基于遗传模拟退火算法的模糊C-均值聚类算法(SAGAFCM)—MATLAB实现
本文的代码将放在最后,需要的小伙伴们可以免费获取哦!!!
文章目录
- 一、模糊C-均值聚类(FCM)
-
- 1、介绍
-
- 1)、算法初步介绍
- 2)算法步骤
- 2、MATLAB实现
-
- 1)、问题描述
- 2)、算法实现
- 二、基于遗传模拟退火算法的模糊C-均值聚类算法(SAGAFCM)
-
- 1、模拟算法介绍算法介绍
-
-
- 1)、算法介绍
- 2)、算法核心公式
- 3)、算法可行性解释
-
- 2、遗传算法介绍
-
-
- 1)、算法介绍
- 2)、算法核心思想
-
- 3、算法优缺点即组合原因
-
- 1)、模拟退火算法的优缺点
-
- 1、模拟退火算法的优点:
- 2、模拟退火算法的缺点:
- 2)、遗传算法的优缺点
-
- 1、遗传算法的优点:
- 2、遗传算法的缺点:
- 3)、算法组合
- 4、算法实现流程
- 5、MATLAB算法实现
-
- 1)、目标函数
- 2)、initFCM函数
- 2)、iterateFCM函数
- 3)、主函数
- 4)、结果分析
- 三、代码链接
一、模糊C-均值聚类(FCM)
1、介绍
1)、算法初步介绍
模糊聚类是目前知识发现以及模式识别等诸多领域中的重要研究分支之一。随着研究范围的拓展,不管是科学研究还是实际应用,都对聚类的结果从多方面提出了更高的要求。模糊C-均值聚类(FCM)是目前比较流行的一种聚类方式。该方法使用了在欧几里得空间确定数据点的几何贴近度概念,它将这些数据分配到不同的聚类,然后确定这些聚类之间的距离。模糊C-均值聚类算法在理论和应用上都为其他的模糊聚类分析方法奠定了基础,应用也是最广泛。但是,在本质上FCM算法是一种局部搜索优化算法,如果初始值选择不当,他就会收敛到局部极小点上。因此,FCM算法的这一缺点限制了人们对他的使用。
2)算法步骤
设 n n n个数据样本 X X X = { x 1 x_1 x1, x 2 x_2 x2,…, x n x_n xn}, c c c(2 ⩽ \leqslant ⩽ c c c ⩽ \leqslant ⩽ n n n )是要将数据样本分成的类型数目, { A 1 A_1 A1, A 2 A_2 A2,…, A c A_c Ac}表示相应的的 c c c个类别, U U U是其相似分类矩阵,各类别的聚类中心点为{ v 1 v_1 v1, v 2 v_2 v2,…, v c v_c vc}, μ \mu μ( x i x_i xi)是样本 x x xi对于 A 1 A_1 A1的隶属度(简写为 μ i k \mu_{ik} μik)。则目标函数 J b J_b Jb可以用下列表达式:
J b ( U , v ) = ∑ i = 1 n ∑ k = 1 c ( μ i k ) b ( d i k ) 2 (1-1) J_b(U,v) =\displaystyle \sum^{n }_{i = 1}\displaystyle \sum^{c }_{k = 1}{(\mu_{ik})^b(d_{ik})^2} \tag{1-1} Jb(U,v)=i=1∑nk=1∑c(μik)b(dik)2(1-1)
其中, d i k = d ( x i − v k ) = ∑ j = 1 m ( x i j − v k j ) 2 d_{ik} = d(x_i-v_k) = \sqrt{\displaystyle \sum^{m }_{j= 1}(x_{ij}-v_{kj})^2} dik=d(xi−vk)=j=1∑m(xij−vkj)2。 d i k d_{ik} dik是欧几里得距离,用来度量第 i i i个样本 x i x_i xi与第 k k k类中心点之间的距离; m m m是样本的特征数; b b b是加权参数,取值范围是1 ⩽ \leqslant ⩽ b b b ⩽ \leqslant ⩽ ∞ \infty ∞。模糊C-均值聚类方法就是寻找到一种最佳的分类,以使该分类能产生最小的函数值 J b J_b Jb。它要求一个样本对于各个聚类的隶属度值和为1,既满足
