【深度学习】深度学习经典数据集汇总
深度学习数据集
Author:louwill
From:深度学习笔记
很多朋友在学习了神经网络和深度学习之后,早已迫不及待要开始动手实战了。第一个遇到的问题通常就是数据。作为个人学习和实验来说,很难获得像工业界那样较高质量的贴近实际应用的大量数据集,这时候一些公开数据集往往就成了大家通往AI路上的反复摩擦的对象。
计算机视觉(CV)方向的经典数据集包括MNIST手写数字数据集、Fashion MNIST数据集、CIFAR-10和CIFAR-100数据集、ILSVRC竞赛的ImageNet数据集、用于检测和分割的PASCAL VOC和COCO数据集等。而自然语言处理(NLP)方向的经典数据集包括IMDB电影评论数据集、Wikitext维基百科数据集、Amazon reviews(亚马逊评论)数据集和Sogou news(搜狗新闻)数据等。
本讲就分别对这些经典数据集和使用进行一个概述。
CV经典数据集
1.MNIST
MNIST(Mixed National Institute of Standards andTechnology database)数据集大家可以说是耳熟能详。可以说是每个入门深度学习的人都会使用MNIST进行实验。作为领域内最早的一个大型数据集,MNIST于1998年由Yann LeCun等人设计构建。MNIST数据集包括60000个示例的训练集以及10000个示例的测试集,每个手写数字的大小均为28*28。在本书的前面一些章节,我们曾多次使用到了MNIST数据集。
MNIST数据集官网地址为http://yann.lecun.com/exdb/mnist/。
MNIST在TensorFlow中可以直接导入使用。在TensorFlow 2.0中使用示例如代码1所示。
代码1 导入MNIST
# 导入mnist模块
from tensorflow.keras.datasets import mnist
# 导入数据
(x_train,y_train), (x_test, y_test) = mnist.load_data()
# 输出数据维度
print(x_train.shape,y_train.shape, x_test.shape, y_test.shape)
输出结果如下。
(60000, 28, 28) (60000,) (10000, 28, 28)(10000,)
可视化展示MNIST 0-9十个数字,如代码2所示,绘制结果如图1。
代码2 绘制MNIST
# 导入相关模块
import matplotlib.pyplot as plt
import numpy as np
# 指定绘图尺寸
plt.figure(figsize=(12,8))
# 绘制10个数字
fori in range(10):
plt.subplot(2,5,i+1)
plt.xticks([])
plt.yticks([])
img = x_train[y_train == i][0].reshape(28,28)
plt.imshow(img, cmap=plt.cm.binary)
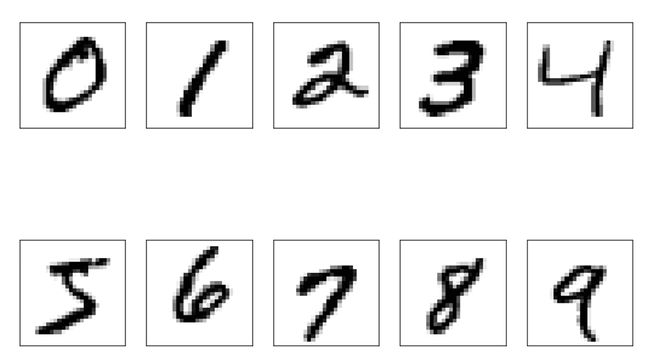
图1 MNIST数据示例
2.Fashion MNIST
可能是见MNIST太烂大街了,德国的一家名为Zalando的时尚科技公司提供了Fashion-MNIST来作为MNIST数据集的替代数据集。Fashion MNIST包含了10种类别70000个不同时尚穿戴品的图像,整体数据结构上跟MNIST完全一致。每张图像的尺寸同样是28*28。
Fashion MNIST数据集地址为:
https://research.zalando.com/welcome/mission/research-projects/fashion-mnist/。
Fashion MNIST同样也可以在TensorFlow中直接导入。如代码3所示。
代码3 导入Fashion MNIST
# 导入fashion mnist模块
from tensorflow.keras.datasets import fashion_mnist
# 导入数据
(x_train,y_train), (x_test, y_test) = fashion_mnist.load_data()
# 输出数据维度
print(x_train.shape,y_train.shape, x_test.shape, y_test.shape)
输出结果如下。
(60000, 28, 28) (60000,) (10000, 28, 28)(10000,)
可视化展示Fashion MNIST 10种类别,如代码4所示。绘制结果如2所示。
代码21.4 绘制Fashion MNIST
# 绘图尺寸
plt.figure(figsize=(12,8))
# 绘制10个示例
fori in range(10):
plt.subplot(2,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
img = x_train[y_train == i][0].reshape(28,28)
plt.imshow(x_train[i], cmap=plt.cm.binary)

