计算机机器视觉原理之全连接神经网络1
计算机机器视觉原理之全连接神经网络1
-
- 一图像表示
- 二.分类器设置
- 1.多层感知器
- 2.激活函数
- 三.网络结构设计
- 1.用不用隐层,用一个还是用几个隐层?(深度设计)
- 2.每隐层设置多少个神经元比较合适?(宽度设计)
- 四.损失函数
- SOFTMAX操作
- 交叉熵损失
- 对比多雷支撑向量机损失
- 五.优化算法
- 基于计算图
一图像表示
直接利用原始像素作为特征,展开为列向量。
比如:
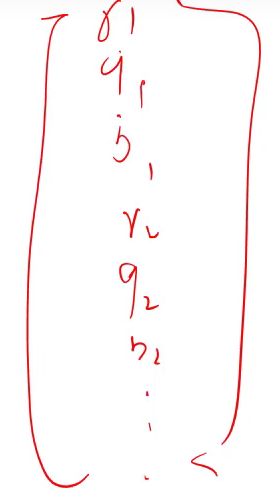
将矩阵转化为列向量再与x点乘,因此
cifar10中每个图像可表示为一个3072(32323)维的向量
二.分类器设置
1.多层感知器
回顾线性分类器:
f(x, W) =wx +b
其中,x代表输入图像,其维度为d ;
f为分数向量,其维度等于类别个数c
W =[W1… wc]T为权值矩阵,wi =[Wi… wid]T为第i个类别的权值向量
b =[b1…be]T为偏置向量,b;为第i个类别的偏置
全连接神经网络级联多个变换来实现输入到输出的映射。
注意:非线性操作是不可以去掉
两层全连接网络
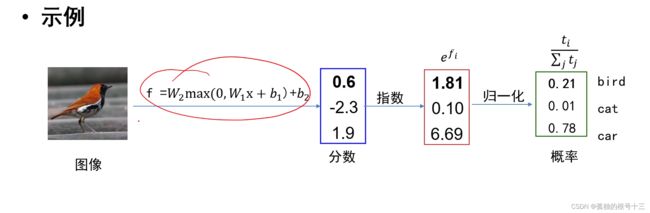
f = W2max(0, W1x + b1)+ b2
max则为激活函数,对变换的结果进行处理
对于两层全连接网络
线性分类器中的W可看作模板,模板个数由类别个数决定
全连接神经网络中:
W1也可看作模板;模板个数人为指定
W2的个数要由类别确定,融合W1的响应结果
w2融合这多个模版的匹配结果来实现最终类别打分

全联接神经网络的描述能力更强。因为调整W1行数等于增加模板个数,分类器有机会学到两个不同方向的马的模板。
线性可分——至少存在一个线性分界面能把两类样本没有错误的分开。