∑ j = 1 c μ j ( x i ) = 1 , i = 1 , 2 , ⋅ ⋅ ⋅ , n (1-2) \displaystyle \sum^{c }_{j= 1}{\mu_j(x_i) =1, i=1,2,···,n \tag{1-2}} j=1∑cμj(xi)=1,i=1,2,⋅⋅⋅,n(1-2)
式(1-3)与式子(1-4)分别用于计算样本 x i x_i xi对于类 A k A_k Ak的隶属度 μ i k \mu_{ik} μik和 c c c个聚类中心{ v i v_i vi}:
μ i k = 1 ∑ j = 1 c ( d i k d l k ) 2 b − 1 (1-3) \mu_{ik} = \frac{1}{\displaystyle \sum^{c }_{j= 1}{(\frac{d_{ik}}{d_{lk}})^\frac{2}{b-1}}\tag{1-3}} μik=j=1∑c(dlkdik)b−121(1-3)
设 I k I_k Ik = { i i i|2 ⩽ \leqslant ⩽ c c c ⩽ \leqslant ⩽ n n n; d i k d_{ik} dik = 0},对于所有的 i i i类, i ∈ I k i \in I_k i∈Ik, u i k u_{ik} uik = 0。
v i j = ∑ k = 1 n ( μ i k ) b x k j ∑ k = 1 n ( μ i k ) b (1-4) v_{ij} = \frac{\displaystyle \sum^{n }_{k= 1}(\mu_{ik})^bx_{kj}}{\displaystyle \sum^{n }_{k= 1}(\mu_{ik})^b}\tag{1-4} vij=k=1∑n(μik)bk=1∑n(μik)bxkj(1-4)
用式(1-3)和式(1-4)反复修改聚类中心、数据隶属度和进行分类,当算法收敛时,理论上就得到了各类的聚类中心以及各个样本对于各模式的隶属度,从而完成了模糊聚类划分。尽管FCM有很高的搜索速度,但FCM时一种局部搜索算法,且对聚类中心的初始值十分敏感,如果初值选择不当,他就会收敛到局部极小点。
2、MATLAB实现
1)、问题描述
本章将随机产生数据集及进行实验。数据集由400个二维平面上的点组成,这些点构成4个集合,但彼此之间没有明显的极限。
2)、算法实现
MATLAB程序
1、加载数据集并观察数据分布
clc;clear;
%% 加载数据
load X
X X X是400 × 2 \times2 ×2的数据集,第一列是 x x x轴坐标,第二列是 y y y轴坐标。
2、观察数据集分布
figure
plot(X(:,1),X(:,2),'o');
hold on;
数据集如下所示:
 3、进行模糊C-均值聚类
3、进行模糊C-均值聚类
%进行模糊C均值聚类
% 设置幂指数为3,最大迭代次数为20,目标函数的终止容限为1e-6
options=[3,20,1e-6,0];
% 调用fcm函数进行模糊C均值聚类,返回类中心坐标矩阵center,隶属度矩阵U,目标函数值obj_fcn
cn=4; %聚类数
[center,U,obj_fcn]=fcm(X,cn,options);
Jb=obj_fcn(end)
maxU = max(U);
index1 = find(U(1,:) == maxU);
index2 = find(U(2, :) == maxU);
index3 = find(U(3, :) == maxU);
% 在前三类样本数据中分别画上不同记号 不加记号的就是第四类了
line(X(index1,1), X(index1, 2), 'linestyle', 'none', 'marker', '*', 'color', 'g');
line(X(index2,1), X(index2, 2), 'linestyle', 'none', 'marker', '*', 'color', 'r');
line(X(index3,1), X(index3, 2), 'linestyle', 'none', 'marker', '*', 'color', 'b');
% 画出聚类中心
plot(center(:,1),center(:,2),'v')
hold off
4、完整代码
clc
clear
%% 加载数据
load X
figure
plot(X(:,1),X(:,2),'o')
hold on
%进行模糊C均值聚类
% 设置幂指数为3,最大迭代次数为20,目标函数的终止容限为1e-6
options=[3,20,1e-6,0];
% 调用fcm函数进行模糊C均值聚类,返回类中心坐标矩阵center,隶属度矩阵U,目标函数值obj_fcn
cn=4; %聚类数
[center,U,obj_fcn]=fcm(X,cn,options);
Jb=obj_fcn(end)
maxU = max(U);
index1 = find(U(1,:) == maxU);
index2 = find(U(2, :) == maxU);
index3 = find(U(3, :) == maxU);
% 在前三类样本数据中分别画上不同记号 不加记号的就是第四类了
line(X(index1,1), X(index1, 2), 'linestyle', 'none', 'marker', '*', 'color', 'g');
line(X(index2,1), X(index2, 2), 'linestyle', 'none', 'marker', '*', 'color', 'r');
line(X(index3,1), X(index3, 2), 'linestyle', 'none', 'marker', '*', 'color', 'b');
% 画出聚类中心
plot(center(:,1),center(:,2),'v')
hold off
5、聚类结果展示
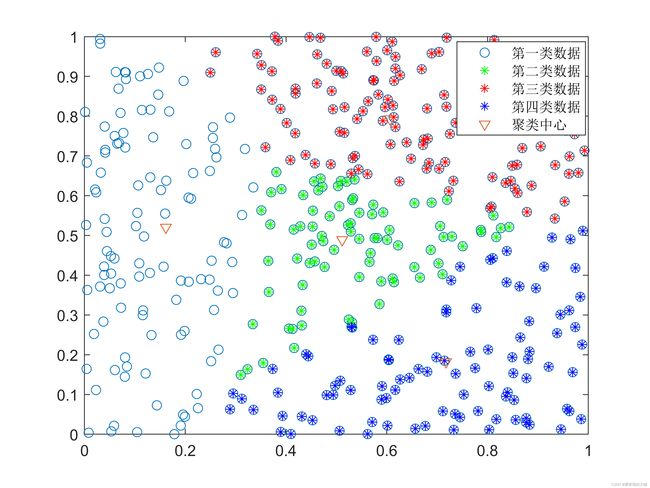
由此图可以看出数据集被我们划分为了4类(类别需要自己定,这里我们定位4类。可以用肘部法则来辅助判断,后续文章后提到,这里就不多说,其实很简单,网上有很多资料介绍)。
6、聚类效果判断
这里我们用上文提到的目标函数值 J b J_b Jb来进行分析
| 目标函数值 J b J_b Jb | |
|---|---|
| 第一次 | 3.4862 |
| 第二次 | 3.4613 |
| 第三次 | 3.4683 |
| 第四次 | 3.5317 |
通过进行4次聚类,发现目标函数值 J b J_b Jb均大于3.46。下面我们将用模拟退火算法结合遗传算法对此进行优化。
二、基于遗传模拟退火算法的模糊C-均值聚类算法(SAGAFCM)
1、模拟算法介绍算法介绍
1)、算法介绍
模拟退火算法于1983年成功地应用在组合优化问题上,其思想想是通过模拟高温物体退火过程找到优化问题的全局最优或者近似全局最优解。首先产生一个初始解作为当前解,然后在当前解的领域中,以概率 P ( T ) P(T) P(T)选择一个非局部最优解,并令这个解再重复下去,从而保证不会陷入局部最优。开始时允许参数调整,目标函数偶尔向增加的方向发展(对应于能量由上升),以利于跳出局部极小区域。随着假想温度的降低(对应于物体的退火),系统活动性降低,最终以概率1稳定在全局最小区域。
2)、算法核心公式
具体的算法这里不详细介绍,大家可以自行上网查找。
下面给出接受准则 P ( T ) P(T) P(T)(Metropolis准则):
首先给定一个初始温度 T 0 T_0 T0和该优化问题的初始解 x ( 0 ) x(0) x(0),并由 x ( 0 ) x(0) x(0)产生下一个解 x ′ ∈ N ( x ( 0 ) ) x' \in N(x(0)) x′∈N(x(0)),是否接受 x ′ x' x′作为一个新解 x ( 1 ) x(1) x(1)依赖于如下概率( P ( T ) P(T) P(T)(Metropolis准则)):
P ( x ( 0 ) → x ′ ) = { 1 , f ( x ′ ) < f ( x ( 0 ) ) e − f ( x ′ ) − f ( x ( 0 ) ) T 0 , 其他 P(x(0)→x') = \begin{cases} 1 ,&f(x')
换句话说,如果生成的解 x ′ x' x′的函数值比前一个解的函数值更小,则接受 x ( 1 ) = x ′ x(1) = x' x(1)=x′作为一个新解,否则以概率 e − f ( x ′ ) − f ( x ( 0 ) ) T 0 e^-\frac{f(x')-f(x(0))}{T_0} e−T0f(x′)−f(x(0))接受 x ′ x' x′作为一个新解。
泛泛地说,对于一个温度 T i T_i Ti和还优化问题的一个解 x ( k ) x(k) x(k),可以生成 x ′ x' x′。接受 x ′ x' x′作为下一个新解 x ( k + 1 ) x(k+1) x(k+1)的概率为:
P ( x ( k ) → x ′ ) = { 1 , f ( x ′ ) < f ( x ( k ) ) e − f ( x ′ ) − f ( x ( k ) ) T i , 其他 (2-1) P(x(k)→x') = \begin{cases} 1 ,&f(x')
在温度 T i T_i Ti下,经过很多次的转换之后,降低温度 T i T_i Ti,得到 T i < T i T_i
3)、算法可行性解释
注意到在每个 T i T_i Ti,所得到的一个新状态 x ( k + 1 ) x(k+1) x(k+1)完全依赖于前一个状态 x ( k ) x(k) x(k),和前面的状态 x ( 0 ) , x ( 1 ) , ⋅ ⋅ ⋅ , x ( k − 1 ) x(0),x(1),···,x(k-1) x(0),x(1),⋅⋅⋅,x(k−1)无关,因此这是一个马尔可夫过程。使用马尔可夫过程对上诉模拟退火的步骤进行分析,结果表明从任何一个状态 x ( k ) x(k) x(k)生成 x ′ x' x′的概率,在 N ( x ( k ) ) N(x(k)) N(x(k))中是均匀分布的,且新状态 x ′ x' x′被接受的概率满足式子(2-1),那么经过有限次的转换,在温度 T i T_i Ti下的平衡态 x i x_i xi的分布由下式给出:
P i ( T i ) = e − f ( x i ) T i ∑ j ∈ S e − f ( x j ) T i P_i(T_i) = \frac{e^\frac{-f(x_i)}{T_i}}{\displaystyle \sum^{}_{j \in S}e^\frac{-f(x_j)}{T_i}} Pi(Ti)=j∈S∑eTi−f(xj)eTi−f(xi)
当温度 T T T降为 0 0 0时, x i x_i xi的分布为:
P i ∗ = { 1 ∣ S m i n ∣ , x i ∈ S m i n 0 , 其他 P_i^* = \begin{cases} \frac{1}{|S_{min}|},&x_i \in S_{min}\\ 0,&其他\\ \end{cases} Pi∗={∣Smin∣1,0,xi∈Smin其他
并且
∑ x i ∈ S m i n P i ∗ = 1 \displaystyle \sum^{}_{x_i \in S_{min}}P_i^* = 1 xi∈Smin∑Pi∗=1
这说明如果温度下降十分缓慢,而在每个温度都有足够多次的状态转换,使之在每一个温度下达到热平衡,则全局最优解将以概率1被找到。因此可以说模拟退火算法可以找到全局最优解。
2、遗传算法介绍
1)、算法介绍
遗传算法(Genetic Algorithms,简称 GA)是一种基于自然选择原理和自然遗传机制的搜索(寻优)算法,它是模拟自然界中的生命进化机制,在人工系统中实现特定目标的优化。遗传算法的实质是通过群体搜索技术,根据适者生存的原则逐代进化,最终得到最优解或准最优解。它必须做以下操作:初始群体的产生、求每一个体的适应度、根据适者生存的原则选择优良个体、被选出的优良个体两两配对,通过随机交叉其染色体的基因并随机变异某些染色体的基因生成下一代群体,按此方法使群体逐代进化,直到满足进化终止条件。
2)、算法核心思想
具体的算法这里不详细介绍,大家可以自行上网查找。
大致的实现方法如下:
(1)根据具体问题确定可行解域,确定一种编码方法,能用数值串或字符串表示可行解域的每一解。
(2)对每一解应有一个度量好坏的依据,它用一函数表示,叫做适应度函数,一般由目标函数构成。
(3)确定进化参数群体规模 M M M 、交叉概率 p c p_c pc 、变异概率 p m p_m pm、进化终止条件。
为便于计算,一般来说,每一代群体的个体数目都取相等。群体规模越大、越容易找到最优解,但由于受到计算机的运算能力的限制,群体规模越大,计算所需要的时间也相应地增加。进化终止条件指的是当进化到什么时候结束,它可以设定到某一代进化结束,也可以根据找出近似最优解是否满足精度要求来确定。下表列出了生物遗传概念在遗传算法中的对应关系。
| 生物遗传概念 | 遗传算法中的作用 |
|---|---|
| 适者生存 | 算法停止时,最优目标值的可行解有最大的可能被留住 |
| 个体 | 可行解 |
| 染色体 | 可行解的编码 |
| 基因 | 可行解中每一分量的特征 |
| 适应性 | 适应度函数值 |
| 种群 | 根据适应度函数值选取的一组可行解 |
| 交配 | 通过交配原则产生一组新可行解的过程 |
| 变异 | 编码的某一分量发生变化的过程 |
3、算法优缺点即组合原因
1)、模拟退火算法的优缺点
1、模拟退火算法的优点:
1. 能够有效解决NP难问题、避免陷入局部最优解。
2. 计算过程简单,通用,鲁棒性强,适用于并行处理,可用于求解复杂的非线性优化问题。
3. 模拟退火算法与初始值无关,算法求得的解与初始解状态S(是算法迭代的起点)无关;
4. 模拟退火算法具有渐近收敛性,已在理论上被证明是一种以概率收敛于全局最优解的全局优化算法;
模拟退火算法具有并行性
2、模拟退火算法的缺点:
1. 收敛速度慢,执行时间长,算法性能与初始值有关及参数敏感等缺点。
2. 由于要求较高的初始温度、较慢的降温速率、较低的终止温度,以及各温度下足够多次的抽样,因此优化过程较长。
3. 如果降温过程足够缓慢,多得到的解的性能会比较好,但与此相对的是收敛速度太慢;
4. 如果降温过程过快,很可能得不到全局最优解。
2)、遗传算法的优缺点
1、遗传算法的优点:
1. 与问题领域无关切快速随机的搜索能力。
2. 搜索从群体出发,具有潜在的并行性,可以进行多个个体的同时比较,robust.
3. 搜索使用评价函数启发,过程简单
4. 使用概率机制进行迭代,具有随机性。
5. 具有可扩展性,容易与其他算法结合
2、遗传算法的缺点:
1、遗传算法的编程实现比较复杂,首先需要对问题进行编码,找到最优解之后还需要对问题进行解码,
2、另外三个算子的实现也有许多参数,如交叉率和变异率,并且这些参数的选择严重影响解的品质,而目前这些参数的选择大部分是依靠经验.
3、没有能够及时利用网络的反馈信息,故算法的搜索速度比较慢,要得要较精确的解需要较多的训练时间。
4、算法对初始种群的选择有一定的依赖性,能够结合一些启发算法进行改进。
5、算法的并行机制的潜在能力没有得到充分的利用,这也是当前遗传算法的一个研究热点方向。
3)、算法组合
由于模拟退火算法和遗传算法可以相互取长补短,因此有效地客服了传统遗传算法早熟的现象,同时根据聚类问题的具体情况设计遗传编码方式及适应度函数,使得该算法更有效、更快捷地收敛到全局最优解。
4、算法实现流程
基于模拟退火遗传算法地模糊C-均值聚类,其过程如下图所示:
(1)初始化控制参数:种群个体大小 s i z e p o p sizepop sizepop,最大进化次数 M A X G E N MAXGEN MAXGEN ,交叉概率 P c P_c Pc,变异概率 P m P_m Pm,退火温度 T 0 T_0 T0,温度冷却系数 k k k,终止温度 T e n d T_{end} Tend。
(2)初始话c个聚类中心,并生成初始种群 C h r o m Chrom Chrom,对每个聚类中心用(1-3)计算各样本地隶属度,以及每个个体地适应度 f i f_i fi ,其中 i = 1 , 2 ⋅ ⋅ ⋅ , s i z e p o p i = 1,2···,sizepop i=1,2⋅⋅⋅,sizepop。
图 基于模拟退火遗传算法的模糊C-均值聚类流程图
(这个markdown画的流程图有点丑,因为初学也不会高级的用法,大家凑合看吧)
(3)设置循环计数变量 g e n = 0 gen = 0 gen=0
(4)对群体 C h r o m Chrom Chrom实施选择。交叉、变异等遗传操作,对新产生的个体用式(1-3)、(1-4)计算 c c c个聚类中心、各样本的隶属度,以及每一个体的适应度值 f i ′ f'_i fi′。若 f i ′ > f i f'_i>f_i fi′>fi,则以新个体替代旧个体;否则,以概率 P = e − f i ′ − f i T P = e^\frac{-f'_i-f_i}{ T} P=eT−fi′−fi接受新个体,舍弃旧个体。
(5)若 g e n < M A X G E N gen
(6)若 T i < T e n d T_i
5、MATLAB算法实现
1)、目标函数
目标函数是算出每个个体的FCM聚类 J b J_b Jb值, J b J_b Jb越小,个体适应度值就越高。目标函数名为FCMfun,函数代码如下:
function [obj,center,U]=FCMfun(X,cluster_n,center,options)
%% FCM主函数
% 输入
% X:样本数据
%cluster_n:聚类数
% center:初始聚类中心矩阵
% options:设置幂指数,最大迭代次数,目标函数的终止容限
% 输出
% obj:目标输出Jb值
% center:优化后的聚类中心
% U:相似分类矩阵
X_n=size(X,1);
in_n=size(X,2);
b=options(1); % 加权参数
max_iter=options(2); % 最大迭代次数
min_impro=options(3); % 相邻两次迭代最小改进(用来判断是否提前终止)
obj_fcn=zeros(max_iter,1); % 初始化目标值矩阵
U = initFCM(X,cluster_n,center,b); % 初始化聚类相似矩阵
% 主函数循环
for i = 1:max_iter,
[U, center,obj_fcn(i)]=iterateFCM(X,U,cluster_n,b);
% 核对终止条件
if i > 1
if abs(obj_fcn(i) - obj_fcn(i-1)) < min_impro, break; end,
end
end
iter_n = i; % 真实迭代次数
obj_fcn(iter_n+1:max_iter)=[];
obj=obj_fcn(end);
其中用到了两个自定义函数initFCM和iterateFCM
2)、initFCM函数
initFCNM是用来初始化相似分类矩阵 U U U的,代码如下:
function U=initFCM(X,cluster_n,center,b)
%% 初始化相似分类矩阵
% 输入
% X:样本数据
%cluster_n:聚类数
% center:初始聚类中心矩阵
% b:设置幂指数
% 输出
% U:相似分类矩阵
dist=distfcm(center,X); % 求出各样本与各聚类中心的距离矩阵
%% 计算新的U矩阵
tmp=dist.^(-2/(b-1));
U=tmp./(ones(cluster_n,1)*sum(tmp));
2)、iterateFCM函数
iterateFCM是用来反复修改聚类中心、数据隶属度和进行分类的函数,代码如下:
function [U_new,center,obj_fcn]=iterateFCM(X,U,cluster_n,b)
%% 迭代
% 输入
% X:样本数据
% U:相似分类矩阵
%cluster_n:聚类数
% b:幂指数
% 输出
%obj_fcn:当前目标输出Jb值
% center:新的的聚类中心
% U_new:相似分类矩阵
mf=U.^b; % 指数修正后的mf矩阵
center=mf*X./((ones(size(X,2),1)*sum(mf'))'); % 新的聚类中心
%% 目标值
dist=distfcm(center,X); % 求出各样本与各聚类中心的距离矩阵
obj_fcn=sum(sum((dist.^2).*mf)); % 目标函数值
%% 计算新的U矩阵
tmp=dist.^(-2/(b-1));
U_new=tmp./(ones(cluster_n,1)*sum(tmp));
3)、主函数
以下代码中的遗传部分直接采用Sheffield工具箱函数。主函数代码如下:
clc
clear all;close all
load X
m=size(X,2);% 样本特征维数
% 中心点范围[lb;ub]
lb=min(X);
ub=max(X);
%% 模糊C均值聚类参数
% 设置幂指数为3,最大迭代次数为20,目标函数的终止容限为1e-6
options=[3,20,1e-6];
% 类别数cn
cn=4;
%% 模拟退火算法参数
q =0.8; % 冷却系数
T0=100; % 初始温度
Tend=1; % 终止温度
%% 定义遗传算法参数
sizepop=10; %个体数目(Numbe of individuals)
MAXGEN=10; %最大遗传代数(Maximum number of generations)
NVAR=m*cn; %变量的维数
PRECI=10; %变量的二进制位数(Precision of variables)
GGAP=0.9; %代沟(Generation gap)
pc=0.7;
pm=0.01;
trace=zeros(NVAR+1,MAXGEN);
%建立区域描述器(Build field descriptor)
FieldD=[rep([PRECI],[1,NVAR]);rep([lb;ub],[1,cn]);rep([1;0;1;1],[1,NVAR])];
Chrom=crtbp(sizepop, NVAR*PRECI); % 创建初始种群
V=bs2rv(Chrom, FieldD);
ObjV=ObjFun(X,cn,V,options); %计算初始种群个体的目标函数值
T=T0;
while T>Tend
gen=0; %代计数器
while gen<MAXGEN %迭代
FitnV=ranking(ObjV); %分配适应度值(Assign fitness values)
SelCh=select('sus', Chrom, FitnV, GGAP); %选择
SelCh=recombin('xovsp', SelCh,pc); %重组
SelCh=mut(SelCh,pm); %变异
V=bs2rv(SelCh, FieldD);
ObjVSel=ObjFun(X,cn,V,options); %计算子代目标函数值
[newChrom, newObjV]=reins(Chrom, SelCh, 1, 1, ObjV, ObjVSel); %重插入
V=bs2rv(newChrom,FieldD);
%是否替换旧个体
for i=1:sizepop
if ObjV(i)>newObjV(i)
ObjV(i)=newObjV(i);
Chrom(i,:)=newChrom(i,:);
else
p=rand;
if p<=exp((newObjV(i)-ObjV(i))/T)
ObjV(i)=newObjV(i);
Chrom(i,:)=newChrom(i,:);
end
end
end
gen=gen+1; %代计数器增加
[trace(end,gen),index]=min(ObjV); %遗传算法性能跟踪
trace(1:NVAR,gen)=V(index,:);
fprintf(1,'%d ',gen);
end
T=T*q;
fprintf(1,'\n温度:%1.3f\n',T);
end
[newObjV,center,U]=ObjFun(X,cn,[trace(1:NVAR,end)]',options); %计算最佳初始聚类中心的目标函数值
% 查看聚类结果
Jb=newObjV
U=U{1};
center=center{1}
figure
plot(X(:,1),X(:,2),'o')
hold on
maxU = max(U);
index1 = find(U(1,:) == maxU);
index2 = find(U(2, :) == maxU);
index3 = find(U(3, :) == maxU);
% 在前三类样本数据中分别画上不同记号 不加记号的就是第四类了
line(X(index1,1), X(index1, 2), 'linestyle', 'none','marker', '*', 'color', 'g');
line(X(index2,1), X(index2, 2), 'linestyle', 'none', 'marker', '*', 'color', 'r');
line(X(index3,1), X(index3, 2), 'linestyle', 'none', 'marker', '*', 'color', 'b');
% 画出聚类中心
plot(center(:,1),center(:,2),'v')
hold off
4)、结果分析
1、结果展示如下图所示:
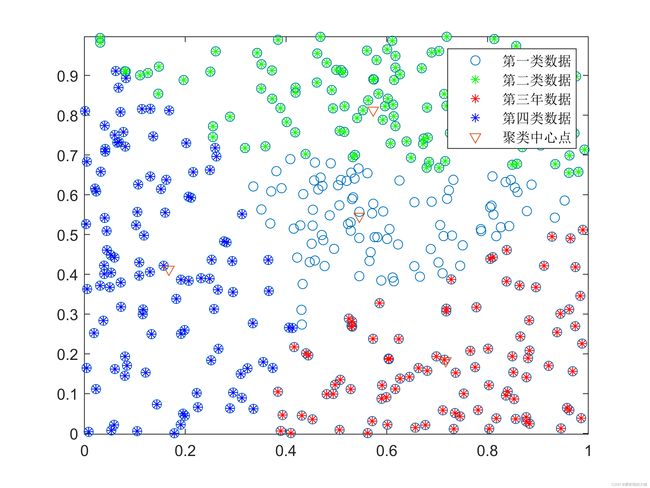
2、聚类效果判断
这里我们用上文提到的目标函数值 J b J_b Jb来进行分析
| 目标函数值 J b J_b Jb | |
|---|---|
| 第一次 | 3.4566 |
| 第二次 | 3.4566 |
| 第三次 | 3.4566 |
| 第四次 | 3.4566 |
SAGA优化后的FCM聚类由未优化时 J b = 3.46 + J_b = 3.46+ Jb=3.46+变成 J b = 3.4566 J_b=3.4566 Jb=3.4566,而且每次都可以得到最优目标函数值。当数据量较大时,SAGA的优越性更加明显。其主要原因是单纯的FCM在处理大规模数据时,更加容易收敛到局部最优解,而将遗传算法与模拟退火算法相结合形成一种混合算法后,可以有效地克服收敛到局部最优解地情况。
三、代码链接
链接:[https://pan.baidu.com/s/1f6uk3tu7ycn7cmiCqQ774Q?pwd=1111
提取码:1111
MATLAB智能算法30案例分析(第二版)