深入剖析多层双向LSTM的输入输出
目录
- 一、前言
- 二、符号约定
- 三、LSTM的参数
- 四、LSTM的输入
- 五、LSTM的输出
- 最后
一、前言
本文将结合官方文档并以seq2seq模型为例全面展示在多层(num_layers >= 2)双向(bidirectional = True)LSTM中输入输出的形状变化以及如何正确使用它们。
以下均假定 batch_first = False,即默认值。
二、符号约定
| 符号 | 描述 |
|---|---|
| L L L | 序列长度(时间步数) |
| N N N | 即 batch_size |
| d d d | 词向量的维度,即 embed_size |
| h h h | LSTM隐藏层神经元的个数 |
| n n n | 即 num_layers |
三、LSTM的参数
LSTM最常用的参数列在下方:
nn.LSTM(
input_size,
hidden_size,
num_layers=1,
dropout=0,
bidirectional=False,
)
除了前两个参数为必需参数以外,后面三个都是可选参数。其中 input_size 是输入层神经元的个数,hidden_size 是隐藏层神经元的个数。
需要注意的是,对于有 n n n 个层的LSTM来说,除了第一个层的 input_size 和 hidden_size 可能不同以外,后面 n − 1 n-1 n−1 个层的 input_size 和 hidden_size 都相同,均为第一个层的 hidden_size。
四、LSTM的输入
LSTM的输入共有三个:input、h_0 和 c_0。为便于理解,我们先来回顾一下seq2seq编码器的工作流程。
在seq2seq模型中,假设我们的编码器采用的就是多层双向的LSTM。对于NMT任务,一般来讲,我们需要根据语料库构建一个词表,该词表不重复地包含了语料库中的所有词元(一般是单词),并根据每个词元的出现频率为其分配唯一的索引(特殊词元一般位于词表的最上方,剩余的词元出现频率越高,索引越小,出现频率过低的词元会被丢弃并视为未知词元)。之后,我们会选定一个序列长度 L L L,并对语料库中的每个句子进行填充或截断(否则无法批量加载)。
在批量读取数据时,数据形状通常为 ( N , L ) (N,L) (N,L)(即每次读取 N N N 个句子,每个句子的长度为 L L L),并且其中的每个元素都是原先词元在词表中的索引。将这批数据丢进embedding层后其形状变为 ( N , L , d ) (N,L,d) (N,L,d)(本质是一个根据索引查表的过程)。为了符合 batch_first = False,我们需要用 permute 方法将 ( N , L , d ) (N,L,d) (N,L,d) 变为 ( L , N , d ) (L,N,d) (L,N,d),而这个 ( L , N , d ) (L,N,d) (L,N,d) 形状的张量正是LSTM的 input。所以对于编码器而言,nn.LSTM 的 input_size 就是 d d d。
因为通常来讲 c_0 的形状和 h_0 的一样,所以接下来我们只介绍 h_0(后续的 h_n 和 c_n 同理)。
顾名思义,h_0 就是LSTM的初始隐状态。对于 n n n 层单向LSTM,我们需要为每一个层都提供初始的隐状态,那么此时 h_0 的形状为 ( n , N , h ) (n,N,h) (n,N,h)。对于双向的情形,我们自然需要两个形状为 ( n , N , h ) (n,N,h) (n,N,h) 的张量,PyTorch的做法是将这两个张量concat在一起成为一个 ( 2 n , N , h ) (2n,N,h) (2n,N,h) 的张量作为 n n n 层双向LSTM的初始隐状态(至于怎么concat后面会提到)。
LSTM的输入如果只提供
input,那么h_0和c_0将进行零初始化。此外,h_0和c_0要么同时提供,要么同时不提供,不可以只提供一个而不提供另一个,否则会报错。
五、LSTM的输出
LSTM的输出为 output、h_n 和 c_n。
其中 output 的形状为 ( L , N , 2 h ) (L,N,2h) (L,N,2h),这是因为PyTorch将正向LSTM和反向LSTM的输出直接concat在了一起。如果需要分别获得正向和反向的输出结果,我们需要将 output 的形状 reshape 成 ( L , N , 2 , h ) (L,N,2,h) (L,N,2,h),这样一来,output[:, :, 0, :] 代表的是正向LSTM的输出结果,output[:, :, 1, :] 代表的是反向LSTM的输出结果,形状均为 ( L , N , h ) (L,N,h) (L,N,h)。
h_n 的形状和 h_0 的相同(事实上每一个 h_t 的形状都相同),均为 ( 2 n , N , h ) (2n, N,h) (2n,N,h),这是因为PyTorch将正向LSTM和反向LSTM的 h_n 交替concat在了一起。如果需要分别获得正向和反向的 h_n,我们不能再像之前那样做 reshape 操作了,而是按步长为 2 2 2 去索引,即 h_n[::2] 代表的是正向LSTM的 h_n,h_n[1::2] 代表的是反向LSTM的 h_n,形状均为 ( n , N , h ) (n,N,h) (n,N,h)。
需要注意的是,无论是正向LSTM还是反向LSTM,其 output 均指的是 L L L 个时间步上最后一个隐藏层的输出,而 h_n 指的是最后一个时间步上 n n n 个隐藏层的输出。下图直观地展示了 output 和 h_n 的区别(以单向的LSTM为例):
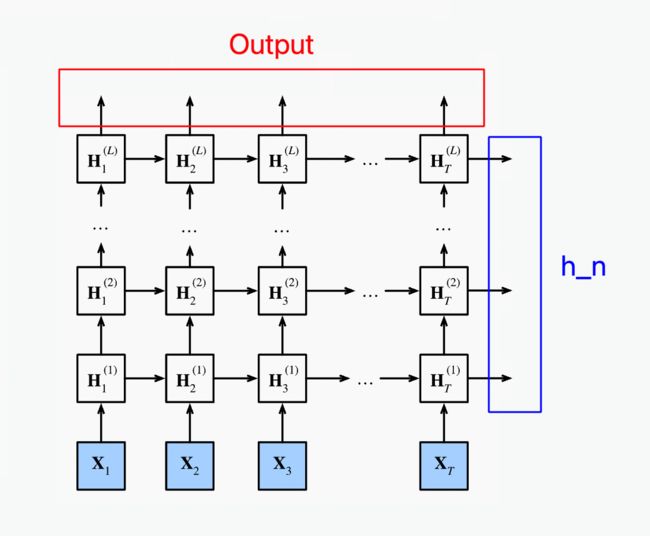
图中使用的记号和本文的略有出入(其中 L L L 相当于本文的 n n n, T T T 相当于本文的 L L L)。可以看出,output[-1] = h_n[-1],因为它们均是最后一个时间步上的最后一个隐层的输出。
验证双向LSTM的输出:
import torch
import torch.nn as nn
L = 6 # 序列长度
N = 5 # 批量大小
d = 4 # 嵌入维度
h = 3 # 隐层大小
n = 2 # LSTM的深度
lstm = nn.LSTM(d, h, num_layers=n, bidirectional=True)
inputs = torch.randn(L, N, d) # LSTM的输入
output, (h_n, c_n) = lstm(inputs) # LSTM的输出
output = output.reshape(L, N, 2, h)
forward_output = output[:, :, 0, :] # 正向LSTM的输出,形状为(L, N, h)
backward_output = output[:, :, 1, :] # 反向LSTM的输出,形状为(L, N, h)
forward_h_n = h_n[::2] # 正向LSTM的h_n,形状为(n, N, h)
backward_h_n = h_n[1::2] # 反向LSTM的h_n,形状为(n, N, h)
# 因为是正向LSTM,所以时间方向是从左向右,因此forward_output[-1]代表
# 最后一个时间步上的最后一层的输出
print(forward_output[-1] == forward_h_n[-1])
# 因为是反向LSTM,所以时间方向是从右向左,因此backward_output[0]代表
# 最后一个时间步上的最后一层的输出
print(backward_output[0] == backward_h_n[-1])
输出均为 True,这里不再展示,读者可自行运行程序。
从以上程序可以看出,backward_h_n[-1] 并不等于 backward_output[-1],这时因为反向LSTM是从右往左进行的,因此 backward_output[-1] 实际上是反向LSTM在第一个时间步上的最后一层的输出,而 backward_h_n 则是反向LSTM在最后一个时间步上的 n n n 个层的输出。
最后
博主水平有限,文章难免存在一定的错误,欢迎批评指正!