对比学习知识扩展——一堆奇奇怪怪的loss,快把我压死了orz...
1.交叉熵loss和对比loss区别
- 交叉熵 loss 是 最后结果过一层 fc 然后进行 softmax 。 然后 fc 的系数 W 就是特征的模板(模板的意思是把一些特征用这个Wc参数转换后,就能判断它是否是c类,相当于这个Wc就是c类的模板)
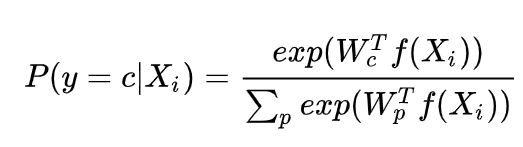
- 非参数样本分类 loss : 这里所谓非参数样本分类,则是将每个计算出的样本特征作为模板
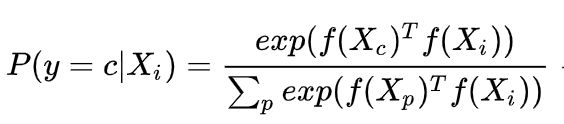
- 对比 loss
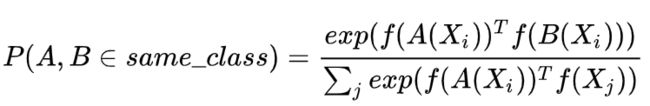
2.Triplet Loss 和 对比loss 区别:
- Triplet Loss 负样本只有一对
- 对比 loss 负样本有很多对
3. 深度度量学习的知识
别笑,这个学习就包含了对比损失。赶紧去学把..
[2]
metric learning的方法有两大分支:pair-based 和 proxy-based.pair-based是基于真实的样本对,比如contrastive loss, triplet loss, N-pair loss和MS loss等,而proxy-based是利用proxy去表示类别的特征,或者样本特征,比如说softmax, Proxy-NCA等.proxy是一个非常宽泛的概念,在softmax中,它是fc层的列;在memory的方法中,它是存储在memory中的特征.
pair-based的方法的好处在于简单准确,准确的意思是你的feature是从当前模型前向出来的,可以精确的表示当前的模型;缺点在于计算量大,信息局限,pair-based只可以利用当前mini-batch的信息,不能看到模型在整体的数据的表现,一直在做局部的优化.
那么,proxy的好处在于可以有global的信息,但是,缺点是什么?proxy是基于历史信息,或者是网络一步步学过来的,未必能够准确的表达当前模型.
4. 奇奇怪怪的loss集合顺序梳理和典型有名的loss
- 最初的对比损失和三元损失
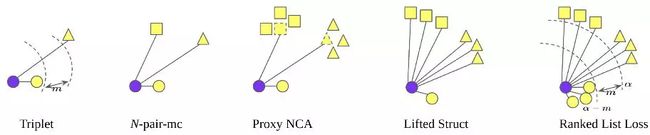
Contrastive loss和triplet loss都很常用,一般来说,Triplet-Loss的效果比Contrastive Loss的效果要好,因为他考虑了正负样本与锚点的距离关系。然而,这两种loss函数如果单独使用则会遭遇收敛速度慢的问题。在学习过程的后期,大多数样本都能满足损失函数的约束条件,这些样本对应进一步学习的贡献很小。因此,这两种损失函数都需要配合hard sample mining的学习策略一起使用,例如FaceNet提出的simi-hard negative sample mining方法。
tripelt loss缺点论文:
度量学习的论文很多都会惯例分析一下tripelt loss的。triplet loss的缺点也是那几个,比如说元组选择花时间,需要的batch size大,对于样本只有选择/不选择,没有权重的分配。
- n-pair loss
N-pair-ms loss对Triplet loss的上述问题进行了改进,不同于Triplet Loss使用单个的正负样本,N-pair-ms loss损失函数利用了数据之间的结构信息来学习到更有区别性的表示,其在每次参数更新的过程中同时考虑了query样本与其他多个不同类的负样本之间的关系,促使query与其他所有类之间都保持距离,这样能够加快模型的收敛速度。真正的 对比学习loss

基于上述的两种损失函数衍生出了很多变形,比如将数据丰富的结构化信息加入到Loss中,而不仅仅局限于二元组或三元组
- Lifted Struct loss
Lifted Struct loss可以只针对最hard的negative来优化。在Triplet loss中,样本i和样本j各自作为锚点时,选择的negative是不相同的。而Lifted Struct loss中,选中i和j这个样本对时,则只选择i或j最hard的一个negative来优化。这样做的目的是忽略没那么hard的negative,起到加速优化的作用。
动态建立负样本论文:
《FaceNet: A Unified Embedding for Face Recognition and Clustering》
《Imbalanced Deep Learning by Minority Class Incremental Rectification》
-
Ranked list loss
不是让正样本更接近,负样本更远离。学习到一个函数f使得正样本对之间的相似度高于负样本之间的相似度
可是有些又把这个归结于 和 三元组、对比loss一样额
- 对于给定的query,基于相似度来对其它所有样本进行排序。
- 进行non-trivial sample mining,本文使用的采样策略很简单,就是损失函数不为0的样本,具体来说,对于正样本,损失函数不为0意味着它们与anchor之间的距离大于α-m , 类似的,对于负样本,损失函数不为0意味着它们与anchor之间的距离小于α。
- 基于欧氏距离来对所有负样本赋予权重,距离越小权重越大
杂七杂八
1.所以目前的pairwise cost method都是集中在研究类内距离和类间距离之间的关系,比如naive triplet loss就是让类间距离比类内距离大一个fix的值。
三项分别表示类内距离,类间距离以及这两个距离的相对距离
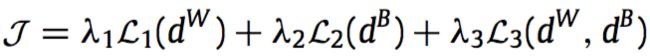
2.基于pair-based loss的方法通常都要限制negative instance的数量和质量
数量——利用memory bank (最新的Moco进行存储)
质量——加权以及各种paper的改进
1).一个positive和一个negative。2).每类都选取一个样本。3).一个positive和每个negative类的平均。4).一个positive和所有negative。5).所有positive和所有
negative。
参考负样本选择知乎
3.
工程调整
一般做法是先选一个基本的,然后根据badcase去调整。比如,你发现很多case错误原因是由于类内距过大,就可以改一个对类内距做了限制的loss。
现实中,我们一般先选几个代表性的loss,都跑一下
推荐知乎博主:(直接去搜就好,(●'◡'●))
军火交易商
Fei Ding
王珣
打个酱油
如何看待研究人员声称近13年来在 deep metric learning 领域的进展实际并不存在?
参考文献
[1]交叉熵loss 和 对比loss区别
[2]度量学习论文简评
[3]度量学习的loss集合
[4]Ranking loss系列
[5]表征学习的Contrastive Loss小结
[6]如何搞懂metric learning
[7]Deep Metric Learning