吴恩达深度学习笔记-超参数调试、Batch正则化(第6课)
超参数调试
- 一、调试处理
- 二、为超参数选择合适的范围
- 三、超参数训练的实践:Pandas VS Caviar
- 四、正则化网络的激活函数
- 五、将Batch Norm拟合进神经网络
- 六、Batch Norm为什么奏效?
- 七、测试时的batch norm
- 八、softmax回归
- 九、训练一个softmax分类器
- 十、深度学习框架
- 十一、Tensorflow
一、调试处理
-
在模型训练中需要调试许多超参数,例如:
(1)学习率α;
(2)动量下降的β;
(3)adam算法的β1、β2、 ε;
(4)隐藏层节点数和层数;
(5)学习率衰变;
(6)mini-batch大小等等。
学习率是需要调试的最重要的超参数;其次重要的是momentum的β(一般设置为0.9)、mini-batch的大小、隐藏层节点数;重要性排第三的是隐藏层层数和学习率衰变;在使用Adam算法时,一般不调试β1、β2和 ε,总是设置为0.9、0.999和10-8 -
如何选取合适的超参数呢?
在传统机器学习,如果有两个超参数,常见的做法是在网格中取样点,然后尝试不同取样点(两个超参数的不同组合)的效果。
如下图两个参数采用了5x5的网格,可以获取25种参数1和参数2的不同组合,可以尝试这所有的25个点,选择效果最好的参数。

参数较少时这个方法很实用。
在深度学习领域,常用的做法是随机选择点,可以选择同等数量的25个点,接着用这些随机选取的点实验超参数的效果。如下图,不再是规律的网格取点。
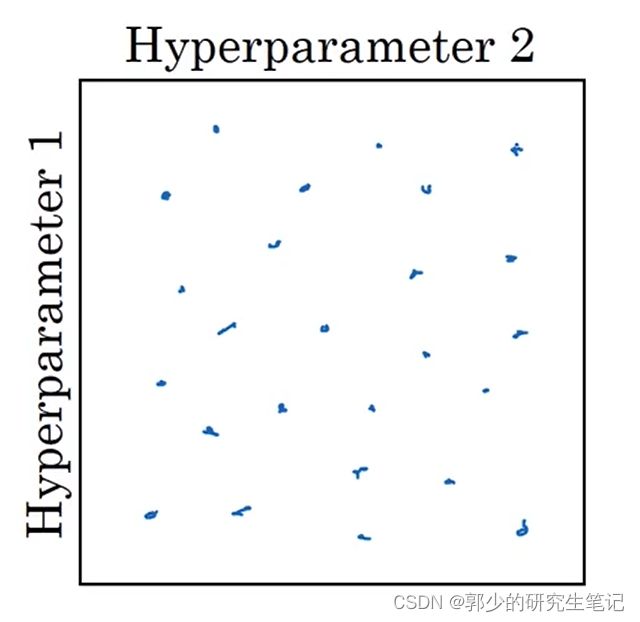
之所以这么做是因为很难提前知道哪个超参数最重要,例如上面的参数1是α,参数2是ε,可以知道α比ε要重要;对于网格选取的方法,25个点只选取了5种α不同的取值,无论ε取值多少效果都是相似的。对比而言,采用随机取值,将会尝试25个不同的α取值,所以能够找到效果更好的α取值。因此,随机取值可以提升搜索效率 -
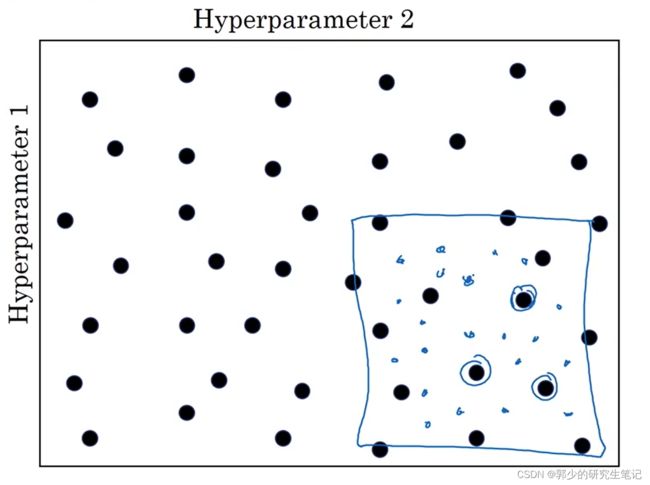
在实验过程种,会发现某一块区域的取值会比其他区域的效果要好。接下来要做的是放大这块小区域,然后在其中更密集地取值。如下图的蓝色框区域,放大并密集取值。
二、为超参数选择合适的范围
对于上节的随机取值,某些参数可以进行尺度均匀采样。
例如神经节点的数量,可能是50~100个,之后可以在这上面进行随机均匀采样很合理,如下图。

