Nuscenes数据集转换voc_xml格式用于yolov4训练
1、下载nuscenes数据集
数据集下载地址https://www.nuscenes.org/download,这里下载v1.0-mini为例。
2、转换nuscenes的json格式(3D转2D)
nuscenes数据集采用的是三维框标注的格式,因此需要先将3D标注框转化为2D格式。下载官方工具nuscenes-devkit
需要使用到的文件是:/nuscenes-devkit/python-sdk/nuscenes/scripts/export_2d_annotations_as_json.py
该文件有以下5种选项,分别是:
--dataroot/ 是我们下载的MetaData的路径
--version/ 是我们需要转化的json文件的存放文件夹名
--filename/ 是我们对生成的2D框的json文件的保存名称
--visibilities/
--image_limit
运行该export_2d_annotations_as_json.py文件即可生成2D-box型的json文件:
python export_2d_annotations_as_json.py --dataroot ~/nuscenes --version v1.0-mini --filename 2D-box.json
此时3D标注转2D标注完成。
3、2D的json转txt
在github上找到一个nuscenes 2D框转为COCO格式的一个工程https://github.com/AlizadehAli/2D_label_parser,但是该项目会有点问题:
nuscenes-mini数据集中一共有23种类别,分别是:
"human.pedestrian.adult",
"human.pedestrian.child",
"human.pedestrian.wheelchair",
"human.pedestrian.stroller",
"human.pedestrian.personal_mobility",
"human.pedestrian.police_officer",
"human.pedestrian.construction_worker",
"vehicle.bicycle",
"vehicle.motorcycle",
"vehicle.car",
"vehicle.bus.bendy",
"vehicle.bus.rigid",
"vehicle.truck",
"vehicle.emergency.ambulance",
"vehicle.emergency.police",
"vehicle.construction",
"movable_object.barrier",
"movable_object.trafficcone",
"movable_object.pushable_pullable",
"movable_object.debris",
"static_object.bicycle_rack"
"vehicle.trailer",
"animal"
【问题1】在该项目的代码中,作者在转换类别的同时,将上述的类别进行了合并,但是遗漏了两个类别:
if 'pedestrian' in name['category_name']:
obj_class = 0
elif 'bicycle' in name['category_name']:
obj_class = 1
elif 'motorcycle' in name['category_name']:
obj_class = 2
elif 'car' in name['category_name']:
obj_class = 3
elif 'bus' in name['category_name']:
obj_class = 4
elif 'truck' in name['category_name']:
obj_class = 5
elif 'emergency' in name['category_name']:
obj_class = 6
elif 'construction' in name['category_name']:
obj_class = 7
elif 'movable_object' in name['category_name']:
obj_class = 8
elif 'bicycle_rack' in name['category_name']:
obj_class = 9
# 遗漏了这两个类别:
"vehicle.trailer",
"animal"
导致这两个类别的目标在转换的时候默认为0,即"pedestrian"类,可能会导致之后检测的时候所有这两个类别的物体全部检测为行人,导致错误。
(PS:我当时修改了这部分代码,改成我需要的之后,发现检测结果中有很多其他的目标也检测为行人的,后来才发现了这个问题)
开始修改:
import os
from os import walk, getcwd
import json
from typing import List, Any
from PIL import Image
from tqdm import tqdm
import argparse
__author__ = "Ali Alizadeh"
__email__ = '[email protected] / [email protected]'
__license__ = 'AA_Parser'
def parse_arguments():
parser = argparse.ArgumentParser(
description='YOLOv3 json, Berkeley Deep Drive dataset (BDD100K), nuscenes 2D labels to txt-label format for '
'yolov3 darknet NN model')
parser.add_argument("-dt", "--data_type",
default="nuscenes",
help="data type of interest; yolo, bdd, nuscenes")
parser.add_argument("-l", "--label_dir", default="./labels/",
help="root directory of the labels for YOLO json file, Berkeley Deep Drive (BDD) json-file, "
"nuscenes")
parser.add_argument("-s", "--save_dir", default="./target_labels/",
help="path directory to save the the converted label files")
parser.add_argument("-i", "--image_dir",
default=None, required=False,
help="path where the images are located to BDD100K, nescenes, etc.")
