Multi-task Learning and Beyond: 过去,现在与未来
本文经授权转载自知乎
标题:Multi-task Learning and Beyond: 过去,现在与未来
原文:https://zhuanlan.zhihu.com/p/138597214
作者:刘诗昆
目录
Multi-task Learning 的两大研究分支
Multi-task Learning Loss Function Design / How to learn? [损失函数设计与梯度优化]
Auxiliary Learning -- Not all tasks are created equal [辅助学习]
总结
近期 Multi-task Learning (MTL) 的研究进展有着众多的科研突破,和许多有趣新方向的探索。这激起了我极大的兴趣来写一篇新文章,尝试概括并总结近期 MTL 的研究进展,并探索未来对于 MTL 研究其他方向的可能。
这篇文章将顺着我 18 年硕士论文:Universal Representations: Towards Multi-Task Learning & Beyond 的大体框架,并加以补充近期新文章的方法,和未来新方向的讨论。
Disclaimer: 在硕士论文里提及的自己的文章均为当时未发表的 preliminary results,对于任何人想要了解论文里的细节请直接参看发表的 conference 文章。
Multi-task Learning 的两大研究分支
在绝大部分情况下,MTL 的研究可以归类为以下两个方向,一个是 MTL Network 网络设计;另一个是 MTL Loss function 损失函数设计。我们以下对于这两个方向进行详细解读。
Multi-task Learning Network Design / What to share? [网络设计]
在起初,MTL 的网络设计通常可以列为两种情况:Hard parameter sharing 和 soft parameter sharing。

Hard-parameter sharing -- 现在是几乎所有做 MTL 不可缺少的 baseline 之一,就是将整个 backbone 网络作为 shared network 来 encode 任务信息,在最后一层网络 split 成几个 task-specific decoders 做 prediction。Hard-parameter sharing 是网络设计参数数量 parameter space 的 (并不严格的,假设不考虑用 network pruning) lower bound,由此作为判断新设计网络对于 efficiency v.s. accuracy 平衡的重要参考对象。
Soft-parameter sharing -- 可以看做是 hard-parameter sharing 的另外一个极端,并不常见于现在 MTL 网络设计的比较。在 soft-parameter sharing 中,每一个任务都有其相同大小的 backbone network 作为 parameter space。我们对于其 parameter space 加于特定的 constraint 可以是 sparsity, 或 gradient similarity, 或 LASSO penalty 来 softly* constrain 不同任务网络的 representation space。假设我们不对于 parameter space 加以任何 constraint,那么 soft-parameter sharing 将塌缩成 single task learning。
任一 MTL 网络设计可以看做是找 hard 和 soft parameter sharing 的平衡点:1. 如何网络设计可以小巧轻便。2. 如何网络设计可以最大幅度的让不同任务去共享信息。
MTL network design is all about sharing.
- Cross-Stitch Network
Cross-Stitch Network 是过去几年内比较经典的网络设计,也已常用于各类 MTL 研究的baseline 之一。其核心思想是将每个独立的 task-specific 网络使用 learnable parameters (cross-stitch units) 以 linear combination 的方式连接其中不同任务的 convolutional blocks。
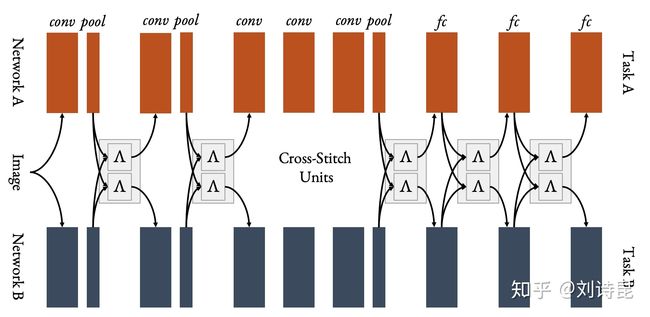 Visualisation of Cross-Stitch Networ
Visualisation of Cross-Stitch Networ

启发于 Cross-stitch 的设计,NDDR-CNN 也有类似的思路。然而不同的是,对于中间层的 convolutional block 的信息融合,他们采用了 concatenate 并通过 [1 x 1] 的 convolutional layer 来 reduce dimensionality。 这样的设计使得每个任务的 channel 都可以与其他不同 index 的 channel 交融信息,而规避了原始 Cross-stitch 只能 infuse 相同 channel 信息的局限性。当 NDDR 的 convolutional layer weights 的 non-diagonal elements 是 0 的话, NDDR-CNN 则数学上等价于 Cross-Stich Network。
Cross-Stitch Network 和 NDDR-CNN 的最大弱势就是对于每个任务都需要一个新的网络,以此整个 parameter space 会对于任务的数量增加而线性增加,因此并不 efficient。
- Multi-task Attention Network
基于 Cross-stitch Network efficiency 的缺点,我后续提出了 Multi-task Attention Network (MTAN) 让网络设计更加小巧轻便,整个网络的 parameter space 对于任务数量的增加以 sub-linearly 的方式增加。

