深入浅出对话系统——任务型对话系统技术框架
任务型对话系统架构

比如,这是一个任务型订票系统的对话例子。
如果要我们实现一个这样的对话系统,其中有三个最大的难点:理解用户输入、记住对话历史信息、知道要问什么。
首先是要能理解用户的输入,知道用户想什么;其次需要维护一个历史状态。因为用户一般不会在一句话中说清楚自己的所有需求,因此需要记住用户所说的关键信息,知道哪些信息提供了,哪些没有提供;最后通过提问题得到未提供信息的答案。
这三个难点可归纳为理解用户、追踪状态和生成下个动作。
任务型对话系统的目标是帮助用户实现他们想做的事情,有一个评测指标是在完成任务的前提下,对话的轮数越少越好。
下面我们来了解一下任务型对话系统中关键的术语。
常用术语
模式(schema): 预定义好的结构化表示,涵盖了任务导向对话所能处理的关键信息。
以订票系统为例,我们需要知道出发地、到达地、出发时间、乘客姓名等。在Python中,可以以字典的形式存储。Key就是这些信息,Value维护了所有可能的Key的取值(或者一个取值规则)。
意图(intent):用户想要进行的操作。
所谓理解用户输入,就是识别用户的意图。
槽(slot):其实就是模型中Key的概念。
比如订机票中,出发地和到达地就是两个Slot。得到每个Slot对应的值就可以完成对话任务。该过程也称为填槽。
领域(domain):预先设计好的意图和槽的集合。
比如订机票和订酒店就可以通过两个领域来维护。
下面是一些领域的例子:

特点
任务型对话系统的特点/难点:
- 领域强相关的
- 缺乏训练数据
- 最终目标:帮助用户做些事情。模型必须理解用户想要什么。
- 尽量简介高效

我们再来回顾下任务型对话系统的概述。本文将详细介绍其中的三大模块:自然语言理解、对话管理、对话生成。
这三个模型分别用于解决上面探讨的三个难点:理解用户输入、追踪状态和生成下个动作。
自然语言理解(NLU)模块接收用户(非结构化字符串)的输入,输出结构化的语义帧表示。比如领域、意图和(语义)槽。
对话管理(DM)模块通过状态追踪(DST)来记录关键信息,它的输入是NLU模块的输出,它的输出是对话的策略(是问问题呢,还是做点什么)。其内部会维护一个对话状态。
自然语言生成(NLG)模块根据DM模块输出的对话动作,生成用户能理解的自然语言。但大多数通过基于规则的模板实现。
自然语言理解模块
自然语言理解模块是用户输入进入系统后接触的第一个模块。可分为三个子模块:领域识别、意图识别、语义槽填充。
比如 Show me morning flights from Boston to San Francisco on Tuesday 这句话进入自然语言理解模块后可以得到:
- 领域识别
- 领域:订机票
- 意图识别
- 意图:查询航班
- 语义槽填充
- 出发地: Boston
- 出发日期: Tuesday
- 出发时间: morning
- 到达地: San Francisco
下面看更多的例子,包含三个领域。

从上图可以看到,这三个子模块也是通过Pipeline的方式运作的,即首先进行领域识别,然后是意图识别,最后才做语义槽填充。
我们知道,领域识别和意图识别本质上都是分类任务,语义槽填充属于序列标注任务。
现在一般使用深度学习来做自然语言理解。
深度学习在意图/领域识别中的发展过程:
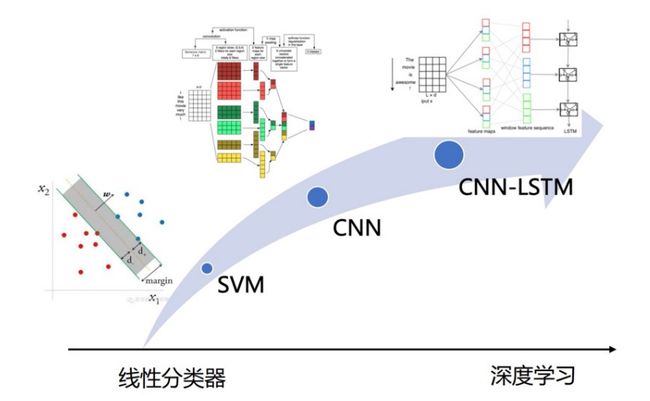
随着自注意的出现,后来常用基于预训练模型的文本分类器。
而在语义槽填充中:
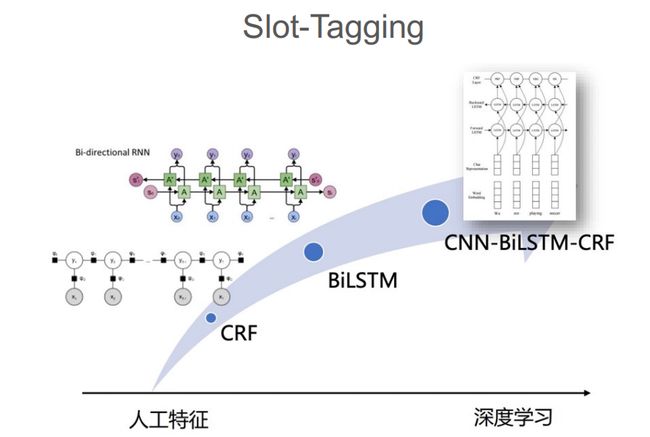
在BERT出来之前,最火的选择就是LSTM+CRF来实现序列标注。
对话管理模块
我们上面知道对话管理模型结构化的语义帧,输出对话动作。其维护了两个子模块——状态追踪(DST)和策略优化(DPO)。
我们先来看一下对话状态追踪。首先要知道什么是对话状态。
对话状态追踪
**对话状态(Dialogue State)**是对话到当前位置为止,用户所提供的哪些关键信息。
具体实现可以理解为Python中的字典。Key是Slot,Value是用户目前位置提供的值。
来看一个例子,从中可以看到对话状态的更新:

