机器学习-sklearn第十一天——笔记
目录
- SVM(下)
-
- 4 SVC真实数据案例:预测明天是否会下雨
-
- 4.1 导库导数据,探索特征
- 4.2 分集,优先探索标签
- 4.3 探索特征,开始处理特征矩阵
-
- 4.3.1 描述性统计与异常值
- 4.3.2 处理困难特征:日期
- 4.3.3 处理困难特征:地点
- 4.3.4 处理分类型变量:缺失值
- 4.3.5 处理分类型变量
- 4.3.6 处理连续型变量:填补缺失值
- 4.3.7 处理连续型变量:无量纲化
- 4.4 建模与模型评估
- 4.5 模型调参
-
- 4.5.1 最求最高Recall
- 4.5.2 追求最高准确率
- 4.5.3 追求平衡
SVM(下)
4 SVC真实数据案例:预测明天是否会下雨
SVC在现实中的应用十分广泛,尤其实在图像和文字识别方面。然而,这些数据不仅非常难以获取,还难以在课程中完整呈现出来,但SVC真实应用的代码其实就是sklearn中的三行,真正能够展现出SVM强大之处的,反而很少是案例本身,而是我们之前所作的各种探索。
我们在学习算法的时候,会使用各种各样的数据集来进行演示,但这些数据往往非常干净并且规整,不需要做太多的数据预处理。在我们讲解第三章:数据预处理与特征工程时,用了自制的文字数据和kaggle上的高维数据来为大家讲解,然而这些数据依然不能够和现实中采集到的数据的复杂程度相比。因此大家学习了这门课程,却依然会对究竟怎样做预处理感到困惑。
4.1 导库导数据,探索特征


粗略观察可以发现,这个特征矩阵由一部分分类变量和一部分连续变量组成,其中云层遮蔽程度虽然是以数字表示,但是本质却是分类变量。大多数特征都是采集的自然数据,比如蒸发量,日照时间,湿度等等,而少部分特征是人为构成的。还有一些是单纯表示样本信息的变量,比如采集信息的地点,以及采集的时间。
4.2 分集,优先探索标签
分训练集和测试集,并做描述性统计

4.3 探索特征,开始处理特征矩阵
4.3.1 描述性统计与异常值


4.3.2 处理困难特征:日期



如此,我们就创造了一个特征,今天是否下雨“RainToday”。
那现在,我们是否就可以将日期删除了呢?对于我们而言,日期本身并不影响天气,但是日期所在的月份和季节其实是影响天气的,如果任选梅雨季节的某一天,那明天下雨的可能性必然比非梅雨季节的那一天要大。虽然我们无法让机器学习体会不同月份是什么季节,但是我们可以对不同月份进行分组,算法可以通过训练感受到,“这个月或者这个季节更容易下雨”。因此,我们可以将月份或者季节提取出来,作为一个特征使用,而舍弃掉具体的日期。如此,我们又可以创造第二个特征,月份"Month”

