关于select/poll/epoll的一切
select
用途
相比与普通的阻塞IO模型
select相当于是一名监管员
把多个要处理的文件描述符纳入自己的监管
在设定的时间内阻塞查询 看哪些套接字是就绪的
如果是就绪的则对这些套接字进行IO处理
用法
看一下下面这段简单的代码
实现的功能就是把标准输入(即文件描述符为0)
那入select的监管
然后select在5s内阻塞的轮询
看是否有读就绪事件
如果有的话就返回 然后对其进行处理
如果超时或者出错的或也返回
#include
#include
#include
#include
#include
#include
#include
#include
#include
using namespace std;
int main(void) {
/**step1 : select工作之前,需要知道要监管哪些套接字**/
int listen_fd=0;
fd_set read_set;
FD_ZERO(&read_set);
FD_SET(listen_fd,&read_set);
/*step2 : select开始工作,设定时间内阻塞轮询套接字是否就绪*/
struct timeval tv;
tv.tv_sec = 5;
tv.tv_usec = 0;
int ret=select(listen_fd+1,&read_set,NULL,NULL,&tv);
/*step3 : select完成工作,即如果出现就绪或者超时 ,则返回*/
if(ret==-1){
cout<<"errno!"<0){
if(FD_ISSET(listen_fd,&read_set));
{
char *buffer=new char[10];
read(listen_fd,buffer,sizeof(buffer));
cout<<"Input String : "< 使用方法总结如下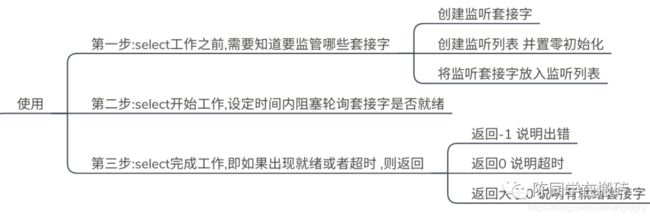
接口
上面的使用涉及到了下面几个接口
fd_set
1.fd_set是一种位数组类型,
也就是说数组中的数组元素值只能是0或1
2.因为由上面小实例
可以看出 select要监听三种就绪事件(可读 可写 出错)
是通过先建立三个事件对应的位数组
然后三个位数组初始化
然后把要监听的套接字
在该套接字数组中置为1进行的
FD_SET
FD_SET(int fd, fd_set *set)
把文件描述符fd加入到
对应的监听列表( fd_set类型的位数组),
就是把数组中该文件描述符位的元素置1,
FD_CLR
FD_CLRint fd, fd_set *set)
把文件描述符fd踢出
出对应的监听列表( fd_set类型的位数组),
就是把数组中该文件描述符位的元素置0,
FD_ISSET
int FD_ISSETint fd, fd_set *set)
判断文件描述符fd是否
在set对应的事件中就绪( fd_set类型的位数组),
就是判断该位数组是否为1
是的话 返回1 否则返回0
FD_ZERO
FD_ISSET(fd_set *set)
对监听列表ser进行置0 相当于对其进行初始化
select
接口:
int select(int nfds, fd_set *readfds, fd_set *writefds,fd_set *exceptfds, struct timeval *timeout);
参数:
nfds 表示总共有几个要监管查询的套接字
通常被设定为所监听的最大文件描述符值+1
因为文件描述附是从0开始的
fd_set是一种位数组类型,
也就是说数组中的数组元素值只能是0或1
readfd表示要进行监管的读操作的套接字的数组,
writefds表示要进行监管的写操作套接字的数组
exceptfds表示要进行监管的异常事件套接字的数组
参数timeout表示每次查询停留的时间,
其中timeval结构体的格式如下
struct timeval {
long tv_sec; /* 秒数 */
long tv_usec; /* 毫秒数 */
}
阻塞情况:
3种情况:
设置为NULL,永远等下去(阻塞),
设置timeval,等待固定时间(固定时间阻塞),
设置timeval为0,检查描述字后立即返回,(非阻塞)
返回值:
3种情况:
在此期间只要有一个套接字就就绪了,
select就会返回停止阻塞
成功时返回就绪套接字数目
去判断自己感兴趣的套接字是否在其中
然后调用read /accept同步读写或者建立连接等IO操作进行响应
如果就绪就执行相应的处理
超时时返回0
失败时返回-1
同时设置errno
失败时候的errno可能有以下情况
EBADF 监听集合中传入了无效的文件描述符
EINTR select在工作过程中被信号中断了
EINVAL nfds 参数是负数或者超出了最大的数量限制
EINVAL The value contained within timeout is invalid.