图2 Fashion MNIST数据示例展示
3.CIFAR-10
相较于MNIST和Fashion MNIST的灰度图像,CIFAR-10数据集由10个类的60000个32*32彩色图像组成,每个类有6000个图像。有50000个训练图像和10000个测试图像。
CIFAR-10是由Hinton的学生Alex Krizhevsky(AlexNet的作者)和Ilya Sutskever 整理的一个用于识别普适物体的彩色图像数据集。一共包含10个类别的RGB彩色图片:飞机(airplane)、汽车(automobile)、鸟类(bird)、猫(cat)、鹿(deer)、狗(dog)、蛙类(frog)、马(horse)、船(ship)和卡车(truck)。
CIFAR-10的官方地址为https://www.cs.toronto.edu/~kriz/cifar.html。
CIFAR-10在TensorFlow中导入方式如代码5所示。
代码5 导入CIFAR-10
# 导入cifar10模块
from tensorflow.keras.datasets import cifar10
# 读取数据
(x_train,y_train), (x_test, y_test) = cifar10.load_data()
# 输出数据维度
print(x_train.shape,y_train.shape, x_test.shape, y_test.shape)
输出结果如下。
(50000,32, 32, 3) (50000, 1) (10000, 32, 32, 3) (10000, 1)
CIFAR-10的可视化展示如代码6所示。图像示例如图3所示。
代码21.6 绘制CIFAR-10
# 指定绘图尺寸
plt.figure(figsize=(12,8))
# 绘制10个示例
fori in range(10):
plt.subplot(2,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(x_train[i], cmap=plt.cm.binary)

