Logistic回归与最大熵模型
Logistic回归与最大熵模型
-
- 算法介绍
- 逻辑斯谛分布
- 二项logistic回归模型
- 最大熵模型
- 习题6.1
- 习题6.2
算法介绍
1.逻辑斯谛回归(logistic regression)是统计学习中的经典分类方法。最大熵是概率模型学习的一个准则,将其推广到分类问题得到最大熵模型(maximum entropy model)。逻辑斯谛回归模型与最大熵模型都属于对数线性模型。本章首先介绍逻辑斯 谛回归模型,然后介绍最大熵模型,最后讲述逻辑斯谛回归与最大熵模型的学习算法, 包括改进的迭代尺度算法和拟牛顿法。
逻辑斯谛分布
1.设 X X X是连续随机变量, X X X服从逻辑斯谛分布是指 X X X 具有下列分布函数和密度函数:
F ( x ) = P ( X ≤ x ) = 1 1 + e − ( x − u ) / γ ( 1.1 ) F(x)=P(X\leq x)=\frac{1}{1+e^{-(x-u)/\gamma}}(1.1) F(x)=P(X≤x)=1+e−(x−u)/γ1(1.1)
f ( x ) = F ′ ( x ) = e − ( x − u ) / γ γ ( 1 + e − ( x − u ) / γ ) f(x)=F^{'}(x)=\frac{e^{-(x-u)/\gamma}}{\gamma(1+e^{-(x-u)/\gamma})} f(x)=F′(x)=γ(1+e−(x−u)/γ)e−(x−u)/γ
u u u为位置参数, γ > 0 \gamma>0 γ>0为形状参数。
2.逻辑斯谛分布的密度函数 f ( x ) f(x) f(x) 和分布函数F(x)的图形如图1.1所示。分布函数 属于逻辑斯谛函数,其图形是一条S形曲线,该曲线以点 ( u , 1 2 ) (u,\frac{1}{2}) (u,21)为中心对称,即满足
F ( − x + u ) − 1 2 = − F ( x + u ) + 1 2 F(-x+u)-\frac{1}{2}=-F(x+u)+\frac{1}{2} F(−x+u)−21=−F(x+u)+21
曲线在中心附近增长速度较快,在两端增长速度较慢。形状参数7的值越小,曲线在 中心附近增长得越快。
二项logistic回归模型
二项logistic模型是一种分类模型,有条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)表示,形式为参数化的logistic分布。这里,随机变量 X X X取值为实数,随机变量 Y Y Y取值1或0。我们通过监督学习的方法来估计模型参数。
二项logistic回归模型是如下的条件概率分布:
P ( Y = 1 x ) = e w ∗ x + b 1 + e w ∗ x + b P(Y=\frac{1}{x})=\frac {e^{w*x+b}}{1+e^{w*x+b}} P(Y=x1)=1+ew∗x+bew∗x+b
P ( Y = 0 x ) = 1 1 + e w ∗ x + b P(Y=\frac{0}{x})=\frac {1}{1+e^{w*x+b}} P(Y=x0)=1+ew∗x+b1
几率的定义:是指事件发生概率与该事件不发生的概率的比值。:
p 1 − p \frac{p}{1-p} 1−pp
对logistic进行回归
P ( Y = 1 ∣ x ) 1 − P ( Y = 1 ∣ x ) = w ∗ x \frac{P(Y=1|x)}{1-P(Y=1|x)}=w*x 1−P(Y=1∣x)P(Y=1∣x)=w∗x
这里将偏置项 b去掉,从这个角度来看logistic模型其实就是或者说,输出 Y = 1 Y=1 Y=1的对数几率是由输入x的线性函数表示的模型。
对参数进行估计
设:
P ( Y = 1 ∣ x ) = π ( x ) , P ( Y = 0 ∣ x ) = 1 − π ( x ) P(Y=1|x)=\pi(x),P(Y=0|x)=1-\pi(x) P(Y=1∣x)=π(x),P(Y=0∣x)=1−π(x)
其中 π ( x ) = e w ∗ x 1 + e w ∗ x \pi(x)=\frac{e^{w*x}}{1+e^{w*x}} π(x)=1+ew∗xew∗x,其似然函数为:
∏ i = 1 N [ π x i ] y i [ 1 − π ( x i ) ] 1 − y i \prod_{i=1}^N [\pi x_i]^{y_i}[1-\pi(x_i)]^{1-y_i} i=1∏N[πxi]yi[1−π(xi)]1−yi
对数似然函数为:
L ( w ) = ∑ k = 1 N [ y i ] l o g π ( x i ) + ( 1 − y i ) l o g ( 1 − π ( x i ) ) L(w)=\sum_{k=1}^N [y_i]log\pi(x_i)+(1-y_i)log(1-\pi(x_i)) L(w)=k=1∑N[yi]logπ(xi)+(1−yi)log(1−π(xi))
化简得:
L ( w ) = ∑ k = 1 N [ y i ( w x i ) − l o g ( 1 + e w x i ) ] L(w)=\sum_{k=1}^N [y_i(wx_i)-log(1+e^{wx_i})] L(w)=k=1∑N[yi(wxi)−log(1+ewxi)]
最大熵模型
最大熵模型由最大熵原理推导实现。
最大熵原理
最大熵原理认为,学习概率时,在所有可能的概率模型中,熵最大的模型是最好的模型。通常用约束条件来确定概率模型的集合,所以,最大熵原理也可以表述为在满足约束条件的模型集合中选取熵最大的模型。在满足约束的条件(保证精度)下有很多模型,原则上来说这些模型都是可取的,但是从泛化角度来说这些模型中熵值最大的那个也就是说最不确定的那个是最好的模型,因为这样能够尽可能的包含未知数据的信息。
最大熵模型定义
最大熵原理是统计学习的一般原理,将它应用到分类得到最大熵模型。
给定一个训练数据集
T = ( x 1 , y 1 ) , ( x 2 , y 2 ) . . . . ( x N , y N ) T={(x_1,y_1),(x_2,y_2)....(x_N,y_N)} T=(x1,y1),(x2,y2)....(xN,yN)
学习的目标是用最大熵原理选择最好的分类模型。
给定一个训练数据集
T = ( x 1 , y 1 ) , ( x 2 , y 2 ) . . . . ( x N , y N ) T={(x_1,y_1),(x_2,y_2)....(x_N,y_N)} T=(x1,y1),(x2,y2)....(xN,yN)
首先考虑模型应该满足的条件。给定训练数据集,可以确定联合分布 P ( X , Y ) P(X,Y) P(X,Y)的经验分布和边缘分布 P ( X ) P(X) P(X)的经验分布,分别以 P ~ ( X , Y ) \tilde{P}(X,Y) P~(X,Y)和 P ~ ( X ) \tilde{P}(X) P~(X)表示,特征如果离散数据有:
P ~ ( X = x , Y = y ) = v ( X = x , Y = y ) N \tilde{P}(X=x,Y=y)=\frac{v(X=x,Y=y)}{N} P~(X=x,Y=y)=Nv(X=x,Y=y)
P ~ ( X = x ) = v ( X = x ) N \tilde{P}(X=x)=\frac{v(X=x)}{N} P~(X=x)=Nv(X=x)
其中 ν ( X = x , Y = y ) ν(X=x,Y=y) ν(X=x,Y=y)表示训练数据集中样本 ( X , Y ) (X,Y) (X,Y)出现的频次, ν ( X = x ) ν(X=x) ν(X=x)表示训练数据中输入 x x x出现的频次, N N N表示训练样本容量。
用特征函数 $f ( X , Y ) $描述输入 x和输出 y之间的某一个事实。其定义是
s i g n ( x ) = { 1 , x 与 y 满 足 某 一 事 实 0 , 不 满 足 sign(x)=\left\{ \begin{array}{rcl} 1, & & x与y满足某一事实\\ 0, & & 不满足 \end{array} \right. sign(x)={1,0,x与y满足某一事实不满足
它是一个二值函数,当 x x x和 y y y满足这个事实时取值为1,否则取值为0。特征函数 f ( X , Y ) f(X,Y) f(X,Y)关于经验分布 P ~ ( X , Y ) \tilde{P} (X,Y) P~(X,Y)的期望值,用 E P ~ ( f ) E_{\tilde{P}}(f) EP~(f)表示
E P ~ ( f ) = ∑ x , y P ~ ( x , y ) f ( x , y ) E_{\tilde{P}}(f)=\sum\limits_{x,y}\tilde{P}(x,y)f(x,y) EP~(f)=x,y∑P~(x,y)f(x,y)
特征函数 f ( X , Y ) f(X,Y) f(X,Y)关于模型 P ( Y ∣ X ) P(Y∣X) P(Y∣X)与经验分布 P ~ ( X ) \tilde{P}(X) P~(X)的期望值,用 E P ( f ) E _P(f) EP(f)表示
E P ( f ) = ∑ x , y P ~ ( y ∣ x ) f ( x , y ) E_P(f)=\sum\limits_{x,y}\tilde{P}(y|x)f(x,y) EP(f)=x,y∑P~(y∣x)f(x,y)
