OD-Model【8】:YOLOv4
系列文章目录
YOLO目标检测系列(一):
OD-Model【5】:YOLOv1
YOLO目标检测系列(二):
OD-Model【6】:YOLOv2
YOLO目标检测系列(三):
OD-Model【7】:YOLOv3
YOLO目标检测系列(四):
OD-Model【8】:YOLOv4
YOLO目标检测系列(五):
OD-Model【9】:YOLOv5
文章目录
- 系列文章目录
- 前言
- 1. Abstract & Introduction
-
- 1.1. Abstract
- 1.2. Introduction
- 2. Related work
-
- 2.1. Object detection models
- 2.2. Bag of freebies
- 2.3. Bag of specials
- 3. Methodology
-
- 3.1. Selection of architecture
-
- 3.1.1. Backbone - CSPDarknet53
-
- 3.1.1.1. CSP module
- 3.1.1.2. CSPDarknet53 structure
- 3.1.2. SPP
- 3.1.3. PAN
- 3.1.4. YOLOv4
- 3.2. Optimization Strategies
-
- 3.2.1. Eliminate grid sensitivity
- 3.2.2. Mosaic data augmentation
-
- 3.2.2.1. Introduction
- 3.2.2.2. Mosaic implementation method
- 3.2.3. IoU threshold
- 3.2.4. Optimizered Anchors
- 3.2.5. CIoU
- 总结
前言
YOLOv4是一个单阶段的物体检测模型,它在 YOLOv3 的基础上改进了文献中介绍的技巧和模块。
原论文链接:
YOLOv4: Optimal Speed and Accuracy of Object Detection
1. Abstract & Introduction
1.1. Abstract
有大量的技巧可以提高卷积神经网络(CNN)的精度。需要在大数据集下对这种技巧的组合进行实际测试,并对结果进行理论论证要求。某些技巧仅在某些模型上使用和专门针对某些问题,或只针对小规模的数据集;而一些技巧,如批处理归一化、残差连接等,适用于大多数的模型、任务和数据集。我们假设这种通用的技巧包括 Weighted-Residual-Connection(WRC)、Cross-Stage-Partial-connections(CSP)、跨小型批量连接(CSP)、Cross mini-Batch Normalization(CmBN)、Self-adversarial-trainin(SAT)和 Mish-activation。我们在本文中使用这些新的技巧:WRC、CSP、CmBN、SAT、Mish-activation
Mosaic data augmentation、CmBN、DropBlock正则化和 CIoU损失,以及组合技巧,以达到最好的效果。
1.2. Introduction
本文的主要目标是设计一个应用生产环境快速运行的目标检测器,并且进行并行计算优化,而不是低水平的计算放量理论指标(BFLOP)。我们希望所设计的对象易于训练和使用。例如,任何使用传统GPU训练和测试可以实现实时、高质量、有说服力的目标检测结果。YOLOv4与其余模型的比较如下图所示:
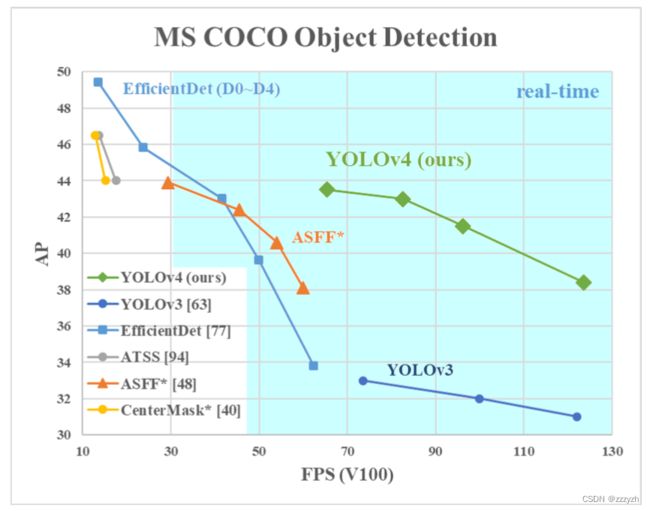