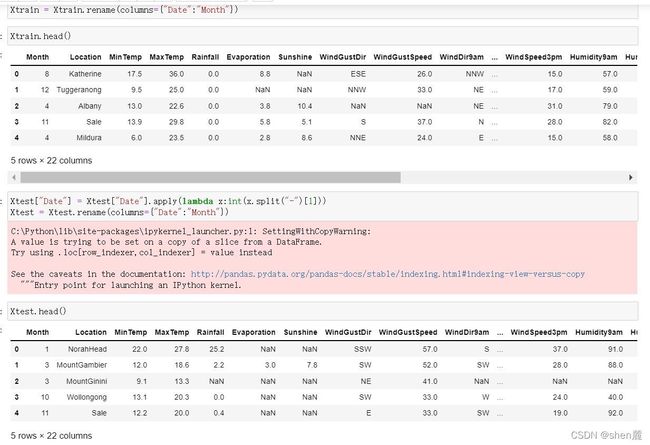
4.3.3 处理困难特征:地点
地点,又是一个非常tricky的特征。常识上来说,我们认为地点肯定是对明天是否会下雨存在影响的。比如说,如果其他信息都不给出,我们只猜测,“伦敦明天是否会下雨”和”北京明天是否会下雨“,我一定会猜测伦敦会下雨,而北京不会,因为伦敦是常年下雨的城市,而北京的气候非常干燥。对澳大利亚这样面积巨大的国家来说,必然存在着不同的城市有着不同的下雨倾向的情况。但尴尬的是,和时间一样,我们输入地点的名字对于算法来说,就是一串字符,"London"和"Beijing"对算法来说,和0,1没有区别。同样,我们的样本中含有49个不同地点,如果做成分类型变量,算法就无法辨别它究竟是否是分类变量。也就是说,我们需要让算法意识到,不同的地点因为气候
不同,所以对“明天是否会下雨”有着不同的影响。如果我们能够将地点转换为这个地方的气候的话,我们就可以将不同城市打包到同一个气候中,而同一个气候下反应的降雨情况应该是相似的。
4.3.4 处理分类型变量:缺失值
接下来,我们总算可以开始处理我们的缺失值了。首先我们要注意到,由于我们的特征矩阵由两种类型的数据组成:分类型和连续型,因此我们必须对两种数据采用不同的填补缺失值策略。传统地,如果是分类型特征,我们则采用众数进行填补。如果是连续型特征,我们则采用均值来填补。
Xtrain.isnull().mean()
#首先找出,分类型特征都有哪些
cate = Xtrain.columns[Xtrain.dtypes == "object"].tolist()
#除了特征类型为"object"的特征们,还有虽然用数字表示,但是本质为分类型特征的云层遮蔽程度
cloud = ["Cloud9am","Cloud3pm"]
cate = cate + cloud
cate
#对于分类型特征,我们使用众数来进行填补
from sklearn.impute import SimpleImputer
si = SimpleImputer(missing_values=np.nan,strategy="most_frequent")
Xtrain.loc[:,cate] = si.transform(Xtrain.loc[:,cate])
Xtest.loc[:,cate] = si.transform(Xtest.loc[:,cate])
Xtrain.head()
Xtest.head()
Xtrain.loc[:,cate].isnull().mean()
Xtest.loc[:,cate].isnull().mean()


4.3.5 处理分类型变量
将分类型变量编码在编码中,和我们的填补缺失值一样,我们也是需要先用训练集fit模型,本质是将训练集中已经存在的类别转换成是数字,然后我们再使用接口transform分别在测试集和训练集上来编码我们的特征矩阵。当我们使用接口在测试集上进行编码的时候,如果测试集上出现了训练集中从未出现过的类别,那代码就会报错,表示说“我没有见过这个类别,我无法对这个类别进行编码”,此时此刻你就要思考,你的测试集上或许存在异常值,错误值,或者的确有一个新的类别出现了,而你曾经的训练数据中并没有这个类别。以此为基础,你需要调整你的模型。有一个新的类别出现了,而你曾经的训练数据中并没有这个类别。以此为基础,你需要调整你的模型。
from sklearn.preprocessing import OrdinalEncoder
oe = OrdinalEncoder()
oe = oe.fit(Xtrain.loc[:,cate])
Xtrain.loc[:,cate] = oe.transform(Xtrain.loc[:,cate])
Xtest.loc[:,cate] = oe.transform(Xtest.loc[:,cate])
Xtrain.loc[:,cate].head()
Xtest.loc[:,cate].head()
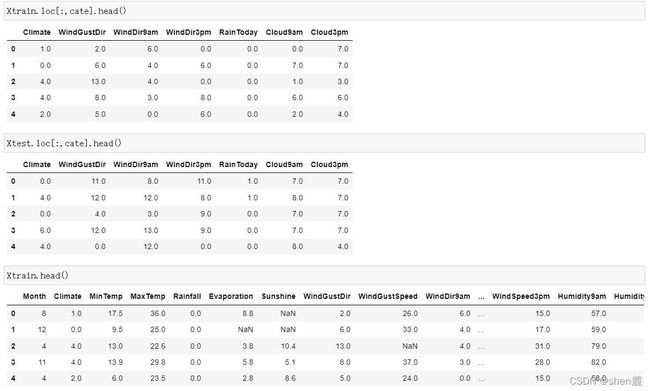
4.3.6 处理连续型变量:填补缺失值
col = Xtrain.columns.tolist()
for i in cate:
col.remove(i)
col
#实例化模型,填补策略为"mean"表示均值
impmean = SimpleImputer(missing_values=np.nan,strategy = "mean") #用训练集来fit模型
impmean = impmean.fit(Xtrain.loc[:,col])
#分别在训练集和测试集上进行均值填补
Xtrain.loc[:,col] = impmean.transform(Xtrain.loc[:,col])
Xtest.loc[:,col] = impmean.transform(Xtest.loc[:,col])
Xtrain.head()
Xtest.head()
4.3.7 处理连续型变量:无量纲化
数据的无量纲化是SVM执行前的重要步骤,因此我们需要对数据进行无量纲化。但注意,这个操作我们不对分类型变量进行。
col.remove("Month")
col
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss = ss.fit(Xtrain.loc[:,col])
Xtrain.loc[:,col] = ss.transform(Xtrain.loc[:,col])
Xtest.loc[:,col] = ss.transform(Xtest.loc[:,col])
Xtrain.head()
Xtest.head()
Ytrain.head()
Ytest.head()


