理然后在调用WebHandler的,最终处理HttpHandler实现是HttpWebHandlerAdapter.java,通过其内部的createExchange方法将请求和响应体封装在ServerWebExchange中了。其handle代码如下:
public Monohandle(ServerHttpRequest request, ServerHttpResponse response) {
if (this.forwardedHeaderTransformer != null) {
request = this.forwardedHeaderTransformer.apply(request);
}
ServerWebExchange exchange = createExchange(request, response);
LogFormatUtils.traceDebug(logger, traceOn ->
exchange.getLogPrefix() + formatRequest(exchange.getRequest()) +
(traceOn ? ", headers=" + formatHeaders(exchange.getRequest().getHeaders()) : ""));
return getDelegate().handle(exchange)
.doOnSuccess(aVoid -> logResponse(exchange))
.onErrorResume(ex -> handleUnresolvedError(exchange, ex))
.then(Mono.defer(response::setComplete));
}
HandlerMapping首先看下HandlerMapping的构造,可以看到就是根据web交换器返回了一个Handler对象
public interface HandlerMapping {
String BEST_MATCHING_HANDLER_ATTRIBUTE = HandlerMapping.class.getName() + ".bestMatchingHandler";
String BEST_MATCHING_PATTERN_ATTRIBUTE = HandlerMapping.class.getName() + ".bestMatchingPattern";
String PATH_WITHIN_HANDLER_MAPPING_ATTRIBUTE = HandlerMapping.class.getName() + ".pathWithinHandlerMapping";
String URI_TEMPLATE_VARIABLES_ATTRIBUTE = HandlerMapping.class.getName() + ".uriTemplateVariables";
String MATRIX_VARIABLES_ATTRIBUTE = HandlerMapping.class.getName() + ".matrixVariables";
String PRODUCIBLE_MEDIA_TYPES_ATTRIBUTE = HandlerMapping.class.getName() + ".producibleMediaTypes";
MonogetHandler(ServerWebExchange exchange);
}
上面的“请求“已经到WebHandler了,那么最终是怎么到我们定义的控制器接口的呢?其实,没有HandlerMapping,Spring WebFlux的功能也是完整的,也是可编程的,因为可以基于WebHandler直接编码。我们最弄的一个网关最后就是直接走自定义的WebHandler,根本没有HandlerMapping的什么事情,但是你这么做的话就失去了Spring编码的友好性了。WebFlux的初始化过程中,会去Spring上下文中找name是“webHandler”的的WebHandler实现。默认情况下,Spring会在上下文中初始化一个DispatcherHandler.java的实现,Bean的name就是“webHandler”。这个里面维护了一个HandlerMapping列表,当请求过来时会迭代HandlerMapping列表,返回一个WebHandler处理,代码如下:
public Monohandle(ServerWebExchange exchange) {
if (this.handlerMappings == null) {
return Mono.error(HANDLER_NOT_FOUND_EXCEPTION);
}
return Flux.fromIterable(this.handlerMappings)
.concatMap(mapping -> mapping.getHandler(exchange))
.next()
.switchIfEmpty(Mono.error(HANDLER_NOT_FOUND_EXCEPTION))
.flatMap(handler -> invokeHandler(exchange, handler))
.flatMap(result -> handleResult(exchange, result));