本文的贡献总结如下:
- 构建了一个快速强大的模型,可以使用单GPU来训练一个超快、准确的目标检测器
- 验证了最先进的Bag-of-Freebies 和 Bag-of-Specials方法在训练期间的影响
- 修改了最先进的方法,使其更为高效,适合单GPU训练,包括CBN、PAN、SAM等
2. Related work
2.1. Object detection models
现代目标检测器通常由两部分组成。ImageNet 上预训练的 backbone 和用于预测类和 BBOX 的检测器 head。
对于那些在 GPU 平台上运行的探测器,其 backbone 可以是 VGG,ResNet、ResNeXt、或 DenseNet。对于那些运行在CPU平台上的检测器形式,它们的backbone 可以是 SqueezeNet、MobileNet,或 ShuffleNet。
至于 head 部分,它通常被分两类:即 one-stage 目标检测器和 two-stage 目标检测器。最有代表性的 two-stage 检测器是 R-CNN 系列。包括 Fast R-CNN,Faster R-CNN,R-FCN 和 Libra R-CNN。也可以做一个 two-stage 目标检测器一个 anchor-free 目标检测器,如 RepPoints。对于 one-stage 检测器来说,最代表性的有 YOLO、SSD 和 RetinaNet。近几年来,anchor-free one-stage目标探测器被开发,如 CenterNet、CornerNet、FCOS 等。
近年来发展起来的检测器,往往会在 backbone 和 head 之间插入一些层,这些层用于收集不同阶段的特征图。我们可以称它为检测器的 neck。通常情况下 neck 是由几个 bottom-up paths 和多个 top-down paths 组成。Feature Pyramid Network (FPN)、 Path Aggregation(PAN)、BiFPN 和 NAS-FPN 具有这个机制。除上述模型外,有的研究者重新构建backbone(DetNet,DetNAS)或重新构建整个模型(SpineNet,HitDetector)用于目标检测

总结来说:
- Input: Image, Patches, Image Pyramid
- Backbones: VGG16, ResNet-50, SpineNet, EfficientNet-B0/B7, CSPResNeXt50, CSPDarknet53
- Neck:
- Additional blocks: SPP, ASPP, RFB, SAM
- Path-aggregation blocks: FPN, PAN, NAS-FPN, Fully-connected FPN, BiFPN, ASFF, SFAM
- Heads:
- Dense Prediction (one-stage):
- RPN, SSD, YOLO, RetinaNet (anchor based)
- CornerNet, CenterNet, MatrixNet, FCOS (anchor free)
- Sparse Prediction (two-stage):
- Faster R-CNN, R-FCN, Mask R-CNN (anchor based)
- RepPoints (anchor free)
- Dense Prediction (one-stage):
2.2. Bag of freebies
