深度学习七 —— BN & LN & IN & GN
文章目录
- BN & LN & IN & GN
-
- 介绍
-
- 为什么要用 γ \gamma γ 和 β \beta β?
- 区别
- Batch Normalization(BN)
-
- BN层的过程
- BN层的作用及分析
-
- 作用
- 分析
- BN层在训练集和测试集上有什么不同?
- BN放在什么位置?
- Layer Normalization(LN)
- Instance Normalization(IN)
- Group Normalization(GN)
BN & LN & IN & GN
介绍
神经网络中,有各种各样的归一化算法:Batch Normalization(BN)、Layer Normalization(LN)、Instance Normalization(IN)、Group Normalization(GN)。
从公式上看,他们差不多:无非是减去均值,除以标准差,再施以线性映射。
y = γ ( x − μ ( x ) σ ( x ) ) + β y = \gamma (\frac{x - \mu(x)}{\sigma(x)} ) + \beta y=γ(σ(x)x−μ(x))+β
其中,
γ \gamma γ——缩放因子,
β \beta β——平移因子,
这些归一化的算法主要区别在于:操作的feature map维度不同。
为什么要用 γ \gamma γ 和 β \beta β?
BN层对原有数据进行标准化处理,将其变为均值为 0 0 0,方差为 1 1 1的正态分布,但是这也不可避免的改变了数据的分布,从而可能会对激活函数只使用了其线性部分,限制了模型的表达能力。引入 γ \gamma γ和 β \beta β可以对标准化后的数据进行重构,使其尽量还原出原有数据的分布。
区别
区别,一图可见
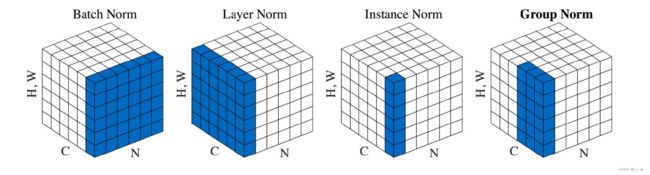
其中C轴表示通道,N轴表示Batch中的样本序号,H、W轴可以认为是图像样本中的宽和高
Batch Normalization(BN)
BN层的过程
在CNN网络中,每层网络的输出都有多个feature map(通道),每个feature map又是由多个像素点组成的;在进行BN时,算法会将一个batch中的所有样本的所有feature map按feature map的序号划分为N(N = feature map)组,然后对这N组的所有像素点进行N次标准化。
BN层的作用及分析
作用
- 加快网络的训练和收敛速度
- 防止梯度爆炸和梯度消失
- 防止过拟合
分析
(1) 加快收敛速度
在深度学习网络中,如果每层的数据分布不一样的话,将会导致网络非常难收敛和训练。而如果把每层的数据都转换为均值为0,方差为1的状态下,这样每层数据的分布都是一样的,训练会更容易收敛。
(2)防止梯度爆炸和梯度消失
梯度消失:
以sigmoid函数为例,sigmoid函数使得输出在 [ 0 , 1 ] [0,1] [0,1]之间,实际上当 x x x过大,或者过小时,经过sigmoid后输出范围就会变得很小,而且反向传播时的梯度就会非常小,从而导致梯度消失的问题,同时也会导致网络学习速度过慢;同时,由于网络的前端比后端求梯度需要更多次的求导运算,最终会出现网络后端一直学习,前端几乎不学习的情况。
BN层通常被添加在全连接和激活函数之间,使得数据在进入激活函数之前集中分布在0值附近,大部分激活函数在0周围时输出都有较大变换,下图可以很好的解释这个现象。
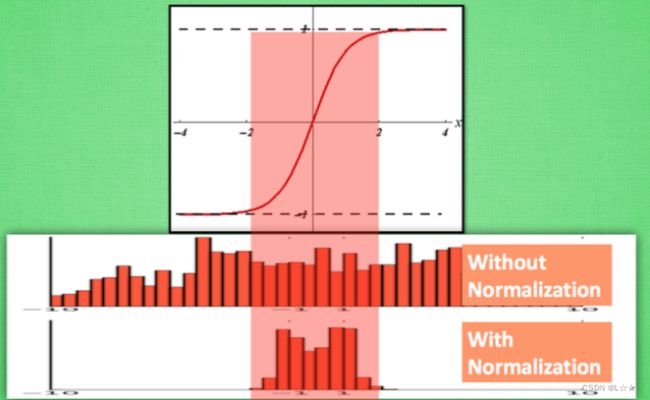
梯度爆炸:
第一层的偏移量的梯度 = 激活层斜率 ( 1 ) × 权值 ( 1 ) × 激活层斜率 ( 2 ) × 权值 ( 2 ) × ⋯ 激活层斜率 ( n − 1 ) × 权值 ( n − 1 ) × 激活层斜率 ( n ) 第一层的偏移量的梯度 = 激活层斜率(1) \times 权值(1) \times 激活层斜率(2) \times 权值(2) \times \cdots 激活层斜率(n-1) \times 权值(n - 1) \times 激活层斜率(n) 第一层的偏移量的梯度=激活层斜率(1)×权值(1)×激活层斜率(2)×权值(2)×⋯激活层斜率(n−1)×权值(n−1)×激活层斜率(n)
假设激活层斜率均为最大值0.25,所有层的权值为100,这样梯度就会出现指数增长,即出现了梯度爆炸情况。
但是使用BN层之后,权值的更新也不会很大,可以防止梯度爆炸的发生。
(3)防止过拟合
在网络的训练中,BN的使用使得一个minibatch中所有样本都被关联在一起,因此网络不会从某一个训练样本中生成确定的结果,即同样一个样本的输出不再仅仅取决于样本本身,也取决于跟这个样本同属一个batch的其他样本,而每次网络的batch都是随机的,这样就会使得整个网络不会只朝着一个方向学习,在一定程度上避免了过拟合。
BN层在训练集和测试集上有什么不同?
训练时: BN层每次都会用每个batch内数据的均值和标准差对Batch内的样本进行标准化;同时会通过滑动平均的方式不断更新训练集上全局均值和方差并保存。
测试时: 用保存好的训练集上的均值和方差,对测试集上的每个数据进行标准化
BN放在什么位置?
BN层一般放在激活函数之前或者之后,这两种效果其实影响不大。但是当激活函数使用sigmoid或者tanh时,将BN层放在激活函数之前,能够防止输入激活函数的值过大或者过小,从而防止梯度消失的现象。
Layer Normalization(LN)
Layer Normalization是将一个样本中的所有数据进行标准化。通常用在RNN或者LSTM网络中。因为RNN一般用来处理序列数据,大部分序列类型的数据样本长度往往存在较大差异,如果使用BN处理就会出现某些通道没有某些样本数据的问题,即使使用特定字符填充,也会造成某些通道分布不均匀的问题。
Instance Normalization(IN)
Instance Normalization是对一个样本中的每一个通道进行单独的标准化。 一般用于风格化迁移,但如果特征图可以用到通道之间的相关性,那么就不建议使用使用Instance Normalization处理。
Group Normalization(GN)
Group Normalization是Layer Normalization和Instance Normalization标准化的折中做法,GN算法将一个样本的通道划分为多个group,然后在对每一个group进行标准化。
以CNN训练图像为例,使用多个卷积核对图像进行卷积会得到多个feature map,但这些feature map并不一定都是相互独立的,某些feature map之间可能存在某些联系,这时使用IN算法对每一个feature map做标准化无疑会丢失这些关联,而为了某些frature map之间的联系而使用LN算法对整个样本进行标准化又会占用大量内存资源,造成不必要的浪费。
GN算法首先将相互关联的feature map组合成一个group,然后在这个group上进行标准化,这样既保留了通道之间的关联,又节省了资源,同时解决了batch_size过小时,BN效果较差的问题。