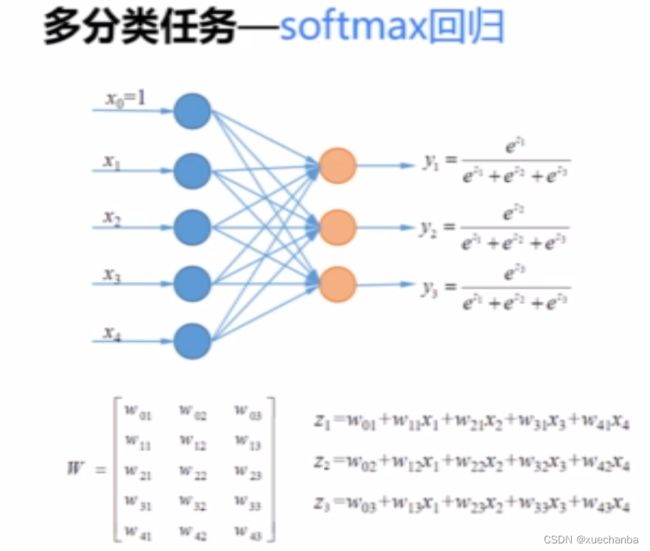
实现多分类
课程回顾:
我们知道,可以采用softmax回归来实现多分类问题。例如,输入鸢尾花的花瓣长度和宽度。首先经过线性运算后,再使用 softmax 函数作为激活函数,就可以得到这个样本属于每种类别鸢尾花的概率。
此外,在机器学习中,通常采用独热编码的方式来表示类别标签,

使用多分类交叉熵损失函数计算预测值和标签值之间的误差。

以上这些也是编程实现多分类问题时,需要注意的与二分类程序的不同之处,另外,在多分类任务中,计算模型的分类准确率也比二分类更复杂一些。
首先,我们使用 TensorFlow 来实现以上这四个步骤的关键函数或代码段。
在 TensorFlow 中实现独热编码
在 TensorFlow 中,提供了 one_hot 函数来实现独热编码,
one_hot(indices, depth)
第一个参数 indices 是输入值,要求是一维数组或者张量。第二个参数depth是编码深度,也就是编码的位数。
例如:
import tensorflow as tf
a = [0, 2, 3, 5] # 可以取到 0、1、2、3、4、5
b = tf.one_hot(a, 6) # 对其进行独立编码, 编码深度就应该是 6
print(b) # 分别对应 a 中每个元素的独立编码
"""
tf.Tensor(
[[1. 0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0.]
[0. 0. 0. 1. 0. 0.]
[0. 0. 0. 0. 0. 1.]], shape=(4, 6), dtype=float32)
"""
在鸢尾花数据集中,
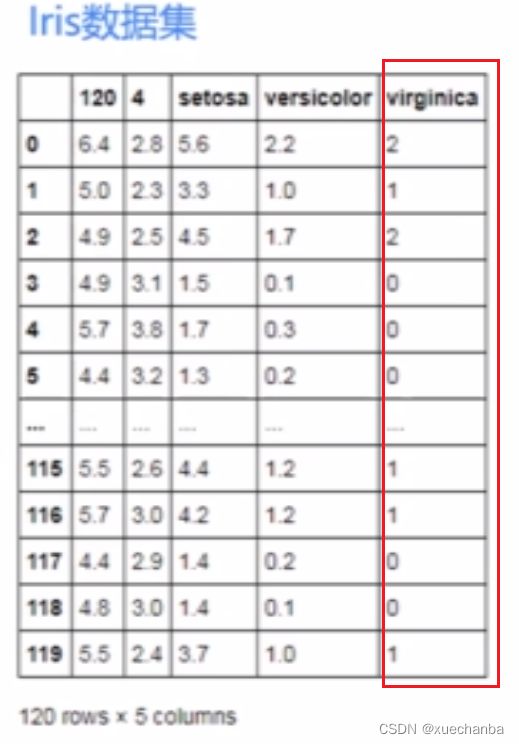
最后一列是标签值,鸢尾花的类别。
从训练集中取出这一列,把它放在一个一维数组中,然后使用 one_hot 函数把它转换为独热编码的形式。因为一共有三种类型的鸢尾花,因此,独热编码的深度为3,在转换为独热编码之前,首先要将其转化为张量。
# 取出标签值
y_train =iris_train[:, 4]
# 转换为独热编码
Y_train = tf.one_hot(tf.constant(y_train, dtype=tf.int32), 3)
在上节课中,我们对softmax函数进行了详细的推导和解释。简单地说,softmax函数是一种更加soft的方式,标记出数组中每个元素成为最大数的概率。
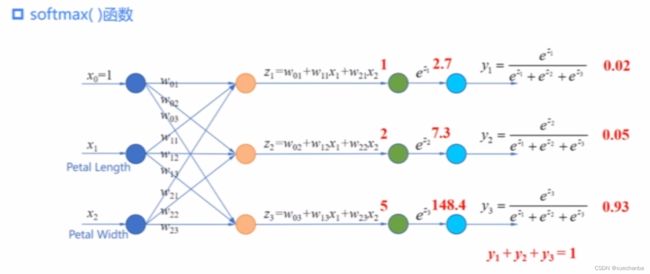
TensorFlow 的 nn 模块中 tf.nn.softmax 函数
下面使用 TensorFlow 的 nn 模块中 tf.nn.softmax 函数来实现上图中的例子,
import numpy as np
import tensorflow as tf
print(tf.nn.softmax([1.0, 2.0, 5.0]))
"""
tf.Tensor([0.01714783 0.04661262 0.93623954], shape=(3,), dtype=float32)