如果模型能够获取训练数据中的信息,那么就可以假设这两个期望值相等,即
E P ( f ) = E P ~ ( f ) E_P(f)=E_{\tilde{P}}(f) EP(f)=EP~(f)
我们将上式作为最大熵模型的约束条件。定义在条件概率分布 P ( Y ∣ X ) P(Y∣X) P(Y∣X)上的条件熵为
H ( P ) = − ∑ x , y P ~ ( y ∣ x ) l o g ( y ∣ x ) H(P)=-\sum\limits_{x,y}\tilde{P}(y|x)log(y|x) H(P)=−x,y∑P~(y∣x)log(y∣x)
习题6.1
1.题目
确认Logistic分布属于指数分布族。
2.解题思路
列出Logistic分布的定义
列出指数分布族的定义
通过指数倾斜,证明Logistic分布的分布函数无法表示成指数分布族的分布函数形式
3.设XX是连续随机变量,XX服从Logistic分布是指XX具有下列分布函数和密度函数:

式中, μ 为 位 置 参 数 , γ > 0 为 形 状 参 数 。 μ为位置参数,\gamma > 0为形状参数。 μ为位置参数,γ>0为形状参数。
1. 设 γ = 1 , 可 得 单 参 数 的 L o g i s t i c 分 布 ; 1.设\gamma=1,可得单参数的Logistic分布; 1.设γ=1,可得单参数的Logistic分布;
2. 计 算 当 μ = 0 时 , 函 数 f ( x ∣ μ = 0 ) ; 2.计算当μ=0时,函数f(x|\mu=0); 2.计算当μ=0时,函数f(x∣μ=0);
3. 根 据 L o g i s t i c 分 布 的 M G F ( 矩 生 成 函 数 ) , 可 得 E ( e θ x ) ; 3.根据Logistic分布的MGF(矩生成函数),可得E(e ^{θx}); 3.根据Logistic分布的MGF(矩生成函数),可得E(eθx);
4.根据指数倾斜的定义,证明单参数θ的指数倾斜密度函数无法表示成Logistic分布的密度函数形式;可证得,Logistic分布不属于指数分布族;
1.单参数Logistic分布:设 γ = 1 \gamma=1 γ=1,则单参数 μ \mu μ的Logistic分布
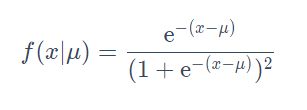
2.计算 f ( x ∣ μ = 0 ) f(x|\mu=0) f(x∣μ=0)

3.Logistic的MGF矩生成函数 M X ( θ ) : M_X (θ): MX(θ):
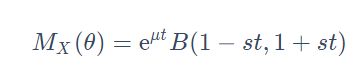
4. 其 中 t ∈ ( − 1 / s , 1 / s ) , B 表 示 B e t a 函 数 其中t \in (-1/s, 1/s),B表示Beta函数 其中t∈(−1/s,1/s),B表示Beta函数
可知,当 u = 0 , s = 1 u=0, s=1 u=0,s=1时
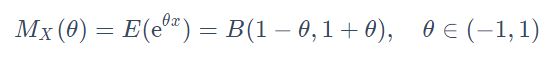
5.给定一个随机变量X,其概率分布为P概率密度为f和矩生成函数(MGF)为 M X ( θ = E ( e θ x ) ) M_X(θ=E(e^{θx})) MX(θ=E(eθx))指数倾斜 P θ P_θ Pθ义如下:
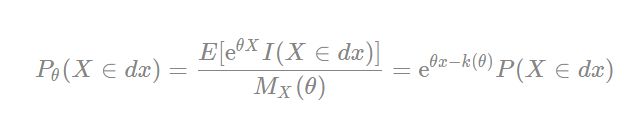
其中, K ( θ ) K(θ) K(θ)表示为累积生成函数(CGF),即 log E ( e θ x ) \log E(e^{θx}) logE(eθx),称 P θ ( X ∈ d x ) = f θ ( x ) P_θ(X∈dx)=f _θ (x) Pθ(X∈dx)=fθ(x)为随机变量X的\thetaθ-tilted密度分布。
综上可知
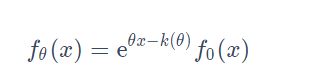
习题6.2
1.题目:写出Logistic回归模型学习的梯度下降算法。
2.解题思路:
(1)写出Logistic回归模型
(2)根据书中附录A梯度下降法,写出Logistic回归模型学习的梯度下降法
(3)自编程实现Logistic回归模型学习的梯度下降法
3.第1步:Logistic回归模型
根据书中第92页Logistic回归模型的定义
二项Logistic回归模型是如下的条件概率分别:
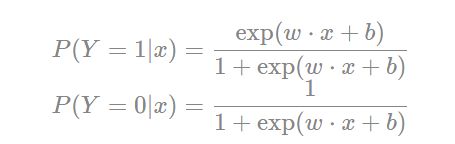
第2步:Logistic回归模型学习的梯度下降法
根据书中第93页模型参数估计:
Logistic回归模型的对数似然函数为
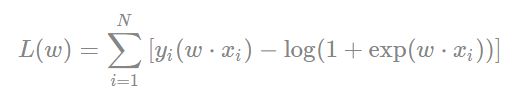
将对数似然函数求偏导,可得

梯度函数为:

根据书中第439页附录A 梯度下降法的算法:
输入:目标函数f(x),梯度函数 g ( x ) = ∇ f ( x ) g(x)=∇f(x) g(x)=∇f(x)计算精度ε;
输出: f ( x ) 的 极 小 值 x ∗ f(x)的极小值x^* f(x)的极小值x∗
(1) 取初始值 x 0 ∈ R n x ^0∈R ^n x0∈Rn置k=0
(2) 计算 f ( x ( k ) ) f(x^{(k)}) f(x(k))
(3) 计算梯度 g k = g ( x ( k ) ) g_k=g(x^{(k)}) gk=g(x(k)),当 ∥ g k ∥ < ε 时 \|g_k\| < \varepsilon时 ∥gk∥<ε时,停止迭代,令 x ∗ = x ( k ) ; x^* = x^{(k)} ; x∗=x(k);否则,令 p k = − g ( x ( k ) ) p_k=-g(x^{(k)}) pk=−g(x(k)),求 λ k \lambda_k λk,使

(4) 置 x ( k + 1 ) = x ( k ) + λ k p k x^{(k+1)}=x^{(k)}+\lambda_k p_k x(k+1)=x(k)+λkpk,计算 f ( x ( k + 1 ) ) f(x^{(k+1)}) f(x(k+1))
当 ∥ f ( x ( k + 1 ) ) − f ( x ( k ) ) ∥ < ε \|f(x^{(k+1)}) - f(x^{(k)})\| < \varepsilon ∥f(x(k+1))−f(x(k))∥<ε或 ∥ x ( k + 1 ) − x ( k ) ∥ < ε ∥x (k+1) −x (k)∥<ε ∥x(k+1)−x(k)∥<ε时,停止迭代,令 x ∗ = x ( k + 1 ) x^* = x^{(k+1)} x∗=x(k+1)
第3步:自编程实现Logistic回归模型学习的梯度下降法
from scipy.optimize import fminbound
from pylab import mpl
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# 图像显示中文
mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei']
class MyLogisticRegression:
def __init__(self, max_iter=10000, distance=3, epsilon=1e-6):
"""
Logistic回归
:param max_iter: 最大迭代次数
:param distance: 一维搜索的长度范围
:param epsilon: 迭代停止阈值
"""
self.max_iter = max_iter
self.epsilon = epsilon
# 权重
self.w = None
self.distance = distance
self._X = None
self._y = None
@staticmethod
def preprocessing(X):
"""将原始X末尾加上一列,该列数值全部为1"""
row = X.shape[0]
y = np.ones(row).reshape(row, 1)
return np.hstack((X, y))
@staticmethod
def sigmod(x):
return 1 / (1 + np.exp(-x))
def grad(self, w):
z = np.dot(self._X, w.T)
grad = self._X * (self._y - self.sigmod(z))
grad = grad.sum(axis=0)
return grad
def like_func(self, w):
z = np.dot(self._X, w.T)
f = self._y * z - np.log(1 + np.exp(z))
return np.sum(f)
def fit(self, data_x, data_y):
self._X = self.preprocessing(data_x)
self._y = data_y.T
# (1)取初始化w
w = np.array([[0] * self._X.shape[1]], dtype=np.float)
k = 0
# (2)计算f(w)
fw = self.like_func(w)
for _ in range(self.max_iter):
# 计算梯度g(w)
grad = self.grad(w)
# (3)当梯度g(w)的模长小于精度时,停止迭代
if (np.linalg.norm(grad, axis=0, keepdims=True) < self.epsilon).all():
self.w = w
break
# 梯度方向的一维函数
def f(x):
z = w - np.dot(x, grad)
return -self.like_func(z)
# (3)进行一维搜索,找到使得函数最大的lambda
_lambda = fminbound(f, -self.distance, self.distance)
# (4)设置w(k+1)
w1 = w - np.dot(_lambda, grad)
fw1 = self.like_func(w1)
# (4)当f(w(k+1))-f(w(k))的二范数小于精度,或w(k+1)-w(k)的二范数小于精度
if np.linalg.norm(fw1 - fw) < self.epsilon or \
(np.linalg.norm((w1 - w), axis=0, keepdims=True) < self.epsilon).all():
self.w = w1
break
# (5) 设置k=k+1
k += 1
w, fw = w1, fw1
self.grad_ = grad
self.n_iter_ = k
self.coef_ = self.w[0][:-1]
self.intercept_ = self.w[0][-1]
def predict(self, x):
p = self.sigmod(np.dot(self.preprocessing(x), self.w.T))
p[np.where(p > 0.5)] = 1
p[np.where(p < 0.5)] = 0
return p
def score(self, X, y):
y_c = self.predict(X)
# 计算准确率
error_rate = np.sum(np.abs(y_c - y.T)) / y_c.shape[0]
return 1 - error_rate
def draw(self, X, y):
# 分隔正负实例点
y = y[0]
X_po = X[np.where(y == 1)]
X_ne = X[np.where(y == 0)]
# 绘制数据集散点图
ax = plt.axes(projection='3d')
x_1 = X_po[0, :]
y_1 = X_po[1, :]
z_1 = X_po[2, :]
x_2 = X_ne[0, :]
y_2 = X_ne[1, :]
z_2 = X_ne[2, :]
ax.scatter(x_1, y_1, z_1, c="r", label="正实例")
ax.scatter(x_2, y_2, z_2, c="b", label="负实例")
ax.legend(loc='best')
# 绘制透明度为0.5的分隔超平面
x = np.linspace(-3, 3, 3)
y = np.linspace(-3, 3, 3)
x_3, y_3 = np.meshgrid(x, y)
a, b, c, d = self.w[0]
z_3 = -(a * x_3 + b * y_3 + d) / c
# 调节透明度
ax.plot_surface(x_3, y_3, z_3, alpha=0.5)
plt.show()
训练数据集
X_train = np.array([[3, 3, 3], [4, 3, 2], [2, 1, 2], [1, 1, 1], [-1, 0, 1], [2, -2, 1]])
y_train = np.array([[1, 1, 1, 0, 0, 0]])
# 构建实例,进行训练
clf = MyLogisticRegression(epsilon=1e-6)
clf.fit(X_train, y_train)
clf.draw(X_train, y_train)
print("迭代次数:{}次".format(clf.n_iter_))
print("梯度:{}".format(clf.grad_))
print("权重:{}".format(clf.w[0]))
print("模型准确率:%0.2f%%" % (clf.score(X_train, y_train) * 100))
输出结果:
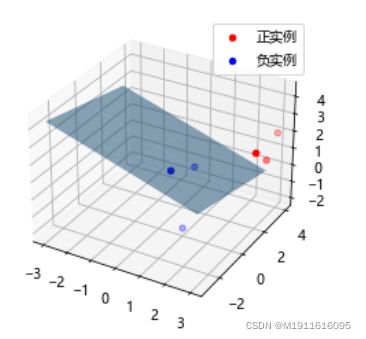
迭代次数:2095次
梯度:[ 7.33881397e-05 2.44073067e-05 2.52604176e-04 -5.13424350e-04]
权重:[ 4.34496173 2.05340452 9.64074166 -22.85079478]
模型准确率:100.00%
参考资料datawhale组队学习