Fordeal的数据平台调度系统之前是基于Azkaban进行二次开发的,但是在用户层面、技术层面都存在一些痛点问题难以被解决。比如在用户层面缺少任务可视化编辑界面、补数等必要功能,导致用户上手难体验差。在技术层面,架构过时,持续迭代难度大。基于这些情况,经过竞品对比和调研后,Fordeal数据平台新版系统决定基于Apache DolphinScheduler进行升级改造。那整个迁移过程中开发人员是如何让使用方平滑过渡到新系统,又做出了哪些努力呢?
5月 Apache Dolphinscheduler 线上 Meetup, 来自 Fordeal 的大数据开发工程师卢栋给大家分享了平台迁移的实践经验
讲师介绍

卢栋Fordeal 大数据开发工程师。5年的数据开发相关经验,目前就职于Fordeal,主要关注的数据技术方向包括:湖仓一体、MPP数据库、数据可视化等。
本次演讲主要包含四个部分:
- Fordeal数据平台调度系统的需求分析
- 迁移到Apache Dolphin Scheduler过程中如何适配
- 适配完成后如何完成特新增强
- 未来规划
01 需求分析
01 Fordeal 应用背景
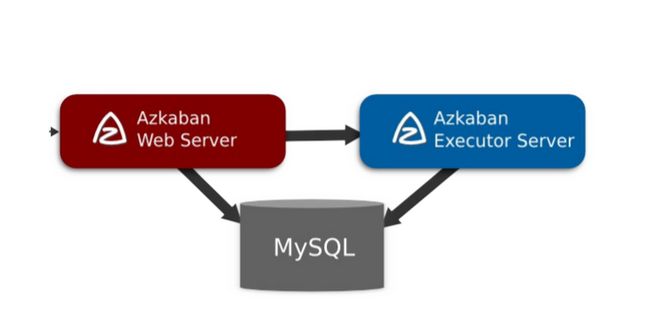
Fordeal 数据平台调度系统最早是基于Azkaban进行二次开发的。支持机器分组,SHELL动态参数、依赖检测后勉强可以满足使用,但在日常使用中依然存在以下三个问题,分别是在用户、技术和运维的层面。
首先在用户层面,缺乏可视化的编辑、补数等必要的功能。只有技术的同学才能使用该调度平台,而其他没有基础的同学如果使用就非常容易出错,并且Azkaban 的报错模式导致开发人员对其进行针对性地进行修改。
第二在技术层面,Fordeal 数据平台调度系统的技术架构非常陈旧,前后端并不分离,想要增加一个功能,二开的难度非常高。
第三在运维层面,也是最大的问题。系统不定时会出来 flow 执行卡死的问题。要处理这个问题,需要登录到数据库,删除 execution flow里面的ID,再重启 Worker 和 API服务,过程十分繁琐。
02 Fordeal 所做的调研
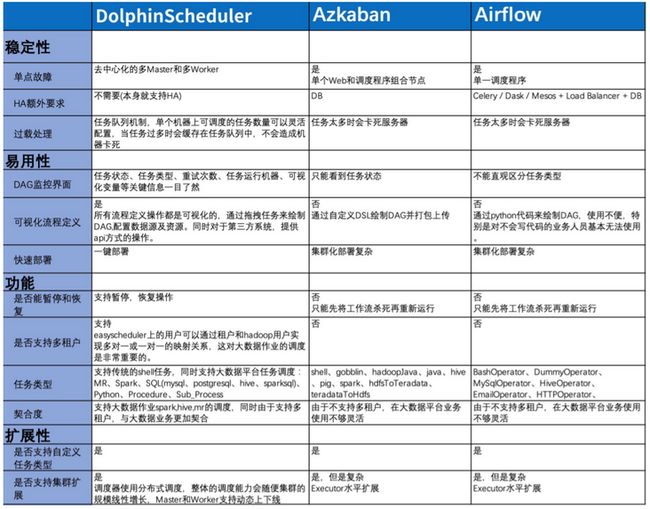
因此,在2019年Apache DolphinScheduler开源时,我们就及时地关注到,并开始了解是否可以进行迁移。当时一同调研了三款软件,Apache Dolphin Scheduler、Azkaban和Airflow。我们基于五大需求。
