数据分析——pandas(二)
pandas
DataFrame
创建DataFrame
import pandas as pd
pd.DataFrame(a)
参数a可以是多种类型,数组列表等
import pandas as pd
import numpy as np
t=pd.DataFrame(np.array(range(30)).reshape((5,6)))
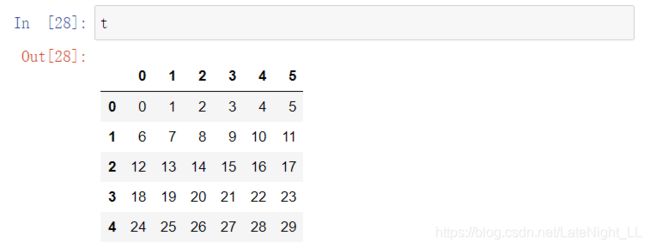
由上可以看出DataFrame对象既有行索引,又有列索引
行索引,表明不同行,叫index,0轴,axis=0
列索引,表明不同列,叫columns,1轴,axis=1
DataFrame的改变索引(轴)
因为DataFrame的构造方法支持轴参数,所以我们可以通过传入轴参数来改变DataFrame的索引
t=pd.DataFrame(np.array(range(30)).reshape((5,6)),index=list("abcde"),columns=list("!@#$%^"))
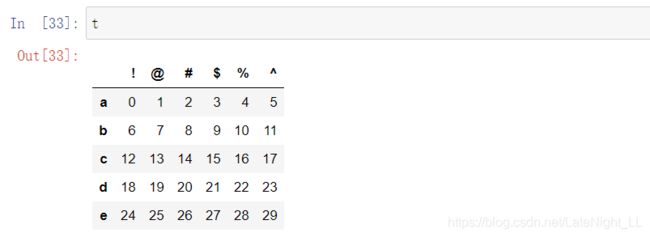
DataFrame与Series的关系
DataFrame中每列或每行单独取出,即二维中取一维,在pandas类型中就是Series类型。DataFrame是Series类型的容器。
DataFrame的基础属性
import pandas as pd
df=pd.DataFrame(a)
df.shape #行数、列数
df.dtype #列行数据类型
df.ndim #数据维度
df.index #行索引
df.columns #列索引
df.values #对象值,二维ndarray数组
DataFrame整体情况查询
import pandas as pd
df=pd.DataFrame(a)
df.head(a) #a为参数,显示头部a行,默认5行
df.tail(a) #显示末尾几行,默认5行
df.info() #相关信息概览:行数,列数,列索引,列非空值个数,列类型,内存占用
df.describe() #快速综合统计结果:计数,均值,标准差,最大值,四分位数,最小值
DataFrame中排序
df.sort_values()
#参数by为排序依据
#参数ascending为升序或降序,默认True为升序
import pandas as pd
import numpy as np
t=pd.DataFrame(np.array(range(24)).reshape((6,4)),index=list("abcdef"),columns=list("xyzp"))
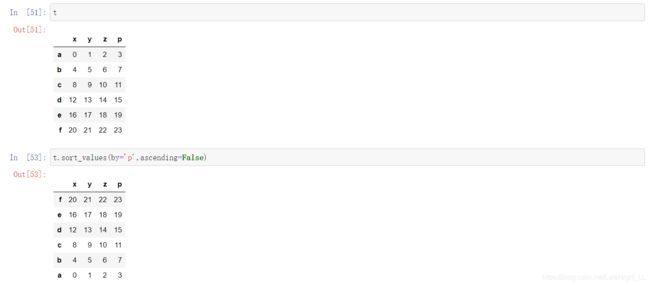
DataFrame中的索引