parser.add_argument("-o", "--output_dir",
default=None, required=False,
help="output directory to save the manipulated image files")
args = parser.parse_args()
return args
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[2]) / 2.0
y = (box[1] + box[3]) / 2.0
w = box[2] - box[0]
h = box[3] - box[1]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def collect_bdd_labels(bdd_label_path):
bdd_json_list = []
for file in tqdm(os.listdir(bdd_label_path)):
if file.endswith(".json"):
bdd_json_list.append(file)
return bdd_json_list
def sync_labels_imgs(label_path, img_path):
for path, subdirs, files in tqdm(os.walk(img_path)):
for file in tqdm(files):
if file.lower().endswith('jpg'):
image_folders_path = img_path + path.split('/')[-1]
image_path = os.path.join(image_folders_path, file)
image_path = image_path.split('.')[0] + '.txt'
if not os.path.isdir(image_path):
os.remove(image_path)
def write_training_data_path_synced_with_labels(img_path):
with open('nuscenes_training_dataPath.txt', 'w') as train_data_path:
for path, subdirs, files in os.walk(img_path):
for file in files:
if file.lower().endswith('png'):
full_path = os.path.join(path, file)
full_path = full_path.split('.')[0] + '.txt'
full_path = 'images/' + path.split('/')[-1] + '/' + full_path.split('/')[-1]
train_data_path.write(str(full_path) + os.linesep)
train_data_path.close()
def bdd_parser(bdd_label_path):
bdd_json_list = collect_bdd_labels(bdd_label_path)
label_data: List[Any] = []
for file in tqdm(bdd_json_list):
label_data.append(json.load(open(bdd_label_path + file)))
return label_data
def yolo_parser(json_path, targat_path):
json_backup = "./json_backup/"
wd = getcwd()
list_file = open('%s_list.txt' % (wd), 'w')
json_name_list = []
for file in tqdm(os.listdir(json_path)):
if file.endswith(".json"):
json_name_list.append(file)
""" Process """
for json_name in tqdm(json_name_list):
txt_name = json_name.rstrip(".json") + ".txt"
""" Open input text files """
txt_path = json_path + json_name
print("Input:" + txt_path)
txt_file = open(txt_path, "r")
""" Open output text files """
txt_outpath = targat_path + txt_name
print("Output:" + txt_outpath)
txt_outfile = open(txt_outpath, "a")
""" Convert the data to YOLO format """
lines = txt_file.read().split('\r\n')
for idx, line in tqdm(enumerate(lines)):
if ("lineColor" in line):
break
if ("label" in line):
x1 = float(lines[idx + 5].rstrip(','))
y1 = float(lines[idx + 6])
x2 = float(lines[idx + 9].rstrip(','))
y2 = float(lines[idx + 10])
cls = line[16:17]
""" in case when labelling, points are not in the right order """
xmin = min(x1, x2)
xmax = max(x1, x2)
ymin = min(y1, y2)
ymax = max(y1, y2)
img_path = str('%s/dataset/%s.jpg' % (wd, os.path.splitext(json_name)[0]))
im = Image.open(img_path)
w = int(im.size[0])
h = int(im.size[1])
print(w, h)
print(xmin, xmax, ymin, ymax)
b = (xmin, xmax, ymin, ymax)
bb = convert((w, h), b)
print(bb)
txt_outfile.write(cls + " " + " ".join([str(a) for a in bb]) + '\n')
os.rename(txt_path, json_backup + json_name) # move json file to backup folder
""" Save those images with bb into list"""
if txt_file.read().count("label") != 0:
list_file.write('%s/dataset/%s.jpg\n' % (wd, os.path.splitext(txt_name)[0]))
list_file.close()
def nuscenes_parser(label_path, target_path, img_path):
json_backup = "json_backup/"
wd = getcwd()
dict = {
'human.pedestrian.adult': '0',
'human.pedestrian.child': '0',
