detectron2(目标检测框架)无死角玩转-07:源码详解(3)-模型构建-RetinaNet为例
以下链接是个人关于detectron2(目标检测框架),所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:17575010159 相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。 文 末 附 带 \color{blue}{文末附带} 文末附带 公 众 号 − \color{blue}{公众号 -} 公众号− 海 量 资 源 。 \color{blue}{ 海量资源}。 海量资源。
detectron2(目标检测框架)无死角玩转-00:目录
前言
通过前面的介绍,我们对于detectron2可以说总体上已经是十分的了解了,接下来我们来看看网络模型的构建。基于之前的讲解,已经以及知道所有的模型都存在于一个容器之中,从容器中获取想要的模型,其核心代码位于detectron2/modeling/meta_arch/build.py:
from detectron2.utils.registry import Registry
META_ARCH_REGISTRY = Registry("META_ARCH") # noqa F401
META_ARCH_REGISTRY.__doc__ = """
def build_model(cfg):
meta_arch = cfg.MODEL.META_ARCHITECTURE
return META_ARCH_REGISTRY.get(meta_arch)(cfg)
其首先通过META_ARCH_REGISTRY = Registry(“META_ARCH”)加载模型容器,然后通过meta_arch = RetinaNet 构建,并且获得 RetinaNet 模型。
RetinaNet
RetinaNet 的实现位于/detectron2/modeling/meta_arch/retinanet.py可以看到如下:
@META_ARCH_REGISTRY.register()
class RetinaNet(nn.Module):
其上的@META_ARCH_REGISTRY.register()就是把RetinaNet这个模型注册到META_ARCH_REGISTRY这个容器之中。首先我们看看RetinaNet实现的函数,如下:
# 网络前线传播
def forward(self, batched_inputs):
# 计算loss
def losses(self, gt_classes, gt_anchors_deltas, pred_class_logits, pred_anchor_deltas):
# 结合anchors获得ground truth
def get_ground_truth(self, anchors, targets):
# 网络推理,如果图片大小一样,统一一个batch_size进行推理
def inference(self, box_cls, box_delta, anchors, image_sizes):
# 网络推理,如果图片大小一样,不能统一成一个batch_size,则一张一张进行推理
def inference_single_image(self, box_cls, box_delta, anchors, image_size):
# 图像预处理
def preprocess_image(self, batched_inputs):
大致的了解其中实现的函数之后,我们来看看class RetinaNet的初始化函数:
def __init__(self, cfg):
super().__init__()
# GPU相关指定
self.device = torch.device(cfg.MODEL.DEVICE)
# fmt: off,
# 训练本人数据集时,为11
self.num_classes = cfg.MODEL.RETINANET.NUM_CLASSES
# 默认为 ['p3', 'p4', 'p5', 'p6', 'p7']
self.in_features = cfg.MODEL.RETINANET.IN_FEATURES
# Loss parameters:,focal_loss的相关系数,以及L1的平滑系数
self.focal_loss_alpha = cfg.MODEL.RETINANET.FOCAL_LOSS_ALPHA
self.focal_loss_gamma = cfg.MODEL.RETINANET.FOCAL_LOSS_GAMMA
self.smooth_l1_loss_beta = cfg.MODEL.RETINANET.SMOOTH_L1_LOSS_BETA
# Inference parameters:
self.score_threshold = cfg.MODEL.RETINANET.SCORE_THRESH_TEST
self.topk_candidates = cfg.MODEL.RETINANET.TOPK_CANDIDATES_TEST
self.nms_threshold = cfg.MODEL.RETINANET.NMS_THRESH_TEST
# 每张图片最多的box数目
self.max_detections_per_image = cfg.TEST.DETECTIONS_PER_IMAGE
# fmt: on
# 主干网络
self.backbone = build_backbone(cfg)
