【Pytorch神经网络实战案例】06 逻辑回归拟合二维数据

1 逻辑回归与拟合过程
1.1 准备数据-code_01_moons.py(第1部分)
import sklearn.datasets
import torch
import numpy as np
import matplotlib.pyplot as plt
from LogicNet_fun import LogicNet,plot_losses,predict,plot_decision_boundary
# 1.1 准备数据
np.random.seed(0) #设置随机种子
X,Y = sklearn.datasets.make_moons(200,noise=0.2)#生成两组半圆形数据
arg = np.squeeze(np.argwhere(Y==0),axis=1) #获取第1组数据索引
arg2 = np.squeeze(np.argwhere(Y==1),axis=1) #获取第2组数据索引
plt.title("moons data") #设置可视化标题
plt.scatter(X[arg,0],X[arg,1],s=100,c='b',marker='+',label='data1') #显示第一组数据索引
plt.scatter(X[arg2,0],X[arg2,1],s=40,c='r',marker='o',label='data2')#显示第二组数据索引
plt.legend() #显示图例
plt.show()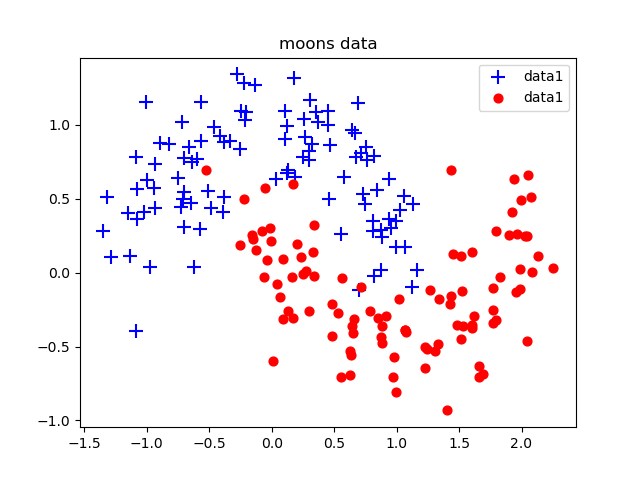
1.2 定义网络模型-LogicNet_fun.py(第1部分)
# 1.2 定义网络模型
class LogicNet(nn.Module): #继承nn.Module类,构建网络模型
def __init__(self,inputdim,hiddendim,outputdim): #初始化网络结构 ===》即初始化接口部分
super(LogicNet,self).__init__()
self.Linear1 = nn.Linear(inputdim,hiddendim) #定义全连接层
self.Linear2 = nn.Linear(hiddendim,outputdim) #定义全连接层
self.criterion = nn.CrossEntropyLoss() #定义交叉熵函数
def forward(self,x):# 搭建用两个全连接层组成的网络模型 ===》 即正向接口部分:将网络层模型结构按照正向传播的顺序搭建
x = self.Linear1(x)# 将输入传入第一个全连接层
x = torch.tanh(x)# 将第一个全连接层的结果进行非线性变化
x = self.Linear2(x)# 将网络数据传入第二个全连接层
return x
def predict(self,x):# 实现LogicNet类的预测窗口 ===》 即预测接口部分:利用搭建好的正向接口,得到模型预测结果
#调用自身网络模型,并对结果进行softmax()处理,分别的出预测数据属于每一个类的概率
pred = torch.softmax(self.forward(x),dim=1)# 将正向结果进行softmax(),分别的出预测结果属于每一个类的概率
return torch.argmax(pred,dim=1)# 返回每组预测概率中最大的索引
def getloss(self,x,y):# 实现LogicNet类的损失值接口 ===》 即损失值计算接口部分:计算模型的预测结果与真实值之间的误差,在反向传播时使用
y_pred = self.forward(x)
loss = self.criterion(y_pred,y)# 计算损失值的交叉熵
return loss
1.3 实例化网络模型-code_01_moons.py(第2部分)
# 1.3 搭建网络模型
model = LogicNet(inputdim=2,hiddendim=3,outputdim=2) #实例化模型 输入数据的维度、隐藏节点的数量、模型最终结果的分类数
optimizer = torch.optim.Adam(model.parameters(),lr=0.01) # 定义优化器 在反向传播时使用
1.4 神经网络的训练模型-code_01_moons.py(第3部分)
#1.4 训练模型
xt = torch.from_numpy(X).type(torch.FloatTensor) #将数据转化为张量形式
yt = torch.from_numpy(Y).type(torch.LongTensor)
epochs = 10000 #训练次数
losses = [] # 损失值列表