图3 CIFAR-10示例展示
4.CIFAR-100
CIFAR-100可以看作是CIFAR-10的扩大版,CIFAR-100将类别扩大到100个类,每个类包含了600张图像,分别有500张训练图像和100张测试图像。CIFAR-100的100个类被分为20个大类,每个大类又有一定数量的小类,大类和大类之间区分度较高,但小类之间有些图像具有较高的相似度,这对于分类模型来说会更具挑战性。
CIFAR-100数据集地址为https://www.cs.toronto.edu/~kriz/cifar.html。
CIFAR-10在TensorFlow中导入方式如代码7所示。
代码21.7 导入CIFAR-100
# 导入cifar100模块
from tensorflow.keras.datasets import cifar100
# 导入数据
(x_train,y_train), (x_test, y_test) = cifar100.load_data()
# 输出数据维度
print(x_train.shape,y_train.shape, x_test.shape, y_test.shape)
输出结果如下。
(50000,32, 32, 3) (50000, 1) (10000, 32, 32, 3) (10000, 1)
CIFAR-100的可视化展示如代码8所示,示例结果如图4所示。
代码8 绘制CIFAR-100
# 指定绘图尺寸
plt.figure(figsize=(12,8))
# 绘制100个示例
fori in range(100):
plt.subplot(10,10,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(x_train[i], cmap=plt.cm.binary)
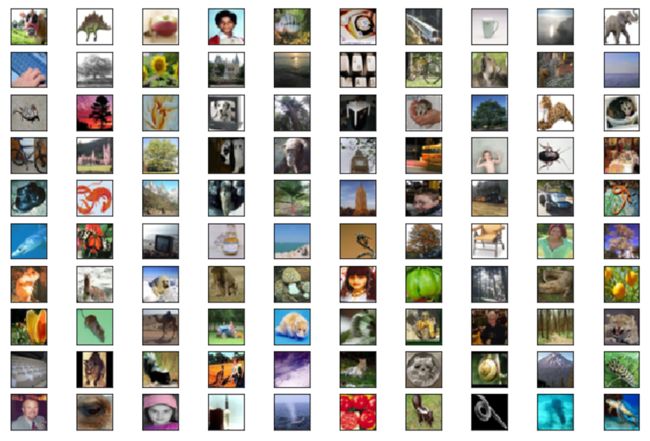
图4 CIFAR-100示例
5.ImageNet
ImageNet图像数据集是在2009年由斯坦福的李飞飞主导的一个项目形成的一个数据集。李飞飞在CVPR2009上发表了一篇名为《ImageNet: A Large-Scale Hierarchical Image Database》的论文,之后从2010年开始基于ImageNet数据集的7届ILSVRC大赛,这使得ImageNet极大的推动了深度学习和计算机视觉的发展。ILSVRC大赛历届经典网络如表1所示。
表1 ILSVRC历年冠军解决方案
年份 |
网络名称 |
Top5成绩 |
论文 |
2012 |
AlexNet |
16.42% |
ImageNet Classification with Deep Convolutional Neural Networks |
2013 |
ZFNet |
13.51% |
Visualizing and understanding convolutional networks |
2014 |
GoogLeNet |
6.67% |
Going Deeper with Convolutions |
VGG |
6.8% |
Very deep convolutional networks for large-scale image recognition |
|
2015 |
ResNet |
3.57% |
Deep Residual Learning for Image Recognition |
2016 |
ResNeXt |
3.03% |
Aggregated Residual Transformations for Deep Neural Networks |
2017 |
SENet |
2.25% |
Squeeze-and-Excitation Networks |
目前ImageNet中总共有14197122张图像,分为21841个类别,数据官网地址为:http://www.image-net.org/
ImageNet数据集示例如图5所示。

图5 ImageNet数据示例
6.PASCAL VOC
PASCAL VOC挑战赛(The PASCAL Visual Object Classes)是一个世界级的计算机视觉挑战赛, 其全称为Pattern Analysis, Statical Modeling andComputational Learning,从2005年开始到2012年结束,PASCAL VOC最初主要用于目标检测,很多经典的目标检测网络都是在PASCAL VOC上训练出来的,例如,Fast R-CNN系列的各种网络。后来逐渐增加了分类、分割、动作识别和人体布局等五类比赛。目前PASCAL VOC主要分为VOC2007和VOC2012两个版本的数据集。PASCAL VOC数据示例如图6所示。
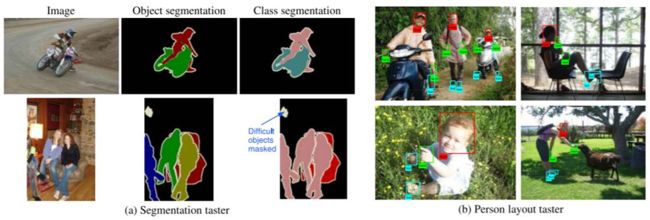
图6 PASCAL VOC数据示例
7.COCO
COCO数据集是微软在ImageNet和PASCAL VOC数据集标注上的基础上产生的,主要是用于图像分类、检测和分割等任务。COCO全称为Common Objects in Context,2014年微软在ECCV Workshops里发表了Microsoft COCO: Common Objects in Context。文章中说明了COCO数据集以场景理解为目标,主要从复杂的日常场景中截取,图像中的目标通过精确的分割进行位置的标定。COCO包括91个类别目标,其中有82个类别的数据量都超过了5000张。
COCO数据集主页地址为http://cocodataset.org/#home。
COCO数据集示例如图7所示。

