opencv dnn部署yolov5的口罩检测模型+GUI界面(三)
我训练完自己的口罩检测模型,得到了一个best.pt文件,在detect.py里运行无误后,尝试把模型导出。
yolov5官方代码的训练出来模型的权重是保存在best.pt文件里的。这个.pt后缀的模型文件并不常规,如果想要脱离训练环境部署模型,需要对原始的.pt文件进行导出操作,这里我把模型导出为onnx文件,想要用opencv的dnn模块读取该onnx模型文件进行推理,这样操作之后,整个检测过程就只需要import cv2这一个第三方库了。
yolov5官方代码已经提供了export.py函数,修改一下运行参数就支持导出为onnx。
进入这个网站Netron 查看一下网络结构。
在里面选择自己的best.pt,这里以我的口罩检测模型为例,看到网络结构如下

查看.pt文件时,每一层网络并未做展开,看着很难受。
下面执行export.py将自己的模型文件导出为onnx文件。
吹爆这位大佬的博客:用opencv的dnn模块做yolov5目标检测_nihate的专栏-CSDN博客_opencv yolov5
这里巨坑,为了opencv的dnn模块能够读取到onnx模型,需要把官方代码里的Focus函数修改为不带有切片操作的形式!!我按大佬的博客做了如下操作
修改common.py里的以下部分:
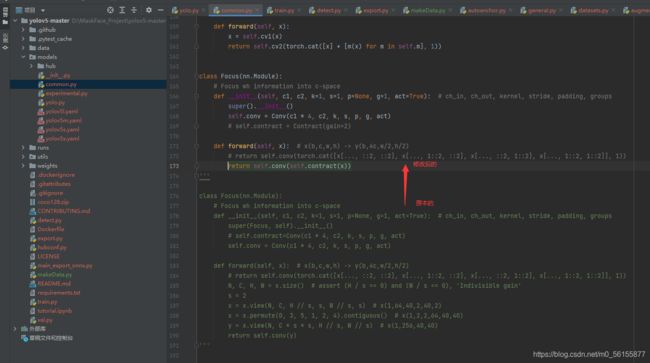
我把修改后的代码贴出来
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
# return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
return self.conv(self.contract(x))以及修改yolo.py的Detect类下面的forward:

做完这部分,就可以执行export.py将模型导出了
参数设置如下
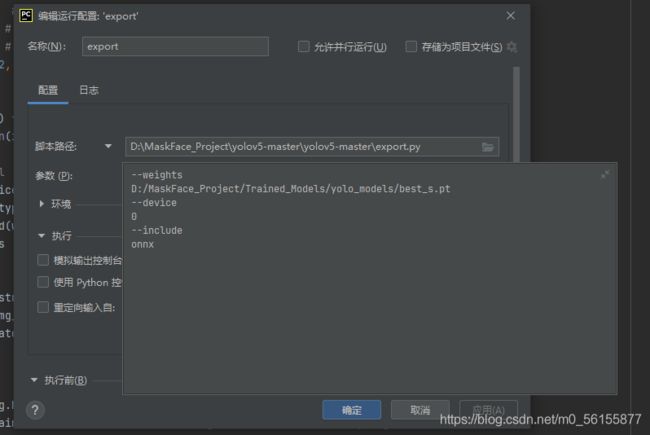
OK,到这一步就得到了onnx的模型文件了
再看看新的网络结构长啥样。
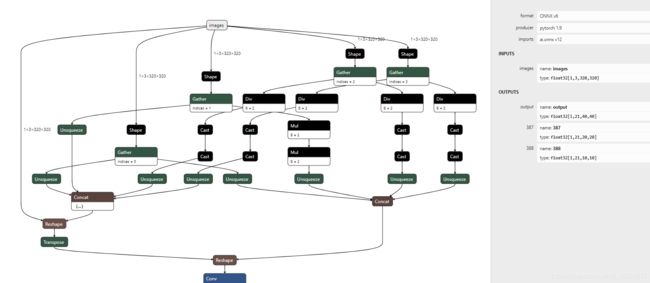
可以看到每一层的具体操作都展开出来了,原模型图太长了就只截了开头部分。
输入维度是1,3,320,320 代指1张图像,3个通道,长宽320个像素
输出维度是1,21,40,40 代指1张图像,21=3个通道*(框的5个参数+2个类别),先验框大小40×40.
其中框的5个参数分别是,类别id 长 宽 中心坐标x y,因为我做的口罩识别只有戴口罩和不戴口罩两类,所以是5+2.
理解了这些,接下来就可以重新写代码了,用opencv读取模型文件,然后复现一遍解析过程。
下一步使用python或者C++调取dnn读取导出的onnx模型,重写一遍detect,再制作一个简单的图形化界面,用pyinstaller把python版本的打包为exe文件。做成了一个桌面小程序

训练模型所用的数据集:
链接:https://pan.baidu.com/s/1gsJhY0O8FXwSdpB1gjLDOw
提取码:lu2c
训练好的模型文件:百度网盘 请输入提取码 提取码:bohd
代码已经上传到了github上。
BigCJL/Real-Time-Mask-Detect- (github.com)