数据分析(七)之pandas学习【dataFrame的使用】
数据分析学习线路图

2、dataFrame的基本用法
2.1 dataFrame的创建

方法2:
import numpy as np
import pandas as pd
t = pd.DataFrame(np.arange(12).reshape((3, 4)), index=list("ABC"), columns=list("WXYZ"))
print(t)
输出:
W X Y Z
A 0 1 2 3
B 4 5 6 7
C 8 9 10 11
那么问题来了:
-
DataFrame和Series有什么关系呢?
-
Series能够传入字典,那么DataFrame能够传入字典作为数据么?那么mongodb的数据是不是也可以这样传入呢?
-
对于一个dataframe类型,既有行索引,又有列索引,我们能够对他做什么操作呢?
import numpy as np
import pandas as pd
d1 = dict(name=["xiaoming", "xiaohong"], age=[20, 32], tel=[10086, 10010])
print(pd.DataFrame(d1))
d2 = [{"name": "张三", "age": 45, "phone": "110"}, {"name": "李四", "phone": "10086"},
{"name": "小光", "age": 18}]
print(pd.DataFrame(d2))
输出:
name age tel
0 xiaoming 20 10086
1 xiaohong 32 10010
name age phone
0 张三 45.0 110
1 李四 NaN 10086
2 小光 18.0 NaN
DataFrame读取豆瓣数据集【数据集下载看数据分析六】
from pymongo import MongoClient
import numpy as np
import pandas as pd
client = MongoClient()
collection = client["douban"]["tv1"]
data = list(collection.find())
print(pd.DataFrame(data))
输出:
id ... total
0 59ba7f9b421aa91b08a43faa ... 2123
1 59ba7f9b421aa91b08a43fab ... 2123
2 59ba7f9b421aa91b08a43fac ... 2123
... ... ... ...
2377 59ba8022421aa91b08a448f3 ... 1454
2378 59ba8022421aa91b08a448f4 ... 1454
[2379 rows x 26 columns]
继续优化,去除不要的豆瓣信息:注意上面打印的为2779x26条数据
# coding=utf-8
from pymongo import MongoClient
import pandas as pd
client = MongoClient()
collection = client["douban"]["tv1"]
data = collection.find()
data_list = []
for i in data:
temp = {}
temp["info"] = i["info"]
temp["rating_count"] = i["rating"]["count"]
temp["rating_value"] = i["rating"]["value"]
temp["title"] = i["title"]
temp["country"] = i["tv_category"]
temp["directors"] = i["directors"]
temp["actors"] = i['actors']
data_list.append(temp)
df = pd.DataFrame(data_list)
print(df)
打印输出:
info ... actors
0 王伟/潘粤明/王泷正/梁缘/剧情/犯罪/悬疑/2017-08-30(中国大陆) ... [潘粤明, 王泷正, 梁缘]
1 丁黑/孙俪/陈晓/何润东/剧情/古装/2017-08-30(中国大陆) ... [孙俪, 陈晓, 何润东]
2 吕行/秦昊/邓家佳/姚橹/犯罪/悬疑/2017-09-06(中国大陆) ... [秦昊, 邓家佳, 姚橹]
... ... ... ...
2377 重光亨彦/津川雅彦/西田敏行/岩下志麻/历史/战争/2000-01-09(日本) ... [津川雅彦, 西田敏 行, 岩下志麻]
2378 永山耕三/芦田爱菜/夏洛特·凯特·福克斯/山本耕史/2016-04-17(日本) ... [芦田爱菜, 夏洛特·凯特·福克斯, 山本耕史]
[2379 rows x 7 columns]
2.2 DataFrame的基础属性和方法

