特征工程系列:GBDT特征构造以及聚类特征构造
特征工程系列:GBDT特征构造以及聚类特征构造
原创: JunLiang 木东居士 4天前
特征工程系列:GBDT特征构造以及聚类特征构造
本文为数据茶水间群友原创,经授权在本公众号发表。
关于作者:JunLiang,一个热爱挖掘的数据从业者,勤学好问、动手达人,期待与大家一起交流探讨机器学习相关内容~
0x00 前言
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。由此可见,特征工程在机器学习中占有相当重要的地位。在实际应用当中,可以说特征工程是机器学习成功的关键。
那特征工程是什么?
特征工程是利用数据领域的相关知识来创建能够使机器学习算法达到最佳性能的特征的过程。
特征工程又包含了 Data PreProcessing(数据预处理)、Feature Extraction(特征提取)、Feature Selection(特征选择)和 Feature construction(特征构造)等子问题,本章内容主要讨论特征构造的方法。

创造新的特征是一件十分困难的事情,需要丰富的专业知识和大量的时间。机器学习应用的本质基本上就是特征工程。
——Andrew Ng
之前文章已经介绍了聚合特征构造、转换特征构造、笛卡尔乘积特征构造和遗传编程特征构造,接下来将介绍怎么使用GBDT进行特征构造以及使用聚类进行特征构造。
0x01 GBDT特征构造
1.原理
GBDT 是一种常用的非线性模型,基于集成学习中 boosting 的思想,由于GBDT本身可以发现多种有区分性的特征以及特征组合,决策树的路径可以直接作为 LR 输入特征使用,省去了人工寻找特征、特征组合的步骤。所以可以将 GBDT 的叶子结点输出,作为LR的输入,如图所示:
![]()
这种通过 GBDT 生成LR特征的方式(GBDT+LR),业界已有实践(Facebook,Kaggle-2014),且效果不错,是非常值得尝试的思路。
2.关键点
1)采用ensemble决策树而非单颗树
一棵树的表达能力很弱,不足以表达多个有区分性的特征组合,多棵树的表达能力更强一些。GBDT 每棵树都在学习前面棵树尚存的不足,迭代多少次就会生成多少颗树。按 paper 以及 Kaggle 竞赛中的 GBDT+LR 融合方式,多棵树正好满足 LR 每条训练样本可以通过 GBDT 映射成多个特征的需求。
2)采用 GBDT 而非 RF
RF 也是多棵树,但从效果上有实践证明不如 GBDT。且 GBDT 前面的树,特征分裂主要体现对多数样本有区分度的特征;后面的树,主要体现的是经过前 N 颗树,残差仍然较大的少数样本。优先选用在整体上有区分度的特征,再选用针对少数样本有区分度的特征,思路更加合理,这应该也是用 GBDT 的原因。
3.实现代码
import numpy as np
import random
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.preprocessing import OneHotEncoder
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, roc_auc_score
# 生成随机数据
np.random.seed(10)
X, Y = make_classification(n_samples=1000, n_features=30)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=233, test_size=0.4)
# 训练GBDT模型
gbdt = GradientBoostingClassifier(n_estimators=10)
gbdt.fit(X_train, Y_train)
# 对GBDT预测结果进行onehot编码
onehot = OneHotEncoder()
onehot.fit(gbdt.apply(X_train)[:, :, 0])
# 训练LR模型
lr = LogisticRegression()
lr.fit(onehot.transform(gbdt.apply(X_train)[:, :, 0]), Y_train)
# 测试集预测
Y_pred = lr.predict_proba(onehot.transform(gbdt.apply(X_test)[:, :, 0]))[:, 1]
fpr, tpr, _ = roc_curve(Y_test, Y_pred)
auc = roc_auc_score(Y_test, Y_pred)
print('GradientBoosting + LogisticRegression: ', auc)
4.方案改进
在广告推荐中,广告 ID 是一个易被忽略的重要特征。采用 GBDT-LR 的方案可将其很好的利用起来。一般而言,ID 取值多且呈现长尾分布,常用作法是对一些大广告(曝光充分,样本充足)建立专属 GBDT,其它构建共用 GBDT。

5.优缺点
-
优点:GBDT 可以自动进行特征组合和离散化,LR 可以有效利用海量 id 类离散特征,保持信息的完整性。
-
缺点:LR 预测的时候需要等待 GBDT 的输出,一方面 GBDT在线预测慢于单 LR,另一方面 GBDT 目前不支持在线算法,只能以离线方式进行更新。
0x02 聚类特征构造
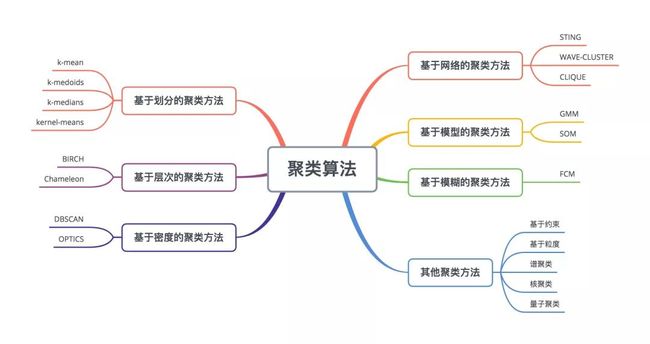
1.聚类算法介绍
俗话说:“物以类聚,人以群分”,在自然科学和社会科学中,存在着大量的分类问题。所谓类,通俗地说,就是指相似元素的集合。
聚类是把相似的对象通过静态分类的方法分成不同的组别或者更多的子集(subset),这样让在同一个子集中的成员对象都有相似的一些属性,常见的包括在坐标系中更加短的空间距离等。
常用的距离算法:
2.聚类算法构造特征流程