通常情况下,因此,研究人员总是喜欢利用这一优势,开发更好的训练方法,使物体检测器获得更好的精度,而不增加推理成本。本文将这些只改变训练策略或只增加训练成本的方法称为 bag of freebies。目标检测经常采用的、并符合这个定义的就是数据增强。
数据增强的目的是:数据增强的目的是增加输入图像的可变性,使设计的物体检测模型对来自不同环境的图像具有更高的鲁棒性。
- 像素级调整
- photometric distortions(光度失真)
- 调整图像的亮度、对比度、色调、饱和度和噪声
- geometric distortions(几何失真)
- 添加随机缩放、裁剪、翻转和旋转
- photometric distortions(光度失真)
- 模拟 object occlusion(物体遮挡)问题
- random erase & CutOut
- hide-and-seek & grid mask
- 将类似的概念应用于特征图
- DropOut、DropConnect 和 DropBlock
- 将多张图像放在一起进行数据增强
- MixUp 使用两幅图像,以不同的系数比例进行乘法和叠加,然后用这些叠加比例调整标签
- CutMix,将裁剪的图像覆盖到其他图像的矩形区域,并根据混合区域的大小来调整标签
- 风格转移 GAN
- 解决数据集中的语义分布可能有偏差的问题
- 不同类之间存在数据不平衡的问题
- 通过两阶段对象检测中的 hard negative example mining 或 online hard example mining 来解决
- focal loss
- 处理不同类别之间存在的数据不平衡的问题
- label smoothing
- 将硬标签转换成软标签进行训练
- 不同类之间存在数据不平衡的问题
- Bounding Box(BBox)回归的目标函数
- 对BBox的每个点的坐标值进行直接估计,就是把这些点当作独立的变量,但事实上并没有考虑物体本身的完整性。
- IoU Loss
- 尺度不变的表示方法
- GIoU 损失是除了覆盖面积外,还包括物体的形状和方向。他们提出,找到能同时覆盖预测 BBox 和 GT box 的最小区域的 BBox,并使用该 BBox 作为分母,以取代 IoU 损失中最初使用的分母
- DIoU 损失,它还考虑了物体中心的距离
- CIoU 损失,则同时考虑了重叠区域、中心点之间的距离和长宽比
- 在 BBox 回归问题上实现更好的收敛速度和准确性
2.3. Bag of specials
对于那些只增加少量推理成本,但能显著提高物体识别精度的插件模块和后处理方法,我们称之为 Bag of specials。一般来说,这些插件模块是为了增强模型中的某些属性,如扩大感受野、引入注意机制或加强特征整合能力等,而后处理是一种筛选模型预测结果的方法。
- 增强感受野的常见模块
- SPP
- ASPP
- RFB
- 注意力模块
- 通道式注意力
- Squeeze-and-Excitation (SE)
- 点式注意力
- Spatial Attention Module (SAM)
- 通道式注意力
- 特征整合
- 早期做法
- skip connection
- hyper-column
- 整合不同特征金字塔的轻量级模块
- SFAM
- ASFF
- BiFPN
- 早期做法
- 激活函数
- ReLU
- 大幅解决传统tanh和sigmoid激活函数中经常遇到的梯度消失的问题
- LReLU 和 PReLU
- 解决当输出小于零时ReLU的梯度为零的问题
- ReLU6 和 hard-Swish
- 专门为量化网络设计
- ReLU
