【自然语言处理】【多模态】OFA:通过简单的sequence-to-sequence学习框架统一架构、任务和模态
论文地址:https://arxiv.org/pdf/2202.03052.pdf
相关博客:
【自然语言处理】【多模态】CLIP:从自然语言监督中学习可迁移视觉模型
【自然语言处理】【多模态】ViT-BERT:在非图像文本对数据上预训练统一基础模型
【自然语言处理】【多模态】BLIP:面向统一视觉语言理解和生成的自举语言图像预训练
【自然语言处理】【多模态】FLAVA:一个基础语言和视觉对齐模型
【自然语言处理】【多模态】SIMVLM:基于弱监督的简单视觉语言模型预训练
【自然语言处理】【多模态】UniT:基于统一Transformer的多模态多任务学习
【自然语言处理】【多模态】Product1M:基于跨模态预训练的弱监督实例级产品检索
【自然语言处理】【多模态】ALBEF:基于动量蒸馏的视觉语言表示学习
【自然语言处理】【多模态】VinVL:回顾视觉语言模型中的视觉表示
【自然语言处理】【多模态】OFA:通过简单的sequence-to-sequence学习框架统一架构、任务和模态
一、简介
在人工智能领域,建立一个能像人类处理多任务和多模态的全能模型是一个有吸引力的目标。这个目标的核心问题是在单一模型中表达大量不同模态、任务和训练机制。
Transformer \text{Transformer} Transformer架构近期的发展已经展示出其成为通用计算引擎的潜力。在监督学习的设置中,预训练-微调范式在许多领域实现了巨大的成功,并且few-/zero-shot学习的机制中,具有prompt/instruction tuning的语言模型被证明是强力的few-/zero-shot学习器。这些进步为全能模型的出现提供了更重要的机会。
为了在保持多任务性能和易用性的同时,更好的支持开放域问题的泛化能力,作者主张全能模型应用具有下面的三个性质:(1) 任务无关( TA \text{TA} TA):统一任务的表示来支持不同类型的任务,包括分类、生成、自监督任务等,并且对于预训练或者微调是不可知的;(2) 模态无关( MA \text{MA} MA):在所有的任务中,对于处理不同的模态统一输入和输出表示;(3) 任务全面( TC \text{TC} TC):足够多样的任务来增加泛化能力的积累。
然而,要在实现优越性能的同时满足上面的三个性质是具有挑战性的。由于下面的设计选择,当前的语言和多模态预训练模型很容易在某些性质上不满足。(1) 用于微调的额外可学习组件,例如:任务相关的头、adapters和soft propmts。这使得模型具有任务相关性,从而违反了 TA \text{TA} TA。此外,寻找最优组件也十分困难,并且这样的设计对于未见过任务的zero-shot并不友好。(2) 任务相关的形式。对于大多数当前的方法,预训练、微调和zero-shot通常在任务形式和训练目标是不同。这违反了 TA \text{TA} TA,并且通过增加任务数量来实现 TC \text{TC} TC是一种负担。(3) 针对各种I/O的模态相关设计。 VL \text{VL} VL预训练模型的通常做法是将检测到的目标作为输入特征来改善下游任务的表现。然而,这种模态相关的设计使得图像和目标的概念纠缠在一起。这使得在任务无关模型中很难将模型与图像生成、或者目标检测一起训练。
因此,作者探索了用于多模态预训练的全面模型,并提出了模型 OFA,One For All \text{OFA,One For All} OFA,One For All,其实现了统一架构、模态和任务的目标,并支持上面的三个属性。具体来说,将预训练和微调任务形式化为统一的sequence-to-sequence,并通过手工的instructions来实现任务任务无关。 Transformer \text{Transformer} Transformer作为模态无关的计算引擎,其具有一个约束,不可学习的任务相关或者模态相关组件将会被添加至下游任务。其可以表示不同模型的信息,通过一个跨所有任务的全局共享多模态词表。