ENOMEM 无法开辟内存
源码
源码框架
这里简单的总结了select源码的一个框架
点击查看大图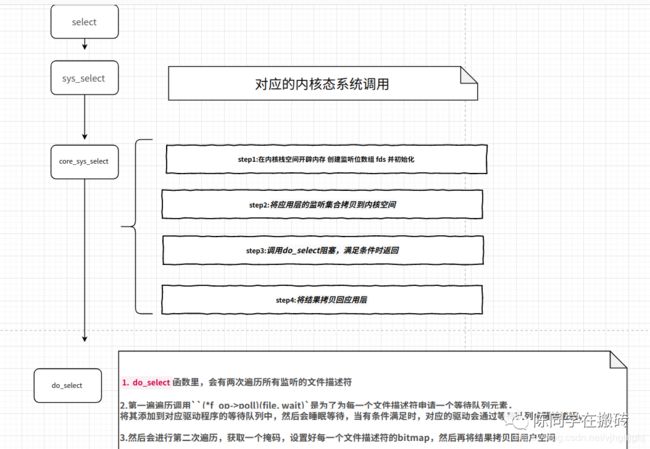
源码细节
将注释都写好了 细节可以看注释
select对应的系统调用如下
SYSCALL_DEFINE5(select, int, n, fd_set __user *, inp, fd_set __user *, outp,
fd_set __user *, exp, struct timeval __user *, tvp)
将其展开后得到如下函数
long sys_select(int n, fd_set __user * inp, fd_set __user * outp,
fd_set __user * exp, struct timeval __user * tvp)
SYSCALL_DEFINE5(select, int, n, fd_set __user *, inp, fd_set __user *, outp,
fd_set __user *, exp, struct timeval __user *, tvp)
{
/* 从应用层会传递过来三个需要监听的集合,可读,可写,异常 */
ret = core_sys_select(n, inp, outp, exp, to);
return ret;
}
接下来看core_sys_select
int core_sys_select(int n, fd_set __user *inp, fd_set __user *outp,
fd_set __user *exp, struct timespec *end_time)
{
/* 在栈上分配一段内存 */
long stack_fds[SELECT_STACK_ALLOC/sizeof(long)];
size = FDS_BYTES(n); //n个文件描述符需要多少个字节
/*
* 如果栈上的内存太小,那么就重新分配内存
* 为什么是除以6呢?
* 因为每个文件描述符要占6个bit(输入:可读,可写,异常;输出结果:可读,可写,异常)
*/
if (size > sizeof(stack_fds) / 6)
bits = kmalloc(6 * size, GFP_KERNEL);
/* 设置好bitmap对应的内存空间 */
fds.in = bits; //可读
fds.out = bits + size; //可写
fds.ex = bits + 2*size; //异常
fds.res_in = bits + 3*size; //返回结果,可读
fds.res_out = bits + 4*size; //返回结果,可写
fds.res_ex = bits + 5*size; //返回结果,异常
/* 将应用层的监听集合拷贝到内核空间 */
get_fd_set(n, inp, fds.in);
get_fd_set(n, outp, fds.out);
get_fd_set(n, exp, fds.ex);
/* 清空三个输出结果的集合 */
zero_fd_set(n, fds.res_in);
zero_fd_set(n, fds.res_out);
zero_fd_set(n, fds.res_ex);
/* 调用do_select阻塞,满足条件时返回 */
ret = do_select(n, &fds, end_time);
/* 将结果拷贝回应用层 */
set_fd_set(n, inp, fds.res_in);
set_fd_set(n, outp, fds.res_out);
set_fd_set(n, exp, fds.res_ex);
return ret;
}
下面来看一看do_select函数
int do_select(int n, fd_set_bits *fds, struct timespec *end_time)
{
for (;;) {
/* 遍历所有监听的文件描述符 */
for (i = 0; i < n; ++rinp, ++routp, ++rexp)
{
for (j = 0; j < __NFDBITS; ++j, ++i, bit <<= 1)