'human.pedestrian.wheelchair': '0',
'human.pedestrian.stroller': '0',
'human.pedestrian.personal_mobility': '0',
'human.pedestrian.police_officer': '0',
'human.pedestrian.construction_worker': '0',
'vehicle.bicycle': '1',
'vehicle.motorcycle': '2',
'vehicle.car': '3',
'vehicle.bus.bendy': '4',
'vehicle.bus.rigid': '4',
'vehicle.truck': '5',
'vehicle.emergency.ambulance': '6',
'vehicle.emergency.police': '6',
'vehicle.construction': '7', # 工程用车,挖掘机啥的
'vehicle.trailer': '8',
'animal': '9'
}
json_name_list = []
for file in tqdm(os.listdir(label_path)):
if file.endswith(".json"):
json_name_list.append(file)
data = json.load(open(label_path + file))
# Aggregate the bounding boxes associate with each image
unique_img_names = []
for i in tqdm(range(len(data))):
unique_img_names.append(data[i]['filename'])
unique_img_names = list(dict.fromkeys(unique_img_names))
i: int
for i in tqdm(range(len(unique_img_names))):
f = open(target_path + unique_img_names[i].split('/')[1] + '/' +
unique_img_names[i].split('/')[-1].split('.')[0] + '.txt', "w+")
for idx, name in enumerate(data):
if unique_img_names[i] == name['filename']:
# 加上一个判定条件,符合上面类别才会将坐标写入txt中
if name['category_name'] in dict:
obj_class = dict[name['category_name']]
x, y, w, h = convert((1600, 900), name['bbox_corners'])
temp = [str(obj_class), str(x), str(y), str(w), str(h), '\n']
L = " "
L = L.join(temp)
f.writelines(L)
f.close()
sync_labels_imgs(target_path, img_path)
n = open('nuscenes.names', "w+")
n.write('pedestrian \n')
n.write('bicycle \n')
n.write('motorcycle \n')
n.write('car \n')
n.write('bus \n')
n.write('truck \n')
n.write('emergency \n')
n.write('animal \n')
n.close()
write_training_data_path_synced_with_labels(img_path)
if __name__ == '__main__':
args = parse_arguments()
if args.data_type == 'yolo':
yolo_parser(args.label_dir, args.save_dir)
elif args.data_type == 'bdd':
data = bdd_parser(args.label_dir)
elif args.data_type == 'nuscenes':
nuscenes_parser(args.label_dir, args.save_dir, args.image_dir)
else:
print(40 * '-')
print('{} data is not included in this parser!'.format(args.data_type))
在target_label目录下新建六个文件夹,即CAM_BACK、CAM_BACK_LEFT、CAM_BACK_RIGHT、CAM_FRONT、CAM_FRONT_LEFT、CAM_FRONT_RIGHT文件夹,然后开始运行:
python label_parse.py
就会在上面的文件夹中生成对应的txt文件。
至此转换完成。
4、txt转xml
#############################################################
# #### txt to xml
#############################################################
import os
import xml.etree.ElementTree as ET
from xml.etree.ElementTree import Element, SubElement
from PIL import Image
import cv2
dict = {
'0': 'pedestrian',
'1': 'bicycle',
'2': 'motorcycle',
'3': 'car',
'4': 'bus',
'5': 'truck',
'6': 'emergency',
'7': 'vehicle.construction',
'8': 'vehicle.trailer',
'9': 'animal'
}
class Xml_make(object):
def __init__(self):
super().__init__()
def __indent(self, elem, level=0):
i = "\n" + level * "\t"
if len(elem):
if not elem.text or not elem.text.strip():
elem.text = i + "\t"
if not elem.tail or not elem.tail.strip():
elem.tail = i
for elem in elem:
self.__indent(elem, level + 1)
if not elem.tail or not elem.tail.strip():
elem.tail = i
else:
if level and (not elem.tail or not elem.tail.strip()):
elem.tail = i
def _imageinfo(self, list_top):
annotation_root = ET.Element('annotation')
annotation_root.set('verified', 'no')
tree = ET.ElementTree(annotation_root)
'''
0:xml_savepath 1:folder,2:filename,3:path