- 但是对于学习率,α可能的范围在0.0001~1之间,在这个范围上进行随机均匀采样, 会有大量的采样点落于0.1~1之间;0.1-1之间占用了90%的搜索资源,而0.0001-0.1之间只有10%的搜索资源,这是不合理的。
相比线性轴的方式,采用对数标尺搜索超参数的方式更合理,这样0.0001-0.001之间就会有更多的搜索资源可用了,如下图所示。

在python中可以这么做
#先确定α范围
a = np.log(10,0.0001) #=-4
b = np.log(10,1) #=0
r = a + (b-a)*np.random.rand() #r∈[-4,0]
#r在[a,b]内可以进行随机均匀取值
α = 10**r #α范围∈[0.0001,1]
- 另一个棘手的例子是给β取值,假设β的搜索范围数0.9-0.999,如果是在这个范围那就不能用线性轴进行取值,所以考虑这个问题的最好办法是
探究1-β,因此1-β的取值范围是在0.1-0.001区间之间,应用之前的对数轴方法进行均匀随机取值即可,就变成了r在[-3,-1]之间进行取值。
接下来解释为什么0.9-0.999不采用线性轴抽样,当0.9变化到0.9005,对于加权平均来说变化并不大;但是对于0.999变化到0.9995,变化十分巨大,从原来的统计过去1000天【1÷(1-0.999)】变成2000天【1÷(1-0.9995)】。因此应该在越接近1的范围,就应该越密集采样。
那为什么采用对数轴,越接近1的范围就密集采样了呢?看下面的图的图就明白了,它将线性轴接近于0的部分进行拉伸,从而使之能够进行均匀采样。
三、超参数训练的实践:Pandas VS Caviar
经过调试后的超参数并非是固定不变的,会根据数据的变化和实际需求发生改变,所以应该每隔一段时间对超参数进行调整以获得较好的模型。
如何搜索超参数?有两个主要的思路
- Babysitting one model
第一种情况是当拥有庞大的数据组,但是没有足够的计算机资源或CPU和GPU的前提下,只能一次负担起实验一个小模型或一小批模型。
这种情况即使它在试验时也可以逐渐改良。例如第0天随机参数初始化开始试验,然后组间观察学习曲线,若曲线在第一天逐渐减少,那这个模型训练的还不错,所以尝试增加一点学习率看它会怎么样;随着模型的不断训练观察学习曲线并不断调整参数。
可以说每天都在花时间照看此模型,所以这是一个人们照料模型的一个方法。这通常是在没有足够的计算能力,不能再同一时间试验大量模型时才采取的办法。
【熊猫模型:一次只产一个仔】 - Training many models in parallel
另一种方法是同时试验多种模型,例如设置了一些超参数,然后对模型进行训练绘制对于的学习曲线;对于不同的超参数就可以得到不同的学习曲线,最后再更具曲线快速选择效果好的模型。
【鱼子酱模型:一次产一大堆仔】
四、正则化网络的激活函数
对于单层神经网络和逻辑回归来说,可以对输入进行标准化,来加速梯度下降的过程。
那么对于深层神经网络,能否标准化某一层隐藏层,加速下一层的梯度下降。这个问题就是batch归一化要做的事情。
在实践中一般归一化的是输入的z,当然也有归一化输出a的例子。但本小节讲的是归一化输入z。
Batch Norm:
- 获取第l层的输入:z[l](1)、z[l](2)……z[l](m)
z[l](i):第i个样本对应第l层神经节点的输入
-
计算期望与方差

-
归一化
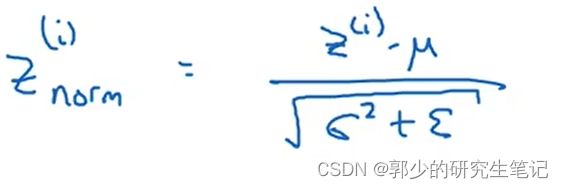
ε是防止分母为0
最后得到的z的每一个分量都含有期望0和方差1,但不想让隐藏单元总是含有期望0和方差1;因为也许隐藏单元有了不同的分布会更有意义,因此进入第四步。
- 进一步处理:

式中的β和γ都是模型的学习参数,所以可以采用梯度下降或者优化算法来更新β和γ,如同更新神经网络的权重一样。
β和γ的作用是可以设置归一化后z的平均值和方差,
若γ=(σ2+ε),β = u,则z就会回到归一化之前的状态。
在归一化后,就可以用归一化后的z进行模型训练。
Batch归一化的作用是它的使用范围不仅是输入层,甚至适用于深度神经网络中的隐藏层。与之前的归一化不同的是,不必让归一化后的数据的期望是0和方差为1。
五、将Batch Norm拟合进神经网络
Batch归一化是发生在计算z和a之间的,如下图:

涉及到的需要更新的参数如下图,可以使用任一种优化法来进行梯度下降更新。

如果采用了深度学习框架,使用一行代码就可以将batch norm应用于各层,如tensorflow框架中的tf.nn.batch_normalization。
实现细节:
Batch 归一化做的是先将z[l]归一化结果为期望0和方差为1,再通过γ和β进行重缩放;这意味着无论b[l]的值是多少,在batch归一化都要被减去得到0,没有意义,所以在batch归一过程中可以省略掉常数的处理过程,或者暂时设置该常数为0再进行归一化处理。推荐不用对b[l]进行处理。
六、Batch Norm为什么奏效?
-
batch norm除了和原来的归一化能够加速学习外,还可以使神经网络的权重W的更新更加“稳健”,尤其在深层神经网络中更加明显。比如神经网络很后面的W对前面的W包容性更强,即前面的W的变化对后面W造成的影响很小,整体网络更加健壮。
-
举一个例子,如下图我们利用逻辑回归构建了一个识别猫的系统;采用左边的数据集(全是黑猫)对模型进行训练,在对右边的数据集(全是彩色的猫)进行识别。识别的效果肯可能是不理想的,涉及到训练集和测试集的数据来自于同一分布的问题,像下图两个坐标系的样本分布一样,正负样本的分布存在一定差异,用第一个数据分布训练出来的模型不一定能够很好的拟合第二个数据集。

-
covariate shift:训练集和测试集差异较大时,我们的训练往往是徒劳的;上面的例子就是一个covariate shift。
-
covariate shift问题如何让影响了神经网络?
假设我们在训练下图的神经网络

首先从第三层截断,只看第三层后面的,如下图;问题就变成了如何根据a[2]映射到正确的y。可以想象是后面两层的W[3]、b[3]和W[4]、b[4]使这个网络的的分类效果很不错。【可以想象W[3]、b[3]和W[4]、b[4]是根据猫的脸部特征进行判断是否是猫的,因为训练集可以收集到猫的特征,所以这些参数其实是“正确的”】

在把网络的左边揭开,如下图。网络中还存在W[1]、b[1]和W[2]、b[2]这些参数,如果这些参数改变,那么第三层的输入a[2]也会发生改变。对于第三层的角度来说,对于不同数据集前面两层的参数一直在不断改变,所以就产生了covariate shift问题。【可以想象W[1]、b[1]和W[2]、b[2]是提取猫脸部特征的参数,对于左边全是黑猫的特征这些参数也许很好的提取,但是对于右边彩色猫的特征并不能很好的提取,导致输入到第三层的特征稀碎,从而导致了covariate shift问题】

-
batch归一化的作用就是减少隐藏层参数分布变化的数量。例如单独讨论对于第二层的z[2]1和z[2]2的分布(方便理解只讨论二维的),对于不同的数据可能这两个feature存在不一样的分布,batch norm归一化可确保这两个特征无论发生什么变化,z[2]1和z[2]2的均值和方差都不会变。【我的理解是:它一定程度限制了数据输入的分布情况,尽量让输入数据在分布上比归一化之前的数据更加相近,排除了一些由于输入数据不同而造成的不同分布问题。尽量使输入到第三层的数据分布的尽量像一点】batch norm限制了前层的参数更新,会影响数值分布的程度,然前面两层的参数更加靠谱,使第三层的输入在分布上差异不会很大。
-
batch归一化还有轻微正则化效果。
因为batch norm对隐藏层都进行了归一化处理,即对隐藏层的各节点都添加了随机噪声,类似于dropout,因此为了避免随机噪声对某个权重的影响,神经网络不会倾向于分配较大的权重。
在实施mini-batch中使用batch norm,mini-batch越小,正则化效果越明显;因为过大的mini-batch会消弱随机噪声。但是正则化并非是batch norm的目的,只是一个附带的微效果。
七、测试时的batch norm
- batch norm在训练时对mini-batch进行了逐一处理,所以在测试时也需要对测试集样本进行逐一处理。下图是在训练时进行batch归一化的等式:

- 注意上图中的u和σ2是在mini-batch上进行计算的,但是在测试时不会将测试集分成mini-batch再进行整体预测;且当只有一个样本时,一个样本的均值和方差没有意义。所以,
为了算法能够用于测试,需要单独计算u和σ^2^。 - 指数加权平均就是一个很好的解决办法,我们在训练时将训练集分成了X{1}、X{2}、X{3}……,现在只关注于第l层,对于各个mini-batch在进行batch归一化时会得到u{1}[l]、u{2}[l]、u{3}[l]……,在训练的过程中可以采用指数加权平均的方法进行追踪u{i}[l]的均值,σ2同理。最后
得到的是在所有mini-batch样本上计算出来的期望和方差,将算出的数值带入到测试集使用即可。
u{i}[l]:第l层第i个mini-batch样本的均值
八、softmax回归
我们之前讨论的都是二分类问题,神经网络只需要一个输出节点,输出0或者1。
当遇到多分类问题,需要将样本分成C类,神经网络要对应C个输出节点。每个人输出结点的含义是P(Ci|X),即在输入样本是X的条件下,分类为Ci的概率。
softmax回归的标签是one hot编码,如C=4,该样本分类为第二类,那么标签为:[0 1 0 0].T;若分类为第四类:[0 0 0 1].T
所以对于的预测输出和标签都是维度为(C,m)的矩阵
- 对于多分类神经网络的输出应该是一个概率值,在二分类的逻辑回归中使用的是sigmoid激活函数将输出映射为0-1之间的概率问题,在多分类采用的是softmax回归模型将输出转换成概率问题。
- 以一个4分类为例子,神经网络图如下。

最后一层的输入Z[L]可以由W[L]A[L-1]+b[L]计算出来,Z[L]的维度是(4,1)。
接下来应用softmax激活函数,
(1)建立临时变量t,公式如下图,t也是一个维度为(4,1)的矩阵。
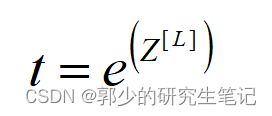
(2)计算激活函数输出矩阵a,a也是一个(1,4)的矩阵

(3)第L层第i个神经结点的输出:a[L]i
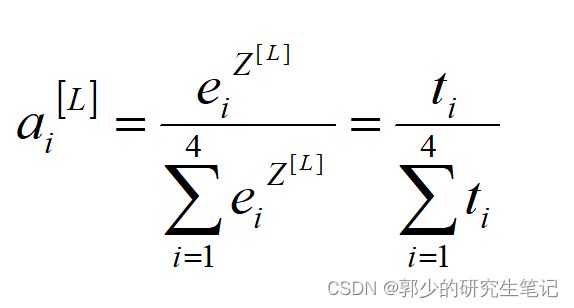
可以保证的是,这4个神经结点的输出相加为1,即样本属于这4个类别的概率为1。所以softmax做的事情其实就是将输出的值转换为0-1之间的概率值,且这些概率值之和为1。
具体数字实例如下图:

- softmax example
若训练一个只有一层神经网络,该层的激活函数是softmax,C=3,如下图:

采用模型进行分类,可以得到下面的分类结果:
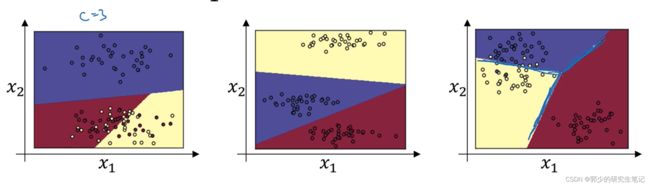
可以看出任两个分类之间的决策边界都是线性的。
当C=4、5、6可以得到下面的分类结果:

上面的例子显示了softmax分类器在没有隐藏层的情况下的线性分类效果。所以当神经网络存在很多隐藏层时,就可以学习更复杂的非线性决策边界来区分不同的分类。
九、训练一个softmax分类器
- 下面是一个softmax的运算过程:

softmax的来源与hardmax形成对比,hardmax对softmax的输出进行处理,将输出a[L]中最大元素的位置放上1,其他位置放上0.如上图中的第一行会放上0,最后输出[1 0 0 0]。
-
softmax回归将logistics回归推广到了C类,不仅仅是两类。当C=2时,那么softmax回归实际上变回了logistics回归。
-
Loss function:
在softmax中使用的损失函数定义如下:
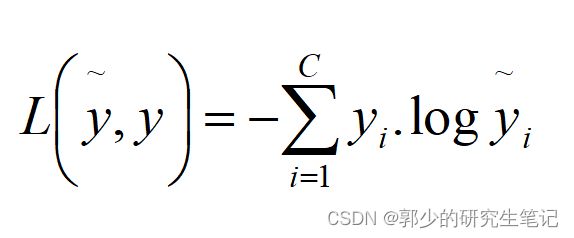
假设y=[0 1 0 0],即正确分类为第2类
那么损失函数式子变成:
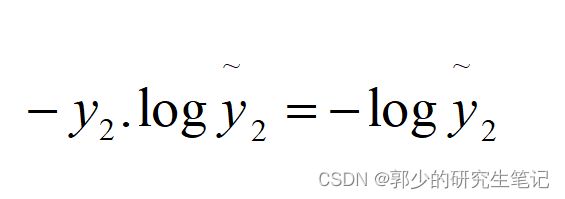
现在想要损失函数尽可能的小,使损失函数变小的唯一方式是使预测值y~2尽可能的大;这与我们实际需要的一致,因为正确分类是第二类,需要的也是预测的y~2尽可能的大,输出的分类结果才会是第二类。
所以概括来说,损失函数的作用是找到训练集中的真实类别,然后试图使该类别相应的概率尽可能地高。
对于整体样本的成本函数如下图:

-
Gradient descent with softmax:
因为softmax回归和之前得神经网络只是在最后一层不同,所以只需要计算最后一层得误差dz即可:

向量化:

十、深度学习框架
- 目前有很多框架,如下所示:

- 选择框架的标准:
 根据自己需求选择正确的框架
根据自己需求选择正确的框架
十一、Tensorflow
简单介绍Tensorflow如何使用:
- 假设损失函数为J(w) = w2-10*w+25,使用tensorflow进行梯度下降:
import numpy as np
import tensorflow as tf
'''定义参数'''
w = tf.Variable(0,dtype=tf.float32)
'''定义代价函数'''
#cost = tf.add(tf.add(w**2,tf.multiply(-10,w)),25)
cost = w**2 - 10*w +25
train = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
init = tf.global_variables_initializer()
'''创建会话空间'''
session = tf.Session()
'''执行初始化函数'''
session.run(init)
'''打印w'''
print(session.run(w))
#输出:0.0
'''执行1次梯度下降'''
session.run(train)
print(session.run(w))
#输出:0.099999994
'''执行1000次梯度下降'''
for i in range(1000):
session.run(train)
print(session.run(w))
若tensorflow版本报错:
添加tf.compat.v1.disable_eager_execution() tf改为tf.compat.v1

- 若要使用数据集x:
import numpy as np
import tensorflow as tf
'''定义一个数组'''
cofficients = np.array([[1.],[-10.],[25.]])
w = tf.Variable(0,dtype=tf.float32)
'''x是一个3*1的矩阵,使用placeholder方便数据加入损失方程'''
x = tf.placeholder(tf.float32,[3,1])
#w前面的数字用x代替
cost = x[0][0]*w**2 + x[1][0]*w + x[2][0]
train = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
init = tf.global_variables_initializer()
session = tf.Session()
session.run(init)
print(session.run(w))
#输出:0.0
#coefficients赋值给x
session.run(train, feed_dict=(x:coefficients))
print(session.run(w))
#输出:0.2
'''执行1000次梯度下降'''
for i in range(1000):
session.run(train)
print(session.run(w))
#输出:9.99998
习惯性表达语句:
session = tf.Session()
session.run(init)
print(session.run(w))
tensorflow获取损失函数后,会自动对其进行求导,采用自适应优化算法进行梯度下降过程,这些过程不需要我们手动完成了。