"""
# round()函数可以完成对数字的四舍五入计算。
print(np.round(tf.nn.softmax([1.0, 2.0, 5.0]), 2))
"""
[0.02 0.05 0.94]
"""
TensorFlow 的 nn 模块中 tf.nn.softmax 函数
PRED_train = tf.nn.softmax(tf.matmul(X_train, W))
其中,X_train 是鸢尾花训练集中的属性矩阵,W 是模型参数矩阵。它们先经过线性变换 XTW,
(这里需要说明一下)
鸢尾花训练集中有120个样本,四个属性,加上x0(全一数组),因此矩阵X_train 是 (120,5),而 W 是上面提到的
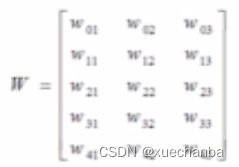
即 (5,3),因此,
tf.matmul(X_train, W)
后,是 (120,3),再使用 softmax 函数,就可以得到每个样本的预测值的分类概率。对每一行求和,结果都约等于1。

交叉熵损失函数

用来计算标签值和损失值之间的误差。
下图为独热编码形式的标签值和预测值:
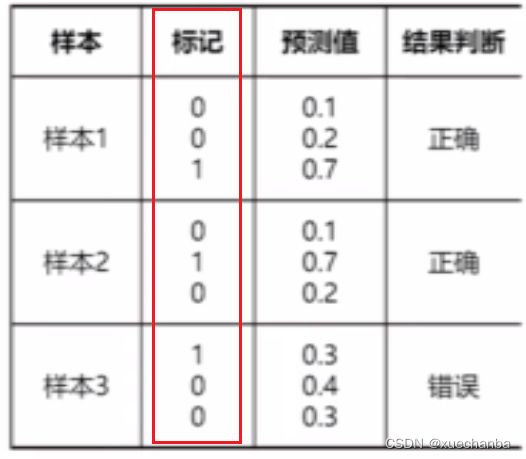
对于每一个样本,计算它的交叉熵损失,并对它们求和,结果如下:

实例:
import numpy as np
import tensorflow as tf
y = np.array([2, 1, 0]) # 分别为 3 个样本的标签值
y_onehot = np.array([[0, 0, 1],
[0, 1, 0],
[0, 0, 1]]) # 将三个样本转化为独热编码后的标签值
pred = np.array([[0.1, 0.2, 0.7],
[0.1, 0.7, 0.2],
[0.3, 0.4, 0.3]]) # 每个样本预测的概率值
# 得到每一个样本的交叉熵损失
print(-y_onehot*tf.math.log(pred))
"""
tf.Tensor(
[[-0. -0. 0.35667494]
[-0. 0.35667494 -0. ]
[-0. -0. 1.2039728 ]], shape=(3, 3), dtype=float64)
"""
# 得到所有样本总的交叉熵损失
print(-tf.reduce_sum(-y_onehot*tf.math.log(pred)))
"""
tf.Tensor(-1.917322692203401, shape=(), dtype=float64)
"""
# 得到平均交叉熵损失
print(-tf.reduce_sum(-y_onehot*tf.math.log(pred))/len(pred))
"""
tf.Tensor(-0.6391075640678003, shape=(), dtype=float64)
"""
要注意,交叉熵损失函数的计算公式前面有一个负号,在编程时不能忘记。
准确率


应该如何使用TensorFlow中的函数来计算正确分类的样本数呢?
