matlab聚类实验,数据挖掘实验(七)Matlab实现聚类算法【clusterdata / kmeans】
本文代码均已在 MATLAB R2019b 测试通过,如有错误,欢迎指正。
另外,这次实验都是调用Matlab现成的函数,没什么技术含量。
(一)聚类分析的原理
聚类是将数据分类到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。
聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准,聚类分析能够从样本数据出发,自动进行分类。聚类分析所使用方法的不同,常常会得到不同的结论。不同研究者对于同一组数据进行聚类分析,所得到的聚类数未必一致。
从实际应用的角度看,聚类分析是数据挖掘的主要任务之一。而且聚类能够作为一个独立的工具获得数据的分布状况,观察每一簇数据的特征,集中对特定的聚簇集合作进一步地分析。聚类分析还可以作为其他算法(如分类和定性归纳算法)的预处理步骤。
(二)matlab中聚类的实现算法
方法一:直接聚类,利用clusterdata函数对样本数据进行一次聚类,其缺点为可供用户选择的面较窄,不能更改距离的计算方法,该方法的使用者无需了解聚类的原理和过程,但是聚类效果受限制。
方法二:层次聚类,该方法较为灵活,需要按步骤实现聚类过程,具体需要进行如下过程处理:
(1)计算数据集合中样本两两之间的相似性,用pdist函数计算样本之间的距离;
(2)用linkage函数定义类间距离;
(3)用cluster函数创建聚类。
方法三:划分聚类,包括K均值聚类和K中心聚类,同样需要系列步骤完成该过程,要求使用者对聚类原理和过程有较清晰的认识。
K-means聚类算法采用的是将N*P的矩阵X划分为K个类,使得所有类内对象与该类中心点之间的距离和最小。
Matlab自带函数:Y=kmeans(X, K)。
(三)利用matlab实现聚类算法
问题描述:
参考表中16*13列的矩阵,利用matlab中提供的几种方法实现聚类的过程。
代码:
clear; clc;
data=[
262725061234162241191550.2531.1514.964.6312.436.398.86
202220473198871918176580.4723.3413.246.2611.896.667.06
284227264291532378191499.6942.1419.948.3615.466.846.96
2637254362606427032110112.7645.3724.137.5517.849.267.38
272622083199681881158985.8332.2113.215.6814.586.626.87
222814091128851365167656.1719.8512.23.9814.099.467.48
2040151672324513131901142.1536.4316.724.6524.027.195.3
1332130992442612691837110.6117.8618.494.3113.647.574.51
1639187742609112531642131.823.719.047.512.627.35.39
2139149552769812231581145.9828.120.268.7218.797.325.7
48121451565853839173666381.9748.7937.789.3710.86.453.65
48126445322964841032606300.6438.4421.953.968.637.43.24
8389604846947955855309475.6690.5850.6517.3714.977.297.69
3059209212286522691757146.5220.1616.022.159.647.012.98
5198369125014326912775322.9836.8530.498.449.986.083.12
65128525634099044543099353.3659.733.391.9211.368.150.77
];
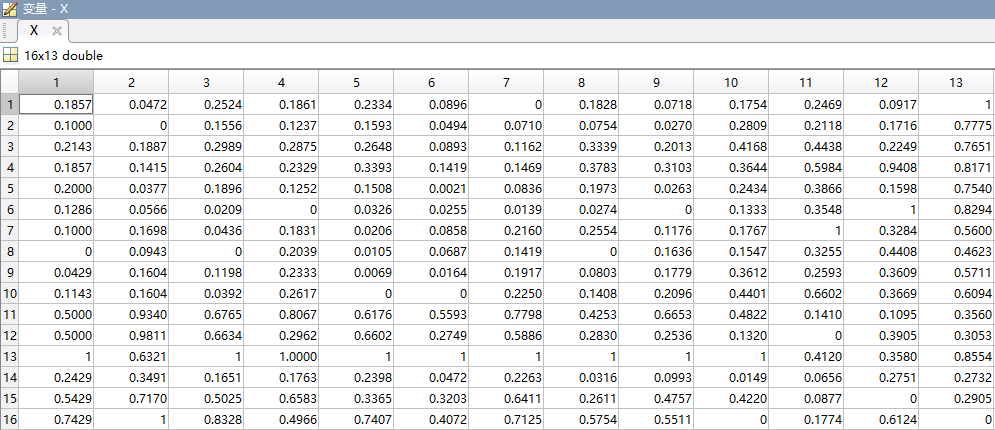
X=mapminmax(data',0,1)'; % 按列最小最大规范化到[0,1]
%% (1)直接聚类
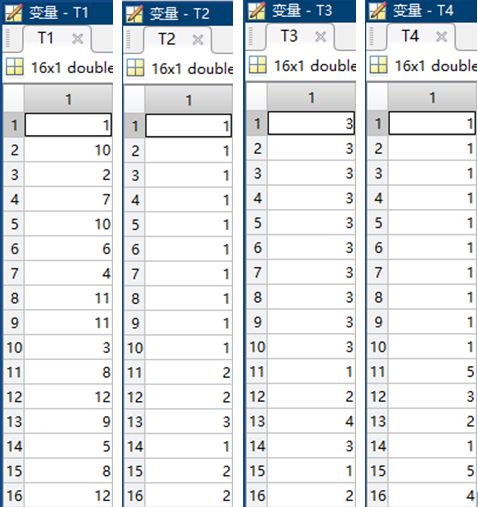
T1=clusterdata(X,0.2); % 如果0
T2=clusterdata(X,3); % 如果cutoff是一个≥2的整数,则形成的不同类别数为cutoff
%% (2)逐步聚类
Y=pdist(X); % 计算矩阵X中样本两两之间的距离,但得到的Y是个行向量
D=squareform(Y); % 将行向量的Y转换成方阵,方便观察两点距离(方阵的对角线元素都是0)
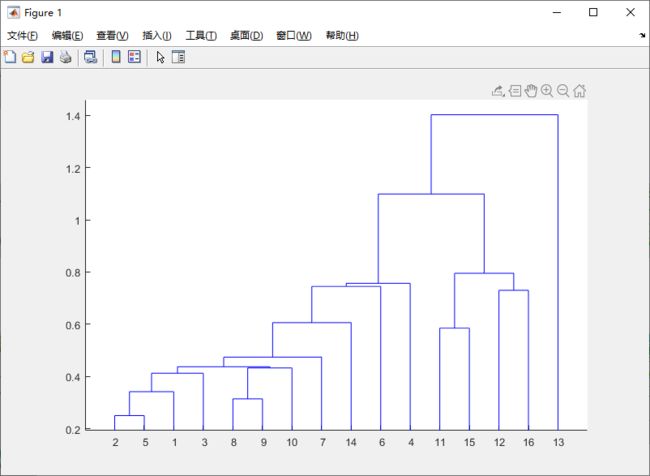
Z=linkage(Y); % 产生层次聚类树,默认采用最近距离作为类间距离的计算公式
dendrogram(Z); % 图示层次聚类树
T3=cluster(Z,4); % 在层次聚类树的基础上生成指定数目的类,cluster(Z,3)表示生成4类
%% (3)用k均值方法聚类
T4=kmeans(X,5); % 直接调用kmeans函数,kmeans(X,5)表示生成5类
最小最大规范化结果:
T1、T2、T3、T4变量的取值:
T3的层次聚类树:
本文分享 CSDN - nefu_ljw。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。