{
/* 调用每一个文件描述符对应驱动的poll函数,得到一个掩码 */
mask = (*f_op->poll)(file, wait);
/* 根据掩码设置相应的bit */
if ((mask & POLLIN_SET) && (in & bit)) {
res_in |= bit;
retval++;
}
if ((mask & POLLOUT_SET) && (out & bit)) {
res_out |= bit;
retval++;
}
if ((mask & POLLEX_SET) && (ex & bit)) {
res_ex |= bit;
retval++;
}
}
}
/* 如果条件满足,则退出 */
if (retval || timed_out || signal_pending(current))
break;
/* 调度,进程睡眠 */
poll_schedule_timeout(&table, TASK_INTERRUPTIBLE, to, slack);
}
}
do_select会遍历所有要监听的文件描述符,调用对应驱动程序的poll函数,驱动程序的poll一般实现如下
static unsigned int button_poll(struct file *fp, poll_table * wait)
{
unsigned int mask = 0;
/* 调用poll_wait */
poll_wait(fp, &wq, wait); //wq为自己定义的一个等待队列头
/* 如果条件满足,返回相应的掩码 */
if(condition)
mask |= POLLIN;
return mask;
}
看看poll_wait做了什么
static inline void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p)
{
if (p && wait_address)
p->qproc(filp, wait_address, p);
}
p->qproc在之前又被初始化为__pollwait
static void __pollwait(struct file *filp, wait_queue_head_t *wait_address,
poll_table *p)
{
/* 分配一个结构体 */
struct poll_table_entry *entry = poll_get_entry(pwq);
/* 将等待队列元素加入驱动程序的等待队列头中 */
add_wait_queue(wait_address, &entry->wait);
}
至此 select源码分析完毕
特性
select特点分析
select缺点:
(1)select能监听的文件描述符个数受限于FD_SETSIZE,
一般为1024
(2)源码中的do_select部分是采用for循环的形式来遍历的,
也就是select采用轮询的方式扫描文件描述符,
文件描述符数量越多,性能越差;
(3)源码中的code_sys_select在每次在轮询期间
都需要将用户态的监听位数组拷贝到内核态的fds对象中,
select需要复制大量的句柄数据结构到内核空间,
产生巨大的开销;
(4)select返回的是含有整个句柄的数组,
应用程序需要遍历整个数组才能发现哪些句柄发生了事件 比较繁琐;
(5)select的触发方式是水平触发,
应用程序如果没有完成
对一个已经就绪的文件描述符进行IO操作,
那么之后每次select调用还是会
将这些文件描述符通知进程。
select优点:
(1)用户可以在一个线程内
同时处理多个socket的IO请求。
同时没有多线程多进程那样耗费系统资源
(2)目前几乎在所有的平台上支持,
其良好跨平台支持也是它的一个优点
poll
用途
poll函数工作原理与select函数类似,
也是监管一系列的文件描述符,
阻塞的去轮询看这些文件描述符是否可读/可写/异常,
再去调用io函数读写
用法
看一下下面这段简单的代码
实现的功能就是把标准输入(即文件描述符为0)
纳入poll的监管
然后poll在5s内阻塞的轮询
看是否有读就绪事件