MTAN 的核心思想是,assume 在 shared network encode 得到 general representation 信息之后,我们只需要少量的参数来 refine task-shared representation into task-specific representation, 就可以对于任意任务得到一个很好的 representation. 因此整个网络只需要增加少量的 task-specific attention module,两层 [1 x 1] conv layer,作为额外的 parameter space 来 attend 到 task-shared represenation。整个模型的参数相对于 Cross-Stitch Network 来说则大量减少。
AdaShare
AdaShare 则更是将 MTL 网络设计的 efficiency 做到的极致。与其增加额外的 conv layer 来 refine task-shared representation,AdaShare 将单个 backbone 网络看做 representation 的整体,通过 differentiable task-specific policy 来决定对于任何一个 task,否用去更新或者利用这个网络的 block 的 representation。
 Visualisation of AdaShare
Visualisation of AdaShare
由于整个网络是应用于所有任务的 representation,因此 network parameter space 是 agnostic 于任务数量,永远为常数,等价于 hard-parameter sharing。而搭接的 task-specific policy 是利用 gumbel-softmax 对于每一个 conv block 来 categorical sampling "select" 或者 "skip" 两种 policy,因为整个 MTL 的网络设计也因此会随着任务的不同而变化,类似于最近大火的 Neural Architecture Search 的思想。
- MTL + NAS
MTL-NAS 则是将 MTL 和 NAS 结合的另外一个例子。他搭载于 NDDR 的核心思想,将其拓展到任意 block 的交融,因此网络搜索于如何将不同 task 的不同 block 交融来获得最好的 performance。
 Visualisation of MTL-NAS
Visualisation of MTL-NAS
我个人更偏向 Adashare 的搜索方式,在单个网络里逐层搜索,这样的 task-specific representation 已经足够好过将每一个 task 定义成新网络的结果。由此, MTL-NAS 也躲不掉网络参数线性增加的特点,不过对于 MTL 网络设计提供了新思路。
MTL + NAS 和传统的 single-task NAS 会有着不同需求,和训练方式。
- MTL+NAS 并不适合用 NAS 里最常见的 two-stage training 方式:以 validation performance 作为 supervision 来 update architecture 参数,得到 converged architecture 后再 re-train 整个网络。因为 MTL 的交融信息具备 training-adaptive 的性质, 因此 fix 网络结构后,这样的 training-adaptive 信息会丢失,得到的 performance 会低于边搜边收敛的 one-stage 方式。换句话说,训练中的 oscillation 和 feature fusion 对于 MTL 网络是更重要的,而在 single task learning 中,并没有 feature fusion 这个概念。这间接导致了 NAS 训练方式的需求不同。
- MTL+NAS is task-specific. 在 NAS 训练中,要是 dataset 的 complexity 过大,有时候我们会采用 proxy task 的方式来加快训练速度。最常见的情况则是用 CIFAR-10 作为 proxy dataset 来搜好的网络结构,应用于过大的 ImageNet dataset。而这一方式并不适用于 MTL,因为对于任一任务,或者几个任务的 pair,他们所需要的 feature 信息和任务特性并不同,因此无法通过 proxy task 的方式来加速训练。每一组任务的网络都是独特和唯一的。
我相信在未来 MTL 网络设计的研究中,我们会得到更具备 interpretable/human-understandable 的网络特性,能够理解任务与任务之间的相关性,和复杂性。再通过得到的任务相关性,我们可以作为一个很好 prior knowledge 去 initialise 一个更好的起始网络,而由此得到一个更优秀的模型,一种良性循环。
A better Task Relationship <==> A better Mutil-task Architecture
Multi-task Learning Loss Function Design / How to learn? [损失函数设计与梯度优化]
平行于网络设计,另外一个较为热门的方向是 MTL 的 loss function design, 或者理解为如何去更好得 update 网络里的 task-specific gradients。
鉴于该部分含有较多公式,因此,详细内容请见原文:[刘诗昆] Multi-task Learning and Beyond: 过去,现在与未来,
Auxiliary Learning -- Not all tasks are created equal [辅助学习]
跟 MTL 高度相关的一个方向被称之为 Auxiliary learning (AL, 辅助学习):他的训练过程与 MTL 完全一致。唯一的不同是,在 Auxiliary Learning 里,只有部分任务的 performance 是需要被考虑的 (primary task),其他(辅助)任务 (auxiliary task) 的存在的意义是,帮助那部分需要被考虑的任务学习到更好的 representation。
- Supervised Auxiliary Learning
Auxiliary Learning 存在的普遍性其实远超于我们的想象。比如,MTL 其实就是一种特殊形式的 AL,我们可以把其中任意一个 task 作为 primary task,其他剩余的 task 看作为 auxiliary task。在 MTL 里,我们默认所有 task 与 task 存在一种 mutual beneficial 的关系,因此所有 learning tasks 都 benefit 到这种相关性。
Auxiliary Learning 还应用在很多领域里,比如 这篇文章 发现在训练 depth 和 normal prediction 的同时,可以有效的帮助 object detection 的精确度。或者 这篇文章 发现在做 short sequence 的重建时,可以帮助 RNN 更有效的训练 very long sequence。
在 supervised auxiliary learning 的 setting 中,整个网络和任务的选择非常依赖于人类的先验知识,并不具备绝对的普遍性。
- Meta Auxiliary Learning
考虑 supervised auxiliary learning 对于任务选择的局限性,我后续提出了一种基于 meta learning 的方法来自动生成 auxiliary task,我把这种方法称之为 Meta Auxiliary Learning (MAXL)。
在传统的 supervised auxiliary learning,我发现有这样如下两个规律:
- 假设 primary 和 auxiliary task 是在同一个 domain,那么 primary task 的 performance 会提高当且仅当 auxiliary task 的 complexity 高于 primary task。
- 假设 primary 和 auxiliary task 是在同一个 domain,那么 primary task 的最终 performance 只依赖于 complexity 最高的 auxiliary task。
这里对于 task 的 complexity 的定义比较 tricky 并不 general,目前我只考虑了最简单的图片分类的情况:细分类任务的 complexity 是高于粗分类任务。
比如在下图,我们看到猫,狗两类的分类的信息,直觉上一定低于细分类,约克夏,波斯猫之类更为细节的信息。而分类猫狗所需要的信息是分类细分类的子集,因此得出了规律 2.