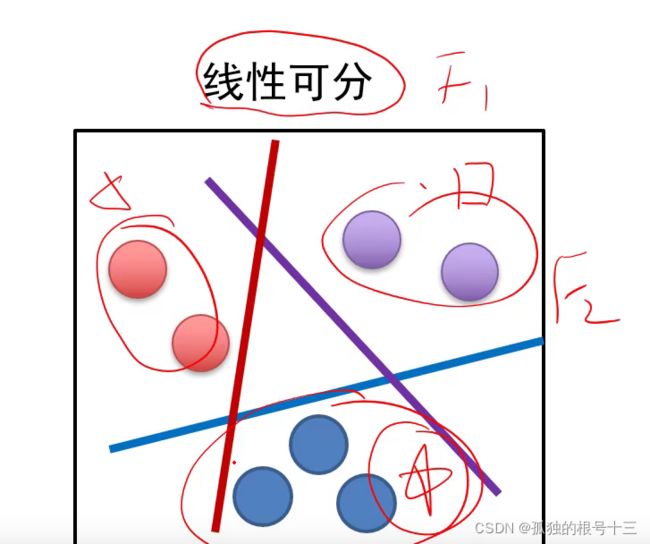
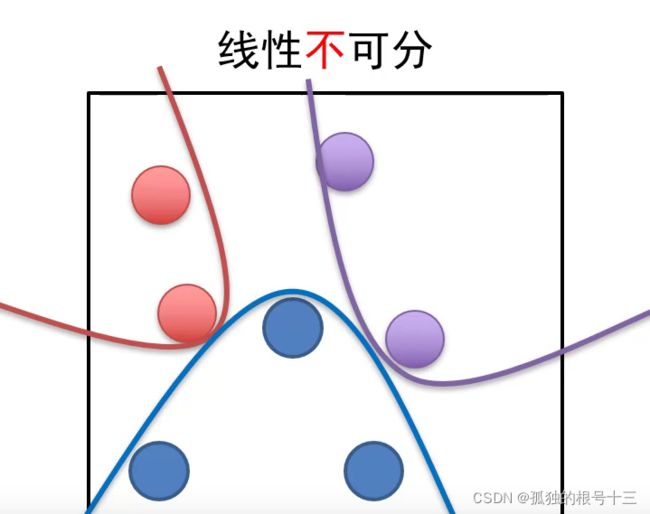
显然不是所有情况都线性可分,这个时候就不适用于线性分类器,使用非线性分类器
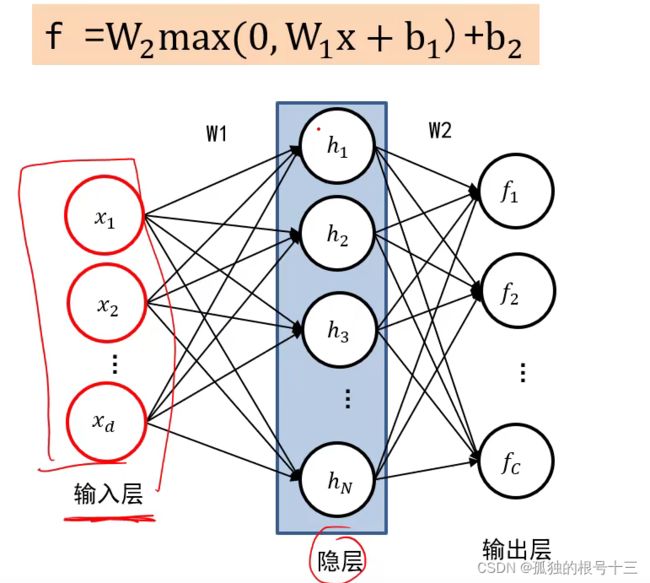
输入层为3072维,即3072个神经元
隐层数是由我们决定W1的模板的个数
输出层是固定的,为类别的数量
一个隐层的神经元要和千层所有的神经元链接,中间的线就是权值,所有线组合起来就是W1,和输出曾链接起来就是W2
N层全连接神经网络——除输入 层之外其他层的数量为N的网络
N个隐层的全连接神经网络— 网络隐层的数量为N的网络
2.激活函数
为什么需要非线性操作?
去激活函数:
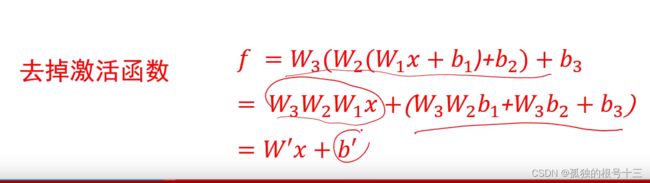
这样之后,结果还是一种线性操作,不能去掉max
答:如果网络中缺少了激活函数,全连接神经网络将变成一个线性分类器
常用的激活函数
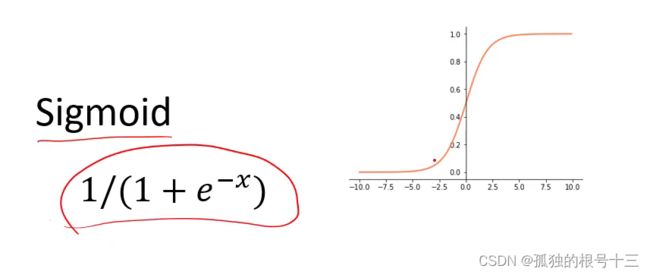
将数组数据变成0到1,大的变为1,小的变为0,中间的数值单调递增,输出的值都大于0且不对称。

将数据压缩至负一到正一,且对称,tanh比Sigmoid函数优秀在tanh不会将所有的数据都压缩至0到1之间,这样在下一层中仍然会有负数存在,更准确。
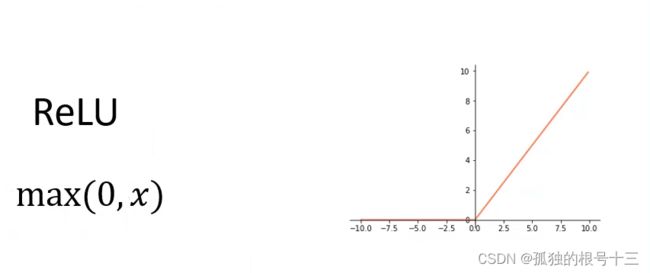
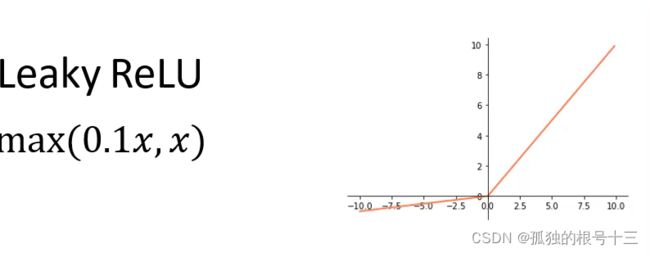
小于0将数据缩小10倍,大于0不变。
三.网络结构设计
1.用不用隐层,用一个还是用几个隐层?(深度设计)
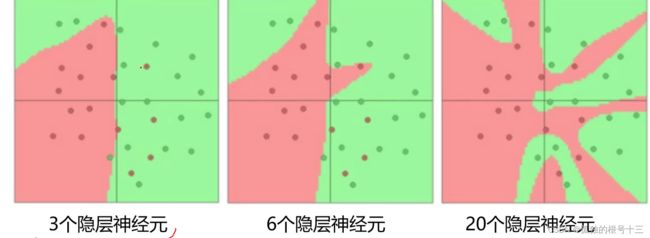
