Hu不变矩+BP神经网络,实现对图像的分类(pytorch实现)
文章目录
- 1.网络模型
- 2.数据集制作
- 3.模型训练、保存、加载和使用
1.网络模型
方案,如图所示。
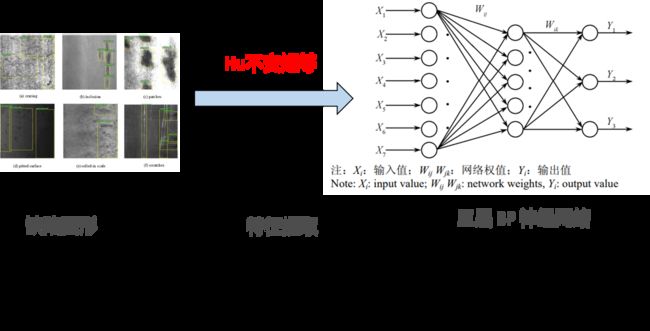
先对图片,用hu矩进行特征提取,每个图片产生7个特征值。这7个特征值作为数据,再加上一个标签值。然后送入BP神经网络中,进行模型的训练。模型训练好后,就可以使用模型,对一个新的图片,进行分类识别了。
2.数据集制作
图片数据集是NEU surface defect database,东北大学热轧带钢表面缺陷数据集,该数据集是东北大学的宋克臣等老师收集的。
数据集收集了夹杂( inclusion )、划痕( scratches )、压入氧化皮( rolled-inscale )、裂纹( cracks )、麻点( pitted )和斑块( patches )6种缺陷,每种缺陷300张,图像尺寸为200×200。

我们选取了裂纹( cracks )、夹杂( inclusion )和麻点( pitted )三类缺陷各100副图像,制作数据集。使用Hu不变矩进行特征提取后,就有了300个样本的特征。240个作为训练集,60个作为验证集。
其中,裂纹类图片的标签,记为0,夹杂类图片的标签,记为1,麻点类图片的标签,记为2。(后面会进行one-hot操作,因此记为数字几并不重要,注意对应关系即可)
然后使用Hu矩对这300幅图片,继续特征提取,得到hu值。就制作成了数据集。(但该数据集并不好,因为只含有缺陷图像,不含无缺陷的图像。也就是数据集中只有正例,没有反例。当训练好模型后,在测试模型时,用一个无缺陷图片,则模型会把它分类成三类缺陷中概率最大的那一类。)
#Hu不变矩代码 python+opencv
def Hu_moments(img):
'''
opencv_python自带求矩以及不变矩的函数
:param img: 灰度图像,对于二值图像来说就只有两个灰度0和255
:return: 返回以10为底对数化后的hu不变矩
'''
moments = cv2.moments(img) # 返回的是一个字典,三阶及以下的几何矩(mpq)、中心矩(mupq)和归一化的矩(nupq)
humoments = cv2.HuMoments(moments) # 根据几何矩(mpq)、中心矩(mupq)和归一化的矩(nupq)计算出hu不变矩
# 因为直接计算出来的矩可能很小或者很大,因此取对数好比较,这里的对数底数为e,通过对数除法的性质将其转换为以10为底的对数
humoment = (np.log(np.abs(humoments))) / np.log(10)
humoment = np.reshape(humoment,(1,7))[0]
return humoment
if __name__ == '__main__':
img = cv2.imread('3.png', 0) #读入图片
#对于300幅图片求hu值的操作,笔者建议读者写代码,依次读入文件下的所有图片,求hu值,并把值写入hu.csv文件中
sys_humoments = hu_moments(img)
print('Hu不变矩为:\n', sys_humoments)
另外,观察这7个hu值的数据,发现有些数据数量差别有些大,量大的可能对结果有更大的影响,因此,可以对数据先做归一化处理,消除数值本身量度大小对模型的影响。(笔者并未做归一化处理,建议读者可以做一下,而且建议使用Z-score标准化方法,因其适合分类问题。)
3.模型训练、保存、加载和使用
a.这里专门定义了一个数据处理类DealDataset,用来把自己的数据加载,处理成DataLoader类需要的格式。
b.因为使用了交叉熵损失函数(Cross Entropy),包含了激活和one-hot操作做,所以模型的最后输出不做激活,不做one-hot.
