【论文阅读】ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS
【论文阅读】ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS
前言
在 BERT 提出之后,各种大体量的预训练模型层出不穷,在他们效果不断优化的同时,带来的是巨大的参数量和漫长的训练时间。当然对于这个问题,也有大量的研究。ALBERT是谷歌在 BERT 基础上设计的一个精简模型,主要为了解决 BERT 参数过大、训练过慢的问题。
Overview
整体模型的架构还是与 BERT 相同,使用 Transformer encoder 和 GELU 激活函数,与 BERT 相比 ALBERT 主要做了如下三点改变:
A Lite BERT (ALBERT)使用了两种减少参数的方法来降低模型大小和提高训练速度:
- Factorized embedding parameterization:Embedding 分解
- Cross-layer parameter sharing:参数共享
除此之外,论文将 BERT 中的Next Sentence Prediction (NSP)问题修改为Sentence-order Prediction (SOP),并引入了一个新的损失函数:
- Inter-sentence coherence loss
但是 ALBERT 的层数并未减少,因此推理时间(Inference Time)还是没有得到改进。不过参数减少的确使得训练变快。
模型架构
Factorized embedding parameterization
论文发现,在 BERT 以及后续提出的 XLNet 和 RoBERTa 这些预训练模型中,都将 E E E(embedding size)和 H H H(hidden size)绑定,例如 E ≡ H E\equiv H E≡H。然而在实际的自然语言处理任务中 V V V(vocabulary size)都是一个较大的值,如果 E ≡ H E \equiv H E≡H那么当 H H H增大时, E E E也需要增大,这也将导致最终的参数量 O ( V × H ) O(V \times H) O(V×H)变得非常大。因此作者在 ALBERT 中将 E E E和 H H H进行了解绑。
具体来说,论文将 Embedding 的参数分解为两个较小的矩阵,即先将 one-hot 投影到大小为 E E E的低维嵌入空间,再将其投影到隐藏空间。通过这样的操作之后, E E E永远不会改变,如果 H H H增大,也只需要进行一个简单的变换即可。参数规模从 O ( V × H ) O(V \times H) O(V×H)减少到 O ( V × E + E × H ) O(V \times E + E \times H) O(V×E+E×H),可以显著减少参数量,在 H ≫ E H \gg E H≫E时尤其明显。
举个例子: V = 30000 , H = 512 , E = 128 V=30000,H=512,E=128 V=30000,H=512,E=128
V × H = 30000 × 512 = 15360000 V \times H = 30000 \times 512 = 15360000 V×H=30000×512=15360000
V × E + E × H = 30000 × 128 + 128 × 512 = 3905536 V \times E + E \times H = 30000 \times 128 + 128 \times 512 = 3905536 V×E+E×H=30000×128+128×512=3905536
从实验数据来看,与同等级的 BERT 模型相比,ALBERT 确实更为轻量,在保证一定准确度的同时,训练速度大大提高。

Cross-layer parameter sharing

在传统 Transformer 中,每一层的参数都是相互独立的,这也意味着随着模型层数的加深,参数量也会明显上升。作者尝试将所有的参数进行共享,这使得多层的 Attention 实际上变成了一层 Attention 的叠加。
作者也通过对比实验发现,共享 Feed Forward 层参数会对精度带来较大的影响,而共享 Attention 层参数的影响则较小。

另外一方面,作者通过比较每一层输入和输出的欧式距离和余弦距离发现,参数共享对模型的稳定性有一定帮助:

Inter-sentence coherence loss
在 BERT 中,作者引入了一个二分类问题,预测下一个句子,Next Sentence Prediction (NSP)。但是在 XLNet 和 RoBERTa 论文中均阐明了 NSP 的无效性,认为其对下游的任务并不可靠。作者任务 NSP 失效的主要原因是缺乏难度。
{% note info no-icon %}
原本 NSP 是来预测一个句子是不是另一个句子的下一个句子。这个任务的问题出在训练数据上面,正例就是用的一个文档里面连续的两句话,但是负例使用的是不同文档里面的两句话。这就导致这个任务包含了主题预测在里面,而主题预测又要比两句话连续性的预测简单太多。

NSP 的本质是topic prediction和coherence prediction,相对来说 topic prediction 更加容易学习,而且也与使用 MLM 损失学习到的内容有更多的重叠。
{% endnote %}
针对这个问题,ALBERT 提出了另一个任务 Sentence-order Prediction (SOP)。在 SOP 中,正样本与 NSP 中相同,负样本交换两句话的顺序。
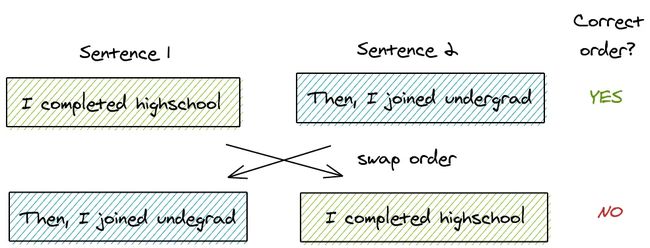
Positive example
Input = [CLS] the man went to [MASK] store [SEP]
he bought a gallon [MASK] milk [SEP]
Label = IsNext
Negative example
Input = [CLS]he bought a gallon [MASK] milk [SEP]
the man went to [MASK] store [SEP]
Label = NotNext

总结
总体来说,ALBERT 确实在很大程度上减少到了模型参数,加快了训练,虽然对于推理时间并没有改进,虽然 xxlarge 版本的参数还是非常大。
参考资料
- [1] ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
- Visual Paper Summary: ALBERT (A Lite BERT)
- ALBERT 详解