结论:神经元个数越多,分界面就可以越复杂,在这个集合上的分类能力就越强。
也就是说划分出来的边就越多越复杂,但是性能好不好不一定好,很可能出现过拟合的情况。
依据分类任务的难易程度来调整神经网络模型的复杂程度。分类任务越难,我们设计的神经网络结构就应该越深、越宽。但是,需要注意的是对训练集分类精度最高的全连接神经网络模型,在真实场景下识别性能未必是最好的(过拟合)
2.每隐层设置多少个神经元比较合适?(宽度设计)
全连接神经网络组成:一个输入层、一个输出层及多个隐层;
输入层与输出层的神经元个数由任务决定,而隐层数量以及每个隐层的神经元个数需要人为指定;
激活函数是全连接神经网络中的一个重要部分,缺少了激活函数全连接神经网络将退化为线性分类器。
四.损失函数
SOFTMAX操作
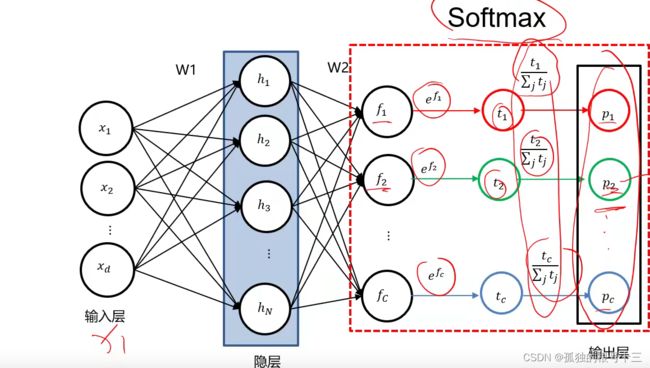
原理是将分到的分数f取指数之后在归一化,这样得到的p为一个概率,最大概率的就倍识别成哪一类,所有p相加等于1。
问题:为什么不直接用f分数归一化
答:因为这个f分数大小正负是不确定的,如果出现负数就不能归一化,取个指数让所有数都大于0 后即可归一化。
交叉熵损失
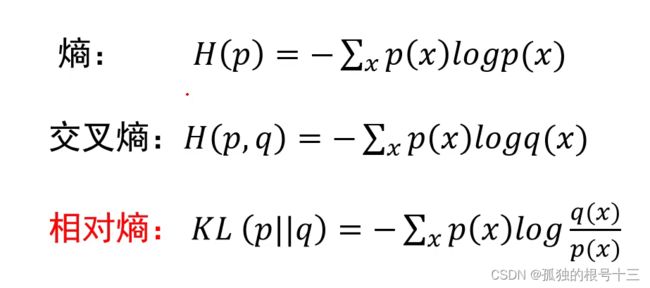
熵:是反映信息量的,如果一件事情信息量越大,那么值也就越大,反之没有信息量就越小
假如一件事的概率分布为u【1;0;0】
根据熵的定义式,1×log1+0+0等于0,也就是说没有信息量,当分布为【1/3;1/3;1/3】为熵最大的时候
交叉熵:这个pq两个分布之间的关系
相对嫡(relative entropy)也叫KL散度 (KL divergence);用来度量两个分布之
间的不相似性(dissimilarity) 。

如何度量现在的分类器输出与预测值之间的距离?