}
上面mapping的内部结构如下:
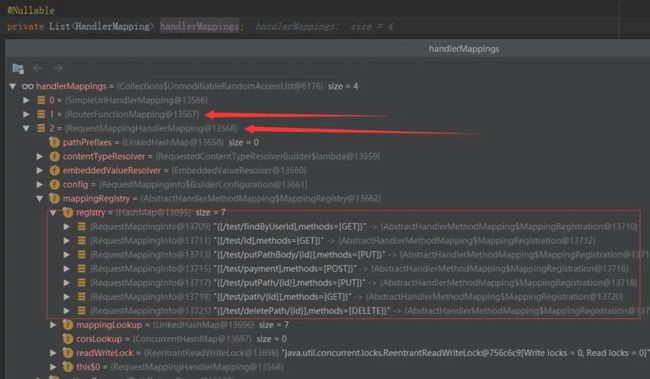
上面箭头指向的地方说明了为什么WebFlux支持控制器和路由器模式模式的编码,因为他们分别有实现的HandlerMapping,能够在WebHandler的handler里路由到具体的业务方法里。红框中正是通过@Controller和@ResultMaping定义的接口信息。
启动流程分析
上面介绍了五个主要的抽象接口定义,以及功能。这五个接口在Spring WebFlux里是灵魂一样的存在。不过想要彻底的搞懂Web Flux的设计以及实现原理,仅仅了解上面这些接口定义是远远不够的,看完上面接口的分析肯定有中模糊的似懂非懂的感觉,不着急,接下来分析下,在Spring Boot环境中,Spring WebFlux的启动流程。
ReactiveWebServerApplicationContext
WebFlux的启动都在Reactive的上下文中完成,和WebMvc类似,Mvc也有一个ServletWebServerApplicationContext,他们是同宗同脉的。
ReactiveWebServerApplicationContext还有一个父类AnnotationConfigReactiveWebServerApplicationContext
在Spring boot启动中,创建的就是这个父类的实例。
在Spring boot的run()方法中创建上下文时有如下代码:
protected ConfigurableApplicationContext createApplicationContext() {
Class contextClass = this.applicationContextClass;
if (contextClass == null) {
try {
switch (this.webApplicationType) {
case SERVLET:
contextClass = Class.forName(DEFAULT_SERVLET_WEB_CONTEXT_CLASS);
break;
case REACTIVE:
contextClass = Class.forName(DEFAULT_REACTIVE_WEB_CONTEXT_CLASS);
break;
default:
contextClass = Class.forName(DEFAULT_CONTEXT_CLASS);
}
}
catch (ClassNotFoundException ex) {
throw new IllegalStateException(
"Unable create a default ApplicationContext, "
+ "please specify an ApplicationContextClass",
ex);
}
}
return (ConfigurableApplicationContext) BeanUtils.instantiateClass(contextClass);
}
可以看到,当webApplicationType是REACTIVE时,加载的就是DEFAULT_REACTIVE_WEB_CONTEXT_CLASS。webApplicationType类型是通过识别你加载了哪个依赖来做的。熟悉Spring启动流程的同学都知道,基础 的Spring上下文是在AbstractApplicationContext的refresh()方法内完成的,针对不同的上下文文实现实例还会有一个onRefresh()方法,完成一些特定的Bean的实例化,如WebFlux的上下文实例就在onRefresh()中完成了WebServer的创建:
protected void onRefresh() {
super.onRefresh();
try {
createWebServer();
}
catch (Throwable ex) {
throw new ApplicationContextException("Unable to start reactive web server",
ex);
}
}
private void createWebServer() {
ServerManager serverManager = this.serverManager;
if (serverManager == null) {
this.serverManager = ServerManager.get(getWebServerFactory());
}
initPropertySources();
}
文末WebFlux里面启动流程太复杂,全盘脱出写的太长严重影响阅读体验。所以上面权当抛砖引玉,开一个好头。不过,WebFlux的启动流程节点博主都已分析并整理成流程图了,结合上面的接口设计分析,搞懂WebFlux的设计及工作原理应该冒点问题
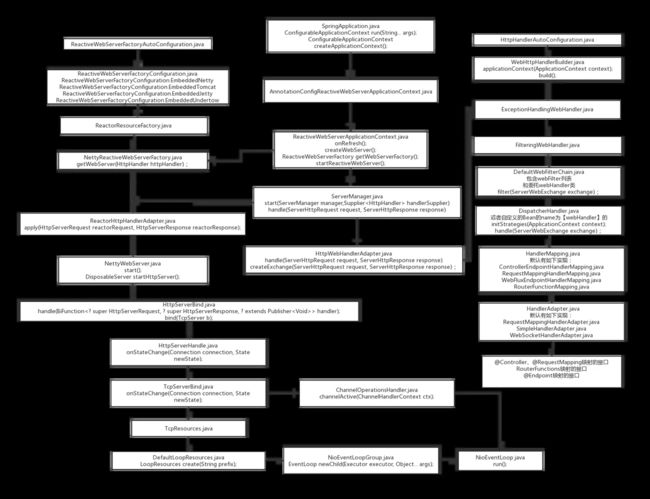
以上就是剖析Spring WebFlux反应式编程模型工作原理的详细内容,更多关于Spring WebFlux反应式编程模型的资料请关注脚本之家其它相关文章!