- 基于深度学习的物体检测中常用的后处理方法
- NMS
3. Methodology
3.1. Selection of architecture
3.1.1. Backbone - CSPDarknet53
在YOLOv3中,特征提取网络使用的是Darknet53,而在YOLOv4中,对Darknet53做了一点改进,借鉴了CSPNet
CSPNet解决了其他大型卷积神经网络框架Backbone中网络优化的梯度信息重复问题,将梯度的变化从头到尾地集成到特征图中,因此减少了模型的参数量和FLOPS数值,既保证了推理速度和准确率,又减小了模型尺寸
3.1.1.1. CSP module
- CSPDenseNet

- 将数据划分成俩部分按通道均分成Part 1 与 Part 2
- 原论文使用的 DenseNet 所以添加的是 Dense Block
- CSPNet 实际上是基于 Densnet 的思想,复制基础层的特征映射图,通过 dense block 发送副本到下一个阶段,从而将基础层的特征映射图分离出来。这样可以有效缓解梯度消失问题(通过非常深的网络很难去反推丢失信号),支持特征传播,鼓励网络重用特征,从而减少网络参数数量。
- CSPDarknet53

- 一般在 CSP 模块之前,会进行一次下采样
- 通过 1 × 1 1 \times 1 1×1 的卷积结构对数据进行划分
- ConvBNMish 是一个 1 × 1 1 \times 1 1×1 的卷积结构,对应 CSPDenseNet 中的 Transition 结构
- CSP 模块的作用:
- 增强 CNN 学习的能力
- 移除计算的瓶颈
- 降低显存的使用
- 只在Backbone中采用了 Mish 激活函数,网络后面仍然采用 Leaky_relu 激活函数
- Mish 激活函数

- Mish 激活函数
3.1.1.2. CSPDarknet53 structure
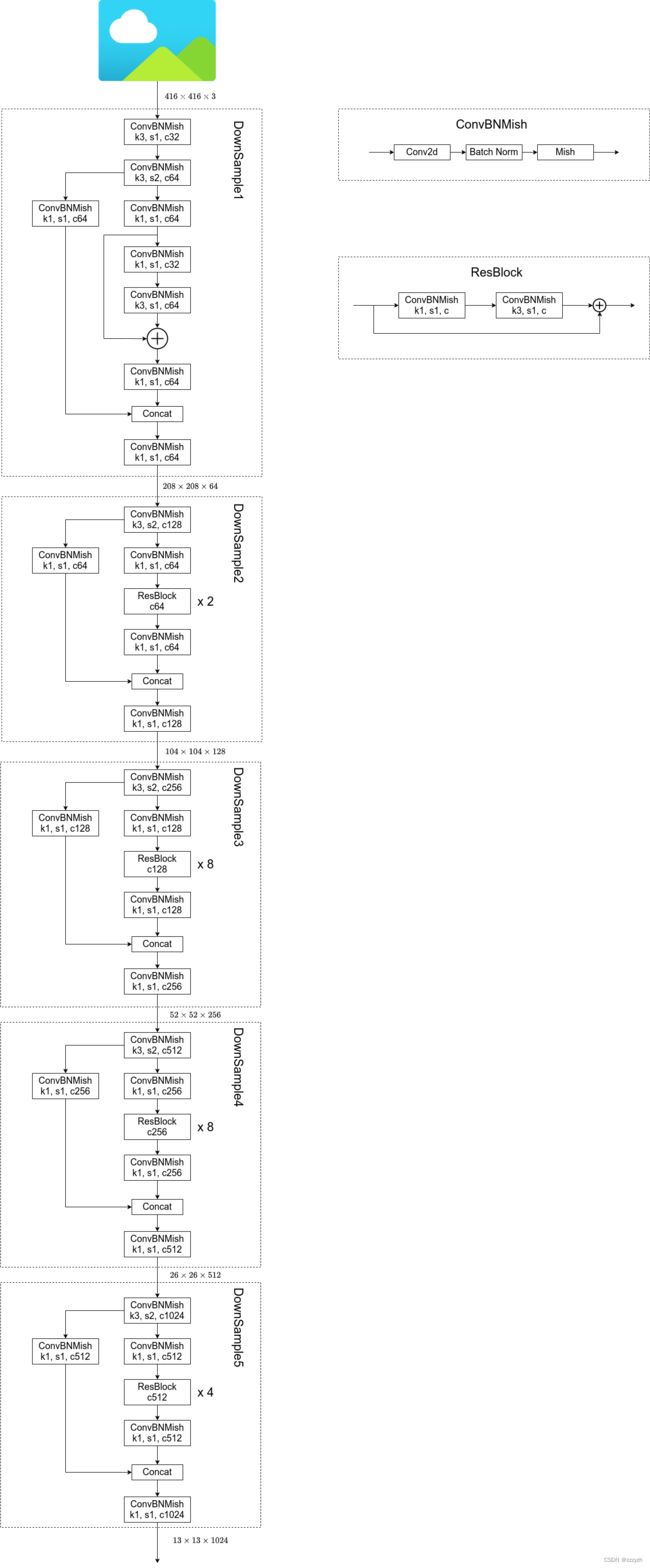
- 以输入图片大小为 416 × 416 × 3 416 \times 416 \times 3 416×416×3 为例
- 参数
- k k k 代表卷积核的大小
- s s s 代表步距
- c c c 代表通过该模块输出的特征层 channels
- CSPDarknet53 Backbone 中所有的激活函数都是 Mish 激活函数
3.1.2. SPP
能够在一定程度上解决多尺度问题
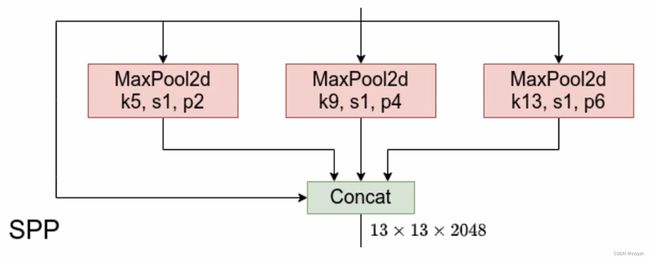
输出由四部分组成:
- 输入直接连接到输出
- 池化核大小为 5 × 5 5 \times 5 5×5,步长为 1 的最大池化下采样
- 池化核大小为 9 × 9 9 \times 9 9×9,步长为 1 的最大池化下采样
- 池化核大小为 13 × 13 13 \times 13 13×13,步长为 1 的最大池化下采样
- 需要注意的是,因为这里的步长均为 1,所以在进行池化操作之前,需要对特征矩阵进行 padding填充
- 输出的特征矩阵的高和宽与输入的相同,深度变为原来的 4 倍
- 上面 4 步操作最后需要进行 Concatenate 操作(在深度方向进行拼接),所以需要使用 padding 来保证每一次池化之后的特征矩阵与原矩阵的高和宽相同
3.1.3. PAN
YOLOv4 中 Neck 这部分使用 FPN + PAN 的结构:

每个CSP模块前面都是大小为 3 × 3 3 \times 3 3×3 ,步长为2的卷积核,相当于下采样操作。