# 从主干网络获得特征图的输出形状,主要指定了缩放的倍数,如下:
# p3 = ShapeSpec(channels=256, height=None, width=None, stride=8)
# p4 = ShapeSpec(channels=256, height=None, width=None, stride=16)
# p5 = ShapeSpec(channels=256, height=None, width=None, stride=32)
# p6 = ShapeSpec(channels=256, height=None, width=None, stride=64)
# ......
backbone_shape = self.backbone.output_shape()
feature_shapes = [backbone_shape[f] for f in self.in_features]
# 头部模型构建,主要构建多个分支,分别进行box,置信度的回归,以及分类
self.head = RetinaNetHead(cfg, feature_shapes)
# 根据cfg配置的参数,生成anchor
self.anchor_generator = build_anchor_generator(cfg, feature_shapes)
# Matching and loss
# 把box (dx, dy, dw, dh) 转化为中心带你以及偏移值来表示
self.box2box_transform = Box2BoxTransform(weights=cfg.MODEL.RPN.BBOX_REG_WEIGHTS)
# 预测出来的box和ground_truth进行匹配
self.matcher = Matcher(
cfg.MODEL.RETINANET.IOU_THRESHOLDS,
cfg.MODEL.RETINANET.IOU_LABELS,
allow_low_quality_matches=True,
)
# 像素级别的平均值
pixel_mean = torch.Tensor(cfg.MODEL.PIXEL_MEAN).to(self.device).view(3, 1, 1)
# 像素级别的标准差
pixel_std = torch.Tensor(cfg.MODEL.PIXEL_STD).to(self.device).view(3, 1, 1)
# 正则化
self.normalizer = lambda x: (x - pixel_mean) / pixel_std
self.to(self.device)
其实,通过上面类和函数的创建,流程大致出来了,不过他们仅仅是创建了类和函数而已,在反向传播的时候才会被调用。所以我们再来看看RetinaNet的反反向传播。
forward
def forward(self, batched_inputs):
"""
Args:
batched_inputs: a list, batch
Each item in the list con
For now, each item in the
* image: Tensor, image in
* instances: Instances
Other information that's
* "height", "width" (int)
See :meth:`postproces
Returns:
dict[str: Tensor]:
mapping from a named loss
"""
# batched_inputs 是一个batch_size大小的
# 如包含了:'file_name' = '/data/zwh/0
# 'height' = 492 'width' = 65
# 'instances':一些注释,如语义分割的坐标,box的坐
# preprocess_image 函数 是对batched_i
images = self.preprocess_image(ba
if "instances" in batched_inputs[
gt_instances = [x["instances"
elif "targets" in batched_inputs[
log_first_n(
logging.WARN, "'targets'
)
gt_instances = [x["targets"].
else:
gt_instances = None
# 得到特征图p3[24,256,72,92], p4[24,2
# 得到特征图p5[24,256,9,12], p7[24,25
features = self.backbone(images.t
features = [features[f] for f in
# 把特征图一起送入head, 进行融合,并且预测box,置信度,
box_cls, box_delta = self.head(fe
# 生成anchor
anchors = self.anchor_generator(f
# 如果是训练,则结合 ground_truth 计算loss
if self.training:
gt_classes, gt_anchors_reg_de
return self.losses(gt_classes
# 如果是训练,则返回预测的结果
else:
results = self.inference(box_
processed_results = []
for results_per_image, input_
results, batched_inputs,
):
height = input_per_image.
width = input_per_image.g
r = detector_postprocess(
processed_results.append(
return processed_results
英文注释这里没有取消掉了,有兴趣的朋友可以阅读以下,通过上面的注释,大家对于网络的正向传播应该是比较理解了。
输入数据来源
前面虽然已经七七八八讲解的差不多了,但是还有一个问题,那就是前向传播过程中,即forward(self, batched_inputs)函数的输入batched_inputs的来源,其实还是很好找到的。其位于:
detectron2/engine/train_loop.py:
class SimpleTrainer(TrainerBase):
def __init__(self, model, data_loader, optimizer):\
......
def run_step(self):
"""
# 获取一个batch_size的数据,如果有必要,是可以对dataloader进行装饰的
If your want to do something with the data, you can wrap the dataloader.
"""
data = next(self._data_loader_iter)
data_time = time.perf_counter() - start
其中的data就是对应前面提到的batched_inputs,跟人的配置运行中显示如下:
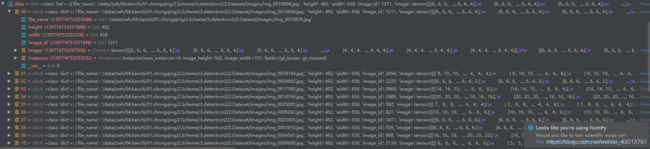
其实,前面已经提到过了,即为:
batched_inputs 是一个batch_size大小的
如包含了:'file_name' = '/data/zwh/0
'height' = 492 'width' = 65
'instances':一些注释,如语义分割的坐标,box的坐标
结语
到这里,分析得算是比较细致了,后面我们研究的就是数据预处理,anchor了,以及loss的计算了。后面再讲。
武汉加油,中国加油。待桃李盛开之时,定是你我煮酒共事之初!