如果有的话就返回 然后对其进行处理
如果超时或者出错的也返回
#include
#include
#include
#include
using namespace std;
int main(){
/*第一步 poll开始监听之前要知道要监管哪些套接字*/
struct pollfd fds[1];
fds[0].fd=0;
fds[0].events=POLL_IN;
fds[0].revents=POLL_IN;
/*第二步 poll开始工作 阻塞的轮询看监管的套接字是否就绪*/
int ret=poll(fds,1,5000);
/*第三部 poll完成工作 有套接字就绪或者时间超时返回*/
if(ret<0){cout<<"error"< 接口
上面的使用设计到了下面几个接口
pollfd
和select监听采用fd_set位数组不同
poll监听采用的是pollfd事件结构体数组
也就是先定义一个事件结构体数组
然后在事件结构体数组中
设定好要监听事件的一个文件描述符
以及要监听的事件等等信息
事件结构体的原型如下
pollfd结构体的原型为:
struct pollfd {
int fd; /* 文件描述符 */
short events; /* 注册的事件 */
short revents; /* 实际发生的事件,由内核填充 */
};
其中:
1.fd 表示你要监听的文件描述符
2.events参数表示你要监听的事件类型
比如POLL_IN表示你想监听该套接字的读就绪事件
3.reevents表示当该套接字的某一事件就绪的
内核就会将该参数置为该事件类型
比如POLL_IN表示该套接字读就绪了
总结来说每个结构体的 events 域是由用户来设置,
告诉内核我们关注的是什么,
而 revents 域是返回时内核设置的,
以说明对该描述符发生了什么事件
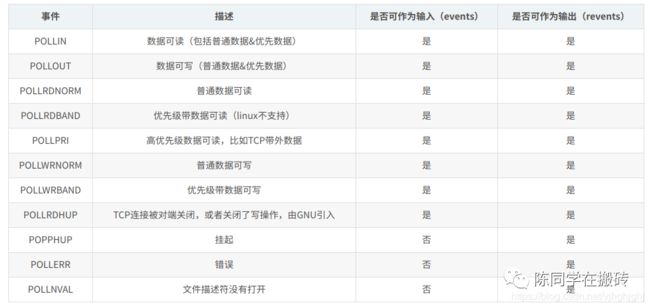
events和reevents具体可以取的一些宏如下
多个宏是可以通过或运算符同时监听的
poll
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
参数情况:
(1)fds:指向一个结构体数组的第0个元素的指针,
每个数组元素都是一个struct pollfd结构,
用于指定测试某个给定的fd的条件
(2)nfds:表示fds结构体数组大小
(3)timeout:表示poll函数的超时时间,单位是毫秒
函数返回值:
(1)返回值小于0,表示出错
(2)返回值等于0,表示poll函数等待超时
(3)返回值大于0,表示poll由于监听的文件描述符就绪返回,
并且返回结果就是就绪的文件描述符的个数。
poll函数使用前面提到的pollfd结构体中的revents参数,
revents变量在每一次poll函数调用完成后
内核设置会设置revents的值,
这个值其实也就是上面列出来的那些events的宏,
以说明对该描述符发生了什么事件
比如 调用完poll函数后要
查看某一个文件描述符是否处于激活状态(比如可读)
是通过调用pollfd参数的revents参数与POLLIN做比较如果相等,
则说明该文件描述符处现在是可读的
使用if语句:if(poll_fd.revents==POLLIN)
就绪情况:
读就绪
1)socket内核中,接收缓冲区中的字节数,
大于等于低水位标记SO_RCVLOWAT.
此时可以无阻塞的读该文件描述符,
并且返回值大于0;
2)socket TCP通信中, 对端关闭连接,
此时对该socket读, 则返回0;
3)监听的socket上有新的连接请求;
4)socket上有未处理的错误;
写就绪
1)socket内核中,
发送缓冲区中的可用字节数
(发送缓冲区的空闲位置大⼩),
大于等于低水位标记 SO_SNDLOWAT,
此时可以无阻塞的写, 并且返回值大于0;
2)socket的写操作被关闭(close或者shutdown).
对一个写操作被关闭的socket进行写操作,
会触发 SIGPIPE信号;
3)socket使⽤非阻塞connect连接成功或失败之后;
4)socket上有未读取的错误;
异常就绪:
socket上收到带外数据.
源码
源码结构
 poll源码架构
poll源码架构
特性
1、优点
由上面的sys_poll可以看出, poll底层使用poll_list来管理 ,
它没有最大连接数的限制,原因是它是基于链表来存储的。
2、缺点
(1) 由上面的do_poll可以看出,
poll采用轮询的方式扫描文件描述符,
文件描述符数量越多,性能越差;
(2)由上面的do_sys_poll可以看出,在轮询期间,
需要复制大量的句柄数据结构到内核空间,
产生巨大的开销;
(3)由上面的do_poll可以看出,
返回的是含有整个句柄的数组,
应用程序需要遍历整个数组才能
发现哪些句柄发生了事件;
(4)触发方式是水平触发,
应用程序如果没有完成
对一个已经就绪的文件描述符进行IO操作,
那么之后每次select调用
还是会将这些文件描述符通知进程。
epoll
用途
epoll类似于select和poll 也是把要监听的文件描述符
纳入自己的监管
但是由于select和poll的缺点存在,
基于selec或者pollt模型的服务器程序,
要达到10万级别的并发访问,是一个很难完成的任务。
由于epoll的实现机制与select/poll机制完全不同,
上面所说的 select/poll的缺点在epoll上不复存在。
用法
下面是epoll监控标准输入(文件描述附为0)的一个简单例子
#include
#include
#include
#include
#include
using namespace std;
int main(){
//step1: epoll开始工作之前 先把文件描述符纳入epoll监管
struct epoll_event listen_fd;
listen_fd.data.fd=0;
listen_fd.events=EPOLLIN;
int epoll_fd=epoll_create(10);
epoll_ctl(epoll_fd,EPOLL_CTL_ADD,0,&listen_fd);
//step2: epoll开始工作 阻塞的等待文件描述符就绪
struct epoll_event ready_events[10];
int ret=epoll_wait(epoll_fd,ready_events,10,-1);
//step3:epoll完成工作 看自己感兴趣的套接字是否就绪
if(ret<0){ cout<<"epoll error"< 接口
上面的使用涉及到了以下接口
1.epoll_event
struct epoll_event结构如下:
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
其中
typedef union epoll_data {
void *ptr;
int fd;
__uint32_t u32;
__uint64_t u64;
} epoll_data_t;
epoll_event和一个指定的要监听的文件描述符相绑定 指定要对它监听的事件
events可以是以下几个宏的集合:
EPOLLIN :表示对应的文件描述符可以读(包括对端SOCKET正常关闭);
EPOLLOUT:表示对应的文件描述符可以写;
EPOLLPRI:表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来);
EPOLLERR:表示对应的文件描述符发生错误;
EPOLLHUP:表示对应的文件描述符被挂断;
EPOLLLT:将EPOLL设为于水平触发(Level Triggered)。
EPOLLET:将EPOLL设为边缘触发(Edge Triggered)模式,
EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,
如果还需要继续监听这个socket的话,
需要再次把这个socket加入到EPOLL队列里
 在这里插入图片描述
在这里插入图片描述
关于EPOLLLT
1. LT模式是水平触发模式 在这种模式中,
内核告诉你一个文件描述符是否就绪了,
然后你可以对这个就绪的fd进行IO操作。
如果你不作任何操作,内核还是会继续通知你的,
所以,这种模式编程出错误可能性要小一点。
传统的select/poll都是这种模型的代表.
2. 默认采用LT模式,
LT支持阻塞和非阻塞套 LT模式更加安全
3.LT模式的缺点:LT对于read操作比较简单,
有read事件就读,
读多读少都没有问题,
但是write就不那么容易了,
一般来说socket在空闲状态时
发送缓冲区一定是不满的,
假如fd一直在监控中,
那么会一直通知写事件,不胜其烦。
所以必须保证没有数据要发送的时候,
要把fd的写事件监控从epoll列表中删除,
需要的时候再加入回去,如此反复。
关于EPOLLET
1. ET是边缘触发模式 在这种模式下当描述符
从未就绪变为就绪时,
内核通过epoll告诉你。
然后它会假设你知道文件描述符已经就绪,