因此可以看到三个紫色箭头处的特征图为: 76 × 76 76 \times 76 76×76、 38 × 38 38 \times 38 38×38、 19 × 19 19 \times 19 19×19。对应的预测结果特征图的尺寸为: 76 × 76 × 255 76 \times 76 \times 255 76×76×255、 38 × 38 × 255 38 \times 38 \times 255 38×38×255、 19 × 19 × 255 19 \times 19 \times 255 19×19×255。
FPN + PAN 结构的立体图如下图所示
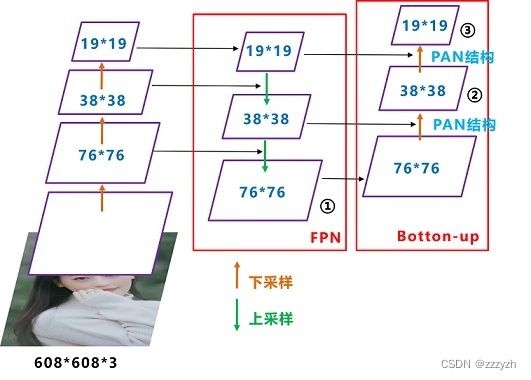
在FPN层的后面还添加了一个自底向上的特征金字塔,其中包含两个PAN结构
这样结合操作,FPN 层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行参数聚合
需要注意的是:
- 特征图的尺寸对应的 anchor box 与YOLOv3 不同
- 第一个 YOLO 层是最大的特征图 76 × 76 76 \times 76 76×76,对应最小的 anchor box
- 第二个 YOLO 层是中等的特征图 38 × 38 38 \times 38 38×38,对应中等的 anchor box
- 第三个 YOLO 层是最小的特征图 19 × 19 19 \times 19 19×19,对应最大的 anchor box
- 特征图结合的方式与 PANet 不同
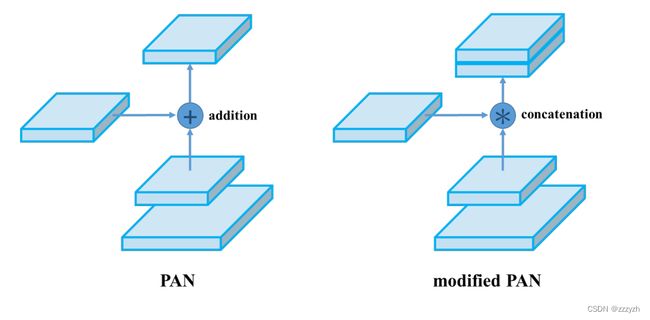
- 原本的 PANet 网络的 PAN 结构中,两个特征图结合是采用 shortcut 操作
- 而 YOLOv4 中则采用 concat(route)操作,特征图融合后的尺寸发生了变化
3.1.4. YOLOv4
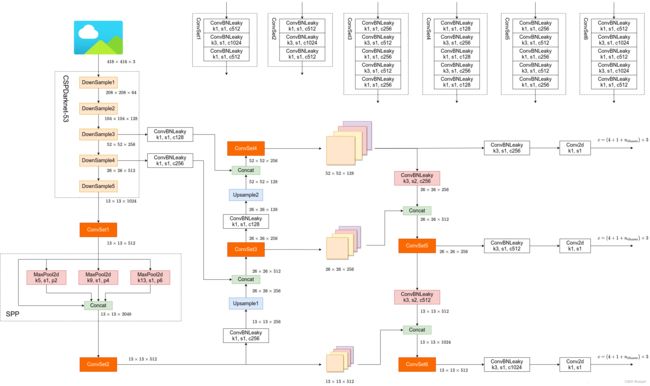
输出参数解析:
- 4 4 4:对每一个 anchor 预测 4 个目标回归参数
- 1 1 1:置信度
- n c l s n_{cls} ncls:预测目标类别个数
- 3 3 3:针对每一个预测特征层,都会采用3个不同的 anchor 模版
3.2. Optimization Strategies
3.2.1. Eliminate grid sensitivity
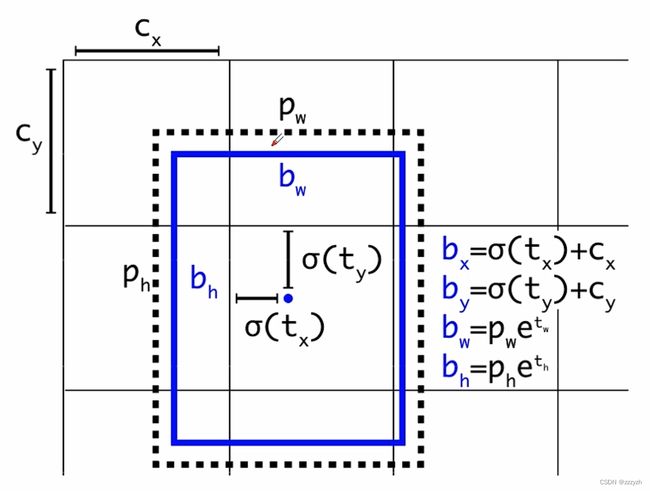
在原来 YOLOv3 中,关于计算预测的目标中心坐标计算公式是:
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b_x = \sigma(t_x) + c_x \\ b_y = \sigma(t_y) + c_y bx=σ(tx)+cxby=σ(ty)+cy
其中:
- t x t_x tx 是网络预测的目标中心 x x x坐标偏移量(相对于网格的左上角)
- t y t_y ty 是网络预测的目标中心 y y y坐标偏移量(相对于网格的左上角)
- c x c_x cx 是对应网格左上角的 x x x 坐标
- c x c_x cx 是对应网格左上角的 y y y 坐标
- σ \sigma σ 是sigmoid激活函数,将预测的偏移量限制在0到1之间,即预测的中心点不会超出对应的Grid Cell区域
- σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1