-
Step 1:从预处理后的特征集中选择一个或多个特征;当只选择一个数值型特征时,聚类算法构造特征相当于使用聚类算法进行特征分箱,详情可参考特征工程系列:特征预处理(上)中的《数值型特征特征分箱(数据离散化)》。
-
Step 2:选择适合聚类算法对已选择的特征进行聚类,并输出聚类类标结果;
-
Step 3:对聚类类标结果进行编码;类似 sklearn 这种机器学习库,一般聚类类标结果为一个数值,但实际上这个数值并没有大小之分,所以一般需要进行特征编码,详情可参看特征工程系列:特征预处理(下)中的《分类特征(类别特征)编码》。
3.程序实现
使用 k-mean 算法对用户兴趣爱好进行聚类
import pandas as pd
import jieba
import numpy as np
from mitie import total_word_feature_extractor
from sklearn.cluster import KMeans
from sklearn.preprocessing import OneHotEncoder
# 构造特征集
hobby = [
'健身', '电影', '音乐', '读书', '历史',
'篮球', '羽毛球', '足球',
]
df = pd.DataFrame({'兴趣': hobby})
display(df.head(20))
# 输出:
兴趣
0 健身
1 电影
2 音乐
3 读书
4 历史
5 篮球
6 羽毛球
7 足球
# 加载Embedding模型
mitie_model_filename = 'total_word_feature_extractor_zh.dat'
twfe = total_word_feature_extractor(mitie_model_filename)
# 把词语转换成embedding向量
embeding_array = np.array(list(df['兴趣'].apply(
lambda w: twfe.get_feature_vector(w))))
# k-mean距离
kmeans = KMeans(n_clusters=2, random_state=0).fit(embeding_array)
kmean_label = kmeans.labels_
print('kmeans.labels_:{}'.format(kmean_label))
# 输出:kmeans.labels_:[1 1 1 1 1 0 0 0]
kmean_label = kmean_label.reshape(-1, 1)
print('kmean_label shape={}'.format(kmean_label.shape))
# 输出:kmean_label shape=(8, 1)
# 特征编码
enc = OneHotEncoder()
onehot_code = enc.fit_transform(kmean_label)
print(onehot_code.toarray())
# 输出:
[[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[1. 0.]
[1. 0.]
[1. 0.]]
0x0FF 总结
-
GBDT 算法的特点可以用来发掘有区分度的特征、特征组合,减少特征工程中人力成本,且业界现在已有实践,GBDT+LR、GBDT+FM 等都是值得尝试的思路。不同场景,GBDT 融合 LR/FM 的思路可能会略有不同,可以多种角度尝试。
-
聚类算法在特征构造中的应用有不少,例如:
-
利用聚类算法对文本聚类,使用聚类类标结果作为输入特征;
-
利用聚类算法对单个数值特征进行聚类,相当于使用聚类算法进行特征分箱;
-
利用聚类算法对R、F、M数据进行聚类,类似RFM模型,然后再使用代表衡量客户价值的聚类类标结果作为输入特征;
预告:下一篇文章将介绍时间特征构造以及时间序列特征构造。
参考文献
-
https://machinelearning-notes.readthedocs.io/zh_CN/latest/feature/%E7%89%B9%E5%BE%81%E5%B7%A5%E7%A8%8B%E2%80%94%E2%80%94%E6%97%B6%E9%97%B4.html
-
https://www.cnblogs.com/nxf-rabbit75/p/11141944.html#_nav_12
-
https://gplearn.readthedocs.io/en/stable/examples.html#symbolic-classifier
-
利用 gplearn 进行特征工程. https://bigquant.com/community/t/topic/120709
-
Practical Lessons from Predicting Clicks on Ads at Facebook. https://pdfs.semanticscholar.org/daf9/ed5dc6c6bad5367d7fd8561527da30e9b8dd.pdf
-
Feature Tools:可自动构造机器学习特征的Python库. https://www.jiqizhixin.com/articles/2018-06-21-2
-
各种聚类算法的系统介绍和比较. https://blog.csdn.net/abc200941410128/article/details/78541273
特征工程系列文章:
特征工程系列:数据清洗
特征工程系列:特征筛选的原理与实现(上)
特征工程系列:特征筛选的原理与实现(下)
特征工程系列:特征预处理(上)
特征工程系列:特征预处理(下)
特征工程系列:特征构造之概览篇
特征工程系列:聚合特征构造以及转换特征构造
特征工程系列:笛卡尔乘积特征构造以及遗传编程特征构造