并且不会再为那个文件描述符
发送更多的就绪通知,
2.ET 是高速工作方式,只支持非阻塞套接字
3. 当使用epoll的ET模型(epoll的非默认工作方式)来工作时,
当产生了一个EPOLLIN事件后,
读数据的时候需要考虑的是当recv()返回的大小
如果等于要求的大小,
即sizeof(buf),那么很有可能是缓冲区
还有数据未读完,
也意味着该次事件还没有处理完,
所以还需要再次读取:
4. ET模式的缺陷:
如果某个socket源源不断地收到非常多的数据,
在试图读取完所有数据的过程中,
可能会造成其他的socket得不到处理,
从而造成饥饿问题。
解决办法:为每个已经准备好的描述符维护一个队列,
这样程序就可以知道哪些描述符已经准备好了
但是并没有被读取完,
然后程序定时或定量的读取,
如果读完则移除,直到队列为空,
这样就保证了每个fd都被读到并且不会丢失数据,
关于EPOLLONSHOT
A线程读完某socket上数据后开始处理这些数据,
此时该socket上又有新数据可读,
B线程被唤醒读新的数据,
造成2个线程同时操作一个socket的局面 ,
EPOLLONESHOT保证一个socket连接
在任一时刻只被一个线程处理。
2.epoll_create
用法:
int epoll_create(int size);
创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大。
这个参数不同于select()中的第一个参数,给出最大监听的fd+1的值。
需要注意的是,当创建好epoll句柄后,它就是会占用一个fd值,
在linux下如果查看/proc/进程id/fd/,
是能够看到这个fd的,所以在使用完epoll后,
必须调用close()关闭,否则可能导致fd被耗尽。
原理:
1.调用epoll_create()建立一个epoll对象
(在epoll文件系统中为这个句柄对象分配资源)
当某一进程调用epoll_create方法时,Linux内核会创建一个eventpoll结构体,
这个结构体中有两个成员与epoll的使用方式密切相关。
eventpoll结构体如下所示:
struct eventpoll{
....
/*红黑树的根节点,这颗树中存储着所有添加到epoll中的需要监控的事件*/
struct rb_root rbr;
/*双链表中则存放着将要通过epoll_wait返回给用户的满足条件的事件*/
struct list_head rdlist;
....
};
每一个epoll对象都有一个独立的eventpoll结构体,
2.在epoll中,对于每一个事件,都会建立一个epitem结构体,
如下所示:
struct epitem{
struct rb_node rbn;//红黑树节点
struct list_head rdllink;//双向链表节点
struct epoll_filefd ffd; //事件句柄信息
struct eventpoll *ep; //指向其所属的eventpoll对象
struct epoll_event event; //期待发生的事件类型
}

3.epoll_ctl
1. 用法:
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
epoll的事件注册函数,它不同与select()是在监听事件时(epoll使用epoll_wait监听)
告诉内核要监听什么类型的事件,
而是在这里先注册要监听的事件类型。第一个参数是epoll_create()的返回值,
第二个参数表示动作,用三个宏来表示:
EPOLL_CTL_ADD:注册新的fd到epfd中;
EPOLL_CTL_MOD:修改已经注册的fd的监听事件;
EPOLL_CTL_DEL:从epfd中删除一个fd;
第三个参数是需要监听的fd,
第四个参数是告诉内核需要监听什么事以及传过来的数据放哪,即对应的事件结构体
2.原理:
调用epoll_ctl向epoll对象中添加这100万个连接的套接字
用于存放通过epoll_ctl方法向epoll对象中添加进来的事件。
这些事件都会挂载在红黑树中,
如此,重复添加的事件就可以通过红黑树而高效的识别出来
(红黑树的插入时间效率是lgn,其中n为树的高度)。
而所有添加到epoll中的事件都会与设备(网卡)驱动程序建立回调关系,
也就是说,当相应的事件发生时会调用这个回调方法。
这个回调方法在内核中叫ep_poll_callback,它会将发生的事件添加到rdlist双链表中。
4.epoll_wait
1.用法:
等待事件的产生,类似于select()调用。
参数epfd表示由epoll_create 生成的epoll专用的文件描述符;
参数events用来从内核得到就绪事件的集合,内核检测到就绪的事件
就将所有就绪事件从内核事件表复制到events数组中
参数maxevents告之内核这个events有多大(数组成员的个数),