但在 YOLOv4的论文中作者认为这样做不太合理,比如当真实目标中心点非常靠近网格的左上角点 ( σ ( t x ) \sigma(t_x) σ(tx) 和 σ ( t y ) \sigma(t_y) σ(ty) 应该趋近于0)或者右下角点( σ ( t x ) \sigma(t_x) σ(tx) 和 σ ( t y ) \sigma(t_y) σ(ty) 应该趋近于1)时。网络的预测值需要负无穷或者正无穷时才能取到,而这种很极端的值网络一般无法达到。
为了解决这个问题,作者引入了一个大于1的缩放系数( s c a l e x y scale_{xy} scalexy):
b x = ( σ ( t x ) ⋅ s c a l e x y − s c a l e x y − 1 2 ) + c x b x = ( σ ( t y ) ⋅ s c a l e x y − s c a l e x y − 1 2 ) + c y b_x = (\sigma(t_x) \cdot scale_{xy} - \frac{scale_{xy} - 1}{2}) + c_x \\ b_x = (\sigma(t_y) \cdot scale_{xy} - \frac{scale_{xy} - 1}{2}) + c_y bx=(σ(tx)⋅scalexy−2scalexy−1)+cxbx=(σ(ty)⋅scalexy−2scalexy−1)+cy
通过引入这个系数,网络的预测值能够很容易达到0或者1。目前主流的实现方法,通常将 s c a l e x y scale_{xy} scalexy 设置为2。绘制对应的 y = σ ( x ) y = \sigma(x) y=σ(x) 的图像和 y = 2 ⋅ σ ( x ) − 0.5 y = 2 \cdot \sigma(x) - 0.5 y=2⋅σ(x)−0.5 的图像如下所示:

很明显通过引入缩放系数 scale 以后, x x x 在同样的区间内, y y y 的取值范围更大,或者说 y y y 对 x x x 更敏感了。并且偏移的范围由原来的 ( 0 , 1 ) (0, 1) (0,1) 调整到了 ( − 0.5 , 1.5 ) (-0.5, 1.5) (−0.5,1.5)。
预测目标高宽的计算公式为:
b w = p w ⋅ e t w b h = p h ⋅ e t h b_w = p_w \cdot e^{t_w} \\ b_h = p_h \cdot e^{t_h} bw=pw⋅etwbh=ph⋅eth
3.2.2. Mosaic data augmentation
3.2.2.1. Introduction
Mosaic data augmentation 的主要思想是将四张图片进行随机裁剪,再拼接到一张图上作为训练数据。这样做的好处是丰富了图片的背景,并且四张图片拼接在一起变相地提高了batch_size,在进行 batch normalization 的时候也会计算四张图片,所以对本身 batch_size 不是很依赖,单块GPU就可以训练 YOLOv4。
几种常见的数据增强方法:
- Mixup:将随机的两张样本按比例混合,分类的结果按比例分配;
- Cutout:随机的将样本中的部分区域 cut 掉,并且填充0像素值,分类的结果不变;
- CutMix:就是将一部分区域cut掉但不填充0像素而是随机填充训练集中的其他数据的区域像素值,分类结果按一定的比例分配
区别:
- Cutout 和 CutMix 就是填充区域像素值的区别;
- Mixup 和 CutMix 是混合两种样本方式上的区别:
- Mixup 是将两张图按比例进行插值来混合样本,CutMix 是采用 cut 部分区域再补丁的形式去混合图像,不会有图像混合后不自然的情形。
优点:
- 在训练过程中不会出现非信息像素,从而能够提高训练效率;
- 保留了regional dropout 的优势,能够关注目标的 non-discriminative parts;
- 通过要求模型从局部视图识别对象,对 cut 区域中添加其他样本的信息,能够进一步增强模型的定位能力;
- 不会有图像混合后不自然的情形,能够提升模型分类的表现;
- 训练和推理代价保持不变。
3.2.2.2. Mosaic implementation method
YOLOv4 的 Mosaic data augmentation 参考了 CutMix 数据增强方式, 是 CutMix 数据增强方法的改进版。Mosaic 数据增强利用了四张图片,对四张图片进行拼接,每一张图片都有其对应的框,将四张图片拼接之后就获得一张新的图片,同时也获得这张图片对应的框,然后我们将这样一张新的图片传入到神经网络当中去学习,相当于一下子传入四张图片进行学习了。
实现步骤:
- 从数据集中每次随机读取四张图片
- 分别对四张图片进行翻转(对原始图片进行左右的翻转)、缩放(对原始图片进行大小的缩放)、色域变化(对原始图片的明亮度、饱和度、色调进行改变)等操作
- 进行图片的组合和框的组合
- 对框进行处理
3.2.3. IoU threshold
在我的另一篇blogOD-Model【7】:YOLOv3中,介绍过 YOLOv3 SPP 的一种匹配准则,大致流程如下所示:

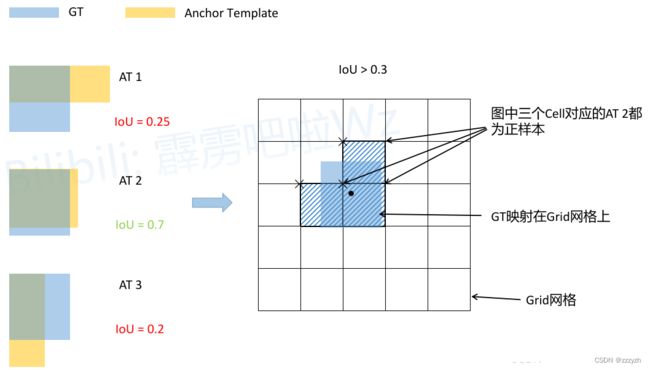
- 将每个 GT Boxes 与每个 Anchor 模板进行匹配(这里直接将GT和Anchor模板左上角对齐,然后计算IoU)
- 如果 GT 与某个 Ancho r模板的 IoU 大于给定的阈值,则将 GT 分配给该 Anchor 模板,如图中的 AT 2
- 将 GT 投影到对应预测特征层上,根据 GT 的中心点定位到对应 cell(图中黑色的 × 表示cell的左上角)
- 则该cell对应的AT2为正样本
在 YOLOv4 中,通过缩放因子 s c a l e x y scale_{xy} scalexy,网络预测中心点的偏移范围已经从原来的 ( 0 , 1 ) (0, 1) (0,1) 调整到了 ( − 0.5 , 1.5 ) (-0.5, 1.5) (−0.5,1.5)。所以对于同一个GT Boxes可以分配给更多的Anchor,即正样本的数量更多了。如下图所示:
- 将每个 GT Boxes 与每个 Anchor 模板进行匹配(这里直接将 GT 和 Anchor 模板左上角对齐,然后计算 IoU,在 YOLOv4 中 IoU 的阈值设置的是0.213)
- 如果 GT 与某个 Anchor 模板的 IoU 大于给定的阈值,则将 GT 分配给该 Anchor 模板,如图中的 AT 2
- 将GT投影到对应预测特征层上,根据 GT 的中心点定位到对应c ell(注意图中有三个对应的 cell,后面会解释)
- 则这三个 cell 对应的 AT 2 都为正样本
刚刚说了网络预测中心点的偏移范围已经调整到了 ( − 0.5 , 1.5 ) (-0.5, 1.5) (−0.5,1.5),所以按理说只要 Grid Cell 左上角点距离 GT 中心点在 ( − 0.5 , 1.5 ) (-0.5, 1.5) (−0.5,1.5) 范围内它们对应的Anchor都能回归到 GT 的位置处。