c.模型的保存和加载使用
torch.save(model, 'BPnet.pt') #保存训练好的模型
model_dict=torch.load('BPnet.pt')#加载训练好的模型
'''
用一个数据,测试模型,看其分类结果
'''
array = [-2.98191252,-9.420647126,-12.1779162,-12.69555161,-25.77957309,-17.64040682,-25.14359491]
# list 转 numpy
#np.array(array)
# numpy转化为tensor :b = torch.from_numpy(a) b=torch.Tensor(a) #
test = torch.Tensor(array)
print(test)
pre = model_dict(test)
print(pre)
out = pre.argmax(dim=1) # 取出预测的最大值的索引,从0开始,所以0是第一类
print(out)
m = int(out)
print(m) #输出哪一类对应的类别标签(0,1,2)
全部代码(bp网络由pytorch框架构建)
import numpy as np
import torch
from torch import nn
from torch.autograd import Variable
import torch.optim as optim
import torch.nn.functional as F
import pandas as pd
import matplotlib.pyplot as plt
import random
from torch.utils.data import Dataset, DataLoader # 该接口主要用来将自定义的数据读取接口的输出或者PyTorch已有的数据读取接口的输入按照batch size封装成Tensor
from torch.utils.data import random_split
# Step 1:============================准备数据===================
class DealDataset(Dataset):
"""
加载数据、把数据转化为DataLoader类需要的格式,都可以在这里完成
"""
def __init__(self):
xy = np.loadtxt('./hu.csv', delimiter=',', dtype=np.float32) # 使用numpy读取数据
self.x_data = torch.from_numpy(xy[:, 0:-1])
self.y_data = torch.from_numpy(xy[:, -1]).long()
self.len = xy.shape[0]
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
# https: // blog.csdn.net / zw__chen / article / details / 82806900
# Step 2:============================定义模型===================
# 定义一个类,继承自 torch.nn.Module,torch.nn.Module是callable的类
# 在整个类里面重新定义一个标准的BP全连接神经网络,网络一共是三层(算上输入层)
# 其中输入层7个节点,输出层是3个节点,隐藏层是5个节点。
# 我们使用了Relu的激活函数,而不是sigmoid激活函数
# 整个子类需要重写forward函数,
data = DealDataset()
# 输入层4个节点,隐藏层7个,输出层3个(100,010,001三类)
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.linear1 = torch.nn.Linear(7,5)
self.linear2 = torch.nn.Linear(5,3)
def forward(self,x):
x = x.view(-1,7) # 改变张量形状。把输入展开成若干行,7列
x = F.leaky_relu(self.linear1(x))
return self.linear2(x) #最后一层不做激活,因为下一步输入到交叉损失函数中,交叉熵包含了激活层
# 创建和实例化一个整个模型类的对象
model = Net()
# 原文链接:https://blog.csdn.net/t18438605018/article/details/122137737
# 打印出整个模型
#print(model)