这个maxevents的值不能大于创建epoll_create()时的size,
参数timeout表示等待I/O事件发生的超时值(单位是ms);-1相当于阻塞,
0相当于非阻塞。一般用-1即可
返回0表示超时
返回-1 表示出错
可能会有以下错误
EBADF epfd不是一个有效的文件描述符
EFAULT events数组不可写
EINTR 被信号中断了
EINVAL epfd不是一个epoll描述符 或者maxevents<=0
返回大于0 表示 就绪的文件描述符的个数
此时再去遍历events集合看自己的感兴趣的文件描述符是否就绪了
比如if(events[i].data.fd!=lisfd&&events[i].events&EPOLLIN)就表示
第lisfd这个文件描述符读就绪了
再去做相应的处理
2.原理:
等侍注册在epfd上的socket fd的事件的发生,
如果发生则将发生的sokct fd和事件类型放入到events数组中。
并 且将注册在epfd上的socket fd的事件类型给清空,
所以如果下一个循环你还要关注这个socket fd的话,
则需要用epoll_ctl(epfd,EPOLL_CTL_MOD,listenfd,&ev)
来重新设置socket fd的事件类型。
这时不用EPOLL_CTL_ADD,因为socket fd并未清空,
只是事件类型清空。这一步非常重要。
在底层实现的时候
当调用epoll_wait检查是否有事件发生时,
只需要检查eventpoll对象中的rdlist双链表中
是否有epitem元素即可。
如果rdlist不为空,则把发生的事件复制到用户态,
同时将事件数量返回给用户。
epoll_wait的效率非常高,因为调用epoll_wait时,
并没有一股脑的向操作系统
复制这100万个连接的句柄数据,
内核也不需要去遍历全部的连接。
源码
源码实现
(1) epoll_wait调用ep_poll,
当rdlist为空(无就绪fd)时挂起当前进程,
知道rdlist不空时进程才被唤醒。
(2) 文件fd状态改变
(buffer由不可读变为可读或由不可写变为可写),
导致相应fd上的回调函数ep_poll_callback()被调用。
(3) ep_poll_callback将相应fd对应epitem加入rdlist,
导致rdlist不空,进程被唤醒,epoll_wait得以继续执行。
(4) ep_events_transfer函数
将rdlist中的epitem拷贝到txlist中,
并将rdlist清空。
(5) ep_send_events函数(很关键),
它扫描txlist中的每个epitem,
调用其关联fd对用的poll方法。
此时对poll的调用仅仅是取得fd上较新的events
(防止之前events被更新),
之后将取得的events和相应的fd发送到用户空间
(封装在struct epoll_event,从epoll_wait返回)。
之后如果这个epitem对应的fd是LT模式监听
且取得的events是用户所关心的,
则将其重新加入回rdlist,
否则(ET模式)不在加入rdlist。
特性
epoll的优点
(1)epoll不会出现像select和poll
那样对文件描述符重复拷贝 .
epoll的解决方案在epoll_ctl函数中。
每次注册新的事件到epoll句柄中时
(在epoll_ctl中指定EPOLL_CTL_ADD),
会把所有的fd拷贝进内核,
而不是在epoll_wait的时候重复拷贝。
epoll保证了每个fd在整个过程中只会拷贝一次。
(2)epoll不会出现像selet和poll那样对文件描述符轮询.
epoll的解决方案不像select或poll一样
每次都把current轮流加入fd对应的设备等待队列中,
而只在epoll_ctl时把current挂一遍(这一遍必不可少)
并为每个fd指定一个回调函数,
当设备就绪,唤醒等待队列上的等待者时,
就会调用这个回调函数,
而这个回调函数会把就绪的fd加入一个就绪链表)。
epoll_wait的工作实际上
就是在这个就绪链表中查看有没有就绪的fd
(3)epoll不会出现在select那样的文件描述符的限制,
它所支持的FD上限是最大可以打开文件的数目,
这个数字一般远大于2048,
举个例子,在1GB内存的机器上大约是10万左右,
具体数目可以cat /proc/sys/fs/file-max察看,
一般来说这个数目和系统内存关系很大。
(4)epoll不会像select和poll那样只支持水平触发模式,
它同时支持ET和 LT

我是陈同学
让技术 有温度
你的支持是我搬砖的动力
▼
往期精彩回顾
▼
你的微信消息是怎么发出去的?
1个小时学会所有Linux核心命令
一个小时学会Git
Leetcode面试高频题汇总--链表
Leetcode面试高频题汇总--数组
【设计模式】可能是东半球最透彻的单例模式讲解