上面的例子中, G T x c e n t e r GT_x^{center} GTxcenter, G T y c e n t e r GT_y^{center} GTycenter 它们距离落入的 Grid Cell 左上角距离都小于 0.5,所以该 Grid Cell 上方的 Cell 以及左侧的 Cell 都满足条件,即 Cell 左上角点距离GT中心在 ( − 0.5 , 1.5 ) (-0.5, 1.5) (−0.5,1.5) 范围内。这样会让正样本的数量得到大量的扩充。但需要注意的是,YOLOv4 源码中扩展 Cell 时只会往上、下、左、右四个方向扩展,不会往左上、右上、左下、右下方向扩展。
下面又给出了一些根据 G T x c e n t e r GT_x^{center} GTxcenter, G T y c e n t e r GT_y^{center} GTycenter 的位置扩展的一些Cell,

需要注意的是,当 GT 的中心点刚好落入 Grid Cell 的中心,即 x x x 和 y y y 坐标对 1 取余都等于 0.5 的时候,只会利用当前 Grid Cell 的 Anchor,因为此时 GT 相对于 其他 Grid Cell 的偏移量都达到了极限
3.2.4. Optimizered Anchors
针对 512 × 512 512 \times 512 512×512 尺度采用的 anchor 模板是:
| 目标类型 | Anchors模版 |
|---|---|
| 小尺度 | 12 × 16 12 \times 16 12×16, 19 × 36 19 \times 36 19×36, 40 × 28 40 \times 28 40×28 |
| 中尺度 | 36 × 75 36 \times 75 36×75, 76 × 55 76 \times 55 76×55, 72 × 146 72 \times 146 72×146 |
| 大尺度 | 142 × 110 142 \times 110 142×110, 192 × 243 192 \times 243 192×243, 459 × 401 459 \times 401 459×401 |
3.2.5. CIoU
在我的另一篇blogOD-Model【7】:YOLOv3中
中的第4节里面,我们对 IoU Loss、GIoU Loss、DIoU Loss 以及 CIoU Loss 做了详细对比
CIoU Loss 将目标框回归函数应该考虑三个重要几何因素:重叠面积、中心点距离,长宽比全都考虑进去了
完整的 CIoU 的计算公式为:
C I o U = I o U − R C I o U = I o U − ( ρ 2 ( b , b g t ) c 2 + α υ ) CIoU = IoU - R_{CIoU} = IoU - (\frac{\rho^2(b, b^{gt})}{c^2} + \alpha \upsilon) CIoU=IoU−RCIoU=IoU−(c2ρ2(b,bgt)+αυ)
损失计算:
L C I o U = 1 − C I o U L_{CIoU} = 1 - CIoU LCIoU=1−CIoU
总结
YOLOv4 将近几年关于深度学习领域最新研究的 tricks 移植到 YOLOv4 中做验证测试,将YOLOv3 的精度提高了不少(但相比于 YOLOv3 SPP 的提升有限)。
YOLOv4 主要带来了 3 点新贡献:
- 提出了一种高效而强大的目标检测模型,使用 1080Ti 或 2080Ti 就能训练出超快、准确的目标检测器
- 在检测器训练过程中,验证了最先进的一些研究成果对目标检测器的影响
- 改进了 SOTA 方法,使其更有效、更适合单 GPU 训练
翻译参考
Mosaic data augmentation 参考