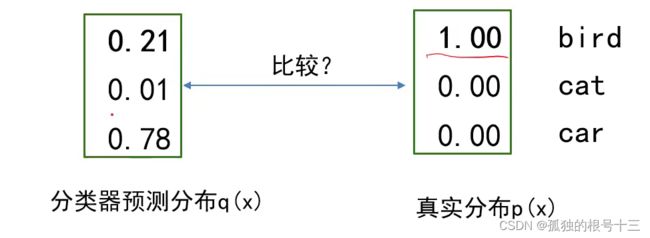

因此交叉熵可以简化为:
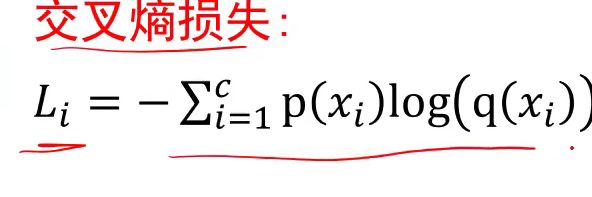
对比多雷支撑向量机损失
还是这个实例
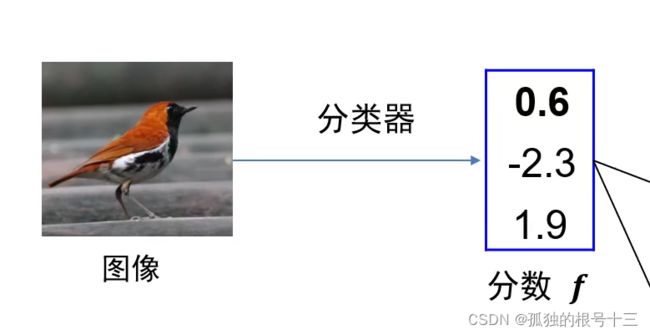
对于多类向量机损失算法为预测分数减正确分数+1和0取最大值,这里最终损失为2.3
对于交叉熵损失:
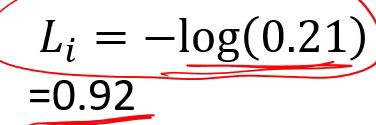
当我们使用交叉熵损失的时候,预测概率分布为【0.334,0.333,0.333】和【0.333,0.333,0.334】的时候,我们会发现损失值是差不多的,但是精确度确实有大的变化,第一组预测成功,而第二个预测失败,因此我们在使用交叉熵损失时,调整的时候会发现损失值不变的情况下可以提高准确度。
五.优化算法
基于计算图
计算图是一种有向图,它用来表达输入、输出以及中间变量之间的计算关系,图中的每个节点对应着一种数学运算。
前向:
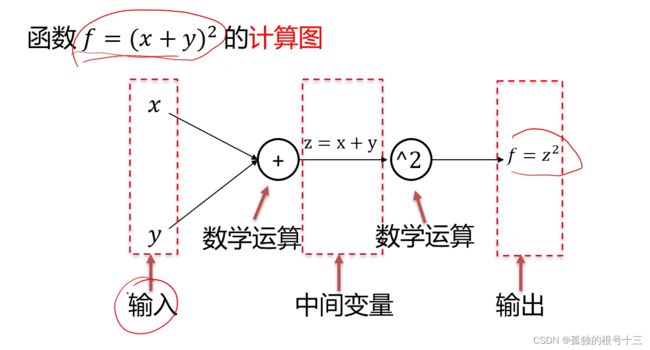
反向:

反向传播原理解释
任意复杂的函数,都可以用计算图的形式表示在整个计算图中,每个门单元都会得到一些输入, 然后,进行下面两个计算:
a)这个门的输出值
b)其输出值关于输入值的局部梯度。
利用链式法则,门单元应该将回传的梯度乘以它对其的输入的局部梯度,从而得到整个网络的输出对该门单元的每个输入值的梯度。
常见门单元:
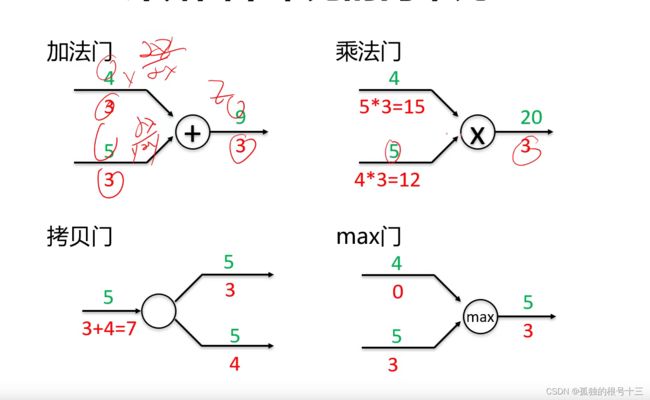
应用:计算图主要是帮助我们计算梯度的,在更新当前的权值时,需要此权值的梯度,在乘以学习率,在前面填一个负号,跟上一轮权值相加,就成功更新权值。
链式法则的缺陷:如果计算图一路都是乘法,中间有些门的数值梯度都比较小的话,这样梯度就会越来越小造成梯度消失。