图7 COCO数据集示例
除了以上这些公开的经典数据集以外,我们也可以通过数据采集和图像标注工具制作数据集。常用的图像标注工具包括Labelme、LabelImg、Vatic、Sloth、ImageJ、CVAT、Yolo_mark、RectLabel和Labelbox等。图8所示是Labelme图像标注示例。
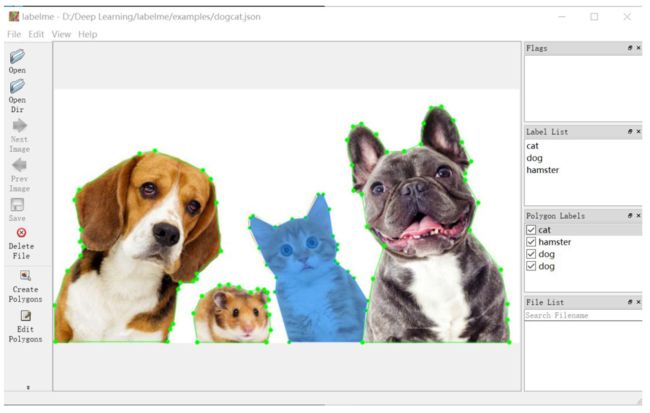
图8 Labelme图像标注
NLP经典数据集
1.IMDB
IMDB本身是一家在线收集各种电影信息的网站,跟国内的豆瓣较为类似,用户可以在上面发表对电影的影评。IMDB数据集是斯坦福整理的一套用于情感分析的IMDB电影评论二分类数据集,包含了25000个训练样本和25000个测试样本,所有影评被标记为正面和负面两种评价。IMDB数据集的一个示例如图9所示。

图9 IMDB数据示例
IMDB数据集在TensorFlow中读取方法跟MNIST等数据集较为类似,如代码9所示。
代码9 导入IMDB
# 导入imdb模块
from tensorflow.keras.datasets import imdb
# 导入数据
(x_train,y_train), (x_test, y_test) = imdb.load_data()
# 输出数据维度
print(x_train.shape,y_train.shape, x_test.shape, y_test.shape)
输出结果如下。
Downloadingdata from
https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz
17465344/17464789[==============================] - 2s 0us/step
(25000,)(25000,) (25000,) (25000,)
IMDB数据集地址为https://www.imdb.com/interfaces/。
2.Wikitext
WikiText 英语词库数据(The WikiText Long Term Dependency Language ModelingDataset)是由Salesforce MetaMind 策划的包含1亿个词汇的大型语言建模语料库。这些词汇都是从维基百科一些经典文章中提取得到,包括WikiText-103和WikiText-2两个版本,其中WikiText-2是WikiText-103的一个子集,常用于测试小型数据集的语言模型训练效果。值得一提的是,WikiText保持了产生每个词汇的原始文章,非常适用于长时依赖的大文本建模问题。
WikiText数据集地址为https://metamind.io/research/the-wikitext-long-term-dependency-language-modeling-dataset。
3.Amazon reviews
Amazon Reviews数据集是2013年由康奈尔大学[1]发布的、从斯坦福网络分析项目(SNAP)中构建的Amazon评论数据集,分为Full和Polarity两个版本。Full版本每个类别包含600000个训练样本和130000个测试样本,Polarity版本每个类别则包含1800000个训练样本和200000个测试样本。评论的商品包括书籍、电子产品、电影、日常家用产品、衣服、手机、玩具等各类常用物品。
Amazon Reviews数据集地址为http://jmcauley.ucsd.edu/data/amazon/。
Amazon Reviews数据集的一个样本示例如图10所示。

图10 Amazon Reviews数据示例
4.Sogou news
Sogou news 数据集是来自SogouCA和SogouCS新闻语料库总共包含运动、金融、娱乐、汽车和技术5个类别2909551篇新闻文章构成的数据集。每个类别分别包含90000个训练样本和12000个测试样本。
Sogou news 数据集地址为:
http://academictorrents.com/details/b2b847b5e1946b0479baa838a0b0547178e5ebe8。
NLP领域还有一些像Ag News、Yelp等经典数据集,这里限于篇幅就不再进行更多的介绍,感兴趣的读者可以自行查阅。

往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑获取一折本站知识星球优惠券,复制链接直接打开:https://t.zsxq.com/662nyZF本站qq群704220115。加入微信群请扫码进群(如果是博士或者准备读博士请说明):