三维点云学习(6)6-3D Object Detection-KITTI object detection evaluation(1)-result from the ground truth
三维点云学习(6)6-3D Object Detection-KITTI object detection evaluation(1)-result from the ground truth
使用kitti检测物体检测评价标准,result数据为ground truth修改

博客参考:
强烈推荐,前两个博客!!!:
Hit_HSW的博客 —KITTI数据使用序列——3D Object检测数据集使用
jane_xueting的博客 —KITTI 3D objection detection results evaluation
一文多图搞懂KITTI检测数据集下载使用(附网盘链接)
KITTI 3D目标检测离线评估工具包说明
KITTI 3D Object Detection Evaluation 结果评估程序
代码参考,大神github
label_2数据集下载:
复制这段内容后打开百度网盘手机App,操作更方便哦
链接:https://pan.baidu.com/s/17Rh10G1UYx2IogelJPl_9Q 提取码:Gb2j
主要流程
step1 环境配置
Setup the KITTI object detection evaluation environment
ps:主要摘自:jane_xueting的博客
运行kitti检测标准代码,并不需要深度学习库,用ubuntu普通虚拟机也可完成
git clone https://github.com/prclibo/kitti_eval.git
#进入到 kitti_eval的目录下
g++ -O3 -DNDEBUG -o evaluate_object_3d_offline evaluate_object_3d_offline.cpp
#若出现 #inlcudestep2 阅读 devkit 开发手册,了解result需要的固定数据格式
devkit 下载
复制这段内容后打开百度网盘手机App,操作更方便哦
链接:https://pan.baidu.com/s/17alhE0aF_cyrUvUCaUWM8g 提取码:QXKE
ps:主要摘自:jane_xueting的博客

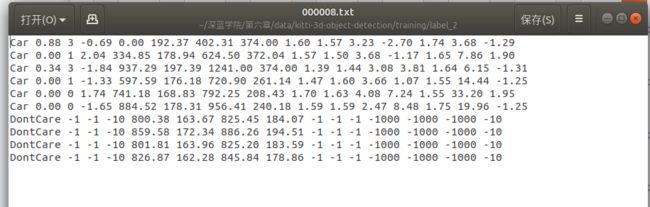
其中第1列truck 表示图中出现了卡车(一共有’Car’, ‘Van’, ‘Truck’,‘Pedestrian’, ‘Person_sitting’, ‘Cyclist’, ‘Tram’,‘Misc’ or 'DontCare’这些类别,Don’t care 是没有3D标注的,原因是雷达扫不了那么远,即使可以视觉检测出来)
第2列0.0表示其是否被截断的程度为0。(如果车在图片边缘,那么就有可能发生部分被截断的情况。用0-1 表示被截断的程度。)
第3列0表示没有被遮挡。(0表示完全可见,1表示部分遮挡,2表示大部分被遮挡,3表示未知。)
第4列 -1.57 表示卡车中心与相机中心构成的矢量与在bird view下的夹角为-1.57,实际上就是说明改开叉在-90,即正前方。这个信息反映目标物体中心在bird view相对方向信息。
第5-8列的599.41 156.40 629.75 189.25是目标的2D bounding box 像素位置,形式为xyxy,前两个值为bounding box左上点的x,y位置,后两个点为右下角的x,y位置。
第9-11列 2.85 2.63 12.34 表示该车的高度,宽度,和长度,单位为米。(H,W,L)
第12-14列 0.47 1.49 69.44 表示该车的3D中心在相机坐标下的xyz坐标。
第15列 -1.56 表示车体朝向,绕相机坐标系y轴的弧度值。注意和第4列区别开来,第四列不在乎车体朝向,而是车体中心与相机中心所构成矢量在与相机坐标系z轴的夹角(其实这里笔者有点疑虑,如果车体中心位置已知,车体朝向是不知道的,但是第4列的alpha是可以算出来的,那么其实第4列的数据是冗余的?)
第十六列,检测的置信度
step3 生成 results 数据
这里我们使用ground truth的label数据修改,得到result数据,观察检测结果
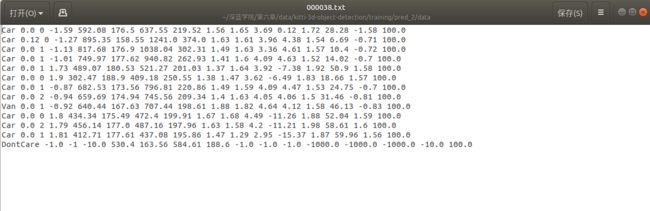
 输出的resul数据和label数据比较,主要比标签多了第16个值,第16个值为confidence置信度,表示形式为score
输出的resul数据和label数据比较,主要比标签多了第16个值,第16个值为confidence置信度,表示形式为score
下载的 训练集 label_2:
部分数据展示:其中,DontCare为非物体类
 1.创建文件夹
1.创建文件夹
根据evaluate_object_3d_offline.cpp中 gtdir result_dir的路径要求
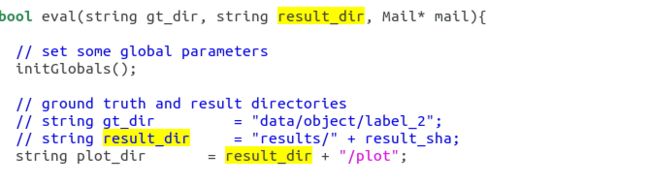
创建文件夹
label_2中存放kitti训练集label_2
pred_2文件夹中创建data文件夹,用于存放result
 2.根据ground truth 生成result
2.根据ground truth 生成result
Generate Object Detection Results Using Ground Truth
这里使用大神github 代码 --create_pred_from_ground_truth.py
运行方式
注意修改自己的label_2路径,和生成result路径
# create object detection results from ground truth labels:
./create_pred_from_ground_truth.py -i /workspace/data/kitti-3d-object-detection/training/label_2/ -o /workspace/data/kitti-3d-object-detection/training/pred_2/
运行结果:生成以下文件
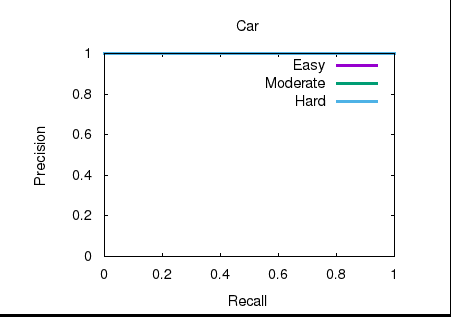
 可以看到,生成的result 的confidence为100,当然置信度可以根据自己喜好调整观看评价后效果
可以看到,生成的result 的confidence为100,当然置信度可以根据自己喜好调整观看评价后效果
3.使用KITTI进行数据检测,观看标准
运行:
# run:
./kitti_eval_node /workspace/data/kitti-3d-object-detection/training/label_2/ /workspace/data/kitti-3d-object-detection/training/pred_2/
运行过程:
 运行结果:
运行结果:
生成如下文件:
 输出AP:
输出AP:


#create_pred_from_ground_truth.PY
#!/opt/conda/envs/deep-detection/bin/python
import argparse
import os
import glob
import pandas as pd
import progressbar
def generate_detection_results(input_dir, output_dir):
"""
Create KITTI 3D object detection results from labels
"""
# create output dir:
os.mkdir(
os.path.join(output_dir, 'data')
)
# get input point cloud filename:
for input_filename in progressbar.progressbar(
glob.glob(
os.path.join(input_dir, '*.txt')
)
):
# read data:
label = pd.read_csv(input_filename, sep=' ', header=None)
label.columns = [
'category',
'truncation', 'occlusion',
'alpha',
'2d_bbox_left', '2d_bbox_top', '2d_bbox_right', '2d_bbox_bottom',
'height', 'width', 'length',
'location_x', 'location_y', 'location_z',
'rotation'
]
# add score:
label['score'] = 100.0
# create output:
output_filename = os.path.join(
output_dir, 'data', os.path.basename(input_filename)
)
label.to_csv(output_filename, sep=' ', header=False, index=False)
def get_arguments():
"""
Get command-line arguments
"""
# init parser:
parser = argparse.ArgumentParser("Generate KITTI 3D Object Detection result from ground truth labels.")
# add required and optional groups:
required = parser.add_argument_group('Required')
# add required:
required.add_argument(
"-i", dest="input", help="Input path of ground truth labels.",
required=True, type=str
)
required.add_argument(
"-o", dest="output", help="Output path of detection results.",
required=True, type=str
)
# parse arguments:
return parser.parse_args()
if __name__ == '__main__':
# parse arguments:
arguments = get_arguments()
generate_detection_results(arguments.input, arguments.output)