4:checked,5:width,6:height,7:depth
'''
folder_element = ET.Element('folder')
folder_element.text = list_top[1]
annotation_root.append(folder_element)
filename_element = ET.Element('filename')
filename_element.text = list_top[2]
annotation_root.append(filename_element)
path_element = ET.Element('path')
path_element.text = list_top[3]
annotation_root.append(path_element)
checked_element = ET.Element('checked')
checked_element.text = list_top[4]
annotation_root.append(checked_element)
source_element = ET.Element('source')
database_element = SubElement(source_element, 'database')
database_element.text = 'Unknown'
annotation_root.append(source_element)
size_element = ET.Element('size')
width_element = SubElement(size_element, 'width')
width_element.text = str(list_top[5])
height_element = SubElement(size_element, 'height')
height_element.text = str(list_top[6])
depth_element = SubElement(size_element, 'depth')
depth_element.text = str(list_top[7])
annotation_root.append(size_element)
segmented_person_element = ET.Element('segmented')
segmented_person_element.text = '0'
annotation_root.append(segmented_person_element)
return tree, annotation_root
def _bndbox(self, annotation_root, list_bndbox):
for i in range(0, len(list_bndbox), 8):
object_element = ET.Element('object')
name_element = SubElement(object_element, 'name')
name_element.text = list_bndbox[i]
# flag_element = SubElement(object_element, 'flag')
# flag_element.text = list_bndbox[i + 1]
pose_element = SubElement(object_element, 'pose')
pose_element.text = list_bndbox[i + 1]
truncated_element = SubElement(object_element, 'truncated')
truncated_element.text = list_bndbox[i + 2]
difficult_element = SubElement(object_element, 'difficult')
difficult_element.text = list_bndbox[i + 3]
bndbox_element = SubElement(object_element, 'bndbox')
xmin_element = SubElement(bndbox_element, 'xmin')
xmin_element.text = str(list_bndbox[i + 4])
ymin_element = SubElement(bndbox_element, 'ymin')
ymin_element.text = str(list_bndbox[i + 5])
xmax_element = SubElement(bndbox_element, 'xmax')
xmax_element.text = str(list_bndbox[i + 6])
ymax_element = SubElement(bndbox_element, 'ymax')
ymax_element.text = str(list_bndbox[i + 7])
annotation_root.append(object_element)
return annotation_root
def txt_to_xml(self, list_top, list_bndbox):
tree, annotation_root = self._imageinfo(list_top)
annotation_root = self._bndbox(annotation_root, list_bndbox)
self.__indent(annotation_root)
tree.write(list_top[0], encoding='utf-8', xml_declaration=True)
def txt_2_xml(source_path, xml_save_dir, txt_dir):
COUNT = 0
for folder_path_tuple, folder_name_list, file_name_list in os.walk(source_path):
for file_name in file_name_list:
file_suffix = os.path.splitext(file_name)[-1]
if file_suffix != '.jpg':
continue
list_top = []
list_bndbox = []
path = os.path.join(folder_path_tuple, file_name)
xml_save_path = os.path.join(xml_save_dir, file_name.replace(file_suffix, '.xml'))
txt_path = os.path.join(txt_dir, file_name.replace(file_suffix, '.txt'))
filename = os.path.splitext(file_name)[0]
checked = 'NO'
img = cv2.imread(path)
height, width, depth = img.shape
# print(height, width, depth)
# im = Image.open(path)
# im_w = im.size[0]
# im_h = im.size[1]
# width = str(im_w)
# height = str(im_h)
# depth = '3'
flag = 'rectangle'
pose = 'Unspecified'
truncated = '0'
difficult = '0'
list_top.extend([xml_save_path, folder_path_tuple, filename, path, checked,
