Learning to Compare: Relation Network for Few-Shot Learning阅读笔记
小样本-Learning to Compare: Relation Network for Few-Shot Learning阅读笔记
- 概要
- 介绍
- 相关工作
- 方法论
-
- 问题定义
- 模型
-
- One-Shot
- K-Shot
- Objective function
- Zero-shot Learning
- 网络结构
- Few-shot Learning
- Zero-shot Learning
- 实验
-
- Few-shot Recogntion
-
- Omniglot
- miniImageNet
- Zero-shot Recognition
- 关系网络为什么能工作
概要
这是2016年CVPR录用的一篇few-shot learning的文章。这篇文章提出了一种概念上简单、灵活和通用的few-shot learning的框架。few-shot learning问题的分类器必须在每个新类别(在训练杰顿未见过的类别)只给出几个样本的情况下正确分类新类别。
文章提出了一种网络——关系网络(Relation Networks, RN),一个从头开始学习,端到端(end to end)的网络。在meta-training过程中,网络学习一个深度距离度量来比较剧集(episode)中的少量图像,每一集(episode)都是为了模拟 few-shot 设置而设计的。一旦训练好,RN能够在不对网络进行任何更新的情况下,对新类别进行正确的分类。 其训练过程可以概括为:通过计算query set中的样本和support set中的样本之间的关系得分来对query set样本进行分类。除了在few-shot learning上t提升了性能,而且这个框架很容易扩展到zero-shot learning。最后在五个基准上的大量实验表明,我们的简单方法为这两个任务提供了一个统一而有效的方法。
同时对于Few-shot learning和Meta-learning推荐通过这篇文章进行理解:
Few-shot learning(少样本学习)和 Meta-learning(元学习)概述
介绍
深度学习模型在计算机视觉识别任务中取得了巨大成功。然而,这些监督学习模型需要大量的标记数据和多次迭代来训练它们的大量参数,这严重限制了它们对新类别的可扩展性(需要对新数据标注成本),但更根本的是限制了它们对新兴(如新消费设备)或稀有(如稀有动物)类别的适用性,在这些类别中,大量标记样本可能根本不存在。相比之下,人类非常擅长在几乎没有直接监督或完全没有监督的情况下识别物体,即分别对应 few-shot leanring 和 zero-shot leanring。例如,孩子们可以从书中的一张图片中概括出“斑马”的概念,或者听到它的描述看起来像一匹条纹马。
few-shot leanring旨在从极少数标记的样本中对新的类别进行识别。数据增强技术和正则化技术可以缓解在少量数据集情况下的 过拟合 (overfitting) 问题,但是并没有很好的解决它。因此开始将 meta-learning 用于 few-shot learning 问题。这种方法将训练分解成了一个辅助的 meta training 阶段,其中学习可以迁移的知识用于识别新的类。这种可以迁移的知识主要可以分为:
- good initial conditions,例如经典的MAML。相对应的,在新的需要识别新类的 meta-testing 的问题任务上基于学习到的初始化对网络进行微调。
《Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks》,
论文链接:https://arxiv.org/pdf/1606.04080.pdf
论文解读:https://blog.csdn.net/qq_41035541/article/details/109896600 - embeddings,例如典型的Matching Networks、Prototypical Networks。相对应的,在新的需要识别新类的 meta-testing 的问题任务上直接前向传播而无需更新网络的权重参数。
Matching Networks论文链接:https://arxiv.org/pdf/1606.04080.pdf
论文解读:https://blog.csdn.net/qq_41035541/article/details/109667619
Prototypical Networks论文链接:https://arxiv.org/pdf/1703.05175.pdf
论文解读:https://blog.csdn.net/qq_41035541/article/details/109701318 - optimisation strategy:例如Optimization as a Model for Few-Shot Learning。相对应的,在新的需要识别新类的 meta-testing 的问题任务上基于学习到的优化策略对网络进行微调。
论文链接:《Optimization as a Model for Few-Shot Learning》
目前大多数现有的few-shot learning方法要么需要复杂的推理机制、要么需要复杂的递归神经网络(RNN)架构,要么需要对目标问题进行微调[MAML,Optimization as a Model for Few-shot Learning]。我们的方法与其他旨在为few-shot learning训练有效指标的方法(Siames Networks、Matching Networks、Prototypical Networks)最为相关。Siames Networks、Matching Networks、Prototypical Networks专注于可迁移嵌入的学习(embeddings)和预定义的固定度量(例如,余弦距离[Siames Networks、Matching Networks],欧几里德[Prototypical Networks])时,我们进一步旨在学习可迁移的深度度量,用于比较图像之间的关系(few-shot learning),或者图像和类描述之间的关系(zero-shot learning)。这个可迁移的度量可以看做是学习一个非线性的比较器,而不是一个固定的线性比较器,通过表达更深解的归纳偏差(嵌入和关系模块中的多个非线性学习阶段),我们可以更容易地学习问题的通用解。
这篇paper的Relation Networks也就是上述中的第二种方法,学习一个embeddings,但是Relation Networks除了学习一个embeddings外,还学习了一个可迁移(不是通过人为手动定义的)的非线性度量。
对于这篇paper提出的Relation Networks主要包含两个模块:
- embedding module: 嵌入模块将训练样本和查询样本进行向量表示。
- relation module: 关系模块对嵌入模块提取的特征向量进行比较,判断他们是匹配的类别。
Relation Networks的训练策略还是和Matching Networks和Prototypica Networks一样,采用基于episode的meta-training训练策略,其中嵌入模块和关系模块可以看做是扩展了Matching Networks和Prototypica Networks中的策略,因为Relation Network包含一个可学习的非线性比较器,而不是一个固定的线性比较器。
Relation Networks相比之前的方法更简单(没有RNN),而且更快(不用微调)。同时该方法也可以直接推广到zero-shot learning。对于zero-shot leanring来说,我们已知的信息不是类别的标签信息,可能是关于类别的一个描述信息,比如将斑马描述为是一种“条纹马”提供给网络。此时样本分支嵌入的不再是单个类别的样本图像,而是一个类别的描述。
相关工作
之前的许多使用元学习或学习到学习的策略,从某种意义上说,它们从一组辅助任务(meta-learning,learn to learn)中提取一些可转移的知识,然后帮助它们很好地学习few-shot learning,而不会遭受将深度模型应用于稀疏数据问题时可能预期的过度拟合。
本文将Meta-learning方法大致分为三类:
- Learning to Fine-Tune: MAML(Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks)是该类方法的典型代表,MAML的主要思想就是学习一个较好的初始化参数(网络的权重),之后遇到新类别的少量样本时,只需要进行几步梯度更新(Fine-tune)就能取得较好的效果。相比之下,我们的方法以完全前馈的方式解决目标问题,不需要更新模型,使其更方便于低延迟或低功耗应用。
- RNN Memory Based: 使用带有记忆力的递归神经网络(RNN)。在我们的RL方法中,我们避免了重复出现的网络的复杂性,以及在确保它们的存储足够性时所涉及的问题。相反,我们的“学会学习”方法完全由简单快速的前馈神经网络定义。
- Embedding and Metric Learning Approaches: 使用嵌入和度量的方法。Siamese Networks、Prototypical Networks侧重于学习一个可迁移的嵌入。相比之下,我们的框架除了学习嵌入以外,还进一步定义了一个关系分类器CNN,通过计算相似性得分来推理两个样本之间的关系,但是缺乏很好的理论证明。与Siamese Networks、Prototypical Networks相比,这可以被视为提供了一个可学习的而不是固定的度量,或者非线性而不是线性的分类器。与Siamese Networks相比,我们受益于从头开始的端到端方式的episdoe的训练策略,同时与Meta-learning with memory-augmented neural networks相比,我们避免了样本集的集合到集合RNN嵌入的复杂性。
Zero-Shot Learning: 我们的方法是为few-shot learning设计的,但是通过修改样本分支以输入单个类别描述而不是单个训练图像,优雅地将空间跨越到zero-shot learning(ZSL)中。
方法论
问题定义
形式上来说,我们将数据分为三个数据集:训练集(training set)、支持集(support set)、测试集(testing set)。其中支持集和测试集共享相同的标签空间(也就是这两个集合包含的是多个相同类别的样本集合),并且训练集与支持集和测试集不相交。如果支持集包含C个不同的类别,每个类别K个样本,我们称这样的小样本任务为C-way K-shot。
在训练的过程中构建的是sample set和query set,用来模拟测试时的support set和test set。(也就是训练时,sample set和query set进行训练,测试时support set和test set进行测试。sample set和support set的作用相同,query set和test set的作用相同)
如果直接使用支持集,原则上我们可以训练处一个分类器(从支持集中选出sample set和query set进行训练),为测试集中的每个样本 x ^ \hat{x} x^分配一个类标签 y ^ \hat{y} y^。但是由于支持集标记样本的个数有限(就相当于train set中作为sample set的一部分),所以训练出来的分类器效果就不是很好。所以,我们的目标是在训练集上执行元学习,以便提取出可转移的知识,之间允许我们在支持集上执行更好的小样本学习,从而更成功的对测试集分类。
一个有效的训练方式就是通过基于episode的训练来模拟小样本学习任务。在每次训练的迭代中,通过从训练集随机抽取C个类别,每个类别K个样本,总共 K ∗ C K*C K∗C个样本作为sample set: S = { ( x i , y i ) } i = 1 m S=\left \{ (x_i,y_i) \right \}_{i=1}^{m} S={(xi,yi)}i=1m(m= K ∗ C K*C K∗C)。然后再从训练集中C个类的剩余部分中抽取一部分(n个样本)作为Query set: Q = { ( x j , y j ) } j = 1 n Q=\left \{ (x_j,y_j) \right \}_{j=1}^{n} Q={(xj,yj)}j=1n
模型
One-Shot
我们的Relation Network(RN)有两个模块组成:嵌入模块(embedding module) f φ f_\varphi fφ 和关系模块(relation module) g ϕ g_\phi gϕ
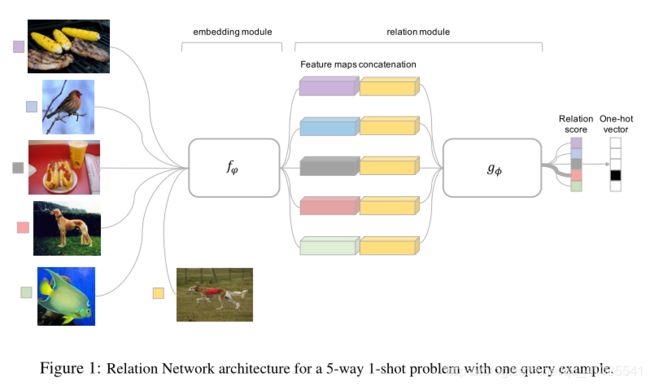
如图所示,左边的五张图片就是sample set,右边的一张图片就是query set。 x j x_j xj来自于query set, x i x_i xi来自于sample set。先通过嵌入模块进行特征的提取,得到 f φ ( x i ) f_\varphi (x_i) fφ(xi)和 f φ ( x j ) f_\varphi (x_j) fφ(xj),然后通过连接算子 C ( f φ ( x i ) , f φ ( x j ) ) C(f_\varphi (x_i), f_\varphi (x_j)) C(fφ(xi),fφ(xj)),将两个特征向量串联起来。然后将连接算子 C ( . , . ) C(.,.) C(.,.)得到的组合特征通过关系模块 g ϕ g_\phi gϕ计算关系得分,这将会产生一个0到1的关系得分来表明 x i x_i xi与 x j x_j xj的相似度。因此,对于C-way One-shot,一个query set中的样本将会有C个关系得分,对于query set中的样本 x j x_j xj和sample set中 x i x_i xi,关系得分为:
r i , j = g ϕ ( C ( f φ ( x i ) , f φ ( x j ) ) ) , i = 1 , 2 , . . . , C r_{i,j}=g_\phi(C(f_\varphi(x_i),f_\varphi(x_j))),i=1,2,...,C ri,j=gϕ(C(fφ(xi),fφ(xj))),i=1,2,...,C (1)
K-Shot
对于K-shot(K>1),即C-way K-shot任务,我们对来自sample set中的每个类的所有样本的嵌入模块嵌入输出后进行向量求和,以形成该类的特征映射,然后对query set中的每个样本计算与sample set中每个类别的关系得分(此时,一个query set中的样本也将会有C个关系得分)。
r i , j = g ϕ ( C ( f φ ( x i ) , f φ ( x j ) ) ) , i = 1 , 2 , . . . , C r_{i,j}=g_\phi(C(f_\varphi(x_i),f_\varphi(x_j))),i=1,2,...,C ri,j=gϕ(C(fφ(xi),fφ(xj))),i=1,2,...,C (1)
Objective function
在这篇文章中,我们使用均方误差(mean square error, MSE)来训练我们的模型,目标函数为:
φ , ϕ ← a r g m i n φ , ϕ ∑ i = 1 m ∑ j = 1 n ( r i , j − 1 ( y i = = y j ) ) 2 \varphi,\phi \leftarrow \underset{\varphi,\phi}{argmin}\sum_{i=1}^{m}\sum_{j=1}^{n}(r_{i,j}-1(y_i==y_j))^2 φ,ϕ←φ,ϕargmin∑i=1m∑j=1n(ri,j−1(yi==yj))2 (2)
其中 1 ( y i = = y j ) 1(y_i==y_j) 1(yi==yj)表示: y i y_i yi和 y j y_j yj匹配,则 1 ( y i = = y j ) 1(y_i==y_j) 1(yi==yj)=1,否则为0
这里分类问题一般使用交叉熵,但是由于最后得分是一个 0 到 1 的关系得分,也可以看成是一个回归问题,因此使用了均方误差MSE作为损失函数。
Zero-shot Learning
Zero-shot Learning类似于one-shot learning。由于Zero-shot不是给对C个类别的每个类提供一些样本作为训练数据,而是给出每个类别的语义的嵌入向量 v c v_c vc。然后使用 f φ 2 f_{\varphi2} fφ2对嵌入向量 v c v_c vc进行特征提取,用 f φ 1 f_{\varphi1} fφ1对query set中的样本进行特征提取,然后使用关系模块计算关系得分。因此,对于每个query set中的样本 x j x_j xj的关系得分为:
r i , j = g ϕ ( C ( f φ 1 ( v c ) , f φ 2 ( x j ) ) ) , i = 1 , 2 , . . . C r_{i,j}=g_\phi(C(f_{\varphi1}(v_c),f_{\varphi2}(x_j))), i=1,2,...C ri,j=gϕ(C(fφ1(vc),fφ2(xj))),i=1,2,...C (3)
Zero-shot learning的目标函数和few-shot learning的目标函数相同,都是:
φ , ϕ ← a r g m i n φ , ϕ ∑ i = 1 m ∑ j = 1 n ( r i , j − 1 ( y i = = y j ) ) 2 \varphi,\phi \leftarrow \underset{\varphi,\phi}{argmin}\sum_{i=1}^{m}\sum_{j=1}^{n}(r_{i,j}-1(y_i==y_j))^2 φ,ϕ←φ,ϕargmin∑i=1m∑j=1n(ri,j−1(yi==yj))2 (2)
网络结构
Few-shot Learning
嵌入模块:我们的网络结构和大多数few-shot learning模型一样利用四个卷积块作为嵌入模块,更具体的说,每个卷积块分别包含64个卷积核的 3 × 3 3\times3 3×3的卷积、一个批归一化、一个Relu非线性层。前两个卷积块还分别包含一个 2 × 2 2\times2 2×2的最大池化层,后两个卷积块不包含池化层。
关系模块:关系模块由两个卷积块和两个全两个全连接层构成。每个卷积块是由一个包含64个 3 × 3 3\times3 3×3的卷积核组成,然后是批归一化、Relu非线性层和最大池化层。全连接层分别是8维和1维的,除了输出层是Sigmoid之外,所有的全连接成都是Relu。

Zero-shot Learning
Zero-shot Learning的网络结构如下图所示,其中的DNN模块是通过Inception或者ResNet等在ImageNet上预训练出来的,用于对query set中的样本进行嵌入,而MLP网络(左边的FC1,FC2)用于嵌入语义属性向量。

实验
Few-shot Recogntion
Settings: 在Few-shot上的实验,我们均使用Adam优化算法,初始学习率为 1 0 − 3 10^{-3} 10−3,每经过100000个episodes学习率减半,我们所有的模型均是从头开始进行端到端的训练,没有额外的数据集。
Baselines: 我们比较了各种现有的few-shot learning 的baselines,比如neural statistician,Matching Networks without fine-tuning,MANN,Siamese Nets,MAML,Meta Nets,Protypical Nets,Meta-Learner LSTM。
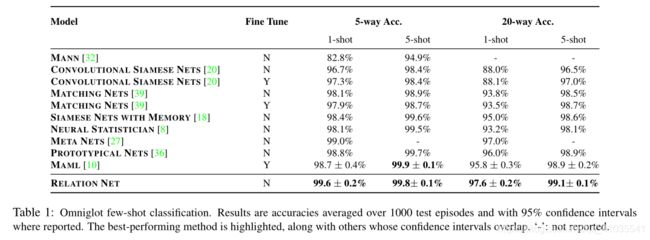
Omniglot
Dataset: Omniglot由来自50个不同国家的字母表1623个字符(类)组成。其中每个字符(类)包含20个由不同的人手工绘制的样本。(1623个类,没类20个样本)。我们使用1200个类别做训练,剩余的423个类别做测试。
在Omniglot数据上试验时,有如下额外设置:
(1) 训练时的数据采样设置:
- 5-way 1-shot时,query set中每个类别有19张图片
- 5-way 5-shot时,query set中每个类别有15张图片
- 20-way 1-shot时,query set中每个类别有10张图片
- 20-way 5-shot时,query set中每个类别有5张图片
(2)测试时,从test set中随机采样1000个episodes,将这1000个epsiodes的测试结果平均作为整体的测试结果。
实验结果如下:
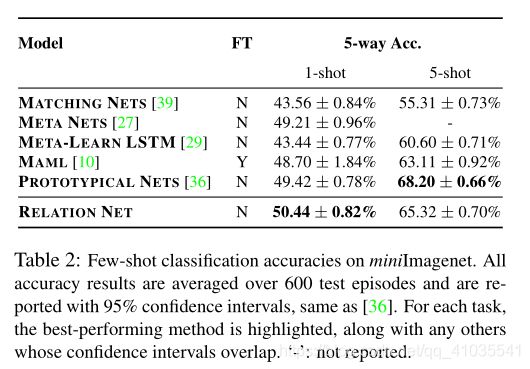
miniImageNet
Dateset: miniImageNet数据集最初是在Matching Networks中提出的,有60000张彩色图像构成,其中包含100个类别,每个类别600个样本。作者将数据集划分为training、validation和testing,分别包含64、16和20个类别。16个类别的validarion仅用于监控模型的泛化能力。
在miniImageNet数据集上试验时,有如下额外设置:
(1)训练时的数据采样设置
- 5-way 1-shot时,query set中每个类别有15张图片
- 5-way 5-shot时,query set中每个类别有10张图片
(2)测试时,从test set中随机采样600个episodes,将这600个episodes的结果平均作为整体结果
实验结果如下:
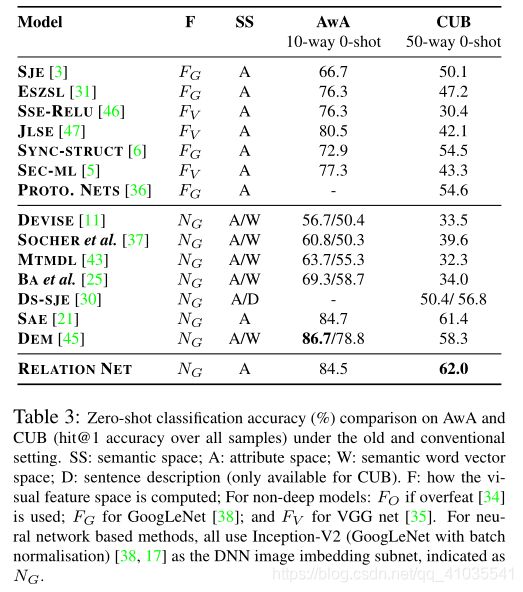
Zero-shot Recognition
Dateset: AwA(Animals with Attributes)是由50个类别的30754张图片组成,他有一个固定的划分:40个类别作为训练集,10个类别作为测试集。CUB(Caltech-UCSD Birds-200-2011)是由200种鸟的类别11788张图像组成,其中150中是已见过的,剩下的50种是未见过的。
Semantic representation(语义表示): 对于AwA,我们使用85维的类级属性向量,对于CUB,我们使用连续的312为类级属性向量。
实验结果如下:

关系网络为什么能工作
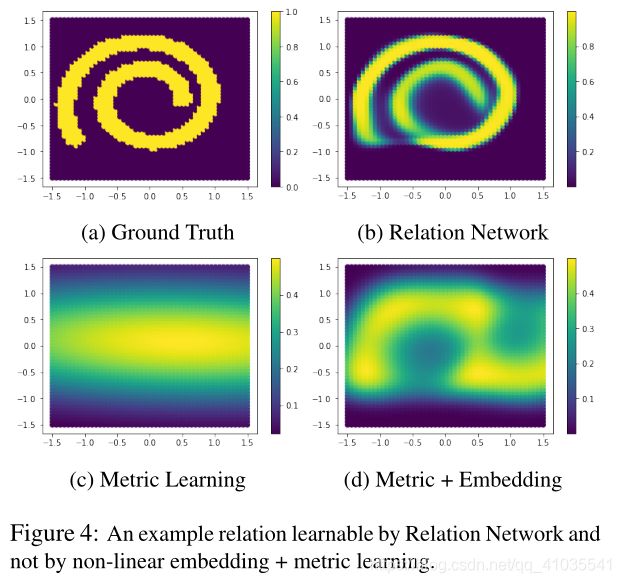
在few-shot领域中,先前的方法一般使用固定的预先设定的距离度量(欧氏距离、余弦距离),这些研究可以被视为距离度量学习,但是所有的学习均发生在特征嵌入的过程中。而这篇paper创新性的提出了完全使用神经网络来学习这种度量方式,并且使用元学习的训练方式(也就是说度量方式不在是人为的提前进行设置,而是通过神经网络自己学习),即关系网络被视为既学习深度嵌入又学习深度非线性度量。
为了验证使用神经网络来学习的度量方式比认为设计的好,作者做了个实验。这个实验室一个二维数据的比较实验,比如这样两个数据(1,2)和(-2,-1),这两个数据看起来是不相关的,但是它们在某一些状态下可能属于同一个类别。那么这种情况,其实传统的人为设计的度量方式实际上就失效了。我们只能通过神经网络去学习这种度量。所以像下图这样复杂的螺旋曲线关系数据情况,我们通过关系网络(relation network)可以学的不错,而人为度量则完全不行。结果如下图所示:
在一个真实的问题中,比较嵌入的困难可能没有这么极端,但它仍然具有挑战性。我们定性地说明了匹配两个Omniglot示例query图像(投影到二维空间),方法是将两个query样本(黄色的点)与真实的样本图像进行匹配,如果真实的样本与query样本匹配就绘制成蓝绿色的点,如果不匹配就绘制成洋红色的点。我们可以看出,匹配关系较为复杂,不能仅通过最近邻进行匹配。接下来作者将2D样本进行主成分分析(PCA),我们可以看到,关系网络已经将数据映射到一个空间中,在这个空间中,匹配对和不匹配是线性可分的。也就是说需要我们的网络去学习一个非线性的度量方式。结果如下图所示:

参考链接:
论文原文:Learning to Compare: Relation Network for Few-Shot Learning
Learning to Compare : Relation Network
Learning to Compare: Relation Network for Few-Shot Learning.论文笔记
Learning to Compare: Relation Network for Few-Shot Learning 少量样本的对比学习