再由于规律 2,我们只需要考虑最简单的两个任务训练的情况: primary task 和 auxiliary task 各为一个任务。因此在这里,我们”生成“一个好的 auxiliary task的问题,也就可转化为对任意输入图片,我们需要有一个好的网络去生成好的细分类标签。
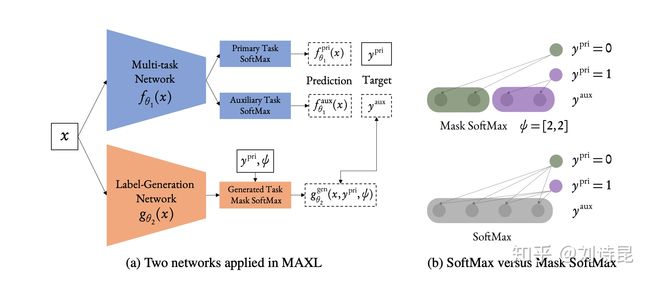
因此在 MAXL 框架里,我们有两个网络:一个网络是 multi-task network 类同于 hard parameter sharing 来做 multi-task training。另外一个网络是 label-generation network 来生成细分类标签,给 multi-task network 作为 auxiliary task 的 prediction label。

在 label-generation network 里还存在一个 hyper-parameter φ 代表人类定义的 dataset hierarchy。 假设我们在做简单的二分类,那么 φ=【2,3】 则意味着将第一个类再细分成 2 类,第二个类再细分成 3 类。那么 label-generation network 就以这样的 hierarchy 通过 masked version of softmax 来生成相应的合适的 auxiliary label。于是 multi-task network 就在进行两个分类任务: primary task 是二分类,auxilairy task 是五分类。
通过 MAXL,我们发现他可以对这样的图片分类任务有着一定的效果提升。我们后续 visualize 生成的标签,发现在一些简单的数据集里有着人类可理解的 clustering 含义。

在上图中,上半部分是 CIFAR-100 的分类,下半部分是 MNIST 的分类。其中这三类 auxiliary class 中的图片是通过 label-generation network 生成在这个 class 里 5 个 confidence 最高的图片。
在较为复杂的 CIFAR-100 数据集中,我们很难理解 MAXL 的分类到底在干什么。而在 MNIST 中,我们可以发现 不同粗细的 数字 3,不同方向的 数字 9,有无中间的 horizontal bar 的数字 7 cluster 到了一起。这种有趣的现象开拓了一个新颖的方向,对自动化辅助任务生成的探索。
总结
终于到总结了!近些年来 MTL 的研究出现了很多新颖且有价值的工作,但是对于任务自身的理解,和任务之间关系的理解还是有很大的不足和进步空间。在 Taskonomy 里,作者尝试了上千种(大量 CO2 排放)任务的组合来绘制出不同任务之间的关系图。但是真实 MTL 训练中,我相信这种关系图应该随着时间的变化而变化,且依赖网络本身。因此,如何更好得通过任务之间的关系去优化网络结构还是一个未解之谜,如何设计/生成辅助任务并通过 MTL 更好得帮助 primary task 也并未了解透彻。希望在后续的研究中能看到更多文章对于 MTL 的深入探索,实现 universal representation 的最终愿景。