# Step 3:============================定义损失函数和优化器===================
# 定义 loss 函数,这里用的是交叉熵损失函数(Cross Entropy),包含了激活层和one-hot操作做,所以模型的最后输出不做激活,不做one-hot.
# 我们优先使用随机梯度下降,lr是学习率: 0.1
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01) #, momentum= 0.5
train_set, test_set = random_split(data,lengths=[240, 60]) #300个样本,按8:2划分训练集和验证集
train_data = DataLoader(train_set, batch_size=4, shuffle=False) # 训练数据
test_data = DataLoader(test_set, batch_size=4, shuffle=False) # 测试数据
# Step 4:============================开始训练网络===================
# 为了实时观测效果,我们每一次迭代完数据后都会,用模型在测试数据上跑一次,看看此时迭代中模型的效果。
# 用数组保存每一轮迭代中,训练的损失值和精确度,也是为了通过画图展示出来。
train_losses = []
train_acces = []
# 用数组保存每一轮迭代中,在测试数据上测试的损失值和精确度,也是为了通过画图展示出来。
eval_losses = []
eval_acces = []
for e in range(100):
# 4.1==========================训练模式==========================
train_loss = 0
train_acc = 0
model.train() # 将模型改为训练模式
# 每次迭代都是处理一个小批量的数据,batch_size是64
for im, label in train_data:
im = Variable(im)
label = Variable(label)
# 计算前向传播,并且得到损失函数的值
out = model(im)
loss = criterion(out, label)
# 反向传播,记得要把上一次的梯度清0,反向传播,并且step更新相应的参数。
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录误差
train_loss += loss.item()
# 计算分类的准确率
out_t = out.argmax(dim=1) #取出预测的最大值的下标索引,从0开始
num_correct = (out_t == label).sum().item()
acc = num_correct / im.shape[0]
train_acc += acc
train_losses.append(train_loss / len(train_data))
train_acces.append(train_acc / len(train_data))
# 4.2==========================每次进行完一个训练迭代,就去测试一把看看此时的效果==========================
# 在测试集上检验效果
eval_loss = 0
eval_acc = 0
model.eval() # 将模型改为预测模式
# 每次迭代都是处理一个小批量的数据,batch_size是128
for im, label in test_data:
im = Variable(im) # torch中训练需要将其封装即Variable,此处封装像素即784
label = Variable(label) # 此处为标签
out = model(im) # 经网络输出的结果
loss = criterion(out, label) # 得到误差
# 记录误差
eval_loss += loss.item()
# 记录准确率
out_t = out.argmax(dim=1) # 取出预测的最大值的索引
num_correct = (out_t == label).sum().item() # 判断是否预测正确
acc = num_correct / im.shape[0] # 计算准确率
eval_acc += acc
eval_losses.append(eval_loss / len(test_data))
eval_acces.append(eval_acc / len(test_data))
print('epoch: {}, Train Loss: {:.6f}, Train Acc: {:.6f}, Eval Loss: {:.6f}, Eval Acc: {:.6f}'
.format(e, train_loss / len(train_data), train_acc / len(train_data),
eval_loss / len(test_data), eval_acc / len(test_data)))
torch.save(model, 'BPnet.pt')
model_dict=torch.load('BPnet.pt')
array = [-2.98191252,-9.420647126,-12.1779162,-12.69555161,-25.77957309,-17.64040682,-25.14359491]
# list 转 numpy
#np.array(array)
# numpy转化为tensor :b = torch.from_numpy(a) b=torch.Tensor(a) #
test = torch.Tensor(array)
print(test)
pre = model_dict(test)
print(pre)
out = pre.argmax(dim=1) # 取出预测的最大值的索引,从0开始,所以0是第一类
print(out)
m = int(out)
print(m) #输出哪一类对应的类别标签(0,1,2)
plt.title('train loss')
plt.plot(np.arange(len(train_losses)), train_losses)
plt.plot(np.arange(len(train_acces)), train_acces)
plt.title('train acc')
plt.plot(np.arange(len(eval_losses)), eval_losses)
plt.title('test loss')
plt.plot(np.arange(len(eval_acces)), eval_acces)
plt.title('test acc')
plt.show()
如果读者需要hu.csv文件和代码,可评论区留言留下邮箱!
感谢大家支持,给笔者一个关注吧!
如果读者希望使用TensorFlow框架,可参考笔者上篇博客:
特征提取+BP神经网络,实现对图像的分类