for i in range(epochs):
loss = model.getloss(xt,yt)
losses.append(loss.item())
optimizer.zero_grad() #梯度清零
# loss.backword() 写错了 # 反向传播
loss.backward()# 反向传播的损失值
optimizer.step()# 更新参数1.5 训练结果的可视化实现
1.5.1 定义可视化函数-LogicNet_fun.py(第2部分)
# 1.5 训练可视化
def moving_average(a,w=10): #计算移动平均损失值
if len(a) < w:
return a[:]
return [val if idx < w else sum(a[(idx - w):idx]) / w for idx, val in enumerate(a)]
def moving_average_to_simp(a,w=10): #
if len(a) < w:
return a[:]
val_list = []
for idx, val in enumerate(a):
if idx < w:# 如果列表 a 的下标小于 w, 直接将元素添加进 xxx 列表
val_list.append(val)
else:# 向前取 10 个元素计算平均值, 添加到 xxx 列表
val_list.append(sum(a[(idx - w):idx]) / w)
def plot_losses(losses):
avgloss = moving_average(losses)#获得损失值的移动平均值
plt.figure(1)
plt.subplot(211)
plt.plot(range(len(avgloss)),avgloss,'b--')
plt.xlabel('step number')
plt.ylabel('Training loss')
plt.title('step number vs Training loss')
plt.show()1.5.2 调用可视化函数-code_01_moons.py(第4部分)
#1.5 训练可视化
plot_losses(losses)

1.6 网络模型评估即预测精度计算-code_01_moons.py(第5部分)
#1.6 模型评估
from sklearn.metrics import accuracy_score
print(accuracy_score(model.predict(xt),yt))1.7 预测结果模型可视化
1.7.1 可视化函数构建--LogicNet_fun.py(第3部分)
# 1.7 数据可视化模型
def predict(x): #封装支持Numpy的预测接口
x = torch.from_numpy(x).type(torch.FloatTensor)
model = LogicNet(inputdim=2, hiddendim=3, outputdim=2)
ans = model.predict(x)
return ans.numpy()
def plot_decision_boundary(pred_func,X,Y): #在直角模型中实现预测结果的可视化
#计算范围
x_min ,x_max = X[:,0].min()-0.5 , X[:,0].max()+0.5
y_min ,y_max = X[:,1].min()-0.5 , X[:,1].max()+0.5
h=0.01
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
#根据数据输入进行预测
Z = pred_func(np.c_[xx.ravel(),yy.ravel()])
Z = Z.reshape(xx.shape)
#将数据的预测结果进行可视化
plt.contourf(xx,yy,Z,cmap=plt.cm.Spectral)
plt.title("Linear predict")
arg = np.squeeze(np.argwhere(Y==0),axis=1)
arg2 = np.squeeze(np.argwhere(Y==1),axis=1)
plt.scatter(X[arg,0],X[arg,1],s=100,c='b',marker='+')
plt.scatter(X[arg2,0],X[arg2,1],s=40,c='r',marker='o')
plt.show()1.7.2 可视化函数调用--code_01_moons.py(第6部分)
# 1.7 数据预测可视化模型
plot_decision_boundary(lambda x:predict(x),xt.numpy(),yt.numpy())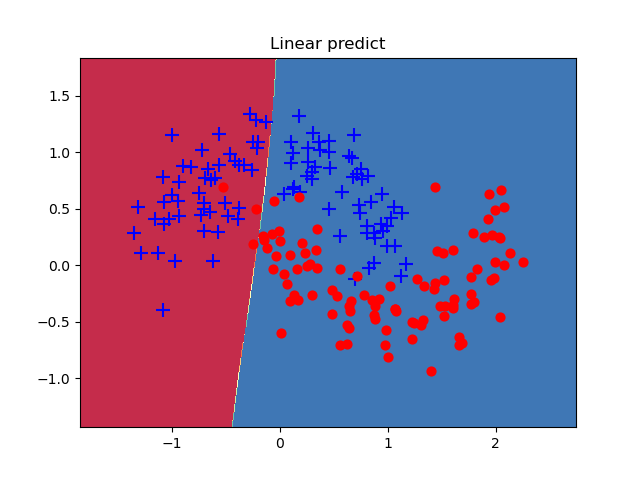
2 总结与回顾
2.1 深度学习的步骤
准备数据、搭建网络模型、训练模型、使用及评估模型
2.1.1 概述步骤
将任务中的数据进行收集整理,通过建立合适的网络模型进行预测,在构建过程中通过一定次数的迭代学习数据特征来行程可用的数据模型,最后就是使用构建好的模型来解决实际问题。
2.2 训练模型

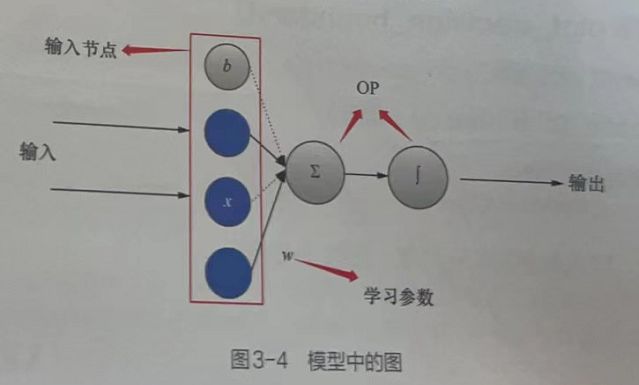
2.3 模型是如何训练的

3 代码汇总
3.1 code_01_moons.py
import sklearn.datasets
import torch
import numpy as np
import matplotlib.pyplot as plt
from LogicNet_fun import LogicNet,plot_losses,predict,plot_decision_boundary
# 1.1 准备数据
np.random.seed(0) #设置随机种子
X,Y = sklearn.datasets.make_moons(200,noise=0.2)#生成两组半圆形数据
arg = np.squeeze(np.argwhere(Y==0),axis=1) #获取第1组数据索引
arg2 = np.squeeze(np.argwhere(Y==1),axis=1) #获取第2组数据索引
plt.title("moons data") #设置可视化标题
plt.scatter(X[arg,0],X[arg,1],s=100,c='b',marker='+',label='data1') #显示第一组数据索引
plt.scatter(X[arg2,0],X[arg2,1],s=40,c='r',marker='o',label='data2')#显示第二组数据索引
plt.legend() #显示图例
plt.show()
# 1.3 搭建网络模型
model = LogicNet(inputdim=2,hiddendim=3,outputdim=2) #实例化模型 输入数据的维度、隐藏节点的数量、模型最终结果的分类数
optimizer = torch.optim.Adam(model.parameters(),lr=0.01) # 定义优化器 在反向传播时使用
#1.4 训练模型
xt = torch.from_numpy(X).type(torch.FloatTensor) #将数据转化为张量形式
yt = torch.from_numpy(Y).type(torch.LongTensor)
epochs = 10000 #训练次数
losses = [] # 损失值列表
for i in range(epochs):
loss = model.getloss(xt,yt)
losses.append(loss.item())
optimizer.zero_grad() #梯度清零
# loss.backword() 写错了 # 反向传播
loss.backward()# 反向传播的损失值
optimizer.step()# 更新参数
#1.5 训练可视化
plot_losses(losses)
#1.6 模型评估
from sklearn.metrics import accuracy_score
print(accuracy_score(model.predict(xt),yt))
# 1.7 数据预测可视化模型
plot_decision_boundary(lambda x:predict(x),xt.numpy(),yt.numpy())3.2 LogicNet_fun.py
import torch.nn as nn #引入torch网络模型库
import torch
import numpy as np
import matplotlib.pyplot as plt
# 1.2 定义网络模型
class LogicNet(nn.Module): #继承nn.Module类,构建网络模型
def __init__(self,inputdim,hiddendim,outputdim): #初始化网络结构 ===》即初始化接口部分
super(LogicNet,self).__init__()
self.Linear1 = nn.Linear(inputdim,hiddendim) #定义全连接层
self.Linear2 = nn.Linear(hiddendim,outputdim) #定义全连接层
self.criterion = nn.CrossEntropyLoss() #定义交叉熵函数
def forward(self,x):# 搭建用两个全连接层组成的网络模型 ===》 即正向接口部分:将网络层模型结构按照正向传播的顺序搭建
x = self.Linear1(x)# 将输入传入第一个全连接层
x = torch.tanh(x)# 将第一个全连接层的结果进行非线性变化
x = self.Linear2(x)# 将网络数据传入第二个全连接层
return x
def predict(self,x):# 实现LogicNet类的预测窗口 ===》 即预测接口部分:利用搭建好的正向接口,得到模型预测结果
#调用自身网络模型,并对结果进行softmax()处理,分别的出预测数据属于每一个类的概率
pred = torch.softmax(self.forward(x),dim=1)# 将正向结果进行softmax(),分别的出预测结果属于每一个类的概率
return torch.argmax(pred,dim=1)# 返回每组预测概率中最大的索引
def getloss(self,x,y):# 实现LogicNet类的损失值接口 ===》 即损失值计算接口部分:计算模型的预测结果与真实值之间的误差,在反向传播时使用
y_pred = self.forward(x)
loss = self.criterion(y_pred,y)# 计算损失值的交叉熵
return loss
# 1.5 训练可视化
def moving_average(a,w=10): #计算移动平均损失值
if len(a) < w:
return a[:]
return [val if idx < w else sum(a[(idx - w):idx]) / w for idx, val in enumerate(a)]
def moving_average_to_simp(a,w=10): #
if len(a) < w:
return a[:]
val_list = []
for idx, val in enumerate(a):
if idx < w:# 如果列表 a 的下标小于 w, 直接将元素添加进 xxx 列表
val_list.append(val)
else:# 向前取 10 个元素计算平均值, 添加到 xxx 列表
val_list.append(sum(a[(idx - w):idx]) / w)
def plot_losses(losses):
avgloss = moving_average(losses)#获得损失值的移动平均值
plt.figure(1)
plt.subplot(211)
plt.plot(range(len(avgloss)),avgloss,'b--')
plt.xlabel('step number')
plt.ylabel('Training loss')
plt.title('step number vs Training loss')
plt.show()
# 1.7 数据可视化模型
def predict(x): #封装支持Numpy的预测接口
x = torch.from_numpy(x).type(torch.FloatTensor)
model = LogicNet(inputdim=2, hiddendim=3, outputdim=2)
ans = model.predict(x)
return ans.numpy()
def plot_decision_boundary(pred_func,X,Y): #在直角模型中实现预测结果的可视化
#计算范围
x_min ,x_max = X[:,0].min()-0.5 , X[:,0].max()+0.5
y_min ,y_max = X[:,1].min()-0.5 , X[:,1].max()+0.5
h=0.01
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
#根据数据输入进行预测
Z = pred_func(np.c_[xx.ravel(),yy.ravel()])
Z = Z.reshape(xx.shape)
#将数据的预测结果进行可视化
plt.contourf(xx,yy,Z,cmap=plt.cm.Spectral)
plt.title("Linear predict")
arg = np.squeeze(np.argwhere(Y==0),axis=1)
arg2 = np.squeeze(np.argwhere(Y==1),axis=1)
plt.scatter(X[arg,0],X[arg,1],s=100,c='b',marker='+')
plt.scatter(X[arg2,0],X[arg2,1],s=40,c='r',marker='o')
plt.show()