首选JVM系语言。因为JVM系语言在线程、开发文档等方面较为成熟。
Airflow基于Python其实和我们现在的体系并无二异,非技术同学无法使用
- 分布式架构,支持HA。Azkaban的work并不是分布式web和master服务是耦合在一起,因此属于单节点。
- 工作流必须支持DSL和可视化编辑。这样可以保证技术同学可以用DSL进行书写,可视化则面向用户,用以扩大用户面。
- 前后端分离,主流架构。前后端可以分开进行开发,剥离开来后耦合度也会降低。
- 社区活跃度。最后关注的的社区活跃度对于开发也十分重要,如果经常存在一些“陈年”老bug都需要自己进行修改,那会大大降低开发效率。
03 Fordeal 现在的架构
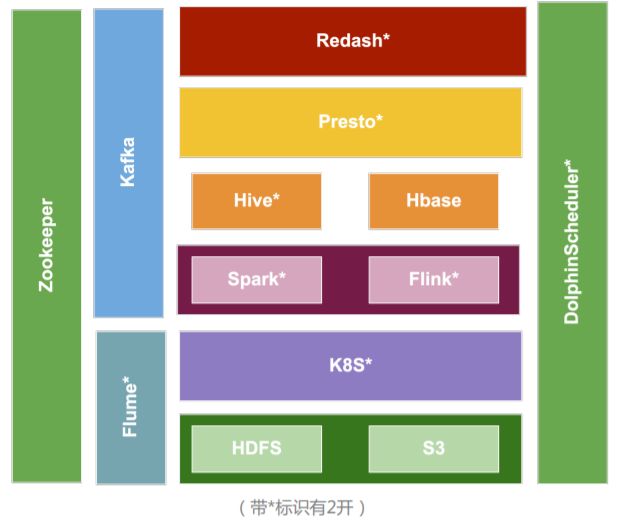
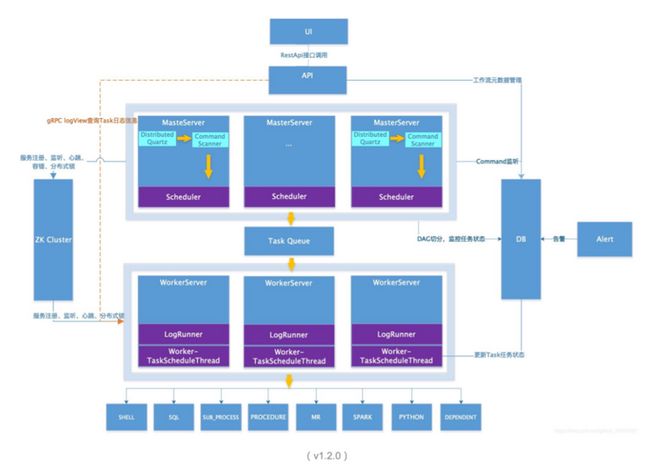
如今我们的数据架构如上图。Apache Dolphin Scheduler承接了整个生命周期从HDFS、S3采集到K8S计算再到基于Spark、Flink的开发。两边的olphinScheduler和Zookeeper都是作为基础性的架构。我们的调度信息如下:Master x2、Worker x6、API x1(承载接口等),目前日均工作流实例:3.5k,日均任务实例15k+。(下图为1.2.0版本架构图)
02 适配迁移
01 内部系统对接
Fordeal内部系统需要上线对用户提供访问,这时候必须对接几个内部服务,以降低用户上手成本和减少运维工作。主要包括以下三个系统。
单点登录系统:
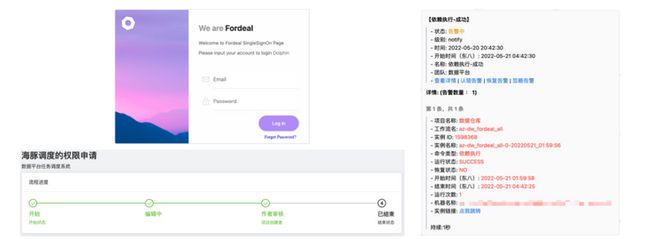
基于JWT实现的SSO系统,一次登录,认证所有。
工单系统:
DS对项目的授权接入工单,避免人肉运维。
(接入所有授权动作,实现自动化)
告警平台:
扩展DS告警模式,将告警信息全部发送到内部告警平台,用户可配置电话、企业微信等模式告警。
下方三张图就是对应分别是登录系统、工单权限和企业微信的告警。
02 Azkaban 的兼容
Azkaban的Flow管理是基于自定义的DSL配置,每个Flow配置包含的Node数量多则800+少则1个,其更新的方式主要有三类。
1、用户本地保存,每次修改后zip压缩上传,用户自行维护Flow的信息。2、所有的flow配置和资源都托管git,在Azkaban项目设置中绑定git地址,git是由我们自行开发的,git提交后在页面点击刷新按钮。3、所有的Flow托管到配置中心,对接Azkaban的上传接口去覆盖掉之前的调度信息。
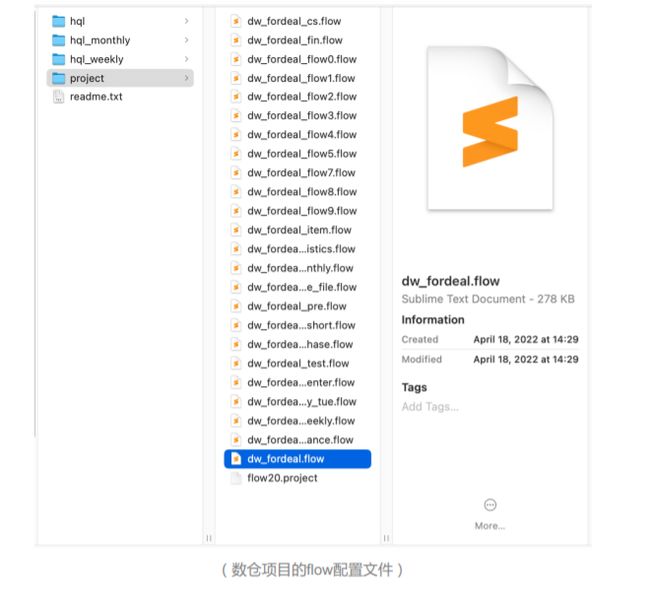
上图为一部分数仓项目的flow配置文件。想要把Azkaban迁移到Apache DolphinScheduler中,我们一共列出了十点需求。
- DS上传接口支持Flow配置文件的解析并生成工作流。(支持嵌套flow)Flow的配置文件就相当于 Azkaban 的DAG文件,如果不配适我们就要自己写代码解析配置文件,将Flow转成Json。
- DS资源中心支持文件夹(托管Azkaban项目下的所有资源)当时我们的1.2.0版本当时没有文件夹功能,而我们的数仓有许多文件夹,因此我们必须要支持。
- DS提供client包,提供基础的数据结构类和工具类,方便调用API,生成工作流的配置。
- DS支持工作流并发控制(并行或跳过)
- DS时间参数需支持配置时区(例如:dt=$[ZID_CTT yyyy-MM=dd=1])。虽然我们配置的时区大多在海外,但对于用户而言,他们更希望看到北京时区。
- DS跑数和部署界面支持全局变量覆写。因为我们的版本较低,一些类似补数的功能都没有,工作流用什么变量跑,希望用户可以自己设置。
- DS DAG图支持task多选操作。
- DS task日志输出最终执行内容,方便用户检查调试。
- DS 支持运行中失败任务手动重试。通常一次跑数仓需要数个小时,其中有几个task可能因为代码问题报错,我们希望可以在不中断任务流的情况下,手动重试,把错误的节点逐一修改完后重试。这样最终的状态是成功的。
- 数仓项目需支持一键迁移,保持用户的工作习惯(jenkins 对接DS)。
在我们与五六个组进行不断的沟通和改造后,这十点需求最终满足。
03 功能优化汇总
从 Azkaban 完全迁移到 Apache DolphinScheduler 完成大概用时一年,因为涉及到API用户,涉及到 git 用户,还有支持各种各样功能用户,每个项目组都会提出自己的需求,在协助其他团队迁移的整个过程中,根据用户使用反馈,共提交了140+个优化 commit,以下是 commit 分类词云。

03 特性增强
01 前端重构
对于为什么我们要重构,我们的痛点到底是什么?我们列出了一下几点。首先,Azkaban的操作步骤过于繁琐。用户想要找一个工作流定义时,首先要打开项目,找到项目首页中的工作流列表,再找到定义,用户无法一眼找到我想要的定义。第二,我无法通过名字、分组等条件检索到工作流定义和实例。第三,无法通过URL分享工作流定义和实例详情。第四,数据库表和API设计不合理,查询卡顿,经常会出现长事务告警。第五,界面很多地方写死布局,如设置了宽度,导致添加列不能很好适配电脑和手机。第六,工作流定义和实例缺少批量操作。凡是程序肯定有错误,如何批量重试,成为用户非常头疼的问题。
执行方案
- 基于 AntDesign 库开发新的一套前端界面。
弱化项目概念,不想让用户过多去关注项目这个概念,项目只作为工作流或实例的标签。
目前电脑版只有四个入口,首页、工作流列表、执行列表和资源中心列表,手机版只有两个入口,分别是工作流列表和执行列表。
- 简化操作步骤,将工作流列表和执行列表放在第一入口。
优化查询条件和索引,增加批量操作接口等。
增加联合索引。
- 完全适配电脑和手机(除了编辑 dag ,其他功能都一致)
02 依赖调度
什么是依赖调度?即工作流实例或 Task 实例成功后主动出发下游工作流或 Task 跑数(执行状态为依赖执行)。设想以下几个场景,下游工作流需要根据上游工作流的调度时间去设置自己的定时时间;上游跑数失败后,下游定时跑数是也会出现错误;上游补数,只能通知所有下游业务方补数。数仓上下游定时间隔调整难,计算集群资源利用率没有最大化(K8S)。因为用户并不是持续提交的。
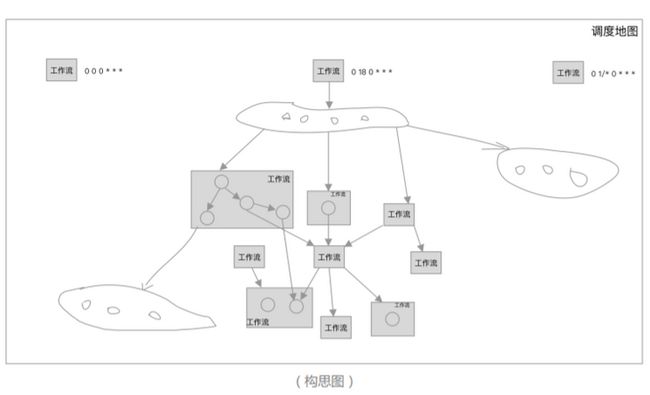
构思图(按层触发工作流)
依赖调度规则
- 工作流支持时间,依赖,两者组合调度(且与或)
- 工作流内的Task支持依赖调度(不受定时限制)。
- 依赖调度需要设置一个依赖周期,只有当所有的依赖在这个周期内满足才会触发。
- 依赖调度最小的设置单位是 Task ,支持依赖多个工作流或 Task (只支持且关系)。
- 工作流仅仅只是一个执行树中的组概念,就是说不会限制Task。
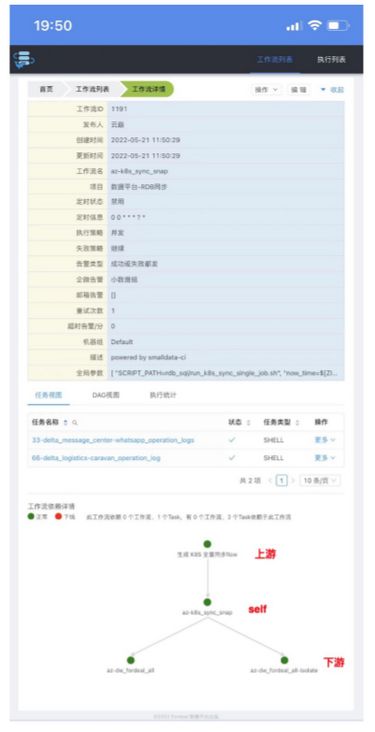
手机工作流依赖详情
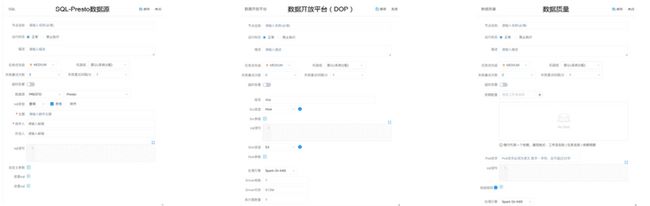
03 任务拓展
拓展更多的 Task 类型,将常用的功能抽象并提供编辑界面,降低使用成本,我们主要扩展了以下几个。
数据开放平台(DOP):
主要是提供数据导入导出功能(支持Hive、Hbase,Mysql、ES、Postgre、Redis、S3)
数据质量:基于Deequ开发的数据校验。
对数据进行抽象供用户使用。
- **SQL-Prest数据源:**SQL模块支持Presto数据源
- 血缘数据采集:内置到所有Task中,Task暴露血缘需要的所有数据
04 监控告警
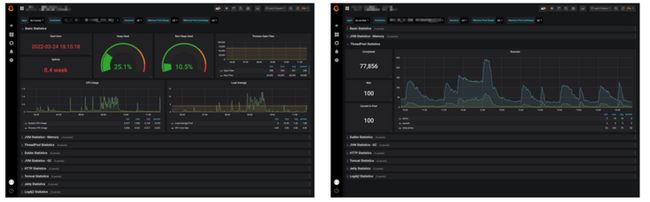
架构为Java+Spring下的服务监控,平台是有一套通用的Grafana监控看板,监控数据存储在Prometheus,我们的原则是服务内部不做监控,只需要把数据暴露出来即可,不重复造轮子,改造列表为:
- API、Master和Worker服务接入micrometer-registry-prometheus,采集通用数据并暴露Prometheus采集接口。
- 采集Master和Worker执行线程池状态数据,如Master和Worker正在运行的工作流实例、数据库等,用于后续的监控优化和告警(下右图)。
- Prometheus侧配置服务状态异常告警,比如一段时间内工作流实例运行数小于n(阻塞)、服务内存&CPU告警等等。
04 未来规划
01 跟进社区特性
目前Fordeal线上运行的版本是基于社区第一个**Apache版本(1.2.0)**进行二开的,通过监控我们也发现了几个问题。
- 数据库压力大,网络IO费用高
- Zookeeper 充当了队列角色,时不时对导致磁盘IOPS飙升,存在隐患
- Command 消费和Task分发模型比较简单,导致机器负载不均匀
- 这个调度模型中使用了非常多的轮询逻辑(Thread.sleep),调度消费、分发、检测等效率不高
社区发展迅速,当下的架构也更加的合理易用,很多问题得到了解决,我们近期比较关注的问题是Master直接对Worker的分发任务,减轻Zookeeper 的压力,**Task 类型插件化,易于后续扩展。**Master配置或自定义分发逻辑,机器复杂更加合理。更完美的容错机制和运维工具(优雅上下线),现在Worker没有优雅上下线功能,现在更新Worker的做法是切掉流量,让线程池归零后再上下线,比较安全。
02 完善数据同步
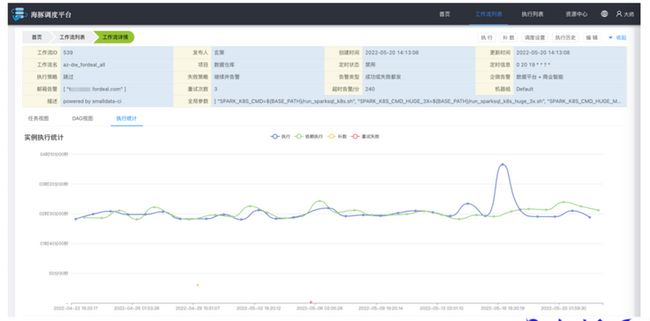
目前只提供了工作流实例的执行统计,粒度比较粗,后续需要支持更细化的统计数据,如按照 Task 筛选进行统计分析,按照执行树进行统计分析,按照最耗时的执行路径分析等(对其进行优化)。
再次,增加更多的数据同步功能,如执行统计添加同步、环比阈值告警等功能,这些都是基于工作流的告警。
03 连接其他系统
当调度迭代稳定后,会逐步充当基础组件使用,提供更加便利的接口和可嵌入的窗口(iframe),让更多的上层数据应用(如BI系统,预警系统)等对接进来,提供基础的调度功能。
我的分享就到这里,谢谢大家认真阅读!