# coding=utf-8
from pymongo import MongoClient
import pandas as pd
client = MongoClient()
collection = client["douban"]["tv1"]
data = collection.find()
data_list = []
for i in data:
temp = {}
temp["info"] = i["info"]
temp["rating_count"] = i["rating"]["count"]
temp["rating_value"] = i["rating"]["value"]
temp["title"] = i["title"]
temp["country"] = i["tv_category"]
temp["directors"] = i["directors"]
temp["actors"] = i['actors']
data_list.append(temp)
df = pd.DataFrame(data_list)
# print(df)
# 显示头几行
print(df.head(1))
print("*"*100)
print(df.tail(2))
# 展示df的概览
print(df.info())
print(df.describe())
输出:
info ... actors
0 王伟/潘粤明/王泷正/梁缘/剧情/犯罪/悬疑/2017-08-30(中国大陆) ... [潘粤明, 王泷正, 梁缘]
[1 rows x 7 columns]
****************************************************************************************************
info ... actors
2377 重光亨彦/津川雅彦/西田敏行/岩下志麻/历史/战争/2000-01-09(日本) ... [津川雅彦, 西田敏行, 岩下志麻]
2378 永山耕三/芦田爱菜/夏洛特·凯特·福克斯/山本耕史/2016-04-17(日本) ... [芦田爱菜, 夏洛特·凯特·福克斯, 山本耕史]
[2 rows x 7 columns]
RangeIndex: 2379 entries, 0 to 2378
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 info 2379 non-null object
1 rating_count 2379 non-null int64
2 rating_value 2379 non-null float64
3 title 2379 non-null object
4 country 2379 non-null object
5 directors 2379 non-null object
6 actors 2379 non-null object
dtypes: float64(1), int64(1), object(5)
memory usage: 130.2+ KB
None
rating_count rating_value
count 2379.000000 2379.000000
mean 9079.419084 7.722783
std 16613.297194 1.068567
min 211.000000 2.800000
25% 807.000000 7.100000
50% 2573.000000 7.800000
75% 9256.000000 8.500000
max 170243.000000 9.800000
动手练习
回到之前我们读取的狗名字统计的数据上,我们尝试一下刚刚的方法
- 那么问题来了:
很多同学肯定想知道使用次数最高的前几个名字是什么呢?
df.sort_values(by=“Count_AnimalName”,ascending=False) - 那么问题又来了:
如果我的数据有10列,我想按照其中的第1,第3,第8列排序,怎么办?(看ipythpn的帮助文档)
# coding=utf-8
import pandas as pd
df = pd.read_csv("./dogNames2.csv")
# print(df.head())
# print(df.info())
# dataFrame中按照某一列进行排序的方法
df = df.sort_values(by="Count_AnimalName", ascending=False) # 降序排列
print(df.head(5))
打印输出:
Row_Labels Count_AnimalName
1156 BELLA 1195
9140 MAX 1153
2660 CHARLIE 856
3251 COCO 852
12368 ROCKY 823
2.3 DataFrame的索引

# coding=utf-8
import pandas as pd
df = pd.read_csv("./dogNames2.csv")
# print(df.head())
# print(df.info())
# dataFrame中按照某一列进行排序的方法
df = df.sort_values(by="Count_AnimalName", ascending=False) # 降序排列
# print(df.head(5))
# pandas取行或者列的注意点
# - 方括号写数组,表示取行,对行进行操作
# - 写字符串,表示的去列索引,对列进行操作
print(df[:5]) # 表示取前20行
print(df["Row_Labels"]) # 表示取Row_Labels这一列
print(type(df["Row_Labels"]))
打印输出:
Row_Labels Count_AnimalName
1156 BELLA 1195
9140 MAX 1153
2660 CHARLIE 856
3251 COCO 852
12368 ROCKY 823
1156 BELLA
9140 MAX
2660 CHARLIE
3251 COCO
12368 ROCKY
...
6884 J-LO
6888 JOANN
6890 JOAO
6891 JOAQUIN
16219 39743
Name: Row_Labels, Length: 16220, dtype: object
pandas之loc和iloc


2.4 布尔索引和缺失值的处理
回到之前狗的名字的问题上,假如我们想找到所有的使用次数超过800的狗的名字,应该怎么选择?
import pandas as pd
# pandas读取csv中的文件
df = pd.read_csv("./dogNames2.csv")
# print(df[(800 < df["Count_AnimalName"] < 1000)]) # 代码错误! 不应该这么写
print(df[(800 < df["Count_AnimalName"]) & (df["Count_AnimalName"] < 1000)])
打印
Row_Labels Count_AnimalName
2660 CHARLIE 856
3251 COCO 852
12368 ROCKY 823
回到之前狗的名字的问题上,假如我们想找到所有的使用次数超过700并且名字的字符串的长度大于4的狗的名字,应该怎么选择?
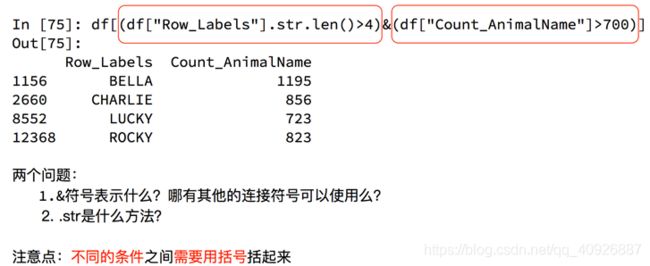
pandas的字符串处理方法

使用split分割豆瓣数据集
# coding=utf-8
from pymongo import MongoClient
import pandas as pd
client = MongoClient()
collection = client["douban"]["tv1"]
data = collection.find()
data_list = []
for i in data:
temp = {}
temp["info"] = i["info"]
temp["rating_count"] = i["rating"]["count"]
temp["rating_value"] = i["rating"]["value"]
temp["title"] = i["title"]
temp["country"] = i["tv_category"]
temp["directors"] = i["directors"]
temp["actors"] = i['actors']
data_list.append(temp)
df = pd.DataFrame(data_list)
print(df["info"].str.split("/"))
print("*" * 100)
print(df["info"].str.split("/").tolist())
打印输出:
0 [王伟, 潘粤明, 王泷正, 梁缘, 剧情, 犯罪, 悬疑, 2017-08-30(中国大陆)]
1 [丁黑, 孙俪, 陈晓, 何润东, 剧情, 古装, 2017-08-30(中国大陆)]
2 [吕行, 秦昊, 邓家佳, 姚橹, 犯罪, 悬疑, 2017-09-06(中国大陆)]
3 [田里, 李现, 张铭恩, 王紫璇, 剧情, 悬疑, 2017-07-19(中国大陆)]
4 [游达志, 韩东君, 陈瑶, 李兰迪, 悬疑, 奇幻, 2017-08-14(中国大陆)]
...
2374 [三宅喜重, 草剪刚, 大岛优子, 木村文乃, 剧情, 2015-01-06(日本)]
2375 [西谷弘, 木村拓哉, 筱原凉子, 松田翔太, 剧情, 2010-05-10(日本)]
2376 [岩本仁志, 佐藤隆太, 稻森泉, 北乃绮, 2012-04-18]
2377 [重光亨彦, 津川雅彦, 西田敏行, 岩下志麻, 历史, 战争, 2000-01-09(日本)]
2378 [永山耕三, 芦田爱菜, 夏洛特·凯特·福克斯, 山本耕史, 2016-04-17(日本)]
Name: info, Length: 2379, dtype: object
****************************************************************************************************
tolist因为数据过多不再展示
Process finished with exit code 0
缺失值的处理

import numpy as np
import pandas as pd
t = pd.DataFrame(np.arange(12).reshape((3, 4)), index=list("ABC"), columns=list("WXYZ"))
t.iloc[1:, :2] = np.nan
print(t)
print(pd.isnull(t))
print(pd.notnull(t))
print(t[pd.notnull(t["W"])])
print("*" * 100)
# 删除nan数据
print(t.dropna(axis=0)) # 删除nan的行或者列、 axis=0:删除nan的行
print(t.dropna(axis=0, how="all")) # 当前行全部为nan才删除该行
print(t.dropna(axis=0, how="any")) # 当前行有nan就删除该行
print(t.dropna(axis=0, how="any", inplace=True)) # inplace=True对当前DataFrame的一个原地修改
print("*" * 100)
# 填充nan数据
d2 = [{"name": "xiaoming", "age": 20, "tel": 10086}, {"name": "xiaohong", "tel": 10010},
{"name": "xiaoguang", "age": 30}]
t2 = pd.DataFrame(d2)
print(t2)
print(t2["age"].fillna(t2["age"].mean()))
打印输出:
W X Y Z
A 0.0 1.0 2 3
B NaN NaN 6 7
C NaN NaN 10 11
W X Y Z
A False False False False
B True True False False
C True True False False
W X Y Z
A True True True True
B False False True True
C False False True True
W X Y Z
A 0.0 1.0 2 3
****************************************************************************************************
W X Y Z
A 0.0 1.0 2 3
W X Y Z
A 0.0 1.0 2 3
B NaN NaN 6 7
C NaN NaN 10 11
W X Y Z
A 0.0 1.0 2 3
None
****************************************************************************************************
name age tel
0 xiaoming 20.0 10086.0
1 xiaohong NaN 10010.0
2 xiaoguang 30.0 NaN
0 20.0
1 25.0
2 30.0
Name: age, dtype: float64
Process finished with exit code 0