为了方便比较,我们会首先将每个样本的概率值转换为自然顺序码的形式,然后再逐个元素进行比较预测值和标签值,看它们是否一致,如果一致,结果为1,如果不一致,结果就为0。最后,将所有的1都给加起来,再除以样本总数就可以了。
实现如下:
import numpy as np
import tensorflow as tf
y = np.array([2, 1, 0]) # 分别为 3 个样本的标签值
y_onehot = np.array([[0, 0, 1],
[0, 1, 0],
[0, 0, 1]]) # 将三个样本转化为独热编码后的标签值
pred = np.array([[0.1, 0.2, 0.7],
[0.1, 0.7, 0.2],
[0.3, 0.4, 0.3]]) # 每个样本预测的概率值
# axis=1 表示对每一行元素求最大索引
print(tf.argmax(pred, axis=1))
# tf.Tensor([2 1 1], shape=(3,), dtype=int64)
print(tf.equal(tf.argmax(pred, axis=1), y))
# tf.Tensor([ True True False], shape=(3,), dtype=bool)
print(tf.cast(tf.equal(tf.argmax(pred, axis=1), y), tf.float32))
# tf.Tensor([1. 1. 0.], shape=(3,), dtype=float32)
print(tf.reduce_mean(tf.cast(tf.equal(tf.argmax(pred, axis=1), y), tf.float32)))
# tf.Tensor(0.6666667, shape=(), dtype=float32)
使用花瓣长度、花瓣宽度将三种鸢尾花区分开
import pandas as pd
import numpy as np
import tensorflow as tf
import matplotlib as mpl
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = "SimHei"
plt.rcParams['axes.unicode_minus'] = False
# 目标:使用花瓣长度、花瓣宽度将三种鸢尾花区分开
# 第一步:加载数据集
TRAIN_URL = "http://download.tensorflow.org/data/iris_training.csv"
train_path = tf.keras.utils.get_file(TRAIN_URL.split('/')[-1], TRAIN_URL)
df_iris_train = pd.read_csv(train_path, header=0) # 表示第一行数据作为列标题
TEST_URL = "http://download.tensorflow.org/data/iris_test.csv"
test_path = tf.keras.utils.get_file(TEST_URL.split('/')[-1], TEST_URL)
df_iris_test = pd.read_csv(test_path, header=0)
# 第二步:数据处理
# 2.1 转化为NumPy数组
iris_train = np.array(df_iris_train) # 将二维数据表转换为 Numpy 数组, (120, 5), iris的训练集中有120条样本,
iris_test = np.array(df_iris_test) # 将二维数据表转换为 Numpy 数组, (30, 5), iris的测试集中有30条样本,
# 2.2 提取属性和标签
train_x = iris_train[:, 2:4] # 取出鸢尾花训练数据集中属性值为花瓣长度、花瓣宽度的列
train_y = iris_train[:, 4] # 取出最后一列作为标签值, (120,)
test_x = iris_test[:, 2:4] # 取出鸢尾花训练数据集中属性值为花瓣长度、花瓣宽度的列
test_y = iris_test[:, 4] # 取出最后一列作为标签值, (30, )
# 2.3 记录训练集和测试集中的样本总数, 方便用于计算平均交叉熵损失值
num_train = len(train_x) # 120
num_test = len(test_x) # 30
# 2.4 生成多元模型的属性矩阵和标签列向量
x0_train = np.ones(num_train).reshape(-1, 1) # (120, 1)
# 改变张量中元素的数据类型函数 tf.cast()
# 拼接就是将多个张量在某个维度上合并,在TensorFlow中使
# 用tf.concat()函数来拼接张量, 拼接并不会产生新的维度。
X_train = tf.cast(tf.concat([x0_train, train_x], axis=1), tf.float32)
# 创建张量函数tf.constant()
Y_train = tf.one_hot(tf.constant(train_y, dtype=tf.int32), 3) # 将标签值转换为独热编码的形式