4.4 建模与模型评估

4.5 模型调参
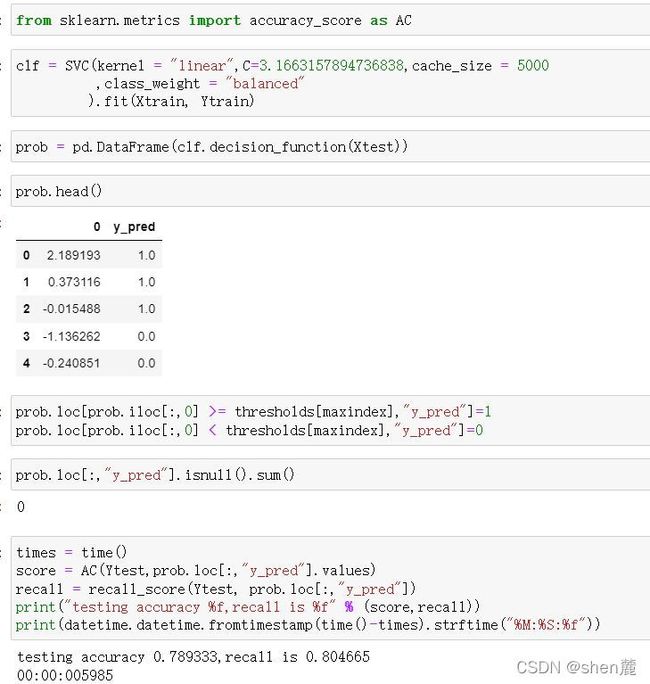
4.5.1 最求最高Recall
4.5.2 追求最高准确率
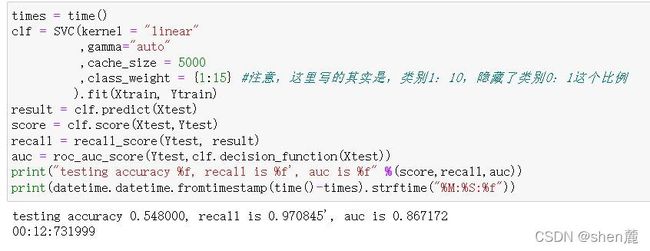
在我们现有的目标(判断明天是否会下雨)下,追求最高准确率而不顾recall其实意义不大, 但出于练习的目的,我们来看看我们能够有怎样的思路。此时此刻我们不在意我们的Recall了,那我们首先要观察一下,我们的样本不均衡状况。如果我们的样本非常不均衡,但是此时却有很多多数类被判错的话,那我们可以让模型任性地把所有地样本都判断为0,完全不顾少数类。
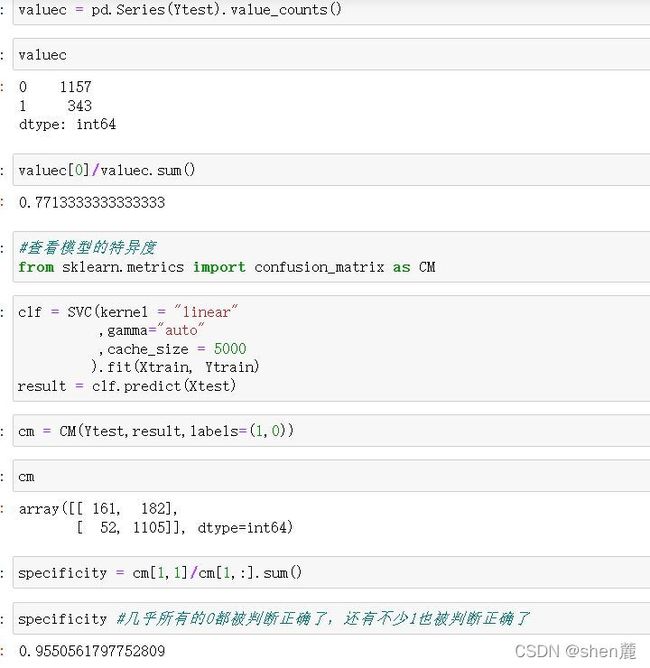
可以试试看使用class_weight将模型向少数类的方向稍微调整,已查看我们是否有更多的空间来提升我们的准确率。如果在轻微向少数类方向调整过程中,出现了更高的准确率,则说明模型还没有到极限。

