(大数据方向)分布式实验一:基于CentOS的伪分布式搭建
目录
什么是伪分布式:
一.实验工具
二.基本设置
1.配置网络
如何查看自己的IP地址,子网掩码,网关IP
2.关闭防火墙
3.关闭 selinux
4.配置主机名
5.配置映射
三.Hadoop伪分布式搭建
1) xshell xftp工具
2)安装 jdk
3) Ssh 密钥文件生成和验证
4)安装 hadoop。
5)在浏览器上查看自己的集群
什么是伪分布式:
伪分布式就是假分布式,假就假在只有一台机器而不是多台机器来完成一个任务,但是模拟了分布式的这个过程,所以伪分布式下Hadoop也就是虽然在一个机器上配置了hadoop的所有节点,但伪分布式完成了所有分布式所必须的事件。 伪分布式Hadoop和单机版最大区别就在于需要配置HDFS。
一.实验工具
1.虚拟机工作台:VMware Workstation Pro(博主自己用的是16)
2.操作系统:centos操作系统
3.hadoop:hadoop-2.6.5
二.基本设置
1.配置网络
1.进入虚拟机后右键打开终端
输入:
vim /etc/sysconfig/network-scripts/ifcfg-ens33进入如下界面(以下是博主已经配置好的,参数含义以及参数是否需要更改已在注释中标明)
YPE=Ethernet #网卡类型(此处是以太网)
PROXY_METHOD=none #代理方式:为关闭状态
BROWSER_ONLY=no #只是浏览器:否
BOOTPROTO=static #网卡的引导协议(如果是第一次配置应该是“dhcp”,改为“static”)
#static:静态IP
#dhcp:动态IP
#none:不指定,不指定容易出现各种各样的网络受限
DEFROUTE=yes #默认路由
IPV4_FAILURE_FATAL=no #是否开启IPV4致命错误检测
IPV6INIT=yes #IPV6是否自动初始化:是
IPV6_AUTOCONF=yes #IPV6是否自动配置:是
IPV6_DEFROUTE=yes #IPV6是否自动初始化:是
IPV6_FAILURE_FATAL=no #是否开启IPV6致命错误检测
IPV6_ADDR_GEN_MODE=stable-privacy #IPV6地址生成模型
NAME=ens33 #网卡物理设备名称
UUID=71ed7afe-303f-4981-b430-88fd054005ea #通用唯一识别码
DEVICE="ens33" #网卡设备名称(必须和‘NAME’值一样)
ONBOOT=yes #是否开机启动
#个人设置(下面有如何查找自己的网络地址等)
IPADDR=192.168.74.128 # IP地址 (需要更改)
NETMASK=255.255.255.0 #子网掩码(需要更改)
GATEWAY=192.168.74.2 #默认网关(需要更改)
DNS1=114.114.114.114 #和博主一样改成114.114.114.114即可
如何查看自己的IP地址,子网掩码,网关IP
(1)打开VMware... 在左边的库中单击选中要查找的虚拟机
(2)找到左上方的编辑并点击虚拟网络编辑器(编辑——>虚拟网络编辑器)
注明:可以点击下方的更改设置,可以自己更改地址(需要管理员身份)
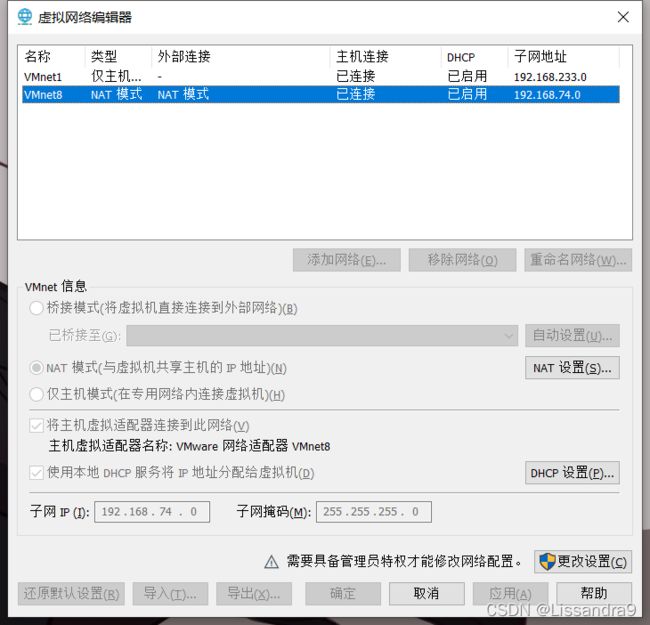
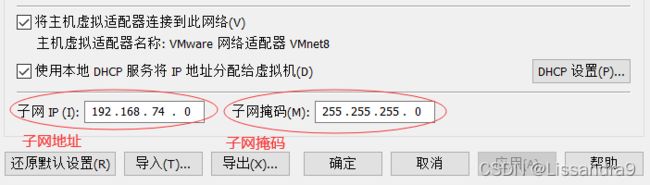
点击NAT设置,和DHCP设置
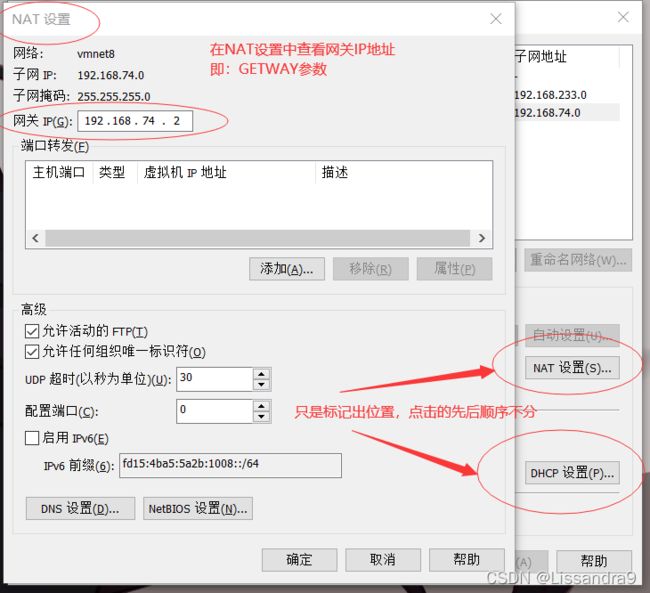
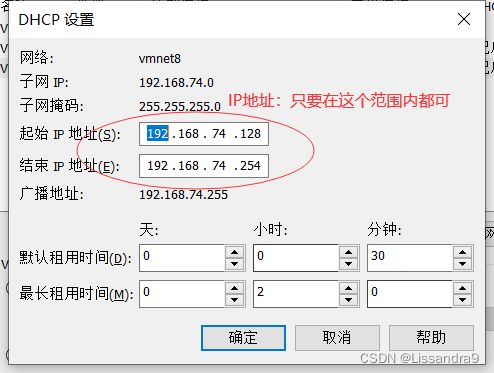
2.配置完成后进行重新加载
service network restart2.关闭防火墙
sudo systemctl stop firewalld //关闭防火墙
sudo systemctl disable firewalld //设置停止开机不启动
systemctl status firewalld //查看防火墙状态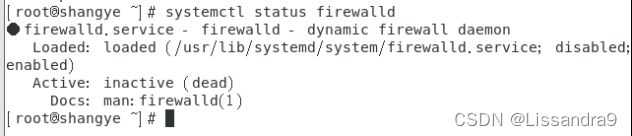
3.关闭 selinux
vim /etc/selinux/config
SELINUX=disabled //将 enforcing 改为 disabled 
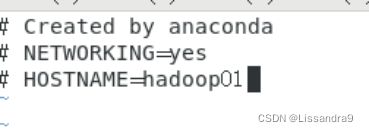
4.配置主机名
vim /etc/sysconfig/network
hostname=hadoop01
5.配置映射
vim /etc/hosts
三.Hadoop伪分布式搭建
1) xshell xftp工具
(xshell,xftp)提取码:uzdq https://pan.baidu.com/s/1GtirSojCKOmJloAfY-shBQ#list/path=%2F
https://pan.baidu.com/s/1GtirSojCKOmJloAfY-shBQ#list/path=%2F
2)安装 jdk
提取码:SY99(jdk-7u67-linux-x64.rpm)https://pan.baidu.com/s/1nBAaSemFX4SSBp6wiqceqg
1.通过xftp传输到虚拟机中
2.在Linux中解压JDK
rpm -i jdk-7u67-linux-x64.rpm //解压JDK
whereis java //查看java下载在哪个目录
cd /usr/java/jdk1.7.0-67/ //进入次目录(看你自己的下载路径而定)
pwd //对输出的结果进行辅助,后面会用到
3.配置环境变量
vim /etc/profile
在文件的最后输入
export JAVA_HOME=/usr/java/jdk1.7.0-67 //根据上一步的路径进行配置
export PATH=$PATH:$JAVA_HOME/bin4.重新加载该文件
source /etc/profile5.查看java是否配置成功
java -version注:openJDK是CENTOS中自带的JDK,查看时要看清楚是否为自己所下载安装的JDK版本(即使传出的OPENJDK,但是没关系,只要环境变量配置成功,就不影响后面的搭建)
3) Ssh 密钥文件生成和验证
ssh-keygen -t rsa //生成密钥
shh localhost
cd /root/.ssh
ssh-copy-id -i id_rsa.pub root@hadoop01 //此处的hadoop01,为你自己所设置的主机名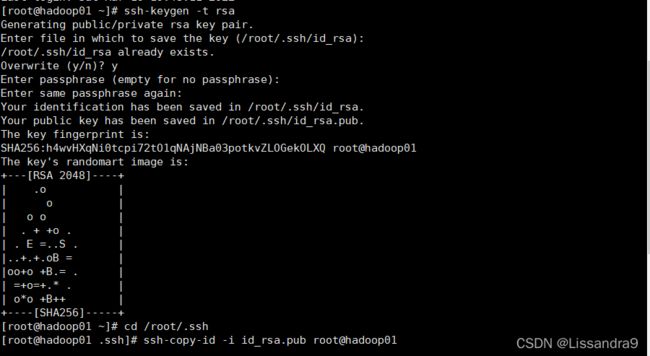
4) 安装 hadoop。
提取码:SY99(hadoop-2.6.5)https://pan.baidu.com/s/1_dE14pfAYRF7GU9YRxoWiQ1.同样通过xftp将hadoop传到linux中
2.解压hadoop
tar -zxvf hadoop-2.6.5.tar.gz -C /etc/hadoop3.配置环境变量。
vi /etc/profile 
4.重新加载profile 文件
source /etc/profile5. 进行二次环境变量的配置(java_home)
cd /etc/hadoop/hadoop-2.6.5/etc/hadoop
vi hadoop-env.sh
#进入插入状态,修改 JAVA_HOME 的值改为“/usr/local/jdk1.8.0_77 “,保存并退出(wq!)
vi mapred-env.sh
#进入插入状态,修改 JAVA_HOME的值为 “/usr/java/jdk1.7.0-67 “,保存并退出。
vi yarn-env.sh
#进入插入状态,修改 JAVA_HOME 的值改为 “/usr/java/jdk1.7.0-67 “,保存并退出。



6.修改配置文件
(1)core-site.xml
fs.defaultFS
hdfs://hadoop01:9000
hadoop.tmp.dir
/etc/hadoop/tmp
(2)hdfs-site.xml
dfs.replication
1
dfs.namenode.secondary.http-address
hadoop01:50090
(3)slave
vim slaves
hadoop01 //自己主机名 
7.格式化并启动集群
(格式化后查看图中标记的successfully和status 0如果为1,则代表格式化出错)
hadoop namenode -format //对名称节点进行格式化

到这里之后,如果上方的步骤无误,则进行下面的代码
cd /etc/hadoop/hadoop/bin //进入hadoop的bin目录
sh start -dfs.sh //启动集群
jps //查看进程
#查看进程时,确保有
#1.datanode
#2.namenode
#3.secondarynamenode
#就代表集群无误,如果出现没有数据结点(datanode)
#可能原因:进行了多次格式化
#解决方法:删除掉tmp目录,参考上方core-site.xml中配置的tmp路径
#(博主自己的路径是etc/hadoop/tmp)
# 删除该路径的代码:rm -rf /etc/hadoop/tmp
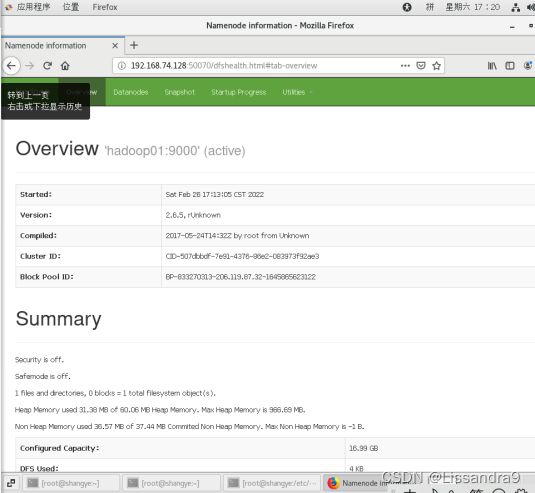
5)在浏览器上查看自己的集群
在网址栏输入 自己的IP地址:50070
6)练习上传文件
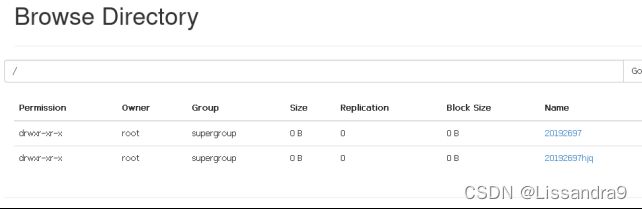
hadoop fs -mkdir -p /user/root //在hdfs上创建文件夹
hadoop fs -ls / //查看文件
在浏览器中查看
hadoop fs -put hadoop-2.6.5.tar.gz /user/root //上传hadoop到这个目录下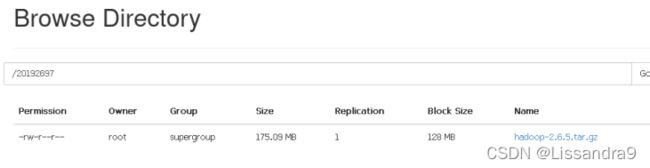
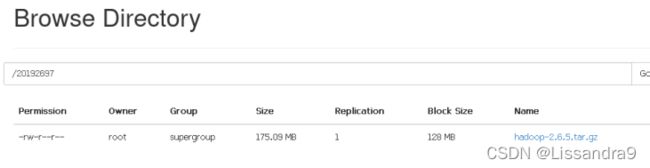
至此,伪分布式搭建完成
PS:如果上述步骤中有纰漏或者错误的,希望大家不吝指教,我一定及时修改,希望能与大家一起学习进步。
评论必回!!!
点赞必回!!!
来自废物萌新的请求!!!