print(X_train.shape) # (120, 3)
print(Y_train.shape) # (120, 3)
x0_test = np.ones(num_test).reshape(-1, 1) # (22, 1)
# 改变张量中元素的数据类型函数 tf.cast()
# 拼接就是将多个张量在某个维度上合并,在TensorFlow中使
# 用tf.concat()函数来拼接张量, 拼接并不会产生新的维度。
X_test = tf.cast(tf.concat([x0_test, test_x], axis=1), tf.float32)
# 创建张量函数tf.constant()
Y_test = tf.one_hot(tf.constant(test_y, dtype=tf.int32), 3)
print(X_test.shape) # (30, 3)
print(Y_test.shape) # (30, 3)
# 第三步:设置超参数和显示间隔
learn_rate = 0.2
itar = 500
display_step = 100
# 第四步:设置模型参数初始值
np.random.seed(612)
# 这里的W是一个(3, 3) 的矩阵
W = tf.Variable(np.random.randn(3, 3), dtype=tf.float32)
# 第五步:训练模型
cross_train = [] # 列表cross_train用来保存每一次迭代的交叉熵损失
acc_train = [] # 用来存放训练集的分类准确率
cross_test = [] # 列表cross_test用来保存每一次迭代的交叉熵损失
acc_test = [] # 用来存放测试集的分类准确率
for i in range(0, itar + 1):
with tf.GradientTape() as tape:
# softmax 函数
# X - (120, 3), W - (3, 3) , 所以 Pred_train - (120, 3), 是每个样本的预测概率
Pred_train = tf.nn.softmax(tf.matmul(X_train, W))
# 计算训练集的平均交叉熵损失函数
Loss_train = -tf.reduce_sum(Y_train * tf.math.log(Pred_train))/num_train
Pred_test = tf.nn.softmax(tf.matmul(X_test, W))
# 计算平均交叉熵损失函数
Loss_test = -tf.reduce_sum(Y_test * tf.math.log(Pred_test))/num_test
# 计算准确率函数 -- 因为不需要对其进行求导运算, 因此也可以把这条语句写在 with 语句的外面
Accuarcy_train = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(Pred_train.numpy(), axis=1), train_y), tf.float32))
Accuarcy_test = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(Pred_test.numpy(), axis=1), test_y), tf.float32))
# 记录每一次迭代的交叉熵损失和准确率
cross_train.append(Loss_train)
cross_test.append(Loss_test)
acc_train.append(Accuarcy_train)
acc_test.append(Accuarcy_test)
# 对交叉熵损失函数W求偏导
dL_dW = tape.gradient(Loss_train, W)
# 更新模型参数
W.assign_sub(learn_rate * dL_dW)
if i % display_step == 0:
print("i: %i, TrainLoss: %f, TrainAccuracy: %f, TestLoss: %f, TestAccuracy: %f"
% (i, Loss_train, Accuarcy_train, Loss_test, Accuarcy_test))
运行结果如下:

最后,显示训练结果。
# 第六步:显示训练结果
print(Pred_train.shape) # (120, 3)
print(Pred_test.shape) # (30, 3)
print(tf.reduce_sum(Pred_train, axis=1))
"""
tf.Tensor(
[1. 0.99999994 1. 0.9999999 1. 0.99999994
1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 0.99999994 0.9999999
1. 1. 1. 1. 1. 0.99999994
1. 1. 1. 1.0000001 1. 1.
1. 1. 1. 1. 1. 0.99999994
1. 1. 1. 1.0000001 1. 1.
1. 1. 1. 1. 1. 1.