惊喜出现了,我们的最高准确度是84.53%,超过了我们之前什么都不做的时候得到的84.40%。可见,模型还是有潜力的。我们可以继续细化我们的学习曲线来进行调整:

模型的效果没有太好,并没有再出现比我们的84.53%精确度更高的取值。可见,模型在不做样本平衡的情况下,准确度其实已经非常接近极限了,让模型向着少数类的方向调节,不能够达到质变。如果我们真的希望再提升准确度,只能选择更换模型的方式,调整参数已经不能够帮助我们了。想想看什么模型在线性数据上表现最好呢?

4.5.3 追求平衡
我们前面经历了多种尝试,选定了线性核,并发现调节class_weight并不能够使我们模型有较大的改善。现在我们来试试看调节线性核函数的C值能否有效果:
###======【TIME WARNING:10mins】======###
import matplotlib.pyplot as plt
C_range = np.linspace(0.01,20,20)
recallall = []
aucall = []
scoreall = []
for C in C_range:
times = time()
clf = SVC(kernel = "linear",C=C,cache_size = 5000
,class_weight = "balanced"
).fit(Xtrain, Ytrain)
result = clf.predict(Xtest)
score = clf.score(Xtest,Ytest)
recall = recall_score(Ytest, result)
auc = roc_auc_score(Ytest,clf.decision_function(Xtest))
recallall.append(recall)
aucall.append(auc)
scoreall.append(score)
print("under C %f, testing accuracy is %f,recall is %f', auc is %f" % (C,score,recall,auc))
print(datetime.datetime.fromtimestamp(time()-times).strftime("%M:%S:%f"))
print(max(aucall),C_range[aucall.index(max(aucall))])
plt.figure()
plt.plot(C_range,recallall,c="red",label="recall")
plt.plot(C_range,aucall,c="black",label="auc")
plt.plot(C_range,scoreall,c="orange",label="accuracy")
plt.legend()
plt.show()

可以看到,这种情况下模型的准确率,Recall和AUC都没有太差,但是也没有太好,这也许就是模型平衡后的一种结果。现在,光是调整支持向量机本身的参数,已经不能够满足我们的需求了,要想让AUC面积更进一步,我们需要绘制ROC曲线,查看我们是否可以通过调整阈值来对这个模型进行改进。

基于我们选出的最佳阈值,我们来认为确定y_predict,并确定在这个阈值下的recall和准确度的值: