PyTorch 07—计算机视觉基础
卷积神经网络(CNN)简介
前面我们讲解了机器学习基础知识,包括多层感知器等问题。下面我们要介绍的目标识别与分类,就是在前面问题的基础上进行扩展,实现对于图像等分类和识别。实现对图像的高准确率识别离不开一种叫做卷积神经网络的深度学习技术。卷积神经网络主要应用于计算机视觉相关任务,但它能处理的任务并不局限于图像,其实语音识别也是可以使用卷积神经网络。
接下来,我们将专注于在使用卷积神经网络(CNN)来处理图像。我们将使用识别Mnist手写数字、四种天气数据集以及猫和狗图像识别数据来让我们对于卷积神经网络有一个大概的了解。

当计算机看到一张图像(输入一张图像)时,它看的是一大堆像素值。当我们人类对图像进行分类时,这些数字毫无用处,可它们却是计算机可获得的唯一输入。 现在的问题是:当你提供给计算机这一数组后,它将输出描述该图像属于某一特定分类的概率的数字(比如:80% 是猫、15% 是狗、5%是鸟)。
我们人类是通过特征来区分猫和狗,现在想要计算机能够区分开猫和狗图片,就要计算机搞清楚猫猫狗狗各自的特有特征。计算机可以通过寻找诸如边缘和曲线之类的低级特点来分类图片,继而通过一系列卷积层级建构出更为抽象的概念。这是 CNN(卷积神经网络)工作方式的大体概述。
为什叫卷积神经网络?CNN 的确是从视觉皮层的生物学上获得启发的。简单来说:视觉皮层有小部分细胞对特定部分的视觉区域敏感。例如:一些神经元只对垂直边缘兴奋,另一些对水平或对角
边缘兴奋。
CNN的工作也是会初始化很多很多的CNN层,每一层可能对某一部分敏感,比如这一层会提取到图像中的边缘、直角,另一层会提取边缘中的曲线或者圆圈,最后所有的层线性组合在一起,最后得出结论。
CNN 工作概述指的是你挑一张图像,让它历经一系列:
- 卷积层:会提取某一部分的特征,创建很多很多这样的层,每 一个卷积层都会提取一部分特征。
- 非线性层:这是必须的,因为对于一个全连接的或者没有非线性层的网络,结果仍然是线性,不会给出更复杂的结论,所以必须经历非线性层。
- 池化(下采样(downsampling))层:图像像素比较高,提取特征时,可能值太多,为了把特征抽取出来,希望图像变得越来越小,然后它的特征一层一层抽取,所以需要池化层对它下采样,比如3000下采样到1500,再下采样到750,让这个图像越来越小 。在减小的过程中特征就会被抽取到每一层的卷积当中。
- 全连接层:将每一个像素使用权重和偏执,连接到一个隐藏单元,再经过输出层得到输出。综合你得到的特征,最后得出结论。
最终得到输出。正如之前所说,输出可以是最好地描述了图像内容的一个单独分类或一组分类的概率。
如果直接将输入图片全连接到输出,也是可以的,但是计算量惊人,可训练参数太多了。所以使用卷积层减少可训练参数。
什么是卷积?
卷积是指将卷积核应用到某个张量的所有点上,通过将卷积核在输入的张量上滑动而生成经过滤波处理的张量。

5x5的卷积核,可训练参数只需要5x5=25个参数即可。
一个卷积提取特征的例子:图像的边缘检测。

应用到图像的每个像素,就是卷积核的中间位置对准图像的每一个像素,然后卷积核和对应的图像元素做相乘求和的操作。结果输出一个刻画了所有边缘的新图像 。

总结起来一句话:卷积完成的是 对图像特征的提取或者说信息匹配。当一个包含某些特征的图像经过一个卷积核的时候,一些卷积核被激活,输出特定信号。
我们训练区分猫狗的图像的时候,卷积核会被训练,训练的结果就是,卷积核会对猫和狗不同特征敏感,输出不同的结果,从而达到了图像识别的目的。
CNN架构
- 卷积层 :conv2d
- 非线性变换层 :relu/sigmiod/tanh
- 池化层: pooling2d
- 全连接层:w*x+b
如果没有这些层,模型很难与复杂模式匹配,因为网络将有过多的信息填充,也就是其他那些层作用就是突出重要信息,降低噪声。
卷积层三个参数:
ksize:卷积核大小。
strides:卷积核移动的宽度,即卷积核在图像上滑动时,是一个一个的滑动还是跳过几个像素滑动。
padding:边缘填充,卷积核中间位置对准某些像素点时,卷积核一部分方框超出了图像范围,是否对图像的边缘进行填充。
非线性变化层:
也就是激活函数。
relu:小于0的直接输出0,大于0的原样输出。
sigmiod:将输出映射为0~1之间的概率。
tanh
池化层:
MaxPooling2D 最大池化。
2x2的最大池化,选取2x2区域上最大的元素输出结果会比原图像小一半。
全连接层:
将最后的输出与全部特征连接,我们要使用全部的特征,为最后的分类的做出决策。最后配合softmax进行分类。
整体架构:
 使用卷积核提取特征,用池化层减少图像,使得图像越来越小,越来越厚(通道数增多,提取到的特征越来越多)。
使用卷积核提取特征,用池化层减少图像,使得图像越来越小,越来越厚(通道数增多,提取到的特征越来越多)。
手写数字分类
引入必要的库、使用GPU加速训练、定义图片的转换方法
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import torchvision
from torchvision import datasets, transforms
# torchvision内置了常用数据集和最常见的模型,transforms是一系列转换数据集的方法。
# 使用GPU加速训练
print(torch.cuda.is_available()) # 查看GPU是否可用
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 在GPU上训练只需两步:
#(1)将模型转移到GPU
#(2)将每一个批次的训练数据转移到GPU
"""
model = Model()
model.to(device) ,将模型放到了GPU上
"""
transformation = transforms.Compose([
transforms.ToTensor(),
])
# Compose方法,会将所有这些变换都以列表的形式放在Compose里面。
# transforms.ToTensor()最常用的转换,将我们读取的图片或者其他数据转换成tensor,
# 会将其他数据转换到0-1之间,归一化,
# 会将channel放在第一维度上加载 数据集
train_ds = datasets.MNIST(
'data/',
train=True,
transform=transformation,
download=True
) # datasets.MNIST手写数字数据集,它会返回一个dataset数据类型
# 第一个参数是要把下载下来的数据集放到哪个位置;第二个参数,是否是训练数据;第三个参数,是否要做变换;最后,表示是否下载。
test_ds = datasets.MNIST(
'data/',
train=False,
transform=transformation,
download=True
)
train_dl = DataLoader(train_ds, batch_size=64, shuffle=True) # 用上一步得到的dataset创建Dataloader
test_dl = DataLoader(test_ds, batch_size=256)# 对于测试数据集,batch_size可以稍微大一些,因为测试数据不需要做反向传播,所以占用的内存小一些取出一个批次的数据出来看看。
mgs, labels = next(iter(train_dl))
print(imgs.shape) #0维度是批次,一维度是channel
print(labels.shape)
# 在pytorch里面图片的表示形式: 【batch, channel(通道), height, width】 运行结果:
def imshow(img):
npimg = img.numpy()
npimg = np.squeeze(npimg)
plt.imshow(npimg)
plt.figure(figsize=(10, 1))
for i, img in enumerate(imgs[:10]):
plt.subplot(1, 10, i+1)
imshow(img)
labels[:10]运行结果:


创建卷积神经网络模型
当使用卷积模型的时候,我们保留了图像的平面的结构,也即不会取消掉图像的空间结构。卷及神经网络会保留图像的空间结构 所以在前向传播一开始过程中,没有展平这一步(全连接模型有展平,即 input.view(-1,28*28))。 或者说,图像的展平是放在了最后,将所有特征提取到了之后我们才展平,而不是在一开始就进行展平,一开始我们使用卷积进行特征的提取。Conv2d表示是2d结构的卷积,使用在图像的特征提取上面。
nn.Conv2d(输入图像的通道数,输出多少个通道(即卷积核数量),卷积核大小Union[int,Tuple[int,int]])
其它参数:stride跨度默认为1,padding默认填充0行0,dilation膨胀卷积用的,bias表示卷积核是否有偏执
卷积核大小即可以是单个值,也可以是[int,int]形式。5 == [5,5] ,都表示5x5的卷积核。
class Model(nn.Module):
def __init__(self):
super().__init__() #继承nn.Module全部的属性
"""
当使用卷积模型的时候,我们保留了图像的平面结构,一开始使用卷积提取特征,所以要初始化卷积层
nn.Conv2d参数1是in_channels;参数2是out_channels,也就是要输出多个个channels,也即使用多少个卷积核提取特征,
你使用多少个卷积核提取特征,它的channels就会变成几。
参数3是kernel_size,即卷积核的大小,5即5x5的卷积核。
"""
self.conv1 = nn.Conv2d(1,6,5) # 2d结构的卷积。
self.pool = nn.MaxPool2d(2) # 池化层,最大池化。2,表示会变成原来的二分之一
self.conv2 = nn.Conv2d(6,16,5)
# 最后使用linear层来全连接一下
# 经过池化以后,最后是立体图形,有channel、高、宽,linear需要是二维的数据才能放进去,要展平它
# liner_1的输入就是input所有的像素大小,就是Conv2d这一层展平之后的像素大小
self.liner_1 = nn.Linear(16*4*4, 256)
self.liner_2 = nn.Linear(256, 10)
def forward(self, input):
# 前向传播的第一层就是进行卷积
x = F.relu(self.conv1(input)) # 首先卷积,再激活(非线性变化层)
x = self.pool(x) # 池化
x = F.relu(self.conv2(input))
x = self.pool(x)
print(x.size()) # torch.Size([64, 16, 4, 4]) 只有知道此时x的形状,才能够进行展平。
# 全连接层
x = x.view(x.size(0), -1) # 将数据展平,(x.size(0)是batch批次大小,展开成一个batch,一个批次这么多行,列不管的数据。
# x = x.view(-1, 16*4*4) # 展平成2d结构之后输入到Linear层中。或者这样展平数据也行
x = F.relu(self.liner_1(x))
x = F.relu(self.liner_2(x))
return x使用GPU进行加速训练
(1)将模型转移到GPU
(2)将每一个批次的训练数据转移到GPU
model = Model() # 创建模型
model.to(device) # 将模型放到GPU上
loss_fn = torch.nn.CrossEntropyLoss() # 损失函数。交叉熵
def fit(epoch, model, trainloader, testloader):
correct = 0
total = 0
running_loss = 0
for x, y in trainloader:
x,y = x.to(device),y.to(device) # 将每一个批次的数据放到GPU中
y_pred = model(x)
loss = loss_fn(y_pred, y)
optim.zero_grad()
loss.backward()
optim.step()
with torch.no_grad():
y_pred = torch.argmax(y_pred, dim=1)# torch.argmax(input, dim=None):返回指定维度最大值的序号。
correct += (y_pred == y).sum().item()
total += y.size(0)
running_loss += loss.item()
epoch_loss = running_loss / len(trainloader.dataset)
epoch_acc = correct / total
test_correct = 0
test_total = 0
test_running_loss = 0
with torch.no_grad():
for x, y in testloader:
x, y = x.to(device), y.to(device)
y_pred = model(x)
loss = loss_fn(y_pred, y)
y_pred = torch.argmax(y_pred, dim=1)
test_correct += (y_pred == y).sum().item()
test_total += y.size(0)
test_running_loss += loss.item()
epoch_test_loss = test_running_loss / len(testloader.dataset)
epoch_test_acc = test_correct / test_total
print('epoch: ', epoch,
'loss: ', round(epoch_loss, 3),
'accuracy:', round(epoch_acc, 3),
'test_loss: ', round(epoch_test_loss, 3),
'test_accuracy:', round(epoch_test_acc, 3)
)
return epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc
optim = torch.optim.Adam(model.parameters(), lr=0.001) # 优化函数
epochs = 20 # 总共训练epochs次
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc = fit(epoch,model, train_dl,test_dl)
train_loss.append(epoch_loss)
train_acc.append(epoch_acc)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)
运行结果:

plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.plot(range(1, epochs+1), train_loss, label='训练数据集的损失')
plt.plot(range(1, epochs+1), test_loss, label='测试数据集的损失')
plt.legend()运行结果:

plt.plot(range(1, epochs+1), train_acc, label='训练数据集的正确率')
plt.plot(range(1, epochs+1), test_acc, label='测试数据集的正确率')
plt.legend()运行结果:

四种天气图片数据分类
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import torchvision # 使用torchvision读取图片
import os
import shutil # 拷贝图片
预处理数据;创建文件夹
本次我们使用 torchvision 为我们提供的 datasets类里面的ImageFolder方法,可以帮助我们从 分类文件夹 中去创建dataset数据。它的要求是你的每一个类别是一个文件夹。
torchvision.datasets.ImageFolder,ImageFolder这个方法,是从图片文件夹加载数据。会从分类的文件夹中创建dataset数据。要求每一个类别是一个文件夹。
# 根目录。要在这个文件夹下创建训train数据和test数据。然后分别在train目录和test目录创建四种分类文件夹
base_dir = r'./dataset2/4weather'
train_dir = os.path.join(base_dir,'train')
test_dir = os.path.join(base_dir,'test')
if not os.path.isdir(base_dir): //判断根目录是否存在
os.mkdir(base_dir) //如果不存在就创建目录
train_dir = os.path.join(base_dir,'train')
test_dir = os.path.join(base_dir,'test')
os.mkdir(train_dir)
os.mkdir(test_dir)
# 四种分类。图片的四种类型
specises = ['cloudy', 'rain', 'shine', 'sunrise']
# 要在train和test下分别创建 cloud、rain...四种天气文件夹
for train_or_test in ['train','test']:
for specie in species:
if not os.path.isdir(os.path.join(base_dir,train_or_test,specie)):
os.mkdir( os.path.join(base_dir,train_or_test,specie) )下一步就是将所有图片分别复制到对应的文件夹中。
image_dir = r'./dataset2_imgs' # 图片所在的文件夹(全部图片,整个数据集)
# os.listdir(image_dir) 会列出image_dir目录下的所有文件
for i, img in enumerate(os.listdir(image_dir)): # i是序号。enumerate会将序号的数据本身返回,序号从0开始。
for spec in specises: # 对四种类别进行迭代。因为图片名称当中包含着类别
if spec in img: # 如果这个类别在图片名字中
s = os.path.join(image_dir, img) # 原始图片路径
if i%5 == 0: # 五分之一的图片拿来做测试数据集
d = os.path.join(base_dir, 'test', spec, img) # 这张图片将要被拷贝到哪里
else:
d = os.path.join(base_dir, 'train', spec, img)
shutil.copy(s, d) # 将s路径的文件拷贝到d目录下。
# 查看训练数据和测试数据,对应的分类下的图片数量
for train_or_test in ['train', 'test']:
for spec in specises:
print(train_or_test,r'/', spec,':', len(os.listdir(os.path.join(base_dir, train_or_test, spec))))运行结果:

读取、预处理图片并创建Dataset
取之前首先要对图片进行转换,图片有大有小,有横有竖,我们需要将它resize一下,转换需要使用transformers。
from torchvision import transforms
transform = transforms.Compose([
transforms.Resize((96, 96)), # 把所有图片规定一个统一的大小
transforms.ToTensor(), # 转换成tensor。将channel放在前面,将数据归一化到0~1之间
# 使用Normalize方法,将图片数据归一化到-1~1之间,或者说叫使用均值为0方差为1 进行标准化。可加可不加。
# 逐channel的对图像进行标准化(均值变为0,标准差变为1),可以加快模型的收敛
# output = (input - mean) / std
#是否可以这样理解:
# [0,1]只是范围改变了, 并没有改变分布,mean和std处理后可以让数据正态分布
transforms.Normalize(mean=[0.5, 0.5, 0.5], # 各通道的均值
std=[0.5, 0.5, 0.5]) # 各通道的标准差
])然后就是加载数据集为dataset了
# 加载数据集为dataset
train_dir = os.path.join(base_dir,'train')
test_dir = os.path.join(base_dir,'test')
train_ds = torchvision.datasets.ImageFolder(train_dir,transform=transform) # 第一个参数是root,即目录;第二个参数是转换方法
test_ds = torchvision.datasets.ImageFolder(test_dir,transform=transform)
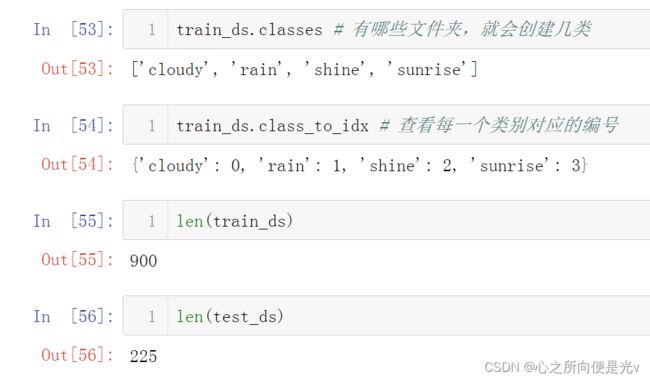
print(train_ds.classes) # train_ds有哪些类别呢?classes方法会列出来。你有哪些文件夹就会创建哪些类
print(train_ds.class_to_idx) # 每一个类别分类对应的编号
print(len(train_ds)) # 查看train_ds这个dataset的长度。打印结果是900,即train目录下的总共图片张数
print(len(test_ds))
运行结果:
生成DataLoader,DataLoader可以帮助我们处理批次、处理乱序以及使用多GPU
BATCHSIZE = 16 # 批次大小要根据显存大小定义,如果显存小,批次大,很容易造成显存的溢出
train_dl = torch.utils.data.DataLoader(train_ds,batch_size=BATCHSIZE,shuffle=True)
test_dl = torch.utils.data.DataLoader(test_ds,batch_size=BATCHSIZE,shuffle=False)
# 得到一个批次的imgs和对应的标签
imgs,labels = next(iter(train_dl))
imgs.shape,labels.shape
运行结果:
下面,我想得到一个批次的数据来绘图看看图像到底长什么样子。
matplotlib绘图的话,通道都是放在最后的,我们需要改变通道顺序,Pytorch为我们提供一个permute方法可以改变每一个维度的顺序。permute用来交换通道的顺序,三个通道分别是[0 1 2],我们想把它交换成[1 2 0]。它是应用在tensor上。
img1 = imgs[0].permute(1,2,0) # permute方法改变维度的顺序,应用对象是tensor。(1,2,0)是将第0个维度放到了最后
img1 = img1.numpy()
#由于在创建dataset时,对输入图像做了标准化的操作,这样的话它会被转化到 -1~1之间,我们需要把它转换回0~1。 我们只需要对它 先加一,再除以二,就可以了。
img1 = (img1+1)/2
img1.max(),img1.min() #查看图像灰度值最大值和最小值
plt.imshow(img1)运行结果:
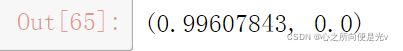

但是现在有一个问题,labels[0] 是编号的形式,我们怎么将id转换为实际的类别呢?
{'cloudy': 0, 'rain': 1, 'shine': 2, 'sunrise': 3} ,创建一个推导式,将id转换为实际的类别。
id_to_class = dict((v,k) for k,v in train_ds.class_to_idx.items()) tems()是字典方法,取出每一个key和value对象
id_to_class运行结果:
![]()
plt.figure(figsize=(12,8))
for i,(img,label) in enumerate(zip(imgs[:6],labels[:6])):
img = img.permute(1,2,0) # 交换通道顺序
img = img.numpy() # 转换为numpy类型
img = (img+1)/2 # 转换回0~1之间
plt.subplot(2,3,i+1)
plt.title(id_to_class.get(label.item())) # label是单个tensor数据,使用item方法取值其中的值
plt.imshow(img)运行结果:

模型的创建
# 规划卷积的样子(没添加dropout层和BN层之前):一层卷积一层pool,再一层卷积一层pool,一层卷积一层pool,最后两个全连接层
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__() # 继承父类所有的属性
self.conv1 = nn.Conv2d(in_channels=3,out_channels=16,kernel_size=3)
self.conv2 = nn.Conv2d(16,32,3)
self.conv3 = nn.Conv2d(32,64,3)
self.pool = nn.MaxPool2d(2,2)
self.fc1 = nn.Linear(64*10*10,1024) # 全连接层
self.fc2 = nn.Linear(1024,4)
def forward(self,x):
x = F.relu(self.conv1(x))
x = self.pool(x)
x = F.relu(self.conv2(x))
x = self.pool(x)
x = F.relu(self.conv3(x))
x = self.pool(x)
# x = self.drop(x)
# print(x.size())
x = x.view(-1, x.size(1)*x.size(2)*x.size(3)) # 将卷积结果进行展平,然后送入全连接层。
# x = x.view(x.size(0), -1)
x = F.relu(self.fc1(x)) #第一个全连接层要激活
# x = self.drop(x)
x = self.fc2(x) # 最后的输出层不进行激活,因为我们使用 CrossEntropyLoss
"""交叉熵:它主要刻画的是实际输出(概率)与期望输出(概率)的距离,也就是交叉熵的值越小,两个概率分布就越接近。"""
return x
model = Model()
preds = model(imgs) # 对一个批次的数据进行预测
imgs.shape,preds.shape # 每一张图片都会被输出到长量为4的一个张量上运行结果:

torch.argmax(preds,dim=1) # 每一张图片都会被输出到一个长度为4的分类结果上。在这4个类别上哪个值最大,就是最有可能的预测结果。在preds的第1个维度(列)上计算最大值的下标 运行结果:
开始进行训练
if torch.cuda.is_available():
model.to('cuda') # 将模型放到GPU
loss_fn = nn.CrossEntropyLoss() # 多分类问题,使用交叉熵损失函数
optim = torch.optim.Adam(model.parameters(),lr = 0.001) # 优化器
# 使用训练代码
def fit(epoch, model, trainloader, testloader):
correct = 0
total = 0
running_loss = 0
model.train() #训练模式。当我们调用model.train()时就相当于告诉这个模型现在处于训练模式,dropout层会发挥作用。
for x, y in trainloader:
if torch.cuda.is_available():
x, y = x.to('cuda'), y.to('cuda')
y_pred = model(x)
loss = loss_fn(y_pred, y)
optim.zero_grad()
loss.backward()
optim.step()
with torch.no_grad():
y_pred = torch.argmax(y_pred, dim=1)
correct += (y_pred == y).sum().item()
total += y.size(0) # y.size(0)每个批次的大小
running_loss += loss.item()
epoch_loss = running_loss / len(trainloader.dataset)
epoch_acc = correct / total
test_correct = 0
test_total = 0
test_running_loss = 0
model.eval() # 告诉模型现在处于预测模式,dropout层不会发生作用。
with torch.no_grad():
for x, y in testloader:
if torch.cuda.is_available():
x, y = x.to('cuda'), y.to('cuda')
y_pred = model(x)
loss = loss_fn(y_pred, y)
y_pred = torch.argmax(y_pred, dim=1)
test_correct += (y_pred == y).sum().item()
test_total += y.size(0)
test_running_loss += loss.item()
epoch_test_loss = test_running_loss / len(testloader.dataset)
epoch_test_acc = test_correct / test_total
print('epoch:', epoch,
' ,loss:', round(epoch_loss, 3),
' ,accuracy:', round(epoch_acc, 3),
' ,test_loss: ', round(epoch_test_loss, 3),
' ,test_accuracy:', round(epoch_test_acc, 3)
)
return epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc
epochs = 100
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc = fit(epoch,model,train_dl,test_dl)
train_loss.append(epoch_loss)
train_acc.append(epoch_acc)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)
"""训练数据可视化"""
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.figure(0)
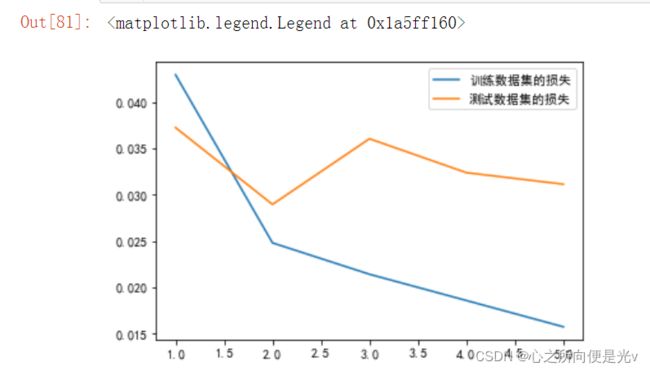
plt.plot(range(1, epochs+1), train_loss, label='训练数据集的损失')
plt.plot(range(1, epochs+1), test_loss, label='测试数据集的损失')
plt.legend()
plt.show()运行结果:
plt.plot(range(1, epochs+1), train_acc, label='训练数据集的正确率')
plt.plot(range(1, epochs+1), test_acc, label='测试数据集的正确率')
plt.legend() 运行结果: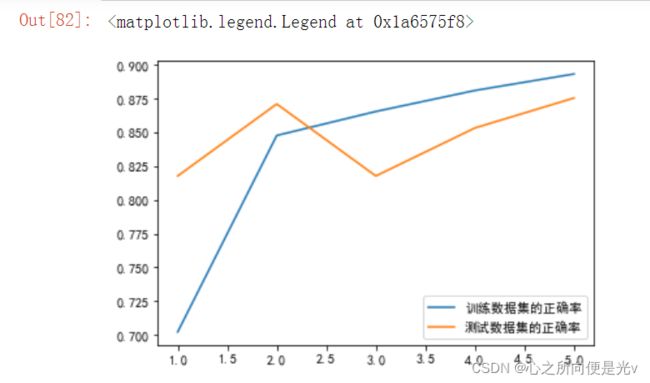
Dropout抑制过拟合
由绘图可知,过拟合了,如何抑制过拟合呢?可以使用dropout层和BN层。
对于解决过拟合问题,最根本的方法是增加训练数据,过拟合的本质就是模型的泛化能力不够,也就是模型只学到了你给他的这部分数据,不能推广到整个样本上。但是如果训练数据有限,就只能使用其它特殊的技巧。
dropout就是随机的丢弃掉一部分神经元,或者说随机的丢弃掉一部分神经元的输出。
dropout相当于就是把一部分神经元在这一次的前向传播过程中,让它们失能,丢弃掉它们的运算结果。
为什么dropout能抑制过拟合呢?
其实它的作用相当于我们说的集成方法或者说随机深林,在经典机器学习中,随机深林就是创建了多颗决策树,然后对多颗决策树的结果进行一个平均、投票得到一个输出结果。对于dropout仍然是这个样子,我们随机的选取一部分创建了模型A,下一次使用其它剩下的神经元创建了模型B,...... 这样相当于创建了多个模型。在进行预测的时候会将全部的神经元进行激活,dropout只是在训练过程中有效;对于预测predict过程中,dropout层并不会发生作用,它会拿全部的神经元进行预测。这个时候他就会将所有的神经元的结果拿过来,然后对他做一种,比如加权平均,得到一个结果。这样就相当于我们训练,使用了多个模型。

为什么说Dropout可以解决过拟合?
- 取平均的作用:dropout就是随机的丢弃掉一部分神经元的输出,dropout随机的选取一部分神经元创造一个模型,下一次随机的使用其它的神经元创造模型,这样训练之后相当于创造了多个模型,在预测的时候会将所有神经元激活。dropout只是在训练过程中有效,在预测的时候dropout层并不会发生作用,这时候就会将所有的这些神经元的结果取过来,然后对它们做比如加权平均,最后得到一个结果。就相当于训练时使用了多个模型
- 减少神经元之间复杂的共适应关系: 因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况 。可能两个神经元之间有依赖关系,dropout就破除了这种依赖关系,阻止了某些特征仅仅在某些条件下才有效这种情况。
- Dropout类似于性别在生物进化中的角色:物种为了生存往往会倾向于适应这种环境,环境突变则会导致物种难以做出及时反应,性别的出现可以繁衍出适应新环境的变种,有效的阻止过拟合,即避免环境改变时物种可能面临的灭绝。增加了模型的适应能力。因为模型的任何一部分都能够解决一部分问题,最后预测的时候使用全部的神经元,那么它的适应能力就会更强。
添加dropout层
nn.Dropout:适用于linear数据,用在linear层后面,dropout层一般添加在模型的后半部分。nn.Dropout(参数p表示随机丢弃掉的单元素比例)。
nn.Dropout2d:适用于四维的图片数据
nn.Dropout3d:适用于3d的数据
前面说了,dropout在训练的时候和预测的时候是不同的,训练的时候会随机丢弃掉百分之五十的神经元(本模型),预测的时候并不会产生丢弃,它会将全部神经元输出使用,所以就导致模型在训练的时候和预测的时候表现是不同的,所以fit函数要做一些变化的。
Pytorch为我们内置了 train方法和eval方法,train方法代表这个模型现在属于训练模式,eval模型代表模型现在处于预测模式。
如果在训练或者预测的时候忘记设置了模型的这两个模式,这个时候会导致在预测的时候dropout层仍然在发挥作用,会导致模型准确率下降。
model.train() 训练模式
model.eval() 预测模式。主要影响dropout层和batchNormalization(BN)层
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 3)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 3)
self.conv3 = nn.Conv2d(32, 64, 3)
self.drop = nn.Dropout(0.5) # 初始化dropout层
self.drop2d = nn.Dropout2d(0.5) # 为卷积层准备的dropout层
self.fc1 = nn.Linear(64*10*10, 1024)
self.fc2 = nn.Linear(1024, 256)
self.fc3 = nn.Linear(256, 4)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = self.drop2d(x) # 卷积层后面添加dropout层。
x = x.view(-1, 64 * 10 * 10)
x = F.relu(self.fc1(x))
x = self.drop(x) # 在第一个全连接层后加了dropout层
x = F.relu(self.fc2(x))
x = self.drop(x) # 第二个全连接层后加dropout层
x = self.fc3(x)
return x
model_deopout = Net()
if torch.cuda.is_available():
model_deopout.to('cuda')
optim = torch.optim.Adam(model_deopout.parameters(), lr=0.001)
loss_fn = nn.CrossEntropyLoss()
def fit(epoch, model, trainloader, testloader):
correct = 0
total = 0
running_loss = 0
model.train() # 模型现在属于训练模式
for x, y in trainloader:
if torch.cuda.is_available():
x, y = x.to('cuda'), y.to('cuda')
y_pred = model(x)
loss = loss_fn(y_pred, y)
optim.zero_grad()
loss.backward()
optim.step()
with torch.no_grad():
y_pred = torch.argmax(y_pred, dim=1)
correct += (y_pred == y).sum().item()
total += y.size(0)
running_loss += loss.item()
epoch_loss = running_loss / len(trainloader.dataset)
epoch_acc = correct / total
test_correct = 0
test_total = 0
test_running_loss = 0
model.eval() # 模型现在处于预测模式
with torch.no_grad():
for x, y in testloader:
if torch.cuda.is_available():
x, y = x.to('cuda'), y.to('cuda')
y_pred = model(x)
loss = loss_fn(y_pred, y)
y_pred = torch.argmax(y_pred, dim=1)
test_correct += (y_pred == y).sum().item()
test_total += y.size(0)
test_running_loss += loss.item()
epoch_test_loss = test_running_loss / len(testloader.dataset)
epoch_test_acc = test_correct / test_total
print('epoch:', epoch,
' loss: ', round(epoch_loss, 5),
' accuracy:', round(epoch_acc, 5),
' test_loss:', round(epoch_test_loss, 5),
' test_accuracy:', round(epoch_test_acc, 5)
)
return epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc
epochs = 10
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc = fit(epoch, model_deopout,train_dl,test_dl)
train_loss.append(epoch_loss)
train_acc.append(epoch_acc)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)
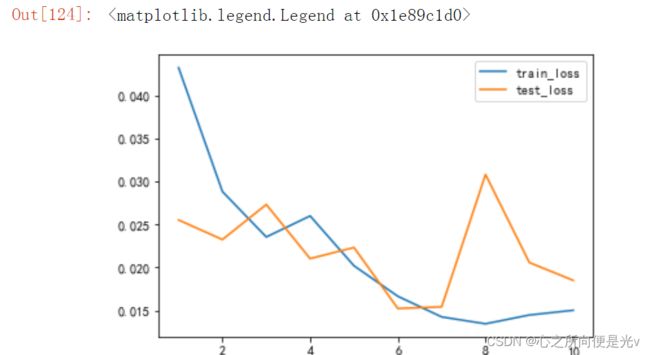
plt.plot(range(1, epochs+1), train_loss, label='train_loss')
plt.plot(range(1, epochs+1), test_loss, label='test_loss')
plt.legend()
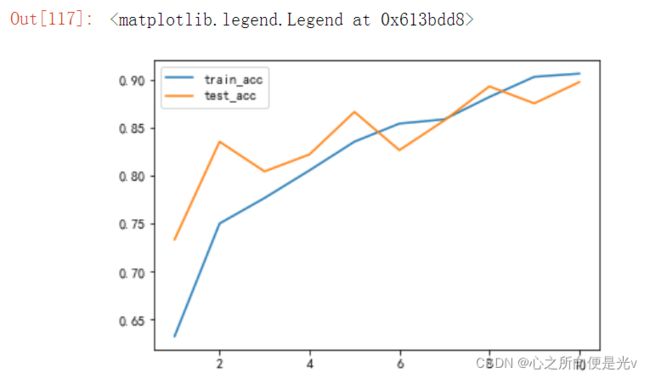
plt.plot(range(1, epochs+1), train_acc, label='train_acc')
plt.plot(range(1, epochs+1), test_acc, label='test_acc')
plt.legend()运行结果:

批标准化
什么是标准化?传统机器学习中标准化也叫做归一化,一般是将数据映射到指定的范围,用于去除不同维度数据的量纲以及量纲单位。 数据标准化让机器学习模型看到的不同样本彼此之间更加相似,这有助于模型的学习与对新数据的泛化。
常见的数据标准化形式:
标准化和归一化。将数据减去其平均值使其中心为 0,然后将数据除以其标准差使其标准差为 1。归一化就是将数据规范到0~1之间,PyTorch有个方法,toTensor会将图像取值范围从0~255规范到0~1之间,标准化就是将数据减去均值,除以方差,让它变成标准正态分布。标准化后均值为0,方差为1。
Batch Normalization, 批标准化, 和普通的数据标准化类似, 是将分散的数据统一的一种做法, 也是优化神经网络的一种方法.。
批标准化不仅在将数据输入模型之前对数据做标准化;在网络的每一次变换之后都应该考虑数据标准化。
即使在训练过程中均值和方差随时间发生变化,它也可以适应性地将数据标准化 。
在输入层经过第一个影藏层之后,由于乘了一个权重,加了一个截距,数据范围可能不再是0~1之间了。披标准化就是网络的每一次变换之后都应该考虑数据标准化。

批标准化解决的问题是梯度消失与梯度爆炸。批标准化一种训练优化方法。
关于梯度消失,以sigmoid函数为例子,sigmoid函数使得输出在[0,1]之间。
如果输入很大,其对应的斜率就很小,反向传播梯度就很小,学习速率就很慢。 因此希望数据落在0的周边,所以对他做披标准化。
我们知道数据预处理做标准化可以加速收敛,同理,在神经网络使用标准化也可以加速收敛,而且还有更多好处。
- 具有正则化的效果,抑制过拟合。
- 提高模型的泛化能力。
- 允许更高的学习速率从而加速收敛。
- 批标准化有助于梯度传播,因此允许更深的网络。对于有些特别深的网络,只有包含多个BatchNormalization 层时才能进行训练。
- BatchNormalization 广泛用于pytroch内置的许多高级卷积神经网络架构,比如ResNet、Inception V3等
实现批标准化
BatchNormalization 层通常在卷积层或密集连接层之后使用。
nn.BatchNorm1d():一般应用在linear层后面
nn.BatchNorm2d():一般应用在卷积层后面
实现过程:
- 求每一个训练批次数据的均值
- 求每一个训练批次数据的方差
- 数据进行标准化(减均值,除方差)
- 训练参数γ,β:我们将原来的数据经过标准化之后就和原来的不一样了,通过γ,β这种线性变换,再把它变换回去。
- 输出y通过γ与β的线性变换得到原来的数值:在训练的正向传播中,不会改变当前输出,只记录下γ与β。在反向传播的时候,根据求得的γ与β通过链式求导方式,求出学习速率以至改变权值。
所以在BN层中,它是训练了四个值,分别是每一个批次的均值和方差,以及线性变换的参数伽马和贝塔。这个线性变换的γ和β,实际上是我们把这个数据通过标准化之后,它就和原来的数据不一样了,那么就通过γ和β这种线性变换,再变换回去。
批标准化的预测过程:
对于预测阶段时所使用的均值和方差,其实也是来源于训练集。比如我们在模型训练时我们就记录下每个batch下的均值和方差,待训练完毕后,我们求整个训练样本的均值和方差期望值,作为我们进行预测时进行BN的的均值和方差。
添加BN层之后,咱门这个模型在训练模式和预测模型是不同的,训练时,根据每一个批次求取均值和方差,以及通过γ,β进行线性变换;预测时,均值和方差是多少呢?这个模型会记录下每一个批次的均值和方差,使用记录下的均值和方差对我们的预测数据进行变换(标准化)。
批标准化的使用位置
model.train()和model.eval();指示模型应在训练模式还是在推理模式下运行。
训练模式 :将使用当前批输入的均值和方差对其输入进行标准化。
推理模式 :将使用在训练期间学习的移动统计数据的均值和方差来标准化其输入 。
原始论文讲在CNN中一般应作用与非线性激活函数之前,但是,实际上放在激活函数之后效果可能会更好。
BN层需要在每一个卷积层或者linear层之后去添加
BN层使得模型表现更好,过拟合受到了极大的抑制。对于一些比较深的现代模型(比如resnet)如果没有BN层的话,这个模型是不可训练的,所以BN层是必须的,在以后创建模型的时候要学会使用BN层。
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__() # 继承父类的属性
self.conv1 = nn.Conv2d(3,16,3) # (3,16,3)代表输入通道是3,输出通道是16(第一层用了16个卷积核),3代表卷积核大小
self.bn1 = nn.BatchNorm2d(16)
self.conv2 = nn.Conv2d(16,32,3)
self.bn2 = nn.BatchNorm2d(32)
self.conv3 = nn.Conv2d(32,64,3)
self.bn3 = nn.BatchNorm2d(64)
self.drop = nn.Dropout(p=0.5)
self.drop2d = nn.Dropout2d(p=0.5)
# nn这个模块为我们内置了好了drop层。线性linear数据使用Drop,对于四维的图片数据使用Dropout2d,对于三维的数据使用Drop3d
# Dropout第一个参数p(float),默认值是0.5,代表它要随机去扔掉的这些单元数(0.5就是丢弃百分之五十的单元)
# BN 层需要在卷积层/linear层之后添加。BatchNorm2d的第一个参数是num_features,即有多少个特征(上一层卷积层输出的channel数)
self.pool = nn.MaxPool2d(2,2) # 池化层。每一次都将原图变为原来的二分之一
self.fc1 = nn.Linear(64*10*10,1024) # 全连接层。nn.Linear需要知道第三个卷积层之后图像的大小。输出到1024个单元
self.bn_f1 = nn.BatchNorm1d(1024)
self.fc2 = nn.Linear(1024, 256)
self.bn_f2 = nn.BatchNorm1d(256)
self.fc3 = nn.Linear(256,4) # 输出到长度为4的张量上
# 编写调用前向传播的过程
def forward(self, input):
x = F.relu(self.conv1(input)) # F.relu进行激活(非线性层)
x = self.pool(x)
x = self.bn1(x)
x = F.relu(self.conv2(x))
x = self.pool(x)
x = self.bn2(x)
x = F.relu(self.conv3(x))
x = self.pool(x)
x = self.bn3(x)
x = self.drop2d(x)
# 需要将数据展平
# print('x.size():',x.size())
# x = x.view(-1,x.size(1)*x.size(2)*x.size(3)) # x.size(0)是batch批次大小
# x = x.view(-1,64*10*10)
x = x.view(x.size(0),-1)
# 全连接
x = F.relu(self.fc1(x))
x = self.bn_f1(x)
x = self.drop(x)
x = F.relu(self.fc2(x))
x = self.bn_f2(x)
x = self.drop(x)
x = self.fc3(x) # 最后这一层不用激活,因为我们使用nn.CrossEntropyLoss交叉熵损失
"""交叉熵:它主要刻画的是实际输出(概率)与期望输出(概率)的距离,也就是交叉熵的值越小,两个概率分布就越接近。"""
return x
"""
dropout层一般添加在模型的后半部分
dropout在训练和预测的时候他的表现是不同的,训练时会随机丢弃百分之五十的神经元,在预测的时候会全部使用神经元
所以,fit函数要做一些变化。
model.train(),训练模式。model.eval(),预测模式。主要影响dropout层和BN层。
"""
model_BN = Net()
if torch.cuda.is_available():
model_BN.to('cuda')
optim = torch.optim.Adam(model_BN.parameters(), lr=0.001)
loss_fn = nn.CrossEntropyLoss()
def fit(epoch, model, trainloader, testloader):
correct = 0
total = 0
running_loss = 0
model.train()
for x, y in trainloader:
if torch.cuda.is_available():
x, y = x.to('cuda'), y.to('cuda')
y_pred = model(x)
loss = loss_fn(y_pred, y)
optim.zero_grad()
loss.backward()
optim.step()
with torch.no_grad():
y_pred = torch.argmax(y_pred, dim=1)
correct += (y_pred == y).sum().item()
total += y.size(0)
running_loss += loss.item()
epoch_loss = running_loss / len(trainloader.dataset)
epoch_acc = correct / total
test_correct = 0
test_total = 0
test_running_loss = 0
model.eval()
with torch.no_grad():
for x, y in testloader:
if torch.cuda.is_available():
x, y = x.to('cuda'), y.to('cuda')
y_pred = model(x)
loss = loss_fn(y_pred, y)
y_pred = torch.argmax(y_pred, dim=1)
test_correct += (y_pred == y).sum().item()
test_total += y.size(0)
test_running_loss += loss.item()
epoch_test_loss = test_running_loss / len(testloader.dataset)
epoch_test_acc = test_correct / test_total
print('epoch: ', epoch,
' loss:', round(epoch_loss, 4),
' accuracy:', round(epoch_acc, 4),
' test_loss:', round(epoch_test_loss, 4),
' test_accuracy:', round(epoch_test_acc, 4)
)
return epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc
epochs = 10
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc = fit(epoch,model_BN,train_dl,test_dl)
train_loss.append(epoch_loss)
train_acc.append(epoch_acc)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)
plt.plot(range(1, epochs+1), train_loss, label='train_loss')
plt.plot(range(1, epochs+1), test_loss, label='test_loss')
plt.legend()
plt.plot(range(1, epochs+1), train_acc, label='train_acc')
plt.plot(range(1, epochs+1), test_acc, label='test_acc')
plt.legend()
运行结果:

网络容量
网络容量:可以认为与网络中的可训练参数成正比 。网络中的神经单元数越多,层数越多,神经网络的拟合能力越强。但是训练速度、难度越大,越容易产生过拟合。
如何选择超参数?所谓超参数,也就是搭建神经网络中,需要我们自己如选择(不是通过梯度下降算法去优化)的那些参数。比如,中间层的神经元个数、学习速率。
那么如何提高网络的拟合能力?
一种显然的想法是增大网络容量:
- 增加层
- 增加隐藏神经元个数
这两种方法哪种更好呢?单纯的增加神经元个数对于网络性能的提高并不明显,增加层会大大提高网络的拟合能力这也是为什么现在深度学习的层越来越深的原因。
注意:单层的神经元个数,不能太小,太小的话,会造成信息瓶颈,使得模型欠拟合。
理想的模型是刚好在欠拟合和过拟合的界线上,也就是正好拟合数据。
参数选择原则:
首先开发一个过拟合的模型:
(1) 添加更多的层。
(2) 让每一层变得更大。
(3) 训练更多的轮次然后,抑制过拟合:
(1)dropout
(2)正则化
(3)图像增强再次,调节超参数:
- 学习速率,
- 隐藏层单元数
- 训练轮次
超参数的选择是一个经验与不断测试的结果。
经典机器学习的方法,如特征工程、增加训练数据也要做交叉验证。
构建网络的总原则:保证神经网络容量足够拟合数据。
- 增大网络容量,直到过拟合
- 采取措施抑制过拟合
- 继续增大网络容量,直到过拟合