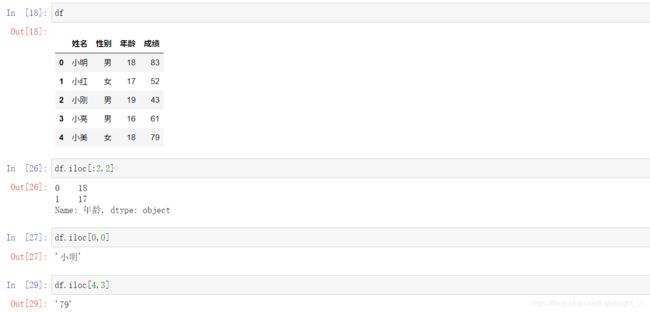
import pandas as pd
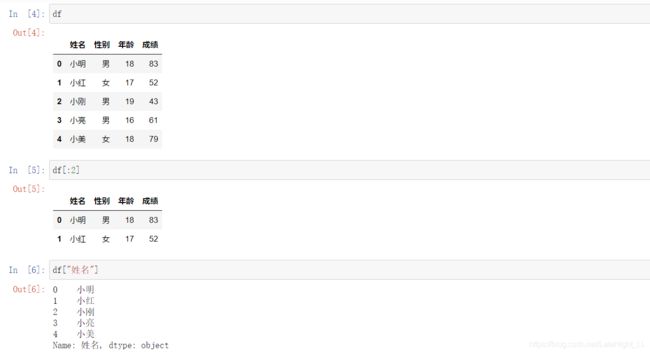
t=[{"姓名":"小明","性别":"男","年龄":"18","成绩":"83"}
,{"姓名":"小红","性别":"女","年龄":"17","成绩":"52"}
,{"姓名":"小刚","性别":"男","年龄":"19","成绩":"43"}
,{"姓名":"小亮","性别":"男","年龄":"16","成绩":"61"}
,{"姓名":"小美","性别":"女","年龄":"18","成绩":"79"}]
#若想使用大数据且不计较数据类型,建议随机生成
df=pd.DataFrame(t)

取行或取列
·方括号写数组,表示取行索引,对行进行操作
·方括号写字符串,表示取列索引,对列进行操作
·具体索引与Series相似
精确索引
我们可以利用数字加字符串来进行更精确的索引
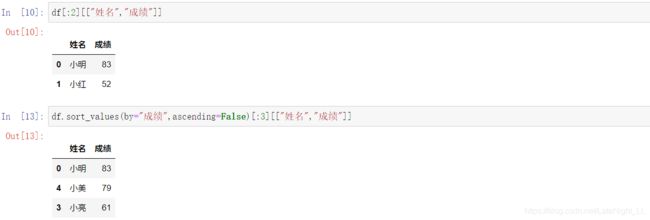
通过标签和位置进行值的精确索引
df.loc[]
#通过标签索引行数据
df.iloc[]
#通过位置获取行数据(无视轴索引)
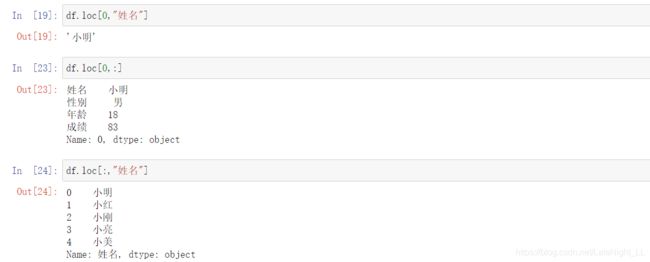
注:语法t.loc["A":"C",["W","Z"]]成立,表示索引A到C,且A、C均可取到
DataFrame同样支持布尔索引
注:
b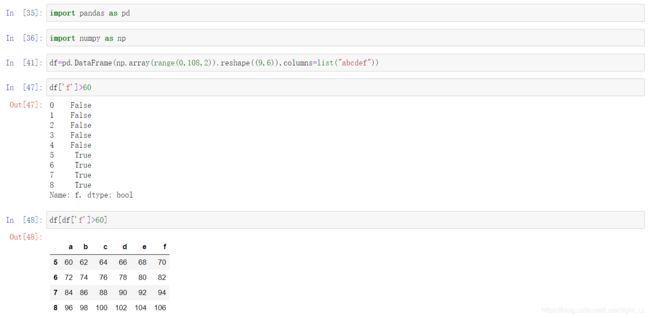
DataFrame更改数据
通过索引取值后通过赋值更改
无论存储什么类型数据的DataFrame,赋值语句df.loc[a][b]=np.nan(df具体意义参考上文)均成立,DataFrame会自动转化数据类型
pandas的字符串方法
|
缺失数据的处理
在pandas中我们处理起来非常容易
对于NaN:
判断数据是否为NaN:pd.isnull(df),pd.notnull(df),pd,df同上
处理方式1:删除NaN所在的行列dropna(axis=0,how='any',inplace=False)(参数axis决定删除行还是列,how默认为any,决定删除含多少NaN的行列,其他赋值还有“all”)
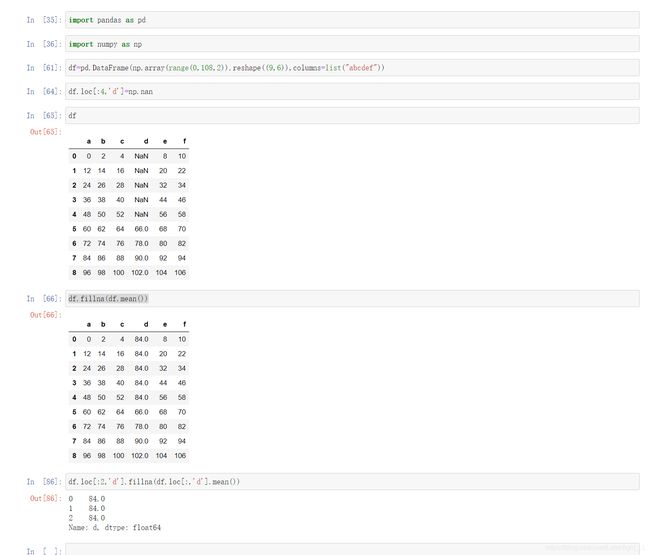
处理方式2:填充数据,t.fillna(t.mean())(填充均值),t.fillna(t.median())(填充中值),t.fillna(0),
单独某行列填充t[行/列].fillna(t[行/列].mean())
注:要注意数据类型,字符串无法进行加减乘除
对于0:
当然不是每次为零的数据都要处理
t[t==0]=np.nan