深度学习 | 交叉熵损失函数
文章目录
- Cross Entropy Error Function
-
- 一,信息量
- 二,熵
- 三,相对熵(KL散度)
- 四,交叉熵
- 五,交叉熵损失函数
- 参考
Cross Entropy Error Function
交叉熵损失函数
一,信息量
信息量:
任何事件都会承载着一定的信息量,包括已经发生的事件和未发生的事件,只是它们承载的信息量会有所不同。如昨天下雨这个已知事件,因为已经发生,是既定事实,那么它的信息量就为0。如明天会下雨这个事件,因为未有发生,那么这个事件的信息量就大。
从上面例子可以看出信息量是一个与事件发生概率相关的概念,而且可以得出,事件发生的概率越小,其信息量越大。
假设 x x x是一个离散型随机变量,其取值集合为 X X X,概率分布函数为 p ( x ) p(x) p(x),则定义事件 x = x 0 x=x_0 x=x0的信息量为: I ( x 0 ) = − log ( p ( x 0 ) ) I(x_0)=-\log(p(x_0)) I(x0)=−log(p(x0))
二,熵
**熵是表示随机变量不确定的度量,是对所有可能发生的事件产生的信息量的期望。**熵值越大,表明这个系统的不确定性就越大。公式如下:
H ( X ) = − ∑ i = 1 n p ( x i ) log ( p ( x i ) ) H(X)=-\sum_{i=1}^n p(x_i)\log(p(x_i)) H(X)=−i=1∑np(xi)log(p(xi))
对于0-1分布问题,熵的计算方法可以简化为:
H ( x ) = − ∑ i = 1 n p ( x i ) l o g ( p ( x i ) ) = − p ( x ) log ( p ( x ) ) − ( 1 − p ( x ) ) log ( 1 − p ( x ) ) H(x)=-\sum_{i=1}^np(x_i)log(p(x_i))\\=-p(x)\log(p(x))-(1-p(x))\log(1-p(x)) H(x)=−i=1∑np(xi)log(p(xi))=−p(x)log(p(x))−(1−p(x))log(1−p(x))
三,相对熵(KL散度)
相对熵又称KL散度,用于衡量对于同一个随机变量x的两个分布p(x)和q(x)之间的差异。在机器学习中,p(x)常用于描述样本的真实分布,例如[1,0,0,0]表示样本属于第一类,而q(x)则常常用于表示预测的分布,例如[0.7,0.1,0.1,0.1]。显然使用q(x)来描述样本不如p(x)准确,q(x)需要不断地学习来拟合准确的分布p(x)。
KL散度的公式如下:
D K L ( p ∣ ∣ q ) = ∑ i = 1 n p ( x i ) log ( p ( x i ) q ( x i ) ) D_{KL}(p||q)=\sum_{i=1}^np(x_i)\log(\frac{p(x_i)}{q(x_i)}) DKL(p∣∣q)=i=1∑np(xi)log(q(xi)p(xi))
KL散度的值越小,表示两个分布越接近。在机器学习中,p往往用来表示样本的真实分布,q用来表示模型所预测的分布,那么KL散度就可以计算两个分布的差异,也就是Loss损失值。
四,交叉熵
将KL散度的公式进行变形,得到:
D K L ( p ∣ ∣ q ) = ∑ i = 1 n p ( x i ) log ( p ( x i ) q ( x i ) ) = ∑ i = 1 n p ( x i ) log ( p ( x i ) ) − ∑ i = 1 n p ( x i ) log ( q ( x i ) ) D_{KL}(p||q)=\sum_{i=1}^np(x_i)\log(\frac{p(x_i)}{q(x_i)})\\=\sum_{i=1}^np(x_i)\log(p(x_i))-\sum_{i=1}^np(x_i)\log(q(x_i)) DKL(p∣∣q)=i=1∑np(xi)log(q(xi)p(xi))=i=1∑np(xi)log(p(xi))−i=1∑np(xi)log(q(xi))
根据熵的定义,前半部分是 p ( x ) p(x) p(x)的熵 H ( x ) = − ∑ i = 1 n p ( x i ) log ( p ( x i ) ) H(x)=-\sum_{i=1}^np(x_i)\log(p(x_i)) H(x)=−∑i=1np(xi)log(p(xi)),而后半部分则是交叉熵,定义为:
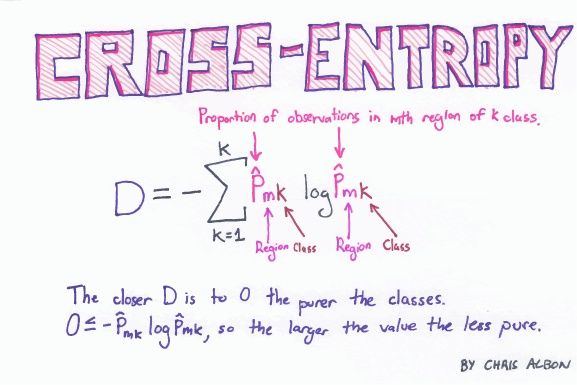
H ( p , q ) = − ∑ i = 1 n p ( x i ) log ( q ( x i ) ) H(p,q)=-\sum_{i=1}^np(x_i)\log(q(x_i)) H(p,q)=−i=1∑np(xi)log(q(xi))
因此 D K L ( p ∣ ∣ q ) = H ( p , q ) − H ( p ) D_{KL}(p||q)=H(p,q)-H(p) DKL(p∣∣q)=H(p,q)−H(p),在机器学习中,我们需要评估label和predicts之间的差距,使用KL散度刚刚好,即 D K L ( p ∣ ∣ q ~ ) D_{KL}(p||\widetilde{q}) DKL(p∣∣q ),由于KL散度中的前一部分 − H ( p ) −H(p) −H(p)不变,故在优化过程中,只需要关注交叉熵就可以了。
五,交叉熵损失函数
在线性回归问题中,常常使用MSE(Mean Squared Error)作为loss函数,而在分类问题中常常使用交叉熵作为loss函数,特别是在神经网络作分类问题时,并且由于交叉熵涉及到计算每个类别的概率,所以交叉熵几乎每次都和sigmoid或者softmax函数一起出现。
(1)二分类
在二分的情况下,对于每个类别我们的预测的到的概率为p和1-p。此时表达式为:
L = 1 N ∑ i L i = 1 N ∑ i ( − [ y i log ( p i ) + ( 1 − y i ) log ( 1 − p i ) ] ) L=\frac{1}{N}\sum_iL_i=\frac{1}{N}\sum_i(-[y_i\log(p_i)+(1-y_i)\log(1-p_i)]) L=N1i∑Li=N1i∑(−[yilog(pi)+(1−yi)log(1−pi)])
其中:
- y i y_i yi表示样本i的label,正类为1,负类为0
- p i p_i pi表示样本i预测为正的概率
(2)多分类
多分类问题实际上就是对二分类问题的扩展:
L = 1 N ∑ i L i = 1 N ∑ i ( − ∑ j = 1 M y i j log ( p i j ) ) L=\frac{1}{N}\sum_iL_i=\frac{1}{N}\sum_i(-\sum_{j=1}^My_{ij}\log(p_{ij})) L=N1i∑Li=N1i∑(−j=1∑Myijlog(pij))
其中:
- M 表示类别的数量
- y i j y_{ij} yij表示该类别和样本i类别是否相同,相同为1,不同为0
- p i j p_{ij} pij表示对于观测样本i属于类别j的预测概率
例如:
| id | predict | label | isCorrect |
|---|---|---|---|
| 1 | 0.3 0.3 0.4 | 0 0 1 | 1 |
| 2 | 0.3 0.4 0.3 | 0 1 0 | 1 |
| 3 | 0.1 0.2 0.7 | 1 0 0 | 0 |
那么求其Loss:
L 1 = − ( 0 × log 0.3 + 0 × log 0.3 + 1 × log 0.4 ) L_1=-(0\times \log 0.3+0\times \log 0.3+1\times \log 0.4) L1=−(0×log0.3+0×log0.3+1×log0.4)
L 2 = − ( 0 × log 0.3 + 1 × log 0.4 + 0 × log 0.3 ) L_2=-(0\times \log 0.3+1\times \log 0.4+0\times \log 0.3) L2=−(0×log0.3+1×log0.4+0×log0.3)
L 3 = − ( 1 × log 0.1 + 0 × log 0.2 + 0 × log 0.7 ) L_3=-(1\times \log 0.1+0\times \log 0.2+0\times \log 0.7) L3=−(1×log0.1+0×log0.2+0×log0.7)
对所有样本的Loss求平均
L o s s = L 1 + L 2 + L 3 3 Loss=\frac{L_1+L_2+L_3}{3} Loss=3L1+L2+L3
参考
https://zhuanlan.zhihu.com/p/74075915
https://zhuanlan.zhihu.com/p/61944055
https://zhuanlan.zhihu.com/p/35709485
https://blog.csdn.net/b1055077005/article/details/100152102