1. 0.9999999 1.0000001 1. 1. 1.
1. 1. 1. 1. 1. 1.
0.9999999 0.99999994 1. 1. 1. 1.
0.99999994 0.99999994 1. 1. 0.99999994 1.
0.99999994 1. 1. 0.9999999 0.99999994 1.
1. 1. 1. 1. 1. 1.
0.99999994 0.9999999 1.0000001 0.9999999 0.99999994 1.
0.99999994 1.0000001 1.0000001 1. 1. 1.0000001
1.0000001 1. 1. 1. 1.0000001 0.99999994
1. 1. 1. 1.0000001 1. 1.0000001
1. 1. 1. 1. 1. 1.
0.99999994 1.0000001 1. 1.0000001 1. 1.0000001 ], shape=(120,), dtype=float32)
"""
print(tf.reduce_sum(Pred_test, axis=1))
"""
tf.Tensor(
[1. 1. 1. 1. 1. 1.
1.0000001 1. 1. 1. 1. 1.
0.99999994 1. 1. 1.0000001 1. 0.99999994
1. 1.0000001 0.99999994 1. 1. 1.
1. 1. 0.9999999 1. 1. 1. ], shape=(30,), dtype=float32)
"""
为了便于观察,可以使用 argmax函数将预测结果转换为自然顺序码。
print(tf.argmax(Pred_train.numpy(), axis=1))
"""
tf.Tensor(
[2 1 2 0 0 0 0 2 1 0 1 1 0 0 2 2 2 2 2 0 2 2 0 1 1 0 1 2 1 2 1 1 1 2 2 2 2
2 0 0 2 2 2 0 0 1 0 2 0 2 0 1 1 0 1 2 2 2 2 1 1 2 2 2 1 2 0 2 2 0 0 1 0 2
2 0 1 1 1 2 0 1 1 1 2 0 1 1 2 0 2 1 0 0 2 0 0 2 2 0 0 1 0 1 0 0 0 0 1 0 2
1 0 2 0 1 1 0 0 1], shape=(120,), dtype=int64)
"""
print(tf.argmax(Pred_test.numpy(), axis=1))
"""
tf.Tensor([2 2 0 2 1 1 0 1 1 2 2 0 2 1 1 0 1 0 0 2 0 1 2 1 1 1 0 1 2 1], shape=(30,), dtype=int64)
"""
最后,绘制分类图,
# 第七步:绘制分区图
def mesh(M, data_x, data_y, xlimin=0.8, xlimax=7.0, ylimin=0.0, ylimax=2.65, meshtitle='分区图'):
# M = 500
x1_min, x2_min = data_x.min(axis=0)
x1_max, x2_max = data_x.max(axis=0)
t1 = np.linspace(x1_min, x1_max, M)
t2 = np.linspace(x2_min, x2_max, M)
m1, m2 = np.meshgrid(t1, t2)
# 生成多元线性模型需要的属性矩阵
m0 = np.ones(M * M) # 生成元素全为1的一位数组
# 在TensorFlow中使用tf.stack函数来实现张量的堆叠。
# 函数:tf.stack(values,axis)
# 合并张量时,创建一个新的维度。
X_mesh = tf.cast(np.stack((m0, m1.reshape(-1), m2.reshape(-1)), axis=1), dtype=tf.float32)
print(X_mesh.shape) # (250000, 3)
# 计算所有网格点对应的函数值
Y_mesh = tf.nn.softmax(tf.matmul(X_mesh, W)) # (250000, 3)
print(Y_mesh)
"""
tf.Tensor(
[[0.9625287 0.03633044 0.00114083]
[0.9625287 0.03633044 0.00114083]
[0.9625287 0.03633044 0.00114083]
...
[0.9625287 0.03633044 0.00114083]
[0.9625287 0.03633044 0.00114083]
[0.9625287 0.03633044 0.00114083]], shape=(250000, 3), dtype=float32)
"""
# 把它们转化为自然顺序码表示的类别, 作为填充颜色的依据
Y_mesh = tf.argmax(Y_mesh.numpy(), axis=1)
print(Y_mesh)
"""
tf.Tensor([0 0 0 ... 0 0 0], shape=(250000,), dtype=int64)
"""
# 对其进行维度变化,让它和 m1 和 m2 具有相同的形状
# 这是 pcolormesh 函数对参数的要求
n = tf.reshape(Y_mesh, m1.shape)
print(n)
"""
tf.Tensor(
[[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
...
