第二章 复杂的HTML解析(下)
2.3 正则表达式
计 算 机 科 学 领 域 有 个 笑 话 :“ 如 果 你 有 一 个 问 题 打 算 用 正 则 表 达 式 来 解 决 , 那 么 就 是 两 个问题了。”
看到这就话,除了有一点好笑外还很让人好奇:
(1)什么是正则表达式?
(2)它很难学吗?
(3)它是怎么使用的呢?
接下来,我们围绕这三个问题去学习。
首先我们来解决第二个问题:
其实正则表达式上手一点儿也不难,而且运行很快,通过一些简单的例子就可以轻松地
学会。
不难、很快、轻松学会……这是原文作者说的,不是我说的。
然后看第一个问题:
正则表达式:通过识别正则字符串,快速过滤、查找关键信息。
之所以叫正则表达式,是因为它们可以识别正则字符串(regular string);也就是说,它们
可以这么定义:“如果你给我的字符串符合规则,我就返回它”,或者是“如果字符串不符合 规 则 , 我 就 忽 略 它 ”。 这 在 快 速 浏 览 大 文 档 , 以 查 找 像 电 话 号 码 和 邮 箱 地 址 之 类 的 字 符串时,是非常方便的。
由此可知,正则表达式是由正则字符串构成的。
那么,什么是正则字符串呢?
其实就是任意可以用一系列线性规则构成的字符串 。
比如:
(1) 字母“a”至少出现一次;
(2) 后面跟着字母“b”,重复 5 次;
(3) 后面再跟字母“c”,重复任意偶数次;(4) 最后一位是字母“d”或“e”。
满足此条件的字符串有无数种:
abbbbbccd
aaabbbbbcccce
……
那么,我们想要找出给定范围内的这种字符串,就需要制定一个规则,满足这个规则的就是我们所需要的,这种规则就叫做“正则表达式”。
例如上述示例的正则表达式为:
aa*bbbbb(cc)*(d|e)
乍一看,这什么玩意儿。结合上面的条件仔细观察,奥~,原来如此:
正则表达式剖析:
aa*bbbbb(cc)*(d|e)
aa*:a*(读作a星),表示a可以出现n次(n>=0),前面在加个a表示a至少出现一次。
bbbbb:没啥说的,就是5个b。
(cc)*:双c可以出现n次(n>=0)。
(d|e):| 表示或,表示要么是d要么是e。
书中给了提示:
尝试正则表达式
在学习书写正则表达式的时候,通过实验来感受一下它们如何工作,这是至
关重要的。如果你不想打开代码编辑器,写几行代码,然后再运行程序以检
查正则表达式的运行是否符合预期,那么你可以去 Regex Pal 这类网站在线
测试你的正则表达式。
下面的卡片就是文中的那个网站,好像需要注册,还是个国外网站,嗯……不会用,你们可以去搜教程,我本人喜欢这个网站正则表达式在线测试 | 菜鸟工具 (runoob.com)Regex Tester - Javascript, PCRE, PHP (regexpal.com) https://www.regexpal.com/
https://www.regexpal.com/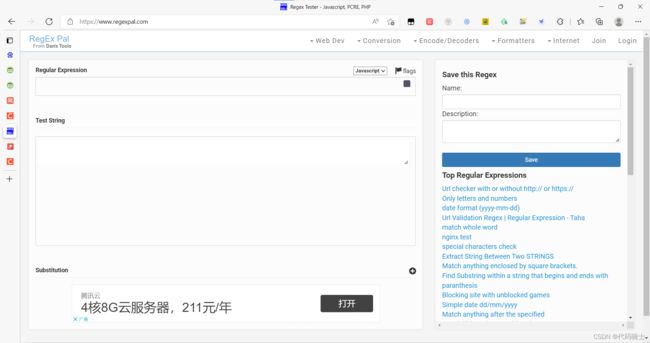
这是菜鸟教程的正则表达式测试网址正则表达式在线测试 | 菜鸟工具 (runoob.com)https://c.runoob.com/front-end/854/?optionGlobl=global
非常好用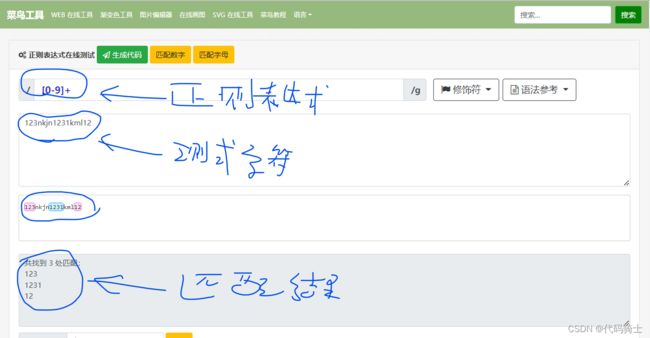
还有配套教程,简单易懂:正则表达式 – 语法 | 菜鸟教程 (runoob.com)https://www.runoob.com/regexp/regexp-syntax.html
列出了常用的正则表达式符号,以及简短的解释和示例。这个列表并没有囊括全部
的正则表达式,正如前面提到的,不同语言中的正则表达式符号会略有不同。但是,这里
列出的 12 个符号是 Python 中最常用的正则表达式符号,可以用于查找和获取几乎任意字
符串类型。
表2-1:常用的正则表达式符号
正则表达式在实际中的一个经典应用是识别邮箱地址。虽然不同邮箱服务器的邮箱地址的
具体规则不尽相同,但是我们还是可以创建几条通用规则。每条规则对应的正则表达式如
下表第 2 列所示。
把上面的规则连接起来,就获得了完整的正则表达式:
[A-Za-z0-9\._+]+@[A-Za-z]+\.(com|org|edu|net)
当动手开始写正则表达式的时候,最好先写一个步骤列表,具体描述出你的目标字符串结
构。还要注意一些细节的处理。比如,当你识别电话号码的时候,会考虑国家代码和分机
号吗?
正则表达式:并非处处正则!
正则表达式的标准版(本书使用的版本,用于 Python 和 BeautifulSoup)是基
于 Perl 语法演变而来的。绝大多数现代编程语言都使用与之相同或近似的版
本。但是要注意,在其他语言中使用这些正则表达式时可能会出问题。有些
语言,比如 Java,其正则表达式就和 Python 不太一样。总之,遇到问题时
看文档!


2.4 正则表达式和BeautifulSoup
在抓取网页的时候,BeautifulSoup 和正则表达式总是配合使用的。其实,大多数支
持字符串参数的函数(比如,find(id="aTagIdHere"))也都支持正则表达式。
举个例子:
目标网页:https://www.pythonscraping.com/pages/page3.html
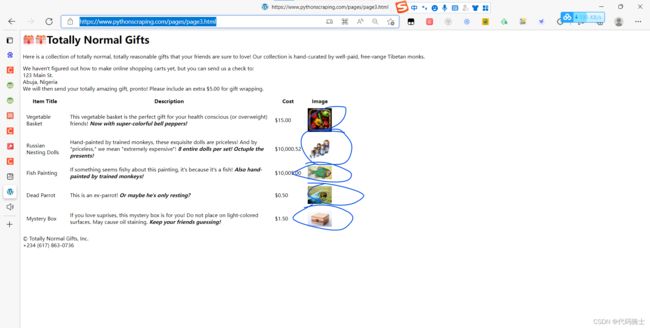
目标代码(所有商品图片):
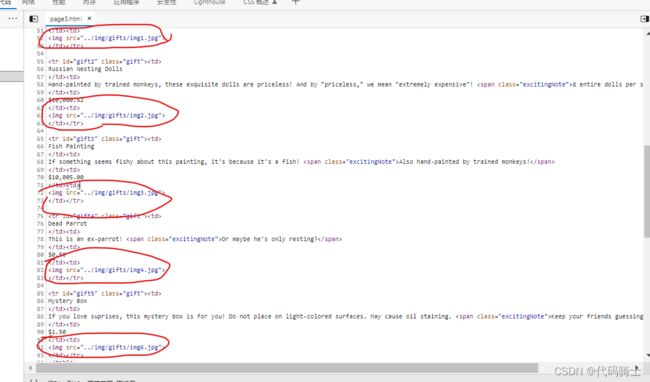
如果我们想抓取所有图片的 URL 链接,非常直接的做法就是用 find_all("img") 抓取所有
图片,对吗?但是有个问题。除了那些明显“多余的”图片(比如 LOGO)之外,现代网
站里都有一些隐藏的图片、用于网页布局留白和元素对齐的空白图片,以及一些不容易察
觉到的图片标签。总之,你不能仅用商品图片来统计网页上所有的图片。
网页的布局也可能会变化,或者,因为某些原因,我们不想通过图片在网页中的位置来查
找标签。当你想抓取随机分布在网站里的某个元素或数据时,可能就是这种情况。例如,
一些网页的最上面可能有一张布局特殊的商品图片,但是另一些网页上则没有。
解决这类问题的办法,就是直接定位那些标签来查找信息。在本例中,我们直接通过商品
图片的文件路径来查找:
程序代码:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
html = urlopen('https://www.pythonscraping.com/pages/page3.html')
bs = BeautifulSoup(html,'html.parser')
images = bs.find_all('img',{'src':re.compile('\.\.\/img\/gifts\/img.*\.jpg')})
for image in images:
print(image['src'])输出结果:

正则表达式可以作为 BeautifulSoup 语句的任意一个参数,让你可以灵活地查找目标元素。
正好借用这个例子再来谈一谈正则表达式:
代码第三行,import re
这里使用了一个python内置re库,专门用来处理正则表达式的,
比如说代码倒数第三行,re.compile()就是调用了re库中的一个compile函数,它的作用:通过re.compile把正则表达式编译成对象,会速度快很多。
接着我们来剖析一下正则表达式:
\.\.\/img\/gifts\/img.*\.jpg
观察目标式子:
\.\. = ..(\是转义字符)
\/img = /img(\是转义字符)
\/gifts = /gifts(\是转义字符)
\/img.* = /img.*(\是转义字符)
所以,图片代码字符串的正则表达式为:\.\.\/img\/gifts\/img.*\.jpg
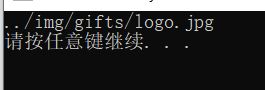
接下来,我们自己写个正则表达式抓取logo的图片代码
目标代码:![]()
正则表达式:\.\.\/img\/gifts\/logo.jpg
修改代码:
images = bs.find_all('img',{'src':re.compile('\.\.\/img\/gifts\/logo.jpg')})输出结果:
常用字符:
(34条消息) 正则表达式_PAL_1024的博客-CSDN博客https://blog.csdn.net/PAL_1024/article/details/108045427
2.5 获取属性
到目前为止,我们已经介绍过如何获取和过滤标签,以及如何获取标签里的内容。但是,
在抓取网页时你经常不需要查找标签的内容,而是需要查找标签属性。比如标签 a 指向的
URL 链接包含在 href 属性中,或者 img 标签的图片文件包含在 src 属性中,这时获取标
签属性就变得非常有用了。
对于一个标签对象,可以用下面的代码获取它的全部属性:
myTag.attrs
要注意这行代码返回的是一个 Python 字典对象,可以轻松获取和操作这些属性。比如要获
取图片的源位置 src,可以用下面这行代码:
myImgTag.attrs['src']
2.6 Lambda(λ)表达式
在这一节里,虽然我们不打算深入学习这类函数,但是会用几个例子来演示它
们是如何用在网页抓取中的。
Lambda 表达式本质上就是一个函数,可以作为变量传入另一个函数;也就是说,一个函
数不是定义成 f(x, y),而是可以定义成 f(g(x), y) 或 f(g(x), h(y)) 的形式。BeautifulSoup 允许我们把特定类型的函数作为参数传入 find_all 函数。唯一的限制条件是
这些函数必须把一个标签对象作为参数并且返回布尔类型的结果。BeautifulSoup 用这个
函数来评估它遇到的每个标签对象,最后把评估结果为“真”的标签保留,把其他标签
剔除。
例如,下面的代码就是获取有两个属性的所有标签:
bs.find_all(lambda tag: len(tag.attrs) == 2)
这里,作为参数传入的函数是 len(tag.attrs) == 2。当该参数为真时,find_all 函数将返
回 tag。即找出带有两个属性的所有标签,如下所示:
Lambda 函数非常实用,你甚至可以用它来替代现有的 BeautifulSoup 函数:
bs.find_all(lambda tag: tag.get_text() ==
'Or maybe he\'s only resting?')
如果不使用 Lambda 函数,代码如下:
bs.find_all('', text='Or maybe he\'s only resting?')
如果你能记住 Lambda 函数的语法,以及如何获取标签的属性,那么你可能再也不需要记
住 BeautifulSoup 的语法了!
由 于 Lambda 函数可以是任意返回 True 或 者 False 值的函数,你甚至可以结合使用
Lambda 函数与正则表达式,来查找匹配特定字符串模式的属性的标签。