总的来说:
-
作者提出了 OFA \text{OFA} OFA,一个支持全面任务的任务不可知且模态不可知框架。其通过具有
instruction简单的seq-to-seq学习框架统一了任务,包括理解和生成,例如:image generation、visual grounding、visual question answering、image captioning、image classification、language modeling。 -
实验结果显示 OFA \text{OFA} OFA在多模态基准上实现了新的 SOTA \text{SOTA} SOTA,包括:
image captioning、text-to-image generation、VQA、SNLI-VE等; -
作者证明了 OFA \text{OFA} OFA在
zero-shot学习中实现了有竞争力的表现。此外,其能够通过新的任务instruction迁移至未见过的任务,并且不适应微调的情况下适应领域外信息。
二、OFA
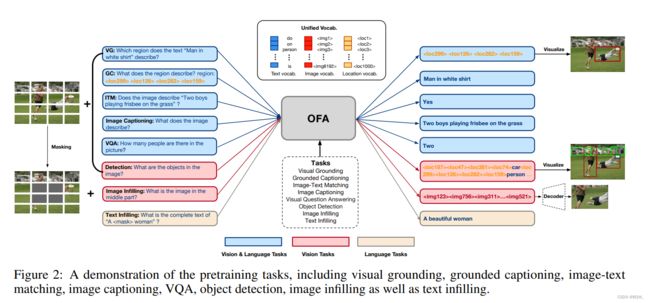
OFA \text{OFA} OFA整体架构如上图所属。
1. I/O&架构
- I/O
多模态预训练需要在大规模image-text语料上预训练 Transformer \text{Transformer} Transformer模型。为了能够进行多模态预训练,需要对数据进行预处理使得视觉和语言信息能够被 Transformer \text{Transformer} Transformer联合处理。相比于复杂且耗时、耗资源的目标特征抽,本文简化这个过程,直接将一个图像 x v ∈ R H × W × C \textbf{x}_{v}\in\mathbb{R}^{H\times W\times C} xv∈RH×W×C划分为 P P P个patches,并且将patches投影至hidden size为 H H H的特征。在处理语言信息时,遵循 GPT \text{GPT} GPT和 BART \text{BART} BART实践,应用byte-pair encoding(BPE)来将给定的文本序列转换为子词序列,然后将其嵌入成特征。
为了以任务不相关的输出模式来处理不同的模态,在统一的空间中表示各种模态的数据是有必要的。一种可能的解决方案是离散化文本、图像和目标至一个统一的输出词表。近期在图像量化上的进展已经证明了text-to-image合成的有效性,因此本文在目标端的图像表示上利用这个策略。稀疏编码在缩减图像表示的序列长度时是有效的。例如,一个分辨率为 256 × 256 256\times 256 256×256的图像被表示为长度为 16 × 16 16\times 16 16×16的code序列。每个离散的编码都与对于的patch强相关。
除了表示图像以外,表示图像中的目标是有必要的,因为有一系列区域相关的任务。遵循先前的工作,将目标表示为离散tokens的序列。具体来说,对于每个目标,抽取它的标签和它的bounding box。bounding box的连续角坐标被统一离散化为整数来作为位置tokens ⟨ x 1 , y 1 , x 2 , y 2 ⟩ \langle x_1,y_1,x_2,y_2 \rangle ⟨x1,y1,x2,y2⟩。为了更加的简单,为所有的语言和视觉tokens使用统一的词表,包括:字词、image codes和location tokens。
- 架构
遵循先前多模态预训练成功的实践,选择 Transformer \text{Transformer} Transformer作为backbone架构,并且采用encoder-decoder网络作为所有预训练、微调以及zero-shot任务的架构。具体来说,encoder和decoder都是堆叠的 Transformer \text{Transformer} Transformer层。一个 Transformer \text{Transformer} Transformer编码层由自注意力和 FFN \text{FFN} FFN组成,而 Transformer \text{Transformer} Transformer解码器则是由自注意力机制、 FFN \text{FFN} FFN和连接解码器和编码器输出表示的交叉注意力组成。为了稳定训练并且加速收敛,添加了自注意力的head scaling、一个后注意力的layer normalization,以及在第一层 FFN \text{FFN} FFN后的 LN \text{LN} LN层。
2. 任务&模态
一个统一的框架被设计来提供跨不同模态和下游任务的架构能力,从而在同一模型中泛化至未见过的任务。该模型需要在统一的范式中呈现不同模型下尽可能的下游任务。因此,预训练任务的设计需要考虑多任务和多模态。
为了统一任务和模态,作者设计了sequence-to-sequence学习范式来预训练、微调和推理所有的任务。这些任务包括:预训练任务、下游的跨模态和单模态任务、以及所有Seq2Seq形式的生成任务。在多模态和单模态上执行多任务预训练能够使模型具有综合能力。具体来说,在所有任务上共享统一的schema,同时为区分不同的任务提供手工的instructions。
对于跨模态表示学习,设计了5个任务,包含visual grounding(VG)、grounded captioning(GC)、image-text matching(ITM)、image captioning(IC)以及visual question answering(VQA)。对于 VG \text{VG} VG,模型会基于图像 x i x_i xi和instruction Which region dose the text x t describe? \text{Which region dose the text }x_t\text{ describe?} Which region dose the text xt describe?来生成具体位置 ⟨ x 1 , y 1 , x 2 , y 2 ⟩ \langle x_1,y_1,x_2,y_2 \rangle ⟨x1,y1,x2,y2⟩的location tokens,其中 x t x_t xt是区域caption。 GC \text{GC} GC是 VG \text{VG} VG的逆任务。模型会基于输入图像 x i x_i xi和instruction What does the region describe?region: ⟨ x 1 , y 1 , x 2 , y 2 ⟩ \text{What does the region describe?region:}\langle x_1,y_1,x_2,y_2 \rangle What does the region describe?region:⟨x1,y1,x2,y2⟩来生成描述。对于 ITM \text{ITM} ITM,使用原始的image-text对作为正样本,然后通过图像与caption的随机配对来构造负样本。模型学习判断给定的图像和文本是否配对来学习生成Yes或者No,基于图像 x i \text{x}_i xi和instruction Does the image describe x t ? \text{Does the image describe }x_t? Does the image describe xt?。对于image captioning,这个任务能够天然的采用sequence-to-sequence形式。模型会基于给定的图像和instruction What does the image describe? \text{What does the image describe?} What does the image describe?来学习生成caption。对于 VQA \text{VQA} VQA,将图像和问题作为输入,并需要模型学习生成正确的答案。
对于单模态表示学习,为视觉设计了2个任务,语言设计了1个任务。模型通过图像infilliing和目标检测来预训练学习视觉表示。在计算机视觉的生成自监督学习中的近期进展显示masked image modeling是一个有效的预训练任务。实践中,将遮蔽了中间部分的图像作为输入。模型从基于被破坏输入的图像和instruction What is the image in the middle part? \text{What is the image in the middle part?} What is the image in the middle part?来生成图像中心部分的稀疏编码。此外,在预训练中额外添加了目标检测任务。模型基于图像输入和文本 What are the objects in the image? \text{What are the objects in the image?} What are the objects in the image?来学习生成人工标注的目标表示,即目标位置和标签的序列。对于语言表示学习,则通过在文本数据上进行文本填充来预训练。
通过这种方式,将多种模态和多种任务统一至单个模型和预训练范式中。 OFA \text{OFA} OFA是联合这些任务和数据预训练的。因此,它可以针对不同的模态和复杂的跨模态场景执行不同的任务,并具有生成答案的能力。
3. 预训练数据集
通过合并视觉语言数据、视觉数据和语言数据来构建预训练数据集。为了可复现,仅使用公开数据集。作者通过仔细的过滤预训练数据来排除下游任务中的验证和测试集图像,以避免数据泄露。
4. 训练&推断
使用交叉熵损失函数来优化模型。给定一个输入 x x x,一个instruction s s s和一个输出 y y y,通过最小化损失函数 L = − ∑ i = 1 ∣ y ∣ log P θ ( y i ∣ y < i , x , s ) \mathcal{L}=-\sum_{i=1}^{|y|}\text{log} P_\theta(y_i|y_{beam search,来增强生成的质量。然而,这种范式在分类任务中有几个问题:(1) 优化整个词表是不必要且效率低下;2. 在推断过程中,模型可能会生成超过封闭标签集的无效标签。为了克服这些问题,作者在训练时和推断时引入了基于前缀树的搜索策略。实验结果显示基于前缀树搜索的策略能够增强 OFA \text{OFA} OFA在分类任务上的效果。
三、实验
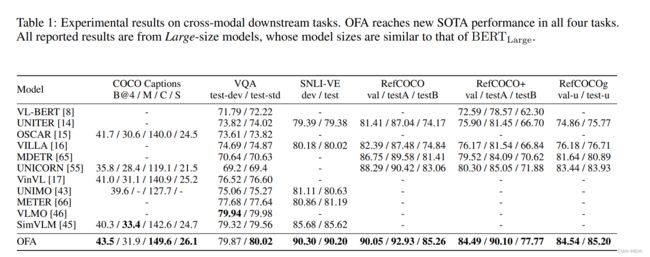
- OFA \text{OFA} OFA在跨模型的下游任务中实现了 SOTA \text{SOTA} SOTA
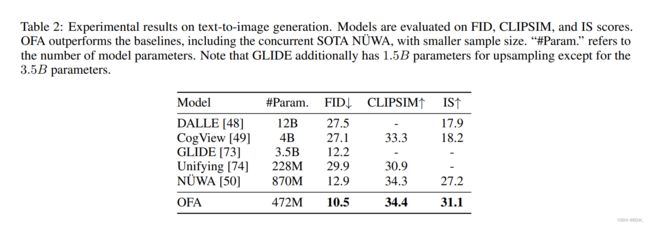
text-to-image生成任务的结果, OFA \text{OFA} OFA超越了baseline。
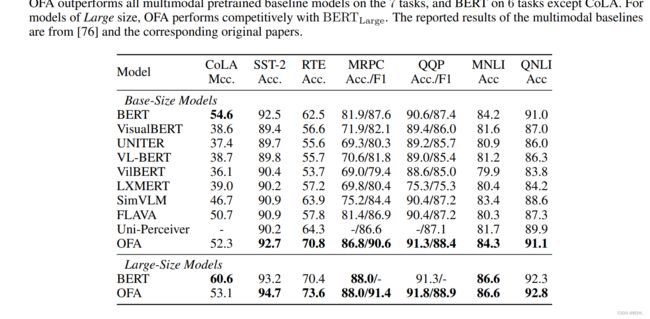
- BERT \text{BERT} BERT和多模态预训练模型在 GLUE \text{GLUE} GLUE上的结果, OFA \text{OFA} OFA优于所有的多模态预训练baseline。
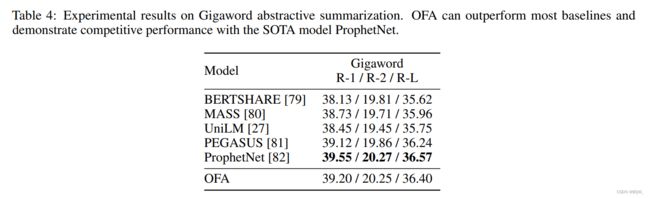
Gigaword生成式摘要的结果。 OFA \text{OFA} OFA好于大多数的baseline。
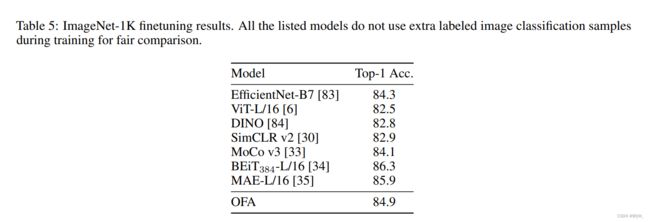
- 在 ImageNet-1K \text{ImageNet-1K} ImageNet-1K上微调的结果。
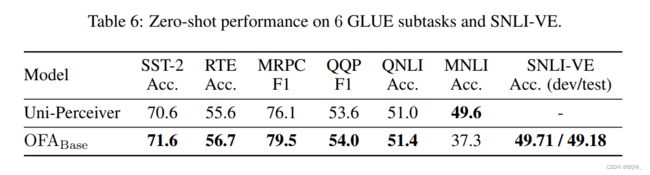
- 在6个 GLUE \text{GLUE} GLUE子任务和 SNLI-VE \text{SNLI-VE} SNLI-VE上的
zero-shot效果