对话状态追踪即对话状态估计。
在上面的例子中,对话状态挺明确的,为什么说是对话状态估计?
因为虽然我们这里的例子很简单,但实际上真实系统上,我们很难找到这么清晰的例子。用户总能想到我们无法处理的意图,或者说用户总有一些我们意想不到的举措。为了满足这些举措,我们需要设计很多的对话动作,很多的槽,并且每个槽有很多不同的取值。最终导致我们对话状态空间非常庞大。

在用户表述不清楚的情况下,我们很难更新对话状态。所以我们需要进行对话状态估计。
那么我们过去一般是如何解决这个问题呢。
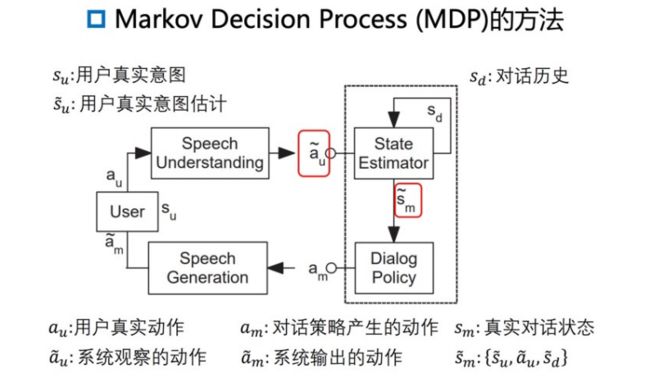
通过马尔科夫决策过程(Markov Decision Process)。提出者认为对话管理模块在和用户交互的过程中,遵循了上面的流程。
具体为:用户说了一句话 a u a_u au,为用户的真实动作。通过语音转文字,得到 a ~ u \tilde{a}_u a~u,为系统观察到的用户行为。这里就可能和用户的真实意图有偏差。模型根据这个观察到的行为,需要产生对于当前对话状态的估计 s ~ m \tilde{s}_m s~m,然后通过对话策略模块生成下一步动作 a m a_m am。接着,通过文字转语音得到系统输出的动作 a ~ m \tilde{a}_m a~m。用户根据系统输出,认为自己已经提供了哪些关键信息 s u s_u su,和DM中维护的对话系统认为用户已经提供的关键信息 s ~ m \tilde{s}_m s~m很有可能不同。
而现在在学术界和比赛中把它当成文本生成任务。

将当前对话历史得到的对话状态打包成字符串,然后通过自回归的语言模型学习。
对于新的对话历史怎么得到状态呢,也是将其打包成字符串,喂给语言模型,然后让语言模型以字符串的方式输出键值对。
https://arxiv.org/abs/2012.03539
https://github.com/salesforce/simpletod
但在商业化应用中只是通过基于对话流的方式,会遍历所有可能的对话状态。
对话策略
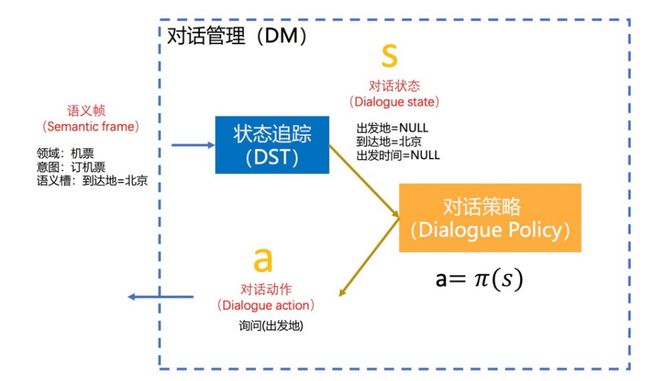
对话策略就是根据当前的对话状态决定对话系统下一步的动作。
具体做法为,将对话策略看成函数 π \pi π。

它接收的输入为当前的对话状态 s s s,输出为对话动作 a a a。通过多轮的对话交互,就可以得到一系列动作序列 A A A。
对话策略过去是通过有限状态机的方式实现的。
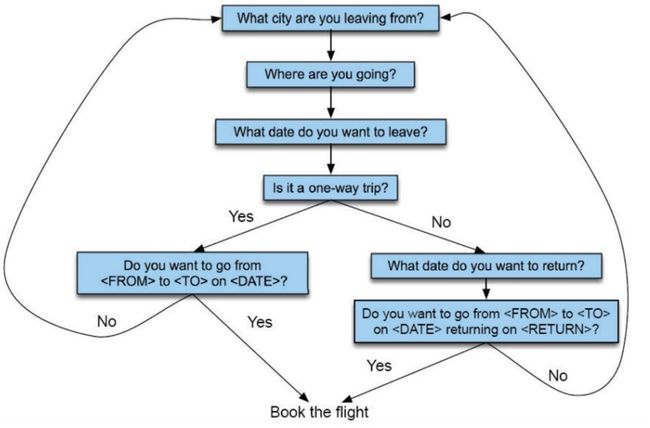
即系统会遍历所有可能的状态,在不同的状态下有不同的决策。在不同的决策中使用规则的方式决定下一步动作。
以订票为例。首先会问出发地,然后问目的地、出发时间。中间会问要不要订返程票,根据答案的不同流程会不同。
而更有趣的做法是把它看成强化学习过程:
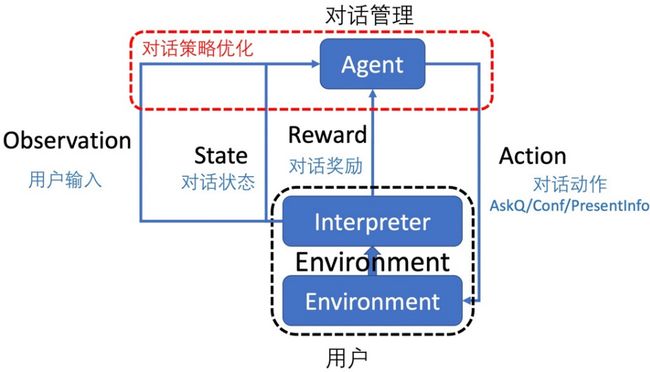
但实际应用中,我们仍然采用的是基于有限状态机的方式。
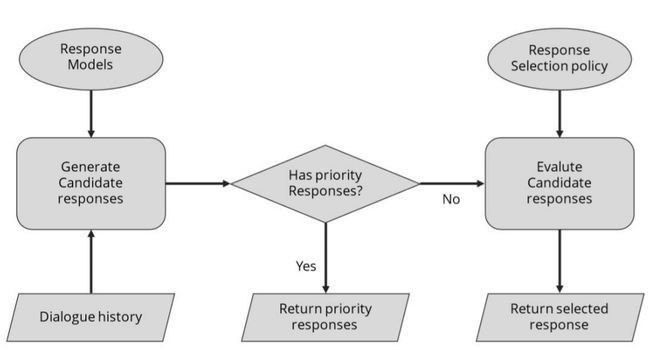
甚至我们也可以为开放领域的聊天机器人设定一些对话管理过程:
对话生成模块
自然语言生成模块主要用于根据对话动作生成文本回复。
最简单的方式就是通过模板来实现。

即为每个对话动作配置一些问题模板。
后来,大家发现可以把生成模板的过程写得更花俏一点。

主要是对生成模板的过程进行细分,比如上图终端Text Planner、Sentence Planner和Realizer。
随着深度学习的发展,有人也尝试通过语言模型来生成。
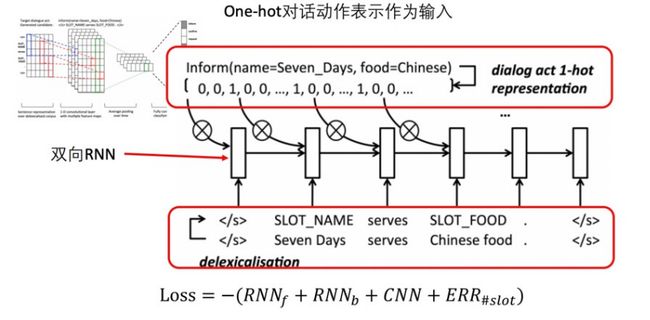
但是在工业界,还是通过基于模板的方式。因为它简单、可控。
参考
- 贪心学院课程