width, height, depth])
for line in open(txt_path, 'r'):
line = line.strip()
info = line.split(' ')
name = dict[info[0]]
x_cen = float(info[1]) * width
y_cen = float(info[2]) * height
w = float(info[3]) * width
h = float(info[4]) * height
xmin = int(x_cen - w / 2)
ymin = int(y_cen - h / 2)
xmax = int(x_cen + w / 2)
ymax = int(y_cen + h / 2)
list_bndbox.extend([name, pose, truncated, difficult,
str(xmin), str(ymin), str(xmax), str(ymax)])
Xml_make().txt_to_xml(list_top, list_bndbox)
COUNT += 1
print(COUNT, xml_save_path)
if __name__ == '__main__':
source_path = r'/home/ZT/ZT_Project/yolov4/VOCdevkit/VOC2007/JPEGImages' # txt标注文件所对应的的图片
xml_save_dir = r'/home/ZT/ZT_Project/yolov4/VOCdevkit/VOC2007/Annotations' # 转换为xml标注文件的保存路径
txt_dir = r'/home/ZT/ZT_Project/yolov4/VOCdevkit/VOC2007/TXT' # 需要转换的txt标注文件
txt_2_xml(source_path, xml_save_dir, txt_dir)
修改上面代码main函数中的三个路径,此时就能在Annotations文件夹中生成对应的xml文件。
此时需要验证一下图片和标注文件是否对应,有可能数目对不上,JPEGImages文件夹中是nuscenes-mini数据集中samples文件夹下的所有图片,Annotations为刚刚生成的文件夹:
import xml.dom.minidom
import os
# 改为自己的目录
root_path = '/home/ZT/dataset/VOCdevkit/VOC2007/'
annotation_path = root_path + 'TXT/'
img_path = root_path + 'JPEGImages/'
annotation_list = os.listdir(annotation_path)
img_list = os.listdir(img_path)
# for _ in annotation_list:
# xml_name = _.split('.')[0]
# img_name = xml_name + '.jpg'
# if img_name not in img_list:
# print("error xml:", img_name)
# print('ok')
if len(img_list) != len(annotation_list):
print("图片和标签数目不匹配")
if len(img_list) < len(annotation_list):
print("标签比图片多")
error_xml = []
for _ in annotation_list:
xml_name = _.split('.')[0]
img_name = xml_name + '.jpg'
if img_name not in img_list:
error_xml.append(_)
os.remove(_)
print("error xml:", error_xml)
else:
print("图片比标签多")
error_img = []
for _ in img_list:
img_name = _.split('.')[0]
xml_name = img_name + '.txt'
if xml_name not in annotation_list:
error_img.append(_)
os.remove(_)
print("缺少标签的图片:", error_img)
此时数据集已经准备完成。
5、开始训练YOLOv4
本文中采用的是这个大神的代码,https://github.com/bubbliiiing/yolov4-tiny-pytorch,以yolov4-tiny为例。
(1)按上面的步骤准备好nuscenes数据集,按照VOC文件目录格式排好;
(2)制作nuscenes_classes.txt,内容为自己的类别,和上面生成txt和xml的类别以及顺序对应:
pedestrian
bicycle
motorcycle
car
bus
truck
emergency
vehicle.construction
vehicle.trailer
animal
(3)下载yolov4-tiny代码以及对应的权重(github上均能找到),修改以下文件:
【voc_annotation.py】:
# classes_path 改为自己的类别的目录
classes_path = 'model_data/nuscenes_classes.txt'
# 修改数据集的路径
VOCdevkit_path = '/home/ZT/dataset/VOCdevkit'
开始运行即可在文件夹下生成2007_train.txt和2007_val.txt两个文件:
python voc_annotation.py
2007_train.txt和2007_val.txt内容如下:
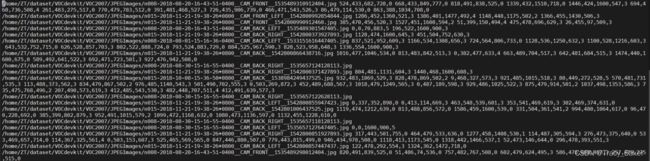 【不长这样的就是有问题的,数据集的问题,肯定有哪一步走错了】
【不长这样的就是有问题的,数据集的问题,肯定有哪一步走错了】
【train.py】
# classes_path 改为自己的类别的目录
classes_path = 'model_data/nuscenes_classes.txt'
# model_path 改为下载的权重的路径
model_path = 'model_data/yolov4_tiny_weights_voc_CBAM.pth'
# phi的值和权重对应,具体看代码和作者的GitHub讲解
# -------------------------------#
# 所使用的注意力机制的类型
# phi = 0为不使用注意力机制
# phi = 1为SE
# phi = 2为CBAM
# phi = 3为ECA
# -------------------------------#
phi = 2
# 修改训练的epoch
Init_Epoch = 0
Freeze_Epoch = 100
Freeze_batch_size = 64
Freeze_lr = 1e-3
# ----------------------------------------------------#
# 解冻阶段训练参数
# 此时模型的主干不被冻结了,特征提取网络会发生改变
# 占用的显存较大,网络所有的参数都会发生改变
# ----------------------------------------------------#
UnFreeze_Epoch = 200
Unfreeze_batch_size = 32
Unfreeze_lr = 1e-4
(4)开始训练。
python train.py