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]], shape=(500, 500), dtype=int64)
"""
plt.figure(figsize=(12, 9))
cm_pt = mpl.colors.ListedColormap(["blue", "red", "green"])
cm_bg = mpl.colors.ListedColormap(["#A0FFA0", "#FFA0A0", "#A0A0FF"])
plt.suptitle(f"{meshtitle}", fontsize=20,color="red", backgroundcolor="yellow")
plt.xlim(xlimin, xlimax)
plt.ylim(ylimin, ylimax)
plt.pcolormesh(m1, m2, n, cmap=cm_bg)
plt.scatter(data_x[:, 0], data_x[:, 1], c=data_y, cmap=cm_pt)
# 需要注意的是,plt 中的绘图是有层次的,这里要首先绘制分区图作为背景。
# 然后,在它的上面绘制散点图。否则散点图会被分区图遮盖住。
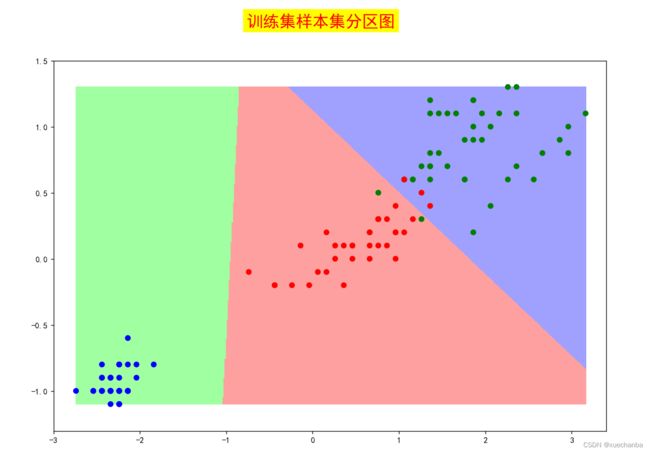
mesh(500, train_x, train_y, meshtitle="训练集样本集分区图")
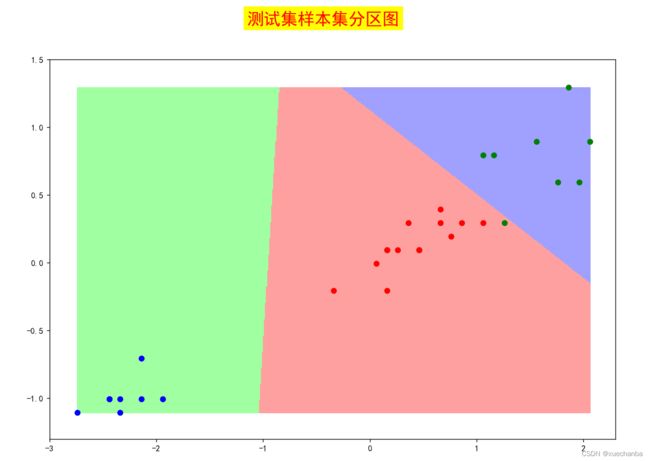
mesh(500, test_x, test_y, xlimax=6.0, meshtitle="测试集样本集分区图")
plt.show()
运行结果如下:


在上面程序中,并没有对训练集和测试集的数据进行中心化处理,我认为应该对它们进行中心化处理。
应该在 2.2 或者 2.3 步骤后面加上中心化处理
# 可以看出这两个属性的尺寸相同,因此不需要进行归一化,可以直接对其进行中心化处理
# 对每个属性进行中心化, 也就是按列中心化, 所以使用下面这种方式
train_x = train_x - np.mean(train_x, axis=0)
test_x = test_x - np.mean(test_x, axis=0)
# 此时样本点的横坐标和纵坐标的均值都是0
这样在最后绘制分区图的时候,还要对坐标轴重新进行调